State space models are good for tasks that do not require (long) history(time)-dependence.
This is because you can process the entire series with a parallelizable scan by making the processing of each element of the sequence independent of others, i.e. there is no shared state between the elements of the sequence, as opposed to RNNs or LSTMs.
An example task would be character-level language modelling.
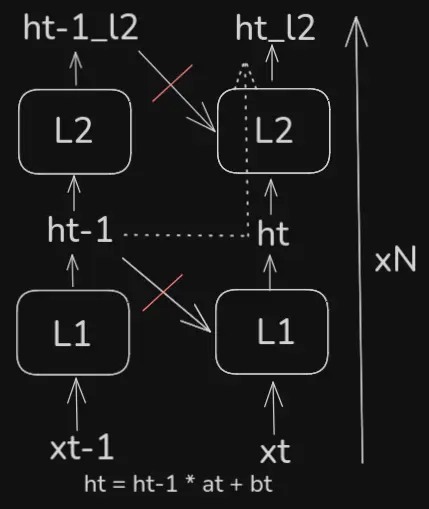
If such dependence is necessary, one can stack layers of SSMs, where the hidden state of each layer still can’t have any knowledge of the previous hidden states of the same layer, but can have knowledge of the hidden states of the previous layer - then layers have to be processed sequentially, but the sequence elements (which are usually much more) can still be processed in parallel. This way, information about the past is implicitly passed via the hidden state, which is computed as , where are the weights and biases of the layer at time .
This is akin to convolutions, which have a limited, local receptive field, but which gets implicitly expanded by stacking layers (also similar to the segment-level recurrence of transformer-xl).
SSMs
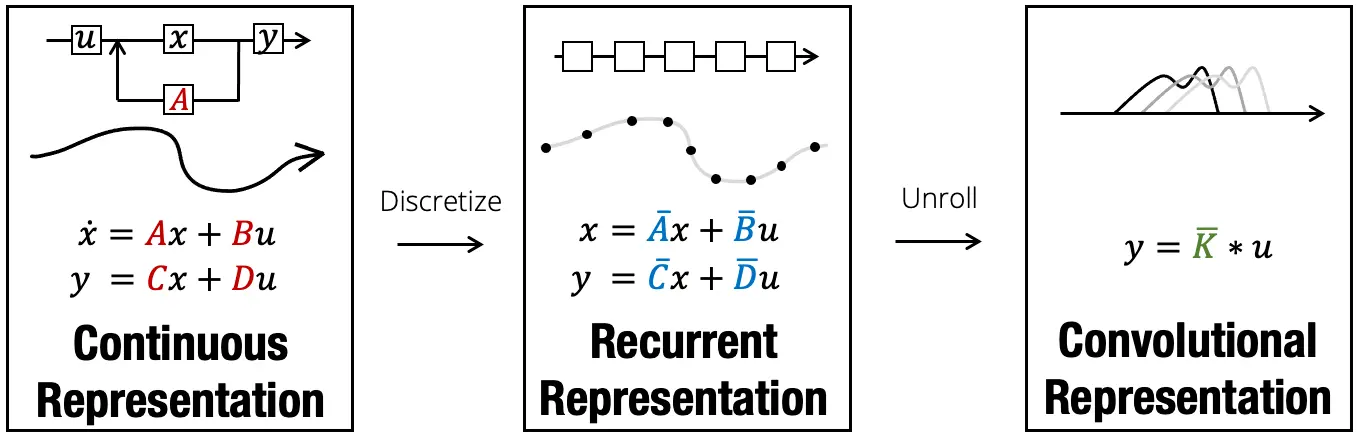
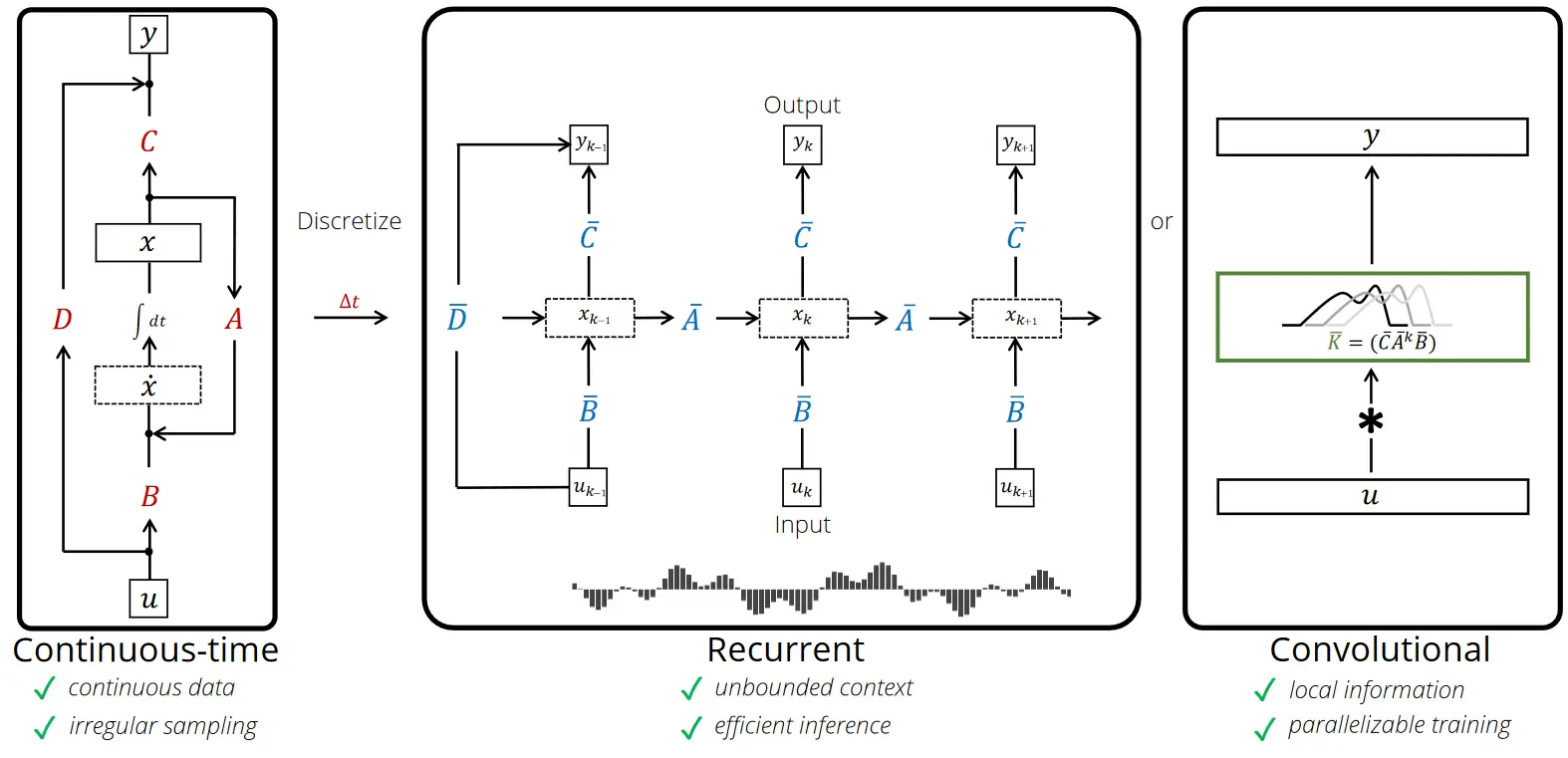
Many SSMs fall under the following framework:
Given a length sequence of inputs , a general class of linear recurrences with hidden states and outputs can be computed as shown:where is the state transition matrix, \boldsymbol{B}{k} \in \mathbb{R}^{N\times D}g(\cdot)\boldsymbol{A}{k} = \boldsymbol{A}\boldsymbol{B}_{k} = \boldsymbol{B} \quad \forall k$ (for example S4 (SSM))
References
https://huggingface.co/blog/lbourdois/get-on-the-ssm-train
Birdie - Advancing State Space Modelswith Reward-Driven Objectives and Curricula