Classical Sorting Algorithms as a Model of Morphogenesis:
self-sorting arrays reveal unexpected competencies in a minimal model of basal intelligence
Authors: Zhang, T., Goldstein, A., Levin, M.
Affiliations:
*Corresponding author: michael.levin@tufts.edu
Keywords: decentralized intelligence, emergence, sort, minimal models, basal cognition
Abstract
The emerging field of Diverse Intelligence seeks to identify, formalize, and understand commonalities in behavioral competencies across a wide range of implementations. Especially interesting are simple systems that provide unexpected examples of memory, decision-making, or problem-solving in substrates that at first glance do not appear to be complex enough to implement such capabilities. We seek to develop tools to help understand the minimal requirements for such capabilities, and to learn to recognize and predict basal forms of intelligence in unconventional substrates. Here, we apply novel analyses to the behavior of classical sorting algorithms, short pieces of code which have been studied for many decades. To study these sorting algorithms as a model of biological morphogenesis and its competencies, we break two formerly-ubiquitous assumptions: top-down control (instead, showing how each element within a array of numbers can exert minimal agency and implement sorting policies from the bottom up), and fully reliable hardware (instead, allowing some of the elements to be “damaged” and fail to execute the algorithm). We quantitatively characterize sorting activity as the traversal of a problem space, showing that arrays of autonomous elements sort themselves more reliably and robustly than traditional implementations in the presence of errors. Moreover, we find the ability to temporarily reduce progress in order to navigate around a defect, and unexpected clustering behavior among the elements in chimeric arrays whose elements follow one of two different algorithms. The discovery of emergent problem-solving capacities in simple, familiar algorithms contributes a new perspective to the field of Diverse Intelligence, showing how basal forms of intelligence can emerge in simple systems without being explicitly encoded in their underlying mechanics.
Introduction
On their respective time scales, evolutionary and developmental biology require that cognitive capabilities such as memory and goal-directed activity in the face of perturbations originate in proto-cognitive functions that existed long before complex brains came onto the scene
For the purposes of this study, “intelligence” refers (in William James’ sense
Great strides have been made in understanding how complexity can emerge from simple local rules
Diverse Intelligence research includes the use of very minimal models to understand how problem-solving capacities can arise from the interaction of components at various levels
One such system involves the collective behavior of cells during morphogenesis, such as embryonic development, regeneration, metamorphic remodeling, and cancer suppression
What all of these phenomena have in common is the ability of cells (themselves composite, agential materials
A large body of existing work explores the complex behavioral responses and capacities of tissues, cells
Here, we abstract one key property of regulative morphogenesis: the ability to produce an anatomical structure with a precise order of components along one axis. For example, development or metamorphosis results in a tadpole or frog in which all of the organs are placed in a specific order along the anterior-posterior axis (Figure 1). For the purpose of modeling, we are agnostic as to whether this behavior occurs from scratch, such as during embryogenesis, or by unscrambling existing components (such as during metamorphosis and regenerative remodeling).
We abstract this task, undertaken by cells which can rearrange the organs as needed even when starting from highly abnormal initial configurations
To improve the fit between this model and the abilities of regulative development, we break two critical assumptions normally used with sorting algorithms. First, instead of a central algorithm operating on an array of numbers it can see and control in its entirety, we implement a distributed algorithm that is executed, in parallel, by each number (i.e., cell) with local knowledge of its environment. In lieu of a central controller, cells have individual preferences about the ordering between them and their neighbors. Second, we do not assume that each operation succeeds—that is, we (like biology) implement an unreliable substrate, in which some cells are defective and may
not be able to obey when the rules tell them to move. We then quantitatively investigate the ability of these algorithms to sort a array of integers.
Our goals here are: 1) to establish a proof of concept for taking a system which seems simple and well-understood, and for using empirical experiments to identify that system’s novel capabilities, goals, behaviors, and failure modes
Definitions of Terms
| Term | Definition |
|---|---|
| Cell | Basic element to be sorted by the sorting algorithms. Each cell has an integer value property which is used for the comparison during the sorting process. |
| Cell-View Sorting Algorithm | Every cell follows an algorithm for making decisions as to how it can swap positions with neighbors to optimize local monotonicity of the integer values. We call it a cell-view algorithm because state evaluations and move decisions are made from the local perspective of each cell, rather than from the global perspective of a single, omniscient top-down controller. |
| Algotype | Each cell utilizes one of several sorting algorithms to dictate its movement. This “Algotype” is constant for the life of the cell (i.e. roughly equivalent to a fixed genetic or phenotypic identity). |
| Cell Value | The fixed integer value of each cell, which guides how it behaves in any of the algorithms (which are designed to order the cell values in sequence). |
| Experiment | Each sorting process starts from a randomized array of cells and runs until it meets the stop condition. |
| Active Cell | A cell that behaves normally during the sorting process as determined by the embedded cell-view sorting algorithm. |
| Frozen Cell | A cell that does not always move, even though the algorithm tells it to move (representing a damaged cell). There are two types. A “movable” Frozen Cell will not move on its own (will not initiate a move), but other cells are able to move it. An immovable Frozen Cell can neither proactively move itself nor can it be moved by another cell. |
| Delayed Gratification | The ability to temporarily go further away from a goal in order to achieve gains later in the process. None of the algorithms have this capability explicitly coded; where present, it is an emergent property of the algorithm dynamics. |
| Cell Aggregation | A metric of the degree to which the same type of cells cluster together (spatial proximity) during the sorting process when different Algotypes are mixed into the same sorting experiment. |
| Probe | The programming object which is created to monitor and record the status of the sorting process. |
Methods
We developed a sorting algorithm evaluation system and implement the cell-view sorting algorithms in python 3.0. The following sections provide more details about the model of the sorting platform, the structure of the sorting cells, the process of the evaluation, and the experimental test methods. GitHub
Sorting Evaluation System
We designed the sorting evaluation system to consist of 2 parts: the sorting algorithm execution (which performs the sorting on a given array) and the sorting process evaluation (which oversees and analyzes the sorting across trials).
- Sorting algorithm execution
The sorting execution part chooses the specified sorting algorithm to perform the sorting experiments based on the given number of experiments and the Frozen Cells.
The execution subsystem passes a Probe object to each experiment run, and the Probe is designed to record each step of the sorting process.
After the sorting process ends, the information collected by the Probe is stored as a.npyfile. - Sorting process evaluation
The input for the evaluation is configurable including the algorithms to evaluate, the number of Frozen Cells, and the evaluation types. The evaluation process fetches the files based on the specified inputs. The evaluation subsystem picks up the corresponding files based on the inputs that contain the sorting process info. Then the given evaluation is performed for the data in those files.
Traditional Sorting Algorithms
In conventional sorting algorithms, a single top-down controller implements a set of rules to move cells around. The traditional algorithms we used as our baseline were:
-
Bubble Sort
- Start at the beginning of the array.
- Compare the first two elements. If the first element is larger than the second, swap them.
- Move to the next pair of elements (second and third) and perform the same comparison and swap if needed.
- Continue this process, comparing and swapping adjacent elements as you move through the array.
- Each pass through the array will “bubble up” the largest unsorted element to its correct position at the end of the array.
- Repeat these steps for the remaining unsorted portion of the array until no more swaps are needed, indicating that the entire array is now sorted.
-
Insertion Sort
- Start with the first element as the sorted portion (since a single element is always considered sorted).
- Take the first element from the unsorted portion and compare it with the elements in the sorted portion, moving from right to left.
- Insert the selected element into its correct position within the sorted portion by shifting larger elements to the right.
- Move to the next element in the unsorted portion
- Repeat steps 2 - 3 until the entire array is sorted.
-
Selection Sort
- Start with the entire array as the unsorted portion.
- Find the smallest (or largest) element in the unsorted portion.
- Swap this element with the first element in the unsorted portion, effectively moving the smallest (or largest) element to its correct position in the sorted portion.
- Move the boundary between the sorted and unsorted portions one element to the right.
- Repeat steps 2-4 until the entire array is sorted.
Implementation of Cell-View Sorting Algorithm
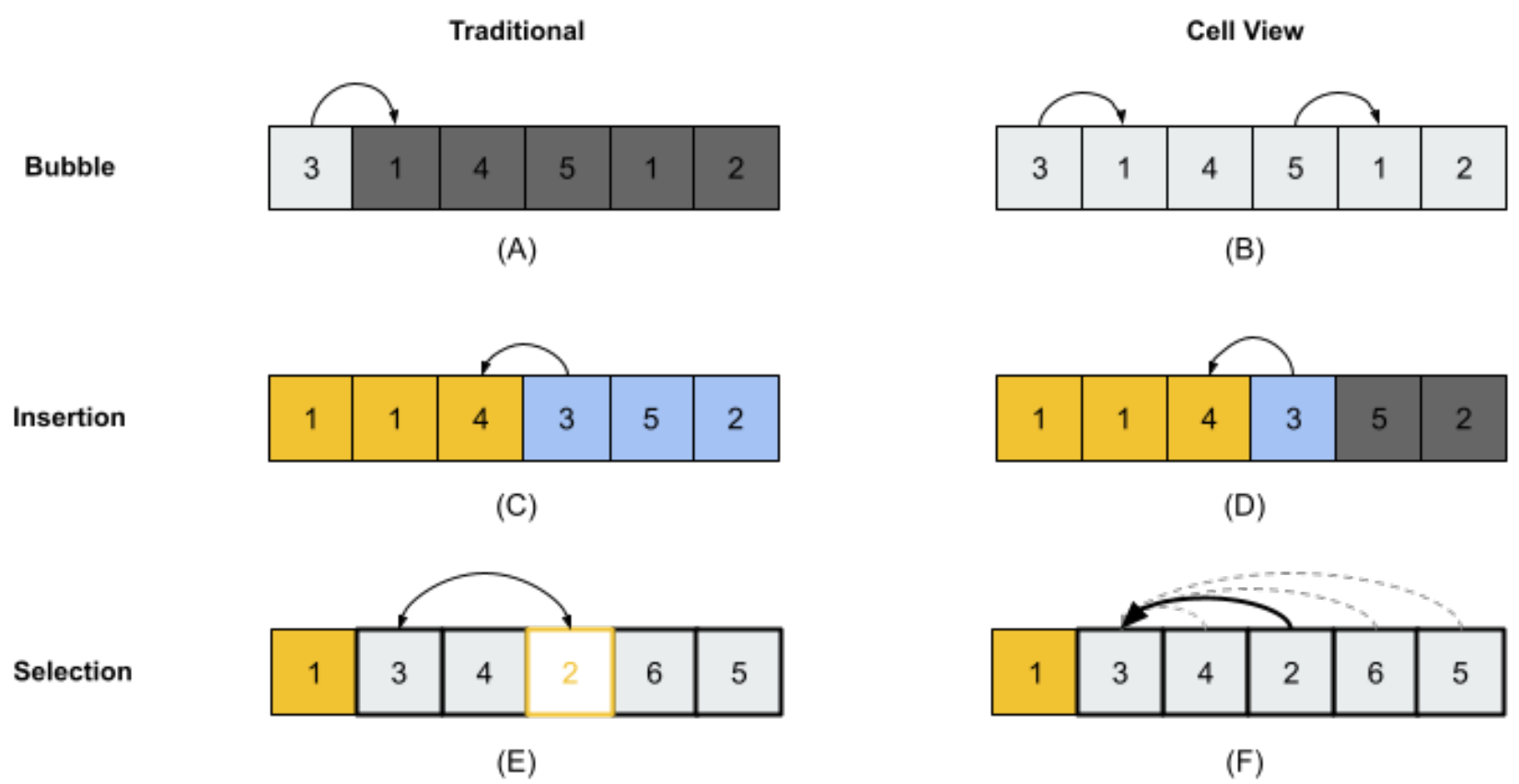
We sought to study the sorting process in a more biologically grounded (distributed) architecture, where each cell is a competent agent implementing local policies. We thus defined three bottom-up versions of common sort algorithms, where actions take place based on the cells’ perspective (view) of their environment within the array. We used multi-thread programming to implement the cell-view sorting algorithms. 2 types of threads were involved during the sorting process: cell threads are used to represent all cells, with each cell represented by a single thread; a main thread is used to activate all the threads and monitor the sorting process. The cell threads were multiple instances of the same sorting class (i.e., each cell had the same Algotype, which determined which of the sorting algorithms that cell used to guide its behavior). Inspired by the 3 traditional sorting algorithms described above, we designed 3 kinds of cell-view sorting algorithms (Figure 2):
-
Cell-view Bubble Sort
- Each cell is able to view and swap with either its left or right neighbor.
- Active cell moves to the left if its value is smaller than that of its left neighbor, or active cell moves to the right if its value is bigger than that of its right neighbor.
-
Cell-view Insertion Sort
- Each cell is able to view all cells to its left, and can swap only with its left neighbor.
- Active cell moves to the left if cells to the left have been sorted, and if the value of the active cell is smaller than that of its left neighbor.
-
Cell-view Selection Sort
- Each cell has an ideal target position to which it wants to move. The initial value of the ideal position for all the cells is the most left position.
- Each cell can view and swap with the cell that currently occupies its ideal position.
- If the value of the active cell is smaller than the value of the cell occupying the active cell’s ideal target position, the active cell swaps places with that occupying cell.
Evaluation Metrics
To quantify the comparison between traditional sorting algorithms and their cell-view versions, we utilized the following metrics to evaluate the performance of those algorithms.
-
Total Sorting Steps, Average and Standard Deviation
We defined each comparison or swap as a sorting step, and we used the Probe to record the total number of sorting steps for each experiment. By comparing the average and standard deviation of the total steps, we derive the efficiency of sorting performance. -
Monotonicity and Monotonicity Error
Monotonicity is the measurement of how well the cells followed monotonic order (either increasing or decreasing). The monotonicity error is the number of cells that violate the monotonic order and break the monotonicity of the cell array. The following formula shows the calculation for the monotonicity error for increasing order sequence. -
Sortedness Value
Sortedness Value is defined as the percentage of cells that strictly follow the designated sort order (either increasing or decreasing). For example, if the array were completely sorted, the Sortedness Value would be 100%. -
Sortedness Delayed Gratification
Delayed Gratification is used to evaluate the ability of each algorithm undertake actions that temporarily increase Monotonicity Error in order to achieve gains later on. Delayed Gratification is defined as the improvement in Sortedness made by a temporarily error-increasing action. The total Sortedness change after a consecutive Sortedness value’s increasing isdelta S increasing . The total Sortedness change after the consecutive Sortedness value decreasing starting from last peak isdelta S decreasing : -
Aggregation Value
In sorting experiments with mixed Algotypes, we measured the extent to which cells of the same Algotype aggregated together (spatially) within the array. We defined Aggregation Value as the percentage of cells with directly adjacent neighboring cells that were all the same Algotype.
Statistical Hypothesis Test Methods
We apply standard statistical hypothesis methods, Z-test and T-test, to evaluate the significance of the differences we report.
Results
We first analyzed the results both from our Cell-View Sorting Algorithms and from the traditional versions of those sorting algorithms, with the goal of determining whether the cell-view versions worked (Figure 3), and comparing measures of efficiency, error tolerance, and Delayed Gratification with those of their canonical counterparts.
Efficiency comparison
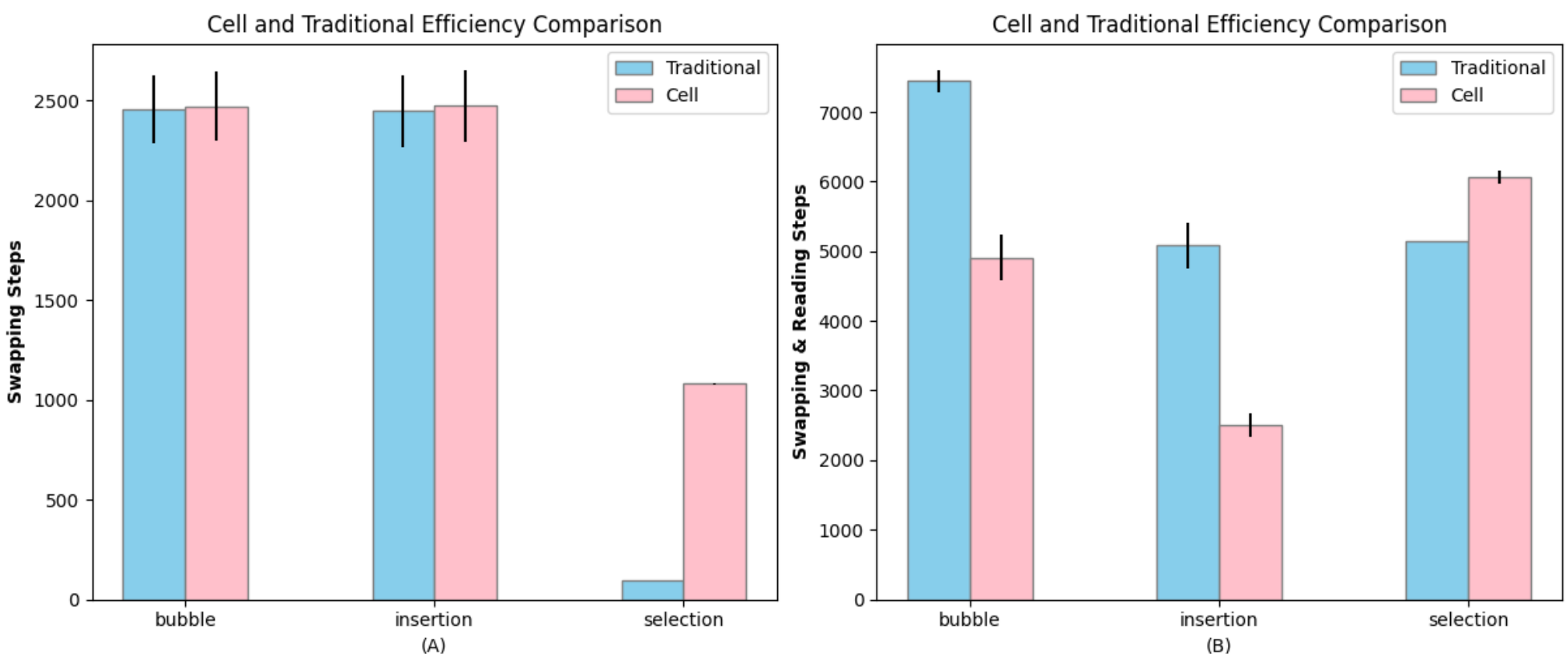
We used the total steps that each algorithm needed to complete the sorting process for 100 elements in each experiment to indicate the efficiency of the algorithm (Figure 4). By repeating the experiments and doing the Z-test over the average steps, we calculated the efficiency difference between traditional sorting and cell-view sorting algorithms.
When we counted only swapping steps, the Z-test statistical values comparing the efficiencies of Bubble and Insertion sort were 0.73 and 1.26
The situation changed when we considered both reading (comparison) and writing (swapping) as costly steps, simulating the metabolic cost of both measurements and actions. In this comparison, the total steps took to complete the sorting process of bottom-up vs. traditional sorting algorithms was decreased by 1.5 and 2.03 times for Bubble and Insertion sort respectively
Error tolerance
To compare the error tolerance of the cell-view sorting algorithms with that of the traditional sorting algorithms, we introduced Frozen Cells into the sorting process. We ran the sorting experiments using different numbers of Frozen Cells and then checked the average final monotonicity errors for the experiments with a given number of Frozen Cells. A higher monotonicity error indicates lower error tolerance (Figure 5). We found that all the cell-view sorting algorithms exhibited less monotonicity error than the traditional versions, from which we conclude that cell-view algorithms have higher error tolerance than the traditional versions.
By comparing the different cell-view algorithms, we saw that with moveable Frozen Cells, the cell-view Bubble sort has the least monotonicity error (average value of 100 experiments was 0 with 1 Frozen Cell, 0.8 with 2 Frozen Cells and 2.64 with 3 Frozen Cells); and the cell-view Selection sort has the highest monotonicity error (average value of 100 experiments was 2.24 with 1 Frozen Cell, 4.36 with 2 Frozen Cells and 13.24 with 3 Frozen Cells). With immovable Frozen Cells, the cell-view Bubble sort has the highest monotonicity error (average value of 100 experiments was 1.91 with 1 Frozen Cell, 3.72 with 2 Frozen Cells and 5.37 with 3 Frozen Cells);
and the cell-view Selection sort has the lowest monotonicity error (average value of 100 experiments was 1.0 with 1 Frozen Cell, 1.96 with 2 Frozen Cells, and 2.91 with 3 Frozen Cells). In conclusion, we can see that both Cell-view and Traditional algorithms have performed error tolerance. The cell-view Selection sort had the highest Error Tolerance with immoveable Frozen Cells, and that the cell-view Bubble sort had higher Error Tolerance with moveable Frozen Cells.
Characterization of Delayed Gratification
Delayed Gratification (DG) is the ability to temporarily go further away from a goal to achieve gains later in the process
A random walker will sometimes move further from its goal and thus exhibit what may look like Delayed Gratification. To demonstrate DG as a problem-solving strategy it must be shown to be performed specifically in the context of barriers, not just part of a random strategy. Thus, we next compared the amount of DG observed for each algorithm in the context of different numbers of Frozen Cells: would the algorithm tend to back-track in Sortedness more when there are more broken cells in its environment? We observed a clear trend of increasing average Delayed Gratification for the Bubble and Insertion sort experiments for both Traditional and Cell-view, and the Cell-view algorithms performed more Delayed Gratification during the sorting process. The average Delayