Graph Attention Networks (GATs) are one of the most popular GNN architectures and are considered as the state-of-the-art architecture for representation learning with graphs. In GAT, every node attends to its neighbors given its own representation as the query. However, in this paper we show that GAT computes a very limited kind of attention: the ranking of the attention scores is unconditioned on the query node. We formally define this restricted kind of attention as static attention and distinguish it from a strictly more expressive dynamic attention. Because GATs use a static attention mechanism, there are simple graph problems that GAT cannot express: in a controlled problem, we show that static attention hinders GAT from even fitting the training data. To remove this limitation, we introduce a simple fix by modifying the order of operations and propose GATv2: a dynamic graph attention variant that is strictly more expressive than GAT. We perform an extensive evaluation and show that GATv2 outperforms GAT across 12 OGB and other benchmarks while we match their parametric costs. Our code is available at GitHub.1 GATv2 is available as part of the PyTorch Geometric library,2 the Deep Graph Library,3 and the TensorFlow GNN library.4
1 INTRODUCTION
Graph neural networks (GNNs; Gori et al., 2005; Scarselli et al., 2008)GNNs have seen increasing popularity over the past few years (Duvenaud et al., 2015; Atwood and Towsley, 2016; Bronstein et al., 2017; Monti et al., 2017). GNNs provide a general and efficient framework to learn from graph-structured data. Thus, GNNs are easily applicable in domains where the data can be represented as a set of nodes and the prediction depends on the relationships (edges) between the nodes. Such domains include molecules, social networks, product recommendation, computer programs and more.
In a GNN, each node iteratively updates its state by interacting with its neighbors. GNN variants (Wu et al., 2019; Xu et al., 2019; Li et al., 2016) mostly differ in how each node aggregates and combines the representations of its neighbors with its own. Veličković et al. (2018)Veličković and colleagues pioneered the use of attention-based neighborhood aggregation, in one of the most common GNN variants — Graph Attention Network (GAT). In GAT, every node updates its representation by attending to its neighbors using its own representation as the query. This generalizes the standard averaging or max-pooling of neighbors (Kipf and Welling, 2017; Hamilton et al., 2017), by allowing every node to compute a weighted average of its neighbors, and (softly) select its most relevant neighbors. The work of
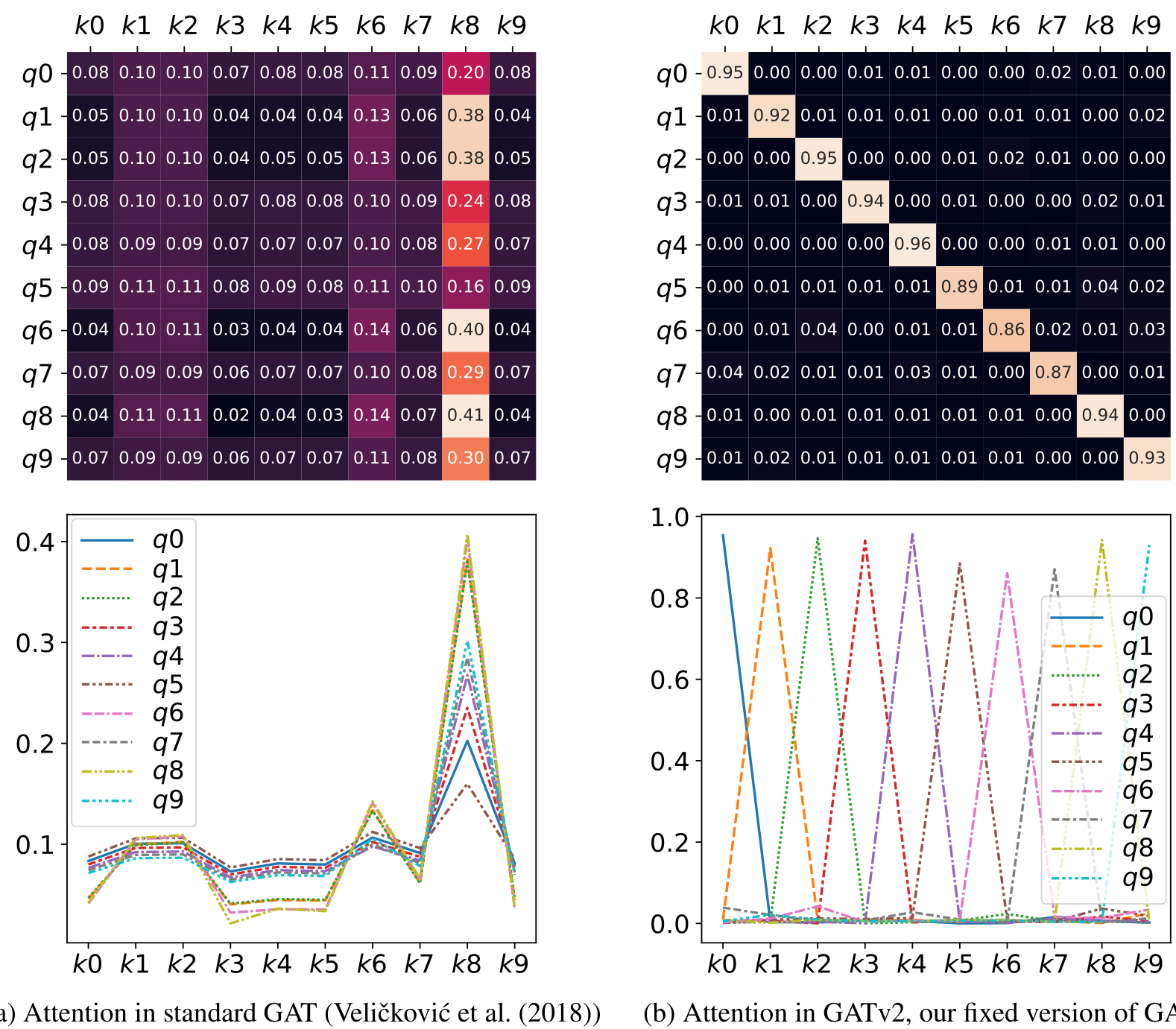
Figure 1: In a complete bipartite graph of “query nodes” {q0,…,q9}q zero through q nine and “key nodes” {k0,…,k9}k zero through k nine: standard GAT (Figure 1a) computes static attention – the ranking of attention coefficients is global for all nodes in the graph, and is unconditioned on the query node. For example, all queries (q0 to q9q zero to q nine) attend mostly to the 8th key (k8k eight). In contrast, GATv2 (Figure 1b) can actually compute dynamic attention, where every query has a different ranking of attention coefficients of the keys.
Veličković et al. (2018)Veličković and colleagues also generalizes the Transformer’s (Vaswani et al., 2017) self-attention mechanism, from sequences to graphs (Joshi, 2020).
Nowadays, GAT is one of the most popular GNN architectures (Bronstein et al., 2021) and is considered as the state-of-the-art neural architecture for learning with graphs (Wang et al., 2019a). Nevertheless, in this paper we show that GAT does not actually compute the expressive, well known, type of attention (Bahdanau et al., 2014), which we call dynamic attention. Instead, we show that GAT computes only a restricted “static” form of attention: for any query node, the attention function is monotonic with respect to the neighbor (key) scores. That is, the ranking (the argsortarg sort) of attention coefficients is shared across all nodes in the graph, and is unconditioned on the query node. This fact severely hurts the expressiveness of GAT, and is demonstrated in Figure 1a.
Supposedly, the conceptual idea of attention as the form of interaction between GNN nodes is orthogonal to the specific choice of attention function. However, Veličković et al.’s (2018)Veličković and colleagues’ original design of GAT has spread to a variety of domains (Wang et al., 2019a; Yang et al., 2020; Wang et al., 2019c; Huang and Carley, 2019; Ma et al., 2020; Kosaraju et al., 2019; Nathani et al., 2019; Wu et al., 2020; Zhang et al., 2020) and has become the default implementation of “graph attention network” in all popular GNN libraries such as PyTorch Geometric(Fey and Lenssen, 2019), DGL(Wang et al., 2019b), and others (Dwivedi et al., 2020; Gordić, 2020; Brockschmidt, 2020).
To overcome the limitation we identified in GAT, we introduce a simple fix to its attention function by only modifying the order of internal operations. The result is GATv2 – a graph attention variant
that has a universal approximator attention function, and is thus strictly more expressive than GAT. The effect of fixing the attention function in GATv2 is demonstrated in Figure 1b.
In summary, our main contribution is identifying that one of the most popular GNN types, the graph attention network, does not compute dynamic attention, the kind of attention that it seems to compute. We introduce formal definitions for analyzing the expressive power of graph attention mechanisms (Definitions 3.1 and 3.2), and derive our claims theoretically (Theorem 1) from the equations of Veličković et al. (2018)Veličković and colleagues. Empirically, we use a synthetic problem to show that standard GAT cannot express problems that require dynamic attention (Section 4.1). We introduce a simple fix by switching the order of internal operations in GAT, and propose GATv2, which does compute dynamic attention (Theorem 2). We further conduct a thorough empirical comparison of GAT and GATv2 and find that GATv2 outperforms GAT across 12 benchmarks of node-, link-, and graph-prediction. For example, GATv2 outperforms extensively tuned GNNs by over 1.4% in the difficult “UnseenProj Test” set of the VarMisuse task (Allamanis et al., 2018)Allamanis and colleagues, without any hyperparameter tuning; and GATv2 improves over an extensively-tuned GAT by 11.5% in 13 prediction objectives in QM9. In node-prediction benchmarks from OGB (Hu et al., 2020)Hu and colleagues, not only that GATv2 outperforms GAT with respect to accuracy — we find that dynamic attention provided a much better robustness to noise.
2 PRELIMINARIES
A directed graph G=(V,E)G equals V, E contains nodes V={1,...,n}V and edges E⊆V×VE, where (j,i)∈Ethe pair j, i in E denotes an edge from a node jj to a node ii. We assume that every node i∈Vi in V has an initial representation hi(0)∈Rd0h i zero of dimension d zero. An undirected graph can be represented with bidirectional edges.
2.1 GRAPH NEURAL NETWORKS
A graph neural network (GNN) layer updates every node representation by aggregating its neighbors’ representations. A layer’s input is a set of node representations {hi∈Rd∣i∈V}h i of dimension d for all i in V and the set of edges EE. A layer outputs a new set of node representations {hi′∈Rd′∣i∈V}h prime i of dimension d prime, where the same parametric function is applied to every node given its neighbors Ni={j∈V∣(j,i)∈E}N i, the set of neighbors j:
hi′=fθ(hi,AGGREGATE({hj∣j∈Ni}))(1)
h prime i equals f theta of h i and the aggregation of its neighbors’ representations h j
The design of ff and AGGREGATEaggregate is what mostly distinguishes one type of GNN from the other. For example, a common variant of GraphSAGE (Hamilton et al., 2017)Hamilton and colleagues performs an element-wise mean as AGGREGATE, followed by concatenation with hih i, a linear layer and a ReLU as ff.
2.2 GRAPH ATTENTION NETWORKS
GraphSAGE and many other popular GNN architectures (Xu et al., 2019; Duvenaud et al., 2015) weigh all neighbors j∈Nij in N i with equal importance (e.g., mean or max-pooling as AGGREGATE). To address this limitation, GAT (Veličković et al., 2018) instantiates Equation (1) by computing a learned weighted average of the representations of NiN i. A scoring function e:Rd×Rd→Re computes a score for every edge (j,i)j, i, which indicates the importance of the features of the neighbor j to the node i:
e(hi,hj)=LeakyReLU(a⊤⋅[Whi∥Whj])(2)
the score e of h i and h j is the leaky ReLU of a transpose times the concatenation of W h i and W h j
where a∈R2d′a, W∈Rd′×dW are learned, and ∥ denotes vector concatenation. These attention scores are normalized across all neighbors j∈Nij in N i using softmax, and the attention function is defined as:
the attention coefficient alpha i j is the softmax of the scores over the neighbors
Then, GAT computes a weighted average of the transformed features of the neighbor nodes (followed by a nonlinearity σsigma) as the new representation of i, using the normalized attention coefficients:
hi′=σj∈Ni∑αij⋅Whj(4)
h prime i equals sigma of the sum over neighbors of alpha i j times W h j
From now on, we will refer to Equations (2) to (4) as the definition of GAT.
3 The Expressive Power of Graph Attention Mechanisms
In this section, we explain why attention is limited when it is not dynamic (Section 3.1). We then show that GAT is severely constrained, because it can only compute static attention (Section 3.2). Next, we show how GAT can be fixed (Section 3.3), by simply modifying the order of operations.
We refer to a neural architecture (e.g., the scoring or the attention function of GAT) as a family of functions, parameterized by the learned parameters. An element in the family is a concrete function with specific trained weights. In the following, we use [n] to denote the set [n]={1,2,…,n}⊂Nthe set of integers from 1 to n.
3.1 The Importance of Dynamic Weighting
Attention is a mechanism for computing a distribution over a set of input key vectors, given an additional query vector. If the attention function always weighs one key at least as much as any other key, unconditioned on the query, we say that this attention function is static:
Definition 3.1 (Static attention). A (possibly infinite) family of scoring functions F⊆(Rd×Rd→R) computes static scoring for a given set of key vectors K={k1,…,kn}⊂Rd and query vectors Q={q1,…,qm}⊂Rd, if for every f∈F there exists a “highest scoring” key jf∈[n] such that for every query i∈[m] and key j∈[n] it holds that f(qi,kjf)≥f(qi,kj). We say that a family of attention functions computes static attention given K and Q, if its scoring function computes static scoring, possibly followed by monotonic normalization such as softmax.
Static attention is very limited because every function f∈F has a key that is always selected, regardless of the query. Such functions cannot model situations where different keys have different relevance to different queries. Static attention is demonstrated in Figure 1a.
The general and powerful form of attention is dynamic attention:
Definition 3.2 (Dynamic attention). A (possibly infinite) family of scoring functions F⊆(Rd×Rd→R) computes dynamic scoring for a given set of key vectors K={k1,…,kn}⊂Rd and query vectors Q={q1,…,qm}⊂Rd, if for any mapping φ:[m]→[n] there exists f∈F such that for any query i∈[m] and any key j=φ(i)∈[n]: f(qi,kφ(i))>f(qi,kj). We say that a family of attention functions computes dynamic attention for K and Q, if its scoring function computes dynamic scoring, possibly followed by monotonic normalization such as softmax.
That is, dynamic attention can select every key φ(i) using the query i, by making f(qi,kφ(i)) the maximal in {f(qi,kj)∣j∈[n]}. Note that dynamic and static attention are exclusive properties, but they are not complementary. Further, every dynamic attention family has strict subsets of static attention families with respect to the same K and Q. Dynamic attention is demonstrated in Figure 1b.
Attending by decaying Another way to think about attention is the ability to “focus” on the most relevant inputs, given a query. Focusing is only possible by decaying other inputs, i.e., giving these decayed inputs lower scores than others. If one key is always given an equal or greater attention score than other keys (as in static attention), no query can ignore this key or decay this key’s score.
3.2 The Limited Expressivity of GAT
Although the scoring function e can be defined in various ways, the original definition of Veličković et al. (2018)Veličković and colleagues (Equation (2)) has become the de facto practice: it has spread to a variety of domains and is now the standard implementation of “graph attention network” in all popular GNN libraries (Fey and Lenssen, 2019; Wang et al., 2019b; Dwivedi et al., 2020; Gordić, 2020; Brockschmidt, 2020).
The motivation of GAT is to compute a representation for every node as a weighted average of its neighbors. Statedly, GAT is inspired by the attention mechanism of Bahdanau et al. (2014)Bahdanau and colleagues and the self-attention mechanism of the Transformer (Vaswani et al., 2017). Nonetheless:
Theorem 1.A GAT layer computes only static attention, for any set of node representations K=Q={h1,…,hn}. In particular, for n>1, a GAT layer does not compute dynamic attention.
Proof. Let G=(V,E) be a graph modeled by a GAT layer with some a and W values (Equations (2) and (3)), and having node representations {h1,…,hn}. The learned parameter a can be written as a
concatenation a=[a1∥a2]∈R2d′a, formed by concatenating a one and a two in two-d-prime space such that a1,a2∈Rd′a one and a two are in d-prime space, and Equation (2) can be re-written as:
e(hi,hj)=LeakyReLU(a1⊤Whi+a2⊤Whj)(5)
e of h i and h j equals Leaky ReLU of, a one transpose W h i plus a two transpose W h j
Since VV is finite, there exists a node jmax∈Vj max in V such that a2⊤Whjmaxa two transpose W h sub j max is maximal among all nodes j∈V (jmax is the jf required by Definition 3.1). Due to the monotonicity of LeakyReLU and softmax, for every query node i∈V, the node jmax also leads to the maximal value of its attention distribution {αij∣j∈V}. Thus, from Definition 3.1 directly, αalpha computes only static attention. This also implies that αalpha does not compute dynamic attention, because in GAT, Definition 3.2 holds only for constant mappings φphi that map all inputs to the same output.
The consequence of Theorem 1 is that for any set of nodes VV and a trained GAT layer, the attention function αalpha defines a constant ranking (argsort) of the nodes, unconditioned on the query nodes i. That is, we can denote sj=a2⊤Whjs j equals a two transpose W h j and get that for any choice of hih i, αalpha is monotonic with respect to the per-node scores {sj∣j∈V}. This global ranking induces the local ranking of every neighborhood NiN i. The only effect of hih i is in the “sharpness” of the produced attention distribution. This is demonstrated in Figure 1a (bottom), where different curves denote different queries (hi).
Generalization to multi-head attentionVeličković et al. (2018)Veličković and colleagues found it beneficial to employ HH separate attention heads and concatenate their outputs, similarly to Transformers. In this case, Theorem 1 holds for each head separately: every head h∈[H]h in H has a (possibly different) node that maximizes {sj(h)∣j∈V}, and the output is the concatenation of HH static attention heads.
3.3 Building Dynamic Graph Attention Networks
To create a dynamic graph attention network, we modify the order of internal operations in GAT and introduce GATv2 – a simple fix of GAT that has a strictly more expressive attention mechanism.
GATv2 The main problem in the standard GAT scoring function (Equation (2)) is that the learned layers W and a are applied consecutively, and thus can be collapsed into a single linear layer. To fix this limitation, we simply apply the a layer after the nonlinearity (LeakyReLU), and the W layer after the concatenation,5 effectively applying an MLP to compute the score for each query-key pair:
GAT <yap-show>(Velicˇkovicˊ et al., 2018)</yap-show><yap-speak>Velicˇkovicˊ and colleagues</yap-speak>:GATv2 (our fixed version):e(hi,hj)=LeakyReLU(a⊤⋅[Whi∥Whj])e(hi,hj)=a⊤LeakyReLU(W⋅[hi∥hj])(6)(7)
For GAT, e equals Leaky ReLU of, a transpose times the concatenation of W h i and W h j. For GAT v 2, e equals a transpose times the Leaky ReLU of, W times the concatenation of h i and h j.
The simple modification makes a significant difference in the expressiveness of the attention function:
Theorem 2.
A GATv2 layer computes dynamic attention for any set of node representations K=Q={h1,…,hn}.K, defined as the set of node representations h one through h n
We prove Theorem 2 in Appendix A. The main idea is that we can define an appropriate function that GATv2 will be a universal approximator (Cybenko, 1989; Hornik, 1991) of. In contrast, GAT (Equation (52)) cannot approximate any such desired function (Theorem 1).
Complexity GATv2 has the same time-complexity as GAT’s declared complexity: O(∣V∣dd′+∣E∣d′)order of the number of nodes times d d prime, plus the number of edges times d prime. However, by merging its linear layers, GAT can be computed faster than stated by Veličković et al. (2018)Veličković and colleagues. For a detailed time- and parametric-complexity analysis, see Appendix G.
4 Evaluation
First, we demonstrate the weakness of GAT using a simple synthetic problem that GAT cannot even fit (cannot even achieve high training accuracy), but is easily solvable by GATv2 (Section 4.1). Second, we show that GATv2 is much more robust to edge noise, because its dynamic attention mechanisms allow it to decay noisy (false) edges, while GAT’s performance severely decreases as noise increases (Section 4.2). Finally, we compare GAT and GATv2 across 12 benchmarks overall. (Sections 4.3 to 4.6 and appendix D.3). We find that GAT is inferior to GATv2 across all examined benchmarks.
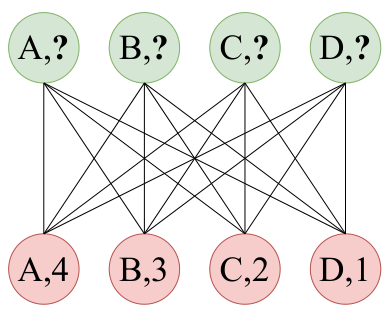
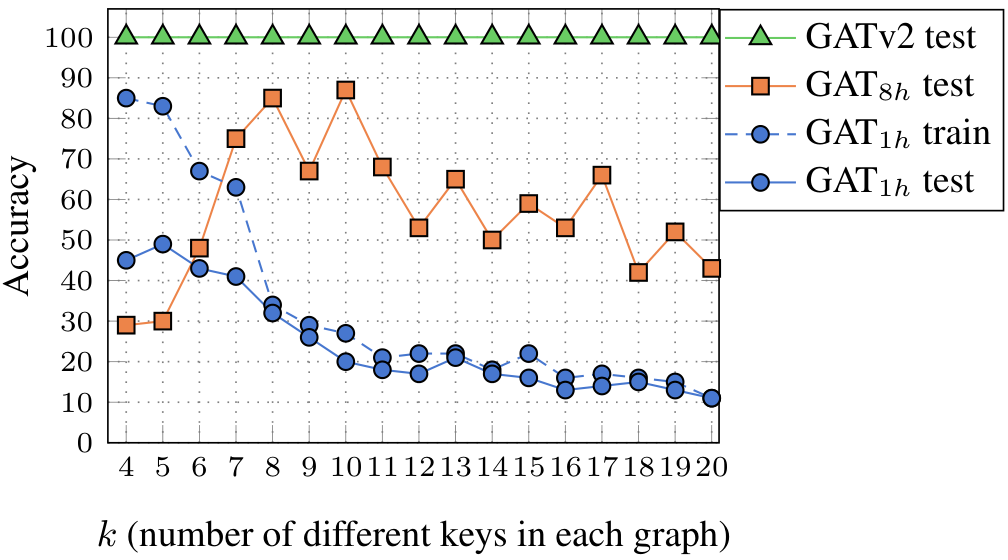
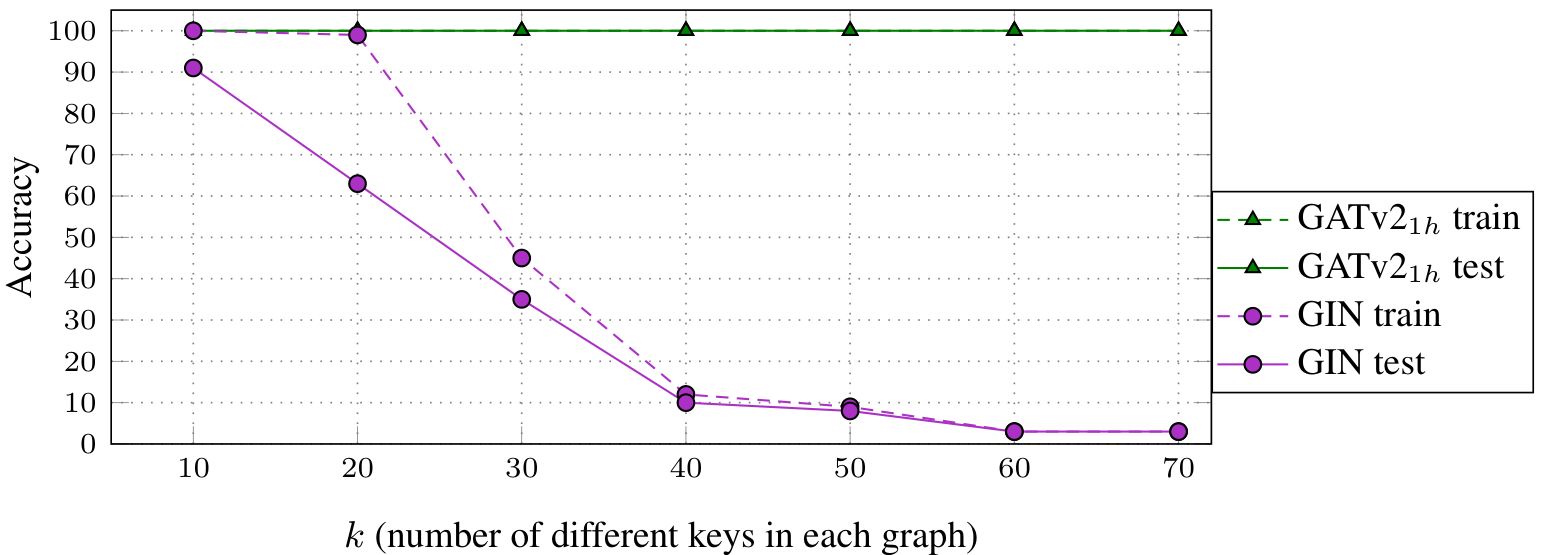
Figure 2: The DictionaryLookup problem of size k=4k equals four: every node in the bottom row has an alphabetic attribute ({A, B, C, ...}) and a numeric value ({1,2,3,...}); every node in the upper row has only an attribute; the goal is to predict the value for each node in the upper row, using its attribute. Figure 3: The DictionaryLookup problem: GATv2 easily achieves 100% train and test accuracies even for k=100k equals one hundred and using only a single head.
Setup When previous results exist, we take hyperparameters that were tuned for GAT and use them in GATv2, without any additional tuning. Self-supervision (Kim and Oh, 2021; Rong et al., 2020a), graph regularization (Zhao and Akoglu, 2020; Rong et al., 2020b), and other tricks (Wang, 2021; Huang et al., 2021)Prior techniques like self-supervision and graph regularization are orthogonal to the contribution of the GNN layer itself, and may further improve all GNNs. In all experiments of GATv2, we constrain the learned matrix by setting W=[W′∥W′]W as the concatenation of W prime with itself, to rule out the increased number of parameters over GAT as the source of empirical difference (see Appendix G.2). Training details, statistics, and code are provided in Appendix B.
Our main goal is to compare dynamic and static graph attention mechanisms. However, for reference, we also include non-attentive baselines such as GCN (Kipf and Welling, 2017), GIN (Xu et al., 2019) and GraphSAGE (Hamilton et al., 2017)G C N, G I N, and Graph SAGE. These non-attentive GNNs can be thought of as a special case of attention, where every node gives all its neighbors the same attention score. Additional comparison to a Transformer-style scaled dot-product attention (“DPGAT”), which is strictly weaker than our proposed GATv2 (see a proof in Appendix E.1), is shown in Appendix E.
4.1 Synthetic Benchmark: DictionaryLookup
The DictionaryLookup problem is a contrived problem that we designed to test the ability of a GNN architecture to perform dynamic attention. Here, we demonstrate that GAT cannot learn this simple problem. Figure 2 shows a complete bipartite graph of 2ktwo k nodes. Each “key node” in the bottom row has an attribute ({A, B, C, ...}) and a value ({1,2,3,...}). Each “query node” in the upper row has only an attribute ({A, B, C, ...}). The goal is to predict the value of every query node (upper row), according to its attribute. Each graph in the dataset has a different mapping from attributes to values. We created a separate dataset for each k={1,2,3,...}k from one, two, three, and so on, for which we trained a different model, and measured per-node accuracy.
Although this is a contrived problem, it is relevant to any subgraph with keys that share more than one query, and each query needs to attend to the keys differently. Such subgraphs are very common in a variety of real-world domains. This problem tests the layer itself because it can be solved using a single GNN layer, without suffering from multi-layer side-effects such as over-smoothing (Li et al., 2018), over-squashing (Alon and Yahav, 2021), or vanishing gradients (Li et al., 2019)over-smoothing, over-squashing, or vanishing gradients. Our code will be made publicly available, to serve as a testbed for future graph attention mechanisms.
Results Figure 3 shows the following surprising results: GAT with a single head (GAT1h)G A T one h failed to fit the training set for any value of kk, no matter for how many iterations it was trained, and after trying various training methods. Thus, it expectedly fails to generalize (resulting in low test accuracy). Using 8 heads, GAT8hG A T eight h successfully fits the training set, but generalizes poorly to the test set. In contrast, GATv2 easily achieves 100% training and 100% test accuracies for any value of kk, and even for k=100k equals one hundred(not shown) and using a single head, thanks to its ability to perform dynamic attention. These results clearly show the limitations of GAT, which are easily solved by GATv2. An additional comparison to GIN, which could not fit this dataset, is provided in Figure 6 in Appendix D.1.
Visualization Figure 1a (top) shows a heatmap of GAT’s attention scores in this DICTIONARY-LOOKUP problem. As shown, all query nodes q0 to q9q zero to q nine attend mostly to the eighth key (k8k eight), and have the same ranking of attention coefficients (Figure 1a (bottom)). In contrast, Figure 1b shows how GATv2 can select a different key node for every query node, because it computes dynamic attention.
The role of multi-head attentionVeličković et al. (2018)Veličković and colleagues found the role of multi-head attention to be stabilizing the learning process. Nevertheless, Figure 3 shows that increasing the number of heads strictly increases training accuracy, and thus, the expressivity. Thus, GAT depends on having multiple attention heads. In contrast, even a single GATv2 head generalizes better than a multi-head GAT.
4.2 ROBUSTNESS TO NOISE
We examine the robustness of dynamic and static attention to noise. In particular, we focus on structural noise: given an input graph G=(V,E)G equals V comma E and a noise ratio 0≤p≤1p between zero and one, we randomly sample ∣E∣×pthe number of edges times p non-existing edges E′E prime from V×V∖Ethe set of possible edges not in E. We then train the GNN on the noisy graph G′=(V,E∪E′)G prime equals V comma E union E prime.
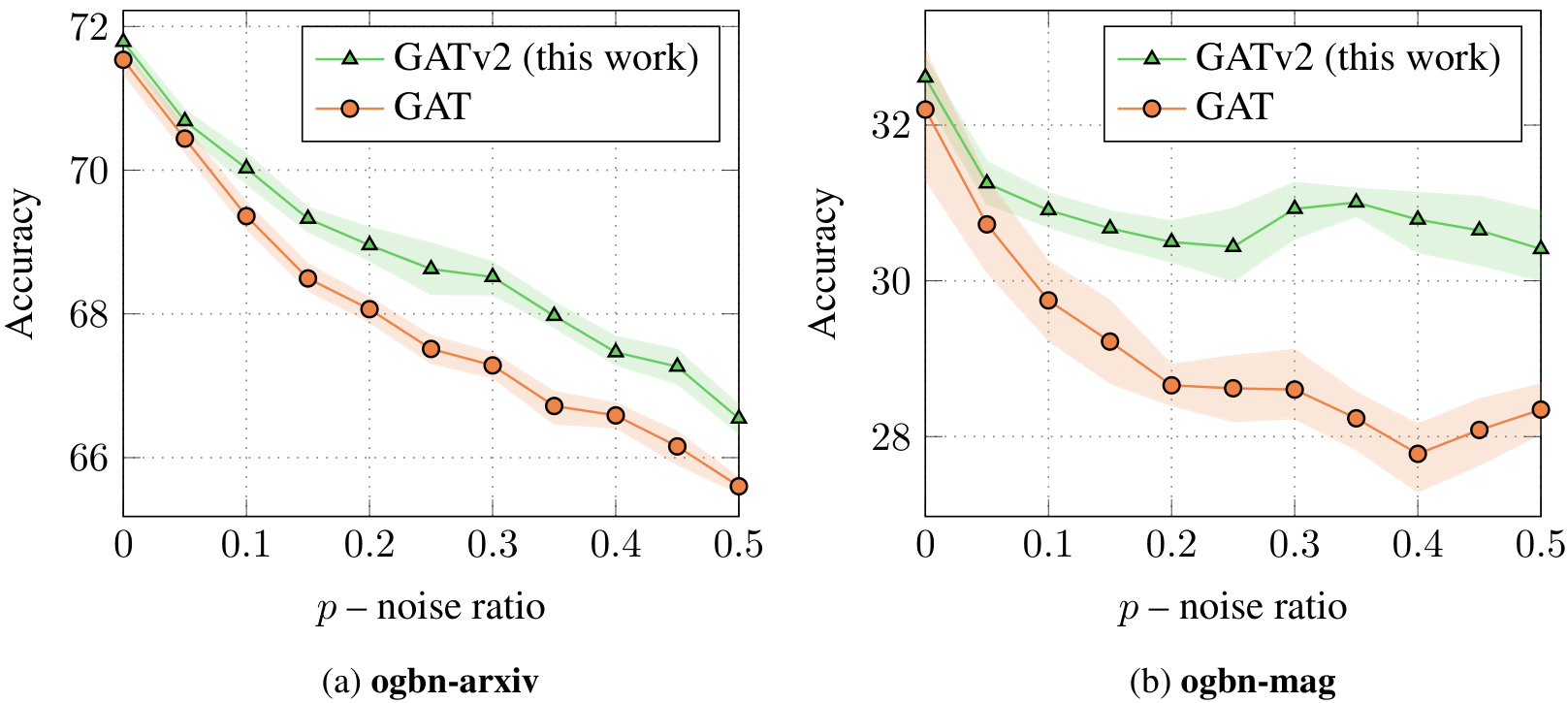
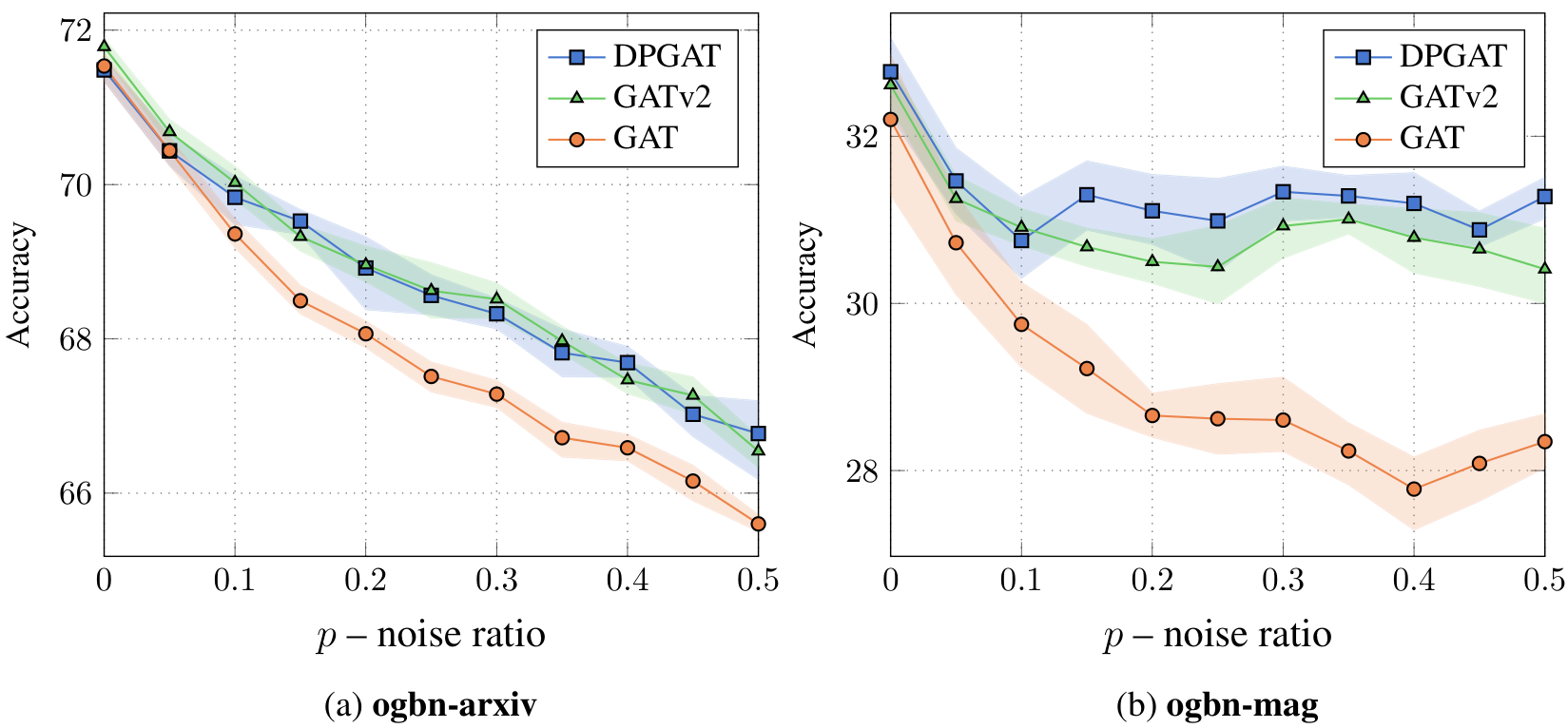
Figure 4: Test accuracy compared to the noise ratio: GATv2 is more robust to structural noise compared to GAT. Each point is an average of 10 runs, error bars show standard deviation.
Results Figure 9 shows the accuracy on two node-prediction datasets from the Open Graph Benchmark (OGB; Hu et al., 2020)O G B as a function of the noise ratio pp. As pp increases, all models show a natural decline in test accuracy in both datasets. Yet, thanks to their ability to compute dynamic attention, GATv2 shows a milder degradation in accuracy compared to GAT, which shows a steeper descent. We hypothesize that the ability to perform dynamic attention helps the models distinguishing between given data edges (EE) and noise edges (E′E prime); in contrast, GAT cannot distinguish between edges, because it scores the source and target nodes separately. These results clearly demonstrate the robustness of dynamic attention over static attention in noisy settings, which are common in reality.
4.3 PROGRAMS: VARMISUSE
Setup VARMISUSE (Allamanis et al., 2018) is an inductive node-pointing problem that depends on 11 types of syntactic and semantic interactions between elements in computer programs.
We used the framework of Brockschmidt (2020)Brockschmidt, who performed an extensive hyperparameter tuning by searching over 30 configurations for every GNN type. We took their best GAT hyperparameters and used them to train GATv2, without further tuning.
Results As shown in Figure 5, GATv2 is more accurate than GAT and other GNNs in the SeenProj test sets. Furthermore, GATv2 achieves an even higher improvement in the UnseenProj test set. Overall, these results demonstrate the power of GATv2 in modeling complex relational problems, especially since it outperforms extensively tuned models, without any further tuning by us.
Published as a conference paper at ICLR 2022
Figure 5: Accuracy (5 runs ± stdev)plus or minus standard deviation over five runs on VARMISUSE. GATv2 is more accurate than all GNNs in both test sets, using GAT’s hyperparameters. † previously reported by Brockschmidt (2020)Brock-shmit, twenty twenty.
Model
SeenProj
UnseenProj
No-Attention
GCN†
87.2±1.5
81.4±2.3
GIN†
87.1±0.1
81.1±0.9
Attention
GAT†
86.9±0.7
81.2±0.9
GATv2
88.0±1.1
82.8±1.7
4.4 Node-Prediction
We further compare GATv2, GAT, and other GNNs on four node-prediction datasets from OGB.
Table 1: Average accuracy (Table 1a) and ROC-AUC (Table 1b) in node-prediction datasets (10 runs ± std)ten runs plus or minus standard deviation. In all datasets, GATv2 outperforms GAT. † – previously reported by Hu et al. (2020)Hu and colleagues, twenty twenty.
(a)
Model
Attn. Heads
ogbn-arxiv
ogbn-products
ogbn-mag
GCN†
0
71.74±0.29
78.97±0.33
30.43±0.25
GraphSAGE†
0
71.49±0.27
78.70±0.36
31.53±0.15
GAT
1
71.59±0.38
79.04±1.54
32.20±1.46
8
71.54±0.30
77.23±2.37
31.75±1.60
GATv2 (this work)
1
71.78±0.18
80.63±0.70
32.61±0.44
8
71.87±0.25
78.46±2.45
32.52±0.39
(b)
ogbn-proteins
72.51±0.35
77.68±0.20
70.77±5.79
78.63±1.62
77.23±3.32
79.52±0.55
Results Results are shown in Table 1. In all settings and all datasets, GATv2 is more accurate than GAT and the non-attentive GNNs. Interestingly, in the datasets of Table 1a, even a single head of GATv2 outperforms GAT with 8 heads. In Table 1b (ogbn-proteins), increasing the number of heads results in a major improvement for GAT (from 70.77 to 78.63), while GATv2 already gets most of the benefit using a single attention head. These results demonstrate the superiority of GATv2 over GAT in node prediction (and even with a single head), thanks to GATv2’s dynamic attention.
4.5 Graph-Prediction: QM9
Setup In the QM9 dataset (Ramakrishnan et al., 2014; Gilmer et al., 2017)Ramakrishnan and colleagues, twenty fourteen; and Gilmer and colleagues, twenty seventeen, each graph is a molecule and the goal is to regress each graph to 13 real-valued quantum chemical properties. We used the implementation of Brockschmidt (2020)Brock-shmit, twenty twenty who performed an extensive hyperparameter search over 500 configurations; we took their best-found configuration of GAT to implement GATv2.
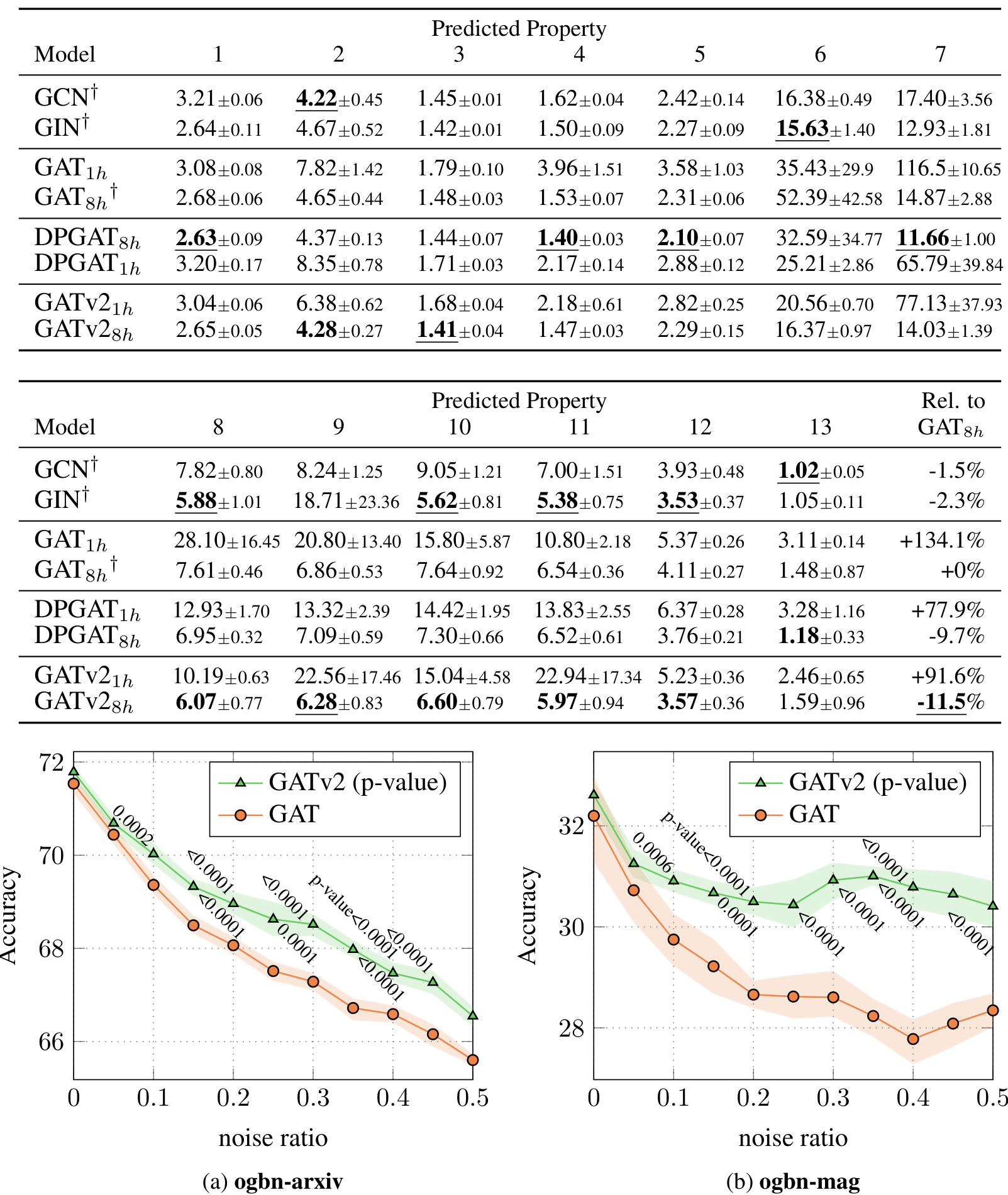
Table 2: Average error rates (lower is better), 5 runs for each property, on the QM9 dataset. The best result among GAT and GATv2 is marked in bold; the globally best result among all GNNs is marked in bold and underline. † was previously tuned and reported by Brockschmidt (2020)Brock-shmit.
Predicted Property
Rel. to
Model
1
2
3
4
5
6
7
8
9
10
11
12
13
GAT
GCN†
3.21
4.22
1.45
1.62
2.42
16.38
17.40
7.82
8.24
9.05
7.00
3.93
1.02
-1.5%
GIN†
2.64
4.67
1.42
1.50
2.27
15.63
12.93
5.88
18.71
5.62
5.38
3.53
1.05
-2.3%
GAT†
2.68
4.65
1.48
1.53
2.31
52.39
14.87
7.61
6.86
7.64
6.54
4.11
1.48
+0%
GATv2
2.65
4.28
1.41
1.47
2.29
16.37
14.03
6.07
6.28
6.60
5.97
3.57
1.59
-11.5%
Results Table 2 shows the main results: GATv2 achieves a lower (better) average error than GAT, by 11.5% relatively. GAT achieves the overall highest average error. In some properties, the non-attentive
GNNs, GCN and GIN, perform best. We hypothesize that attention is not needed in modeling these properties. Generally, GATv2 achieves the lowest overall average relative error (rightmost column).
4.6 Link-Prediction
We compare GATv2, GAT, and other GNNs in link-prediction datasets from OGBthe Open Graph Benchmark.
Table 3: Average Hits@50 (Table 3a) and mean reciprocal rank (MRR) (Table 3b) in link-prediction benchmarks from OGB (10 runs±plus or minusstd). The best result among GAT and GATv2 is marked in bold; the best result among all GNNs is marked in bold and underline. †dagger was reported by Hu et al. (2020)Hu and colleagues.
(a)
ogbl-collab
(b) ogbl-citation2
Model
Attn. Heads
w/o val edges
w/ val edges
No-Attention
GCN†
44.75±1.07
47.14±1.45
80.04±0.25
GraphSAGE†
48.10±0.81
54.63±1.12
80.44±0.10
GAT
GAT1h
39.32±3.26
48.10±4.80
79.84±0.19
GAT8h
42.37±2.99
46.63±2.80
75.95±1.31
GATv2
GATv21h
42.00±2.40
48.02±2.77
80.33±0.13
GATv28h
42.85±2.64
49.70±3.08
80.14±0.71
Results Table 3 shows that in all datasets, GATv2 achieves a higher MRR than GAT, which achieves the lowest MRR. However, the non-attentive GraphSAGE performs better than all attentive GNNs. We hypothesize that attention might not be needed in these datasets. Another possibility is that dynamic attention is especially useful in graphs that have high node degrees: in ogbn-products and ogbn-proteins (Table 1) the average node degrees are 50.5 and 597, respectively (see Table 5 in Appendix C). ogbl-collab and ogbl-citation2 (Table 3), however, have much lower average node degrees – of 8.2 and 20.7. We hypothesize that a dynamic attention mechanism is especially useful to select the most relevant neighbors when the total number of neighbors is high. We leave the study of the effect of the datasets’s average node degrees on the optimal GNN architecture for future work.
4.7 Discussion
In all examined benchmarks, we found that GATv2 is more accurate than GAT. Further, we found that GATv2 is significantly more robust to noise than GAT. In the synthetic DICTIONARYLOOKUP benchmark (Section 4.1), GAT fails to express the data, and thus achieves even poor training accuracy.
In few of the benchmarks (Table 3 and some of the properties in Table 2) – a non-attentive model such as GCN or GIN achieved a higher accuracy than all GNNs that do use attention.
Which graph attention mechanism should I use? It is usually impossible to determine in advance which architecture would perform best. A theoretically weaker model may perform better in practice, because a stronger model might overfit the training data if the task is “too simple” and does not require such expressiveness. Intuitively, we believe that the more complex the interactions between nodes are – the more benefit a GNN can take from theoretically stronger graph attention mechanisms such as GATv2. The main question is whether the problem has a global ranking of “influential” nodes (GAT is sufficient), or do different nodes have different rankings of neighbors (use GATv2).
Veličković, the author of GAT, has confirmed on Twitter6 that GAT was designed to work in the “easy-to-overfit” datasets of the time (2017), such as Cora, Citeseer and Pubmed (Sen et al., 2008)described by Sen and colleagues, where the data might had an underlying static ranking of “globally important” nodes. Veličković agreed that newer and more challenging benchmarks may demand stronger attention mechanisms such as GATv2. In this paper, we revisit the traditional assumptions and show that many modern graph benchmarks and datasets contain more complex interactions, and thus require dynamic attention.
5 RELATED WORK
Attention in GNNs Modeling pairwise interactions between elements in graph-structured data goes back to interaction networks (Battaglia et al., 2016; Hoshen, 2017)Battaglia and colleagues, and Hoshen, and relational networks (Santoro et al., 2017)Santoro and colleagues. The GAT formulation of Veličković et al. (2018)Veličković and colleagues rose as the most popular framework for attentional GNNs, thanks to its simplicity, generality, and applicability beyond reinforcement learning (Denil et al., 2017; Duan et al., 2017)Denil and colleagues, and Duan and colleagues. Nevertheless, in this work, we show that the popular and widespread definition of GAT is severely constrained to static attention only.
Other graph attention mechanisms Many works employed GNNs with attention mechanisms other than the standard GAT’s (Zhang et al., 2018; Thekumparampil et al., 2018; Gao and Ji, 2019; Lukovnikov and Fischer, 2021; Shi et al., 2020; Dwivedi and Bresson, 2020; Busbridge et al., 2019; Rong et al., 2020a; Veličković et al., 2020), and Lee et al. (2018)Lee and colleagues conducted an extensive survey of attention types in GNNs. However, none of these works identified the monotonicity of GAT’s attention mechanism, the theoretical differences between attention types, nor empirically compared their performance. Kim and Oh (2021)Kim and Oh compared two graph attention mechanisms empirically, but in a specific self-supervised scenario, without observing the theoretical difference in their expressiveness.
The static attention of GATQiu et al. (2018)Qiu and colleagues recognized the order-preserving property of GAT, but did not identify the severe theoretical constraint that this property implies: the inability to perform dynamic attention (Theorem 1). Furthermore, they presented GAT’s monotonicity as a desired trait (!) To the best of our knowledge, our work is the first work to recognize the inability of GAT to perform dynamic attention and its practical harmful consequences.
6 CONCLUSION
In this paper, we identify that the popular and widespread Graph Attention Network does not compute dynamic attention. Instead, the attention mechanism in the standard definition and implementations of GAT is only static: for any query, its neighbor-scoring is monotonic with respect to per-node scores. As a result, GAT cannot even express simple alignment problems. To address this limitation, we introduce a simple fix and propose GATv2: by modifying the order of operations in GAT, GATv2 achieves a universal approximator attention function and is thus strictly more powerful than GAT.
We demonstrate the empirical advantage of GATv2 over GAT in a synthetic problem that requires dynamic selection of nodes, and in 11 benchmarks from OGB and other public datasets. Our experiments show that GATv2 outperforms GAT in all benchmarks while having the same parametric cost.
We encourage the community to use GATv2 instead of GAT whenever comparing new GNN architectures to the common strong baselines. In complex tasks and domains and in challenging datasets, a model that uses GAT as an internal component can replace it with GATv2 to benefit from a strictly more powerful model. To this end, we make our code publicly available at GitHub, and GATv2 is available as part of the PyTorch Geometric library, the Deep Graph Library, and TensorFlow GNN. An annotated implementation is available at nn.labml.ai.
ACKNOWLEDGMENTS
We thank Gail Weiss for the helpful discussions, thorough feedback, and inspirational paper (Weiss et al., 2018)by Weiss and colleagues. We also thank Petar Veličković for the useful discussion about the complexity and implementation of GAT.
References
[references omitted]
[references omitted]
[references omitted]
[references omitted]
[references omitted]
A PROOF FOR THEOREM 2
For brevity, we repeat our definition of dynamic attention (Definition 3.2):
Definition 3.2 (Dynamic attention). A (possibly infinite) family of scoring functions F⊂(Rd×Rd→R) computes dynamic scoring for a given set of key vectors K={k1,…,kn}⊂Rd and query vectors Q={q1,…,qm}⊂Rd, if for any mapping φ:[m]→[n] there exists f∈F such that for any query i∈[m] and any key j=φ(i)∈[n]: f(qi,kφ(i))>f(qi,kj). We say that a family of attention functions computes dynamic attention for K and Q, if its scoring function computes dynamic scoring, possibly followed by monotonic normalization such as softmax.
Theorem 2.A GATv2 layer computes dynamic attention for any set of node representations K=Q={h1,…,hn}.
Proof. Let G=(V,E) be a graph modeled by a GATv2 layer, having node representations {h1,…,hn}, and let φ:[n]→[n] be any node mapping [n]→[n]. We define g:R2d→R as follows:
g(x)={10∃i:x=[hi∥hφ(i)]otherwise(8)
Next, we define a continuous function g~:R2d→R that equals to g in only specific n2 inputs:
g~([hi∥hj])=g([hi∥hj]),∀i,j∈[n](9)
For all other inputs x∈R2d, g~(x) realizes to any values that maintain the continuity of g~ (this is possible because we fixed the values of g~ for only a finite set of points).7
Thus, for every node i∈V and j=φ(i)∈V:
1=g~([hi∥hφ(i)])>g~([hi∥hj])=0(10)
If we concatenate the two input vectors, and define the scoring function e of GATv2 (Equation (7)) as a function of the concatenated vector [hi∥hj], from the universal approximation theorem (Hornik et al., 1989; Cybenko, 1989; Funahashi, 1989; Hornik, 1991)according to the universal approximation theorem, e can approximate g~ for any compact subset of R2d.
Thus, for any sufficiently small ϵepsilon (any 0<ϵ<1/2) there exist parameters W and a such that for every node i∈V and every j=φ(i):
eW,a(hi,hφ(i))>1−ϵ>0+ϵ>eW,a(hi,hj)(11)
and due to the increasing monotonicity of softmax:
αi,φ(i)>αi,j(12)
□
The choice of nonlinearity In general, these results hold if GATv2 had used any common non-polynomial activation function (such as ReLU, sigmoid, or the hyperbolic tangent function). The LeakyReLU activation function of GATv2 does not change its universal approximation ability (Leshno et al., 1993; Pinkus, 1999; Park et al., 2021), and it was chosen only for consistency with the original definition of GAT.
B TRAINING DETAILS
In this section we elaborate on the training details of all of our experiments. All models use residual connections as in Veličković et al. (2018)Velitch-ko-vitch and colleagues. All used code and data are publicly available under the MIT license.
B.1 NODE- AND LINK-PREDICTION
We used the provided splits of OGB (Hu et al., 2020)O G B and the Adam optimizer. We tuned the following hyperparameters: number of layers ∈{2,3,6}, hidden size ∈{64,128,256}, learning rate ∈{0.0005,0.001,0.005,0.01}number of layers, either two, three, or six; hidden size, either 64, 128, or 256; learning rate, ranging from five ten-thousandths to one hundredth and sampling method – full batch, GraphSAINT (Zeng et al., 2019)Graph SAINT and NeighborSampling (Hamilton et al., 2017)Neighbor Sampling. We tuned hyperparameters according to validation score and early stopping. The final hyperparameters are detailed in Table 4.
Dataset
# layers
Hidden size
Learning rate
Sampling method
ogbn-arxiv
3
256
0.01
GraphSAINT
ogbn-products
3
128
0.001
NeighborSampling
ogbn-mag
2
256
0.01
NeighborSampling
ogbn-proteins
6
64
0.01
NeighborSampling
ogbl-collab
3
64
0.001
Full Batch
ogbl-citation2
3
256
0.0005
NeighborSampling
Table 4: Training details of node- and link-prediction datasets.
B.2 ROBUSTNESS TO NOISE
In these experiments, we used the same best-found hyperparameters in node-prediction, with 8 attention heads in ogbn-arxiv and 1 head in ogbn-mag. Each point is an average of 10 runs.
B.3 SYNTHETIC BENCHMARK: DICTIONARYLOOKUP
In all experiments, we used a learning rate decay of 0.5, a hidden size of d=128d equals 128, a batch size of 1024, and the Adam optimizer.
We created a separate dataset for every graph size (kk), and we split each such dataset to train and test with a ratio of 80:20. Since this is a contrived problem, we did not use a validation set, and the reported test results can be thought of as validation results. Every model was trained on a fixed value of kk. Every key node (bottom row in Figure 2) was encoded as a sum of learned attribute embedding and a value embedding, followed by ReLU.
We experimented with layer normalization, batch normalization, dropout, various activation functions and various learning rates. None of these changed the general trend, so the experiments in Figure 3 were conducted without any normalization, without dropout and a learning rate of 0.001.
B.4 PROGRAMS: VARMISUSE
We used the code, splits, and the same best-found configurations as Brockschmidt (2020)Brock-shmit, who performed an extensive hyperparameter tuning by searching over 30 configurations for each GNN type. We trained each model five times.
We took the best-found hyperparameters of Brockschmidt (2020)Brock-shmit for GAT and used them to train GATv2, without any further tuning.
B.5 GRAPH-PREDICTION: QM9
We used the code and splits of Brockschmidt (2020)Brock-shmit who performed an extensive hyperparameter search over 500 configurations. We took the best-found hyperparameters of Brockschmidt (2020)Brock-shmit.
for GAT and used them to train GATv2. The only minor change from GAT is placing a residual connection after every layer, rather than after every other layer, which is within the experimented hyperparameter search that was reported by Brockschmidt (2020)Brock-shmit, twenty twenty.
B.6 COMPUTE AND RESOURCES
Our experiments consumed approximately 100 days of GPU in total. We used cloud GPUs of type V100, and we used RTX 3080 and 3090 in local GPU machines.
C DATA STATISTICS
C.1 NODE- AND LINK-PREDICTION DATASETS
Statistics of the OGB datasets we used for node- and link-prediction are shown in Table 5.
Dataset
# nodes
# edges
Avg. node degree
Diameter
ogbn-arxiv
169,343
1,166,243
13.7
23
ogbn-mag
1,939,743
21,111,007
21.7
6
ogbn-products
2,449,029
61,859,140
50.5
27
ogbn-proteins
132,534
39,561,252
597.0
9
ogbl-collab
235,868
1,285,465
8.2
22
ogbl-citation2
2,927,963
30,561,187
20.7
21
Table 5: Statistics of the OGB datasets (Hu et al., 2020)by Hu and colleagues, twenty twenty.
C.2 QM9
Statistics of the QM9 dataset, as used in Brockschmidt (2020)Brock-shmit, twenty twenty are shown in Table 6.
Training
Validation
Test
# examples
110,462
10,000
10,000
# nodes - average
18.03
18.06
18.09
# edges - average
18.65
18.67
18.72
Diameter - average
6.35
6.35
6.35
Table 6: Statistics of the QM9 chemical dataset (Ramakrishnan et al., 2014)by Ram-ah-krish-nan and colleagues, twenty fourteen as used by Brockschmidt (2020)Brock-shmit, twenty twenty.
C.3 VARMISUSE
Statistics of the VARMISUSE dataset, as used in Allamanis et al. (2018)All-ah-man-iss and colleagues, twenty eighteen and Brockschmidt (2020)Brock-shmit, twenty twenty, are shown in Table 7.
Training
Validation
UnseenProject Test
SeenProject Test
# graphs
254360
42654
117036
59974
# nodes - average
2377
1742
1959
3986
# edges - average
7298
7851
5882
12925
Diameter - average
7.88
7.88
7.78
7.82
Table 7: Statistics of the VARMISUSE dataset (Allamanis et al., 2018)by All-ah-man-iss and colleagues, twenty eighteen as used by Brockschmidt (2020)Brock-shmit, twenty twenty.
Figure 6: Train and test accuracy across graph sizes in the DICTIONARYLOOKUP problem. GATv2 easily achieves 100% train and test accuracy even for k=100k equals 100 and using only a single head. GIN (Xu et al., 2019)Xu and colleagues, although considered as more expressive than other GNNs, cannot perfectly fit the training data (with a model size of d=128d equals 128) starting from k=20k equals 20.
D ADDITIONAL RESULTS
D.1 DICTIONARYLOOKUP
Figure 6 shows additional comparison between GATv2 and GIN (Xu et al., 2019)Xu and colleagues in the DICTIONARYLOOKUP problem. GATv2 easily achieves 100% train and test accuracy even for k=100k equals 100 and using only a single head. GIN, although considered as more expressive than other GNNs, cannot perfectly fit the training data (with a model size of d=128d equals 128) starting from k=20k equals 20.
D.2 QM9
Standard deviation for the QM9 results of Section 4.5 are presented in Table 8.
Model
1
2
3
4
5
6
7
GCN†
3.21±0.06
4.22±0.45
1.45±0.01
1.62±0.04
2.42±0.14
16.38±0.49
17.40±3.56
GIN†
2.64±0.11
4.67±0.52
1.42±0.01
1.50±0.09
2.27±0.09
15.63±1.40
12.93±1.81
GAT1h
3.08±0.08
7.82±1.42
1.79±0.10
3.96±1.51
3.58±1.03
35.43±29.9
116.5±10.65
GAT$_{8h}$$
^\dagger$
2.68±0.06
4.65±0.44
1.48±0.03
1.53±0.07
2.31±0.06
52.39±42.58
14.87±2.88
GATv21h
3.04±0.06
6.38±0.62
1.68±0.04
2.18±0.61
2.82±0.25
20.56±0.70
77.13±37.93
GATv28h
2.65±0.05
4.28±0.27
1.41±0.04
1.47±0.03
2.29±0.15
16.37±0.97
14.03±1.39
Model
8
9
10
11
12
13
Rel. to GAT8h
GCN†
7.82±0.80
8.24±1.25
9.05±1.21
7.00±1.51
3.93±0.48
1.02±0.05
-1.5%
GIN†
5.88±1.01
18.71±23.36
5.62±0.81
5.38±0.75
3.53±0.37
1.05±0.11
-2.3%
GAT1h
28.10±16.45
20.80±13.40
15.80±5.87
10.80±2.18
5.37±0.26
3.11±0.14
+134.1%
GAT$_{8h}
$$^\dagger$
7.61±0.46
6.86±0.53
7.64±0.92
6.54±0.36
4.11±0.27
1.48±0.87
+0%
GATv21h
10.19±0.63
22.56±17.46
15.04±4.58
22.94±17.34
5.23±0.36
2.46±0.65
+91.6%
GATv28h
6.07±0.77
6.28±0.83
6.60±0.79
5.97±0.94
3.57±0.36
1.59±0.96
-11.5%
Table 8: Average error rates (lower is better), 5 runs ± standard deviation for each property, on the QM9 dataset. The best result among GAT and GATv2 is marked in bold; the globally best result among all GNNs is marked in bold and underline. † was previously tuned and reported by Brockschmidt (2020)Brockschmidt in twenty twenty.
D.3 PUBMED CITATION NETWORK
We tuned the following parameters for both GAT and GATv2: number of layers $\in \{0, 1, 2\}$, hidden size $\in \{8, 16, 32\}$, number of heads $\in \{1, 4, 8\}$, dropout $\in \{0.4, 0.6, 0.8\}$, bias $\in \{\text{True}, \text{False}\}$, share weights $\in \{\text{True}, \text{False}\}$, use residual $\in \{\text{True}, \text{False}\}$. Table 9 shows the test accuracy (100 runs$\pm$stdev) using the best hyperparameters found for each model.
We tuned the following parameters for both GAT and GAT v 2: number of layers, hidden size, number of heads, dropout, bias, weight sharing, and the use of residuals. Table 9 shows the test accuracy over 100 runs, plus or minus the standard deviation, using the best hyperparameters found for each model.
Table 9: Accuracy (100 runs±stdev) on Pubmed. GATv2 is more accurate than GAT.
Model
Accuracy
GAT
78.1±0.59
GATv2
78.5±0.38
It is important to note that PubMed has only 60 training nodes, which hinders expressive models such as GATv2 from exploiting their approximation and generalization advantages. Still, GATv2 is more accurate than GAT even in this small dataset. In Table 14, we show that this difference is statistically significant (p-value <0.0001p value less than zero point zero zero zero one).
E ADDITIONAL COMPARISON WITH TRANSFORMER-STYLE ATTENTION (DPGAT)
The main goal of our paper is to highlight a severe theoretical limitation of the highly popular GAT architecture, and propose a minimal fix.
We perform additional empirical comparison to DPGAT, which follows Luong et al. (2015)Luong and colleagues and the dot-product attention of the Transformer (Vaswani et al., 2017)by Vaswani and colleagues. We define DPGAT as:
DPGAT (Vaswani et al., 2017):e(hi,hj)=((hi⊤Q)⋅(hj⊤K)⊤)/dk(13)
e of h i, h j is defined as the dot product of h i transpose Q and the transpose of h j transpose K, all divided by the square root of d k
Variants of DPGAT were used in prior work (Gao and Ji, 2019; Dwivedi and Bresson, 2020; Rong et al., 2020a; Veličković et al., 2020; Kim and Oh, 2021), and we consider it here for the conceptual and empirical comparison with GAT.
Despite its popularity, DPGAT is strictly weaker than GATv2. DPGAT provably performs dynamic attention for any set of node representations only if they are linearly independent (see Theorem 3 and its proof in Appendix E.1). Otherwise, there are examples of node representations that are linearly dependent and mappings φphi, for which dynamic attention does not hold (Appendix E.2). This constraint is not harmful when violated in practice, because every node has only a small set of neighbors, rather than all possible nodes in the graph; further, some nodes possibly never need to be “selected” in practice.
E.1 PROOF THAT DPGAT PERFORMS DYNAMIC ATTENTION FOR LINEARLY INDEPENDENT NODE REPRESENTATIONS
Theorem 3.A DPGAT layer computes dynamic attention for any set of node representations K=Q={h1,…,hn}K equals Q equals the set of h one through h n that are linearly independent.
Proof. Let G=(V,E)G equals V, E be a graph modeled by a DPGAT layer, having linearly independent node representations {h1,…,hn}h one through h n. Let φ:[n]→[n]phi from n to n be any node mapping [n]→[n]n to n.
We denote the ith row of a matrix M as Mi.
We define a matrix P as:
Pi,j={10j=φ(i) otherwise (14)
Let X∈Rn×dX in R n by d be the matrix holding the graph’s node representations as its rows:
Published as a conference paper at ICLR 2022
X=———h1h2⋮hn———(15)
Since the rows of XX are linearly independent, it necessarily holds that d≥nd is greater than or equal to n.
Next, we find weight matrices Q∈Rd×dQ and K∈Rd×dand K such that:
(XQ)⋅(XK)⊤=P(16)
To satisfy Equation (16), we choose QQ and KK such that XQ=UX Q equals U and XK=P⊤UX K equals P transpose U where UU is an orthonormal matrix (U⋅U⊤=U⊤⋅U=I)U times U transpose equals the identity matrix.
We can obtain UU using the singular value decomposition (SVD) of XX:
X=UΣV⊤(17)
Since Σ∈Rn×nSigma and XX has a full rank, ΣSigma is invertible, and thus:
XVΣ−1=U(18)
Now, we define QQ as follows:
Q=VΣ−1(19)
Note that XQ=UX Q equals U, as desired.
To find KK that satisfies XK=P⊤UX K equals P transpose U, we use Equation (17) and require:
UΣV⊤K=P⊤U(20)
and thus:
K=VΣ−1U⊤P⊤U(21)
We define:
z(hi,hj)=e(hi,hj)⋅dk(22)
z of h i and h j is defined as e of h i and h j times the square root of d k
Where e is the attention score function of DPGAT (Equation (13)).
Now, for a query ii and a key jj, and the corresponding representations hi,hjh i and h j:
Since XiQ=(XQ)iX i Q equals the i-th row of X Q and XjK=(XK)jand X j K equals the j-th row of X K, we get
z(hi,hj)=(XQ)i⋅((XK)j)⊤=Pi,j(25)
Therefore:
z(hi,hj)={10j=φ(i)otherwise(26)
And thus:
e(hi,hj)={1/dk0j=φ(i)otherwise(27)
To conclude, for every selected query ii and any key j=φ(i)j not equal to phi of i:
e(hi,hφ(i))>e(hi,hj)(28)
and due to the increasing monotonicity of softmax:
αi,φ(i)>αi,j(29)
Hence, a DPGAT layer computes dynamic attention.
In the case that d>nd is greater than n, we apply SVD to the full-rank matrix XX⊤∈Rn×nX X transpose in the set of real n by n matrices, and follow the same steps to construct Q and K.
In the case that Q∈Rd×Rdk and K∈Rd×Rdk and dk>dQ and K are d by d sub k, and d sub k is greater than d, we can use the same Q and K (Equations (19) and (21)) padded with zeros. We define the Q′∈Rd×Rdkey and K′∈Rd×Rdkey as follows:
There are examples of node representations that are linearly dependent and mappings φphi, for which dynamic attention does not hold. First, we show a simple 2-dimensional example, and then we show the general case of such examples.
Figure 7: An example for node representations that are linearly dependent, for which DPGAT cannot compute dynamic attention, because no query vector q∈R2q in R two can “select” h1h one.
Consider the following linearly dependent set of vectors K=Q (Figure 7):
h0h1h2=x^=x^+y^=x^+2y^(32)(33)(34)
where x^ and y^x hat and y hat are the cartesian unit vectors. We define β∈{0,1,2}beta in the set zero, one, two to express {h0,h1,h2} using the same expression:
hβ=x^+βy^(35)
h beta equals x hat plus beta times y hat
Let q∈Qq in Q be any query vector. For brevity, we define the unscaled dot-product attention score as s:
s(q,hβ)=e(q,hβ)⋅dk(36)
s of q and h beta is the attention score e times the square root of d k
Where e is the attention score function of DPGAT (Equation (13)). The (unscaled) attention score between q and {h0,h1,h2} is:
The first term (q⊤Q)(x^⊤K)⊤q transpose Q times x hat transpose K transpose is unconditioned on β, and thus shared for every hβ. Let us focus on the second term β(q⊤Q)(y^⊤K)⊤. If (q⊤Q)(y^⊤K)⊤>0that term is positive, then:
e(q,h2)>e(q,h1)(41)
the attention score for h two is greater than for h one
Otherwise, if (q⊤Q)(y^⊤K)⊤≤0the product of q transpose Q and the transpose of y hat transpose K is less than or equal to zero:
e(q,h0)≥e(q,h1)(42)
Thus, for any query qq, the key h1h one can never get the highest score, and thus cannot be “selected”. That is, the key h1h one cannot satisfy that e(q,h1)e of q comma h one is strictly greater than any other key.
In the general case, let h0,h1∈Rdh zero and h one be non-zero vectors in R d be some non-zero vectors , and λlambda is some scalar such that 0<λ<1zero is less than lambda is less than one.
Consider the following linearly dependent set of vectors:
K=Q={βh1+(1−β)h0∣β∈{0,λ,1}}(43)
For any query q∈Qq in Q and β∈{0,λ,1}beta in the set zero, lambda, one we define:
s(q,β)=e(q,(βh1+(1−β)h0))⋅dk(44)
Where e is the attention score function of DPGAT (Equation (13)).
If (q⊤Q)(h1⊤K−h0⊤K)⊤>0the product of q transpose Q and the transpose of the difference h one transpose K minus h zero transpose K is greater than zero:
e(q,h1)>e(q,hλ)(50)
Otherwise, if (q⊤Q)(h1⊤K−h0⊤K)⊤≤0the product is less than or equal to zero:
e(q,h0)≥e(q,hλ)(51)
Thus, for any query qq, the key hλh lambda cannot be selected. That is, the key hλh lambda cannot satisfy that e(q,hλ)e of q comma h lambda is strictly greater than any other key. Therefore, there are mappings φphi, for which dynamic attention does not hold.
While we prove that GATv2 computes dynamic attention (Appendix A) for any set of node representations K=QK equals Q, there are sets of node representations and mappings φphi for which dynamic attention does not hold for DPGAT. Thus, DPGAT is strictly weaker than GATv2.
E.3 Empirical Evaluation
Here we repeat the experiments of Section 4 with DPGAT. We remind that DPGAT is strictly weaker than our proposed GATv2 (see a proof in Appendix E.1).
F Statistical Significance
Here we report the statistical significance of the strongest GATv2 and GAT models of the experiments reported in Section 4.
Figure 8: Test accuracy compared to the noise ratio: GATv2 and DPGAT are more robust to structural noise compared to GAT. Each point is an average of 10 runs, error bars show standard deviation.
Table 10: Accuracy (5 runs±plus or minusstdev) on VARMISUSE. GATv2 is more accurate than all GNNs in both test sets, using GAT’s hyperparameters. †dagger – previously reported by Brockschmidt (2020).
Model
SeenProj
UnseenProj
No-Attention
GCN†
87.2±1.5
81.4±2.3
GIN†
87.1±0.1
81.1±0.9
Attention
GAT†
86.9±0.7
81.2±0.9
DPGAT
88.0±0.8
81.5±1.2
GATv2
88.0±1.1
82.8±1.7
Table 11: Average accuracy (Table 11a) and ROC-AUC (Table 11b) in node-prediction datasets (10 runs±plus or minusstd). In all datasets, GATv2 outperforms GAT. †dagger – previously reported by Hu et al. (2020).
(a)
(b)
Model
Attn. Heads
ogbn-arxiv
ogbn-products
ogbn-mag
ogbn-proteins
GCN†
0
71.74±0.29
78.97±0.33
30.43±0.25
72.51±0.35
GraphSAGE†
0
71.49±0.27
78.70±0.36
31.53±0.15
77.68±0.20
GAT
1
71.59±0.38
79.04±1.54
32.20±1.46
70.77±5.79
8
71.54±0.30
77.23±2.37
31.75±1.60
78.63±1.62
DPGAT
1
71.52±0.17
76.49±0.78
32.77±0.80
63.47±2.79
8
71.48±0.26
73.53±0.47
27.74±9.97
72.88±0.59
GATv2 (this work)
1
71.78±0.18
80.63±0.70
32.61±0.44
77.23±3.32
8
71.87±0.25
78.46±2.45
32.52±0.39
79.52±0.55
Published as a conference paper at ICLR 2022
Table 12: Average error rates (lower is better), 5 runs ±plus or minus standard deviation for each property, on the QM9 dataset. The best result among GAT, GATv2 and DPGAT is marked in bold; the globally best result among all GNNs is marked in bold and underline. †dagger was previously tuned and reported by Brockschmidt (2020)Brockschmidt in twenty twenty.
Model
1
2
3
4
5
6
7
GCN†
3.21±0.06
4.22±0.45
1.45±0.01
1.62±0.04
2.42±0.14
16.38±0.49
17.40±3.56
GIN†
2.64±0.11
4.67±0.52
1.42±0.01
1.50±0.09
2.27±0.09
15.63±1.40
12.93±1.81
GAT1h
3.08±0.08
7.82±1.42
1.79±0.10
3.96±1.51
3.58±1.03
35.43±29.9
116.5±10.65
GAT$_{8h}$$
^\dagger$
2.68±0.06
4.65±0.44
1.48±0.03
1.53±0.07
2.31±0.06
52.39±42.58
14.87±2.88
DPGAT8h
2.63±0.09
4.37±0.13
1.44±0.07
1.40±0.03
2.10±0.07
32.59±34.77
11.66±1.00
DPGAT1h
3.20±0.17
8.35±0.78
1.71±0.03
2.17±0.14
2.88±0.12
25.21±2.86
65.79±39.84
GATv21h
3.04±0.06
6.38±0.62
1.68±0.04
2.18±0.61
2.82±0.25
20.56±0.70
77.13±37.93
GATv28h
2.65±0.05
4.28±0.27
1.41±0.04
1.47±0.03
2.29±0.15
16.37±0.97
14.03±1.39
Model
8
9
10
11
12
13
Rel. to GAT8h
GCN†
7.82±0.80
8.24±1.25
9.05±1.21
7.00±1.51
3.93±0.48
1.02±0.05
-1.5%
GIN†
5.88±1.01
18.71±23.36
5.62±0.81
5.38±0.75
3.53±0.37
1.05±0.11
-2.3%
GAT1h
28.10±16.45
20.80±13.40
15.80±5.87
10.80±2.18
5.37±0.26
3.11±0.14
+134.1%
GAT$_{8h}
$$^\dagger$
7.61±0.46
6.86±0.53
7.64±0.92
6.54±0.36
4.11±0.27
1.48±0.87
+0%
DPGAT1h
12.93±1.70
13.32±2.39
14.42±1.95
13.83±2.55
6.37±0.28
3.28±1.16
+77.9%
DPGAT8h
6.95±0.32
7.09±0.59
7.30±0.66
6.52±0.61
3.76±0.21
1.18±0.33
-9.7%
GATv21h
10.19±0.63
22.56±17.46
15.04±4.58
22.94±17.34
5.23±0.36
2.46±0.65
+91.6%
GATv28h
6.07±0.77
6.28±0.83
6.60±0.79
5.97±0.94
3.57±0.36
1.59±0.96
-11.5%
Figure 9: Test accuracy and statistical significance compared to the noise ratio: GATv2 is more robust to structural noise compared to GAT. Each point is an average of 10 runs, error bars show standard deviation.
Table 13: Accuracy (5 runs±stdev)plus or minus standard deviation on VARMISUSE. GATv2 is more accurate than all GNNs in both test sets, using GAT’s hyperparameters. †dagger – previously reported by Brockschmidt (2020)Brockschmidt in twenty twenty.
Model
SeenProj
UnseenProj
GAT†
86.9±0.7
81.2±0.9
GATv2
88.0±1.1
82.8±1.7
p-value
0.048
0.049
Table 14: Accuracy (100 runs ±plus or minus stdev) on Pubmed. GATv2 is more accurate than GAT.
Model
Accuracy
GAT
78.1±0.59
GATv2
78.5±0.38
p-value
< 0.0001
Table 15: Average accuracy (Table 15a) and ROC-AUC (Table 15b) in node-prediction datasets (30 runs ±plus or minus std). We report on the best GAT / GATv2 from Table 1.
(a)
Model
ogbn-arxiv
ogbn-products
ogbn-mag
GAT
71.65±0.38
79.04±1.54
32.36±1.10
GATv2
71.93±0.35
80.63±0.70
33.01±0.41
p-value
0.0022
<0.0001
0.0018
(b)
ogbn-proteins
GAT
78.29±1.59
GATv2
78.96±1.19
p-value
0.0349
Table 16: Average Hits@50 (Table 16a) and mean reciprocal rank (MRR) (Table 16b) in link-prediction benchmarks from OGB (30 runs ±plus or minus std). We report on the best GAT / GATv2 from Table 3.
(a)
ogbl-collab
Model
w/o val edges
w/ val edges
GAT
42.24±2.26
46.02±4.09
GATv2
43.82±2.24
49.06±2.50
p-value
0.0043
0.0005
(b)
ogbl-citation2
GAT
79.91±0.13
GATv2
80.20±0.62
p-value
0.0075
Table 17: Average error rates (lower is better), 20 runs ±plus or minus standard deviation for each property, on the QM9 dataset. We report on GAT and GATv2 with 8 attention heads.
Predicted Property
Model
1
2
3
4
5
6
7
GAT
2.74±0.08
4.73±0.40
1.47±0.06
1.53±0.06
2.44±0.60
55.21±42.33
25.36±31.42
GATv2
2.67±0.08
4.28±0.23
1.43±0.05
1.51±0.07
2.21±0.08
16.64±1.17
13.61±1.68
p-value
0.0043
<0.0001
0.0138
0.1691
0.0487
0.0001
0.0516
Predicted Property
Model
8
9
10
11
12
13
GAT
7.36±0.87
6.79±0.86
7.36±0.93
6.69±0.86
4.10±0.29
1.51±0.84
GATv2
6.13±0.59
6.33±0.82
6.37±0.86
5.95±0.62
3.66±0.29
1.09±0.85
p-value
<0.0001
0.0458
0.0006
0.0017
<0.0001
0.0621
G Complexity Analysis
We repeat the definitions of GAT, GATv2 and DPGAT:
GAT <yap-show>(Velicˇkovicˊ et al., 2018)</yap-show><yap-speak>by Velicˇkovicˊ and colleagues</yap-speak>:GATv2 (our fixed version):DPGAT <yap-show>(Vaswani et al., 2017)</yap-show><yap-speak>by Vaswani and colleagues</yap-speak>:e(hi,hj)e(hi,hj)e(hi,hj)=LeakyReLU(a⊤⋅[Whi∥Whj])=a⊤LeakyReLU(W⋅[hi∥hj])=((hi⊤Q)⋅(hj⊤K)⊤)/d′(52)(53)(54)
G.1 Time Complexity
GAT As noted by Veličković et al. (2018)Veličković and colleagues, the time complexity of a single GAT head may be expressed as O(∣V∣dd′+∣E∣d′)big O of, the number of vertices times d d prime, plus the number of edges times d prime. Because of GAT’s static attention, this computation can be further optimized, by merging the linear layer a1 with W, merging a2 with W, and only then compute a{1,2}⊤Whi for every i∈V.
GATv2 require the same computational cost as GAT’s declared complexity: O(∣V∣dd′+∣E∣d′): we denote W=[W1∥W2], where W1∈Rd′×d and W2∈Rd′×d contain the left half and right half of the columns of W, respectively. We can first compute W1hi and W2hj for every i,j∈V. This takes O(∣V∣dd′).
Then, for every edge (j,i), we compute LeakyReLU(W⋅[hi∥hj]) using the precomputed W1hi and W2hj, since W⋅[hi∥hj]=W1hi+W2hj. This takes O(∣E∣d′).
Finally, computing the results of the linear layer a takes additional O(∣E∣d′) time, and overall O(∣V∣dd′+∣E∣d′).
DPGAT also takes the same time. We can first compute hi⊤Q and hj⊤K for every i,j∈V. This takes O(∣V∣dd′). Computing the dot-product (hi⊤Q)(hj⊤K)⊤ for every edge (j,i) takes additional O(∣E∣d′) time, and overall O(∣V∣dd′+∣E∣d′).
G.2 Parametric Complexity
GAT
GATv2
DPGAT
Official
2d′+dd′
d′+2dd′
2ddk+dd′
In our experiments
2d′+dd′
d′+dd′
2dd′
Table 18: Number of parameters for each GNN type, in a single layer and a single attention head.
All parametric costs are summarized in Table 18. All following calculations refer to a single layer having a single attention head, omitting bias vectors.
GAT has learned vector and a matrix: a∈R2d′ and W∈Rd′×d, thus overall 2d′+dd′ learned parameters.
GATv2 has a matrix that is twice larger: W∈Rd′×2d, because it is applied on the concatenation [hi∥hj]. Thus, the overall number of learned parameters is d′+2dd′. However in our experiments, to rule out the increased number of parameters over GAT as the source of empirical difference, we constrained W=[W′∥W′], and thus the number of parameters were d′+dd′.
DPGAT has Q and K matrices of sizes ddk each, and additional dd′ parameters in the value matrix V, thus 2ddk+dd′ parameters overall. However in our experiments, we constrained Q=K and set dk=d′, and thus the number of parameters is only 2dd′.
Footnotes
An annotated implementation of GATv2 is available at nn.labml.ai↩
from torch_geometric.nn.conv.gatv2_conv import GATv2Conv↩
The function g~ is a function that we define for the ease of proof, because the universal approximation theorem is defined for continuous functions, and we only need the scoring function of GATv2 e to approximate the mapping φ in a finite set of points. So, we need the attention function e to approximate g (from Equation 8) in some specific points. But, since g is not continuous, we define g~ and use the universal approximation theorem for g~. Since e approximates g~, e also approximates g in our specific points, as a special case. We only require that g~ will be identical to g in specific n2 points {[hi∥hj]∣i,j∈[n]}. For the rest of the input space, we don’t have any requirement on the value of g~, except for maintaining the continuity of g~. There exist infinitely many such possible g~ for every given set of keys, queries and a mapping φ, but the concrete functions are not needed for the proof. ↩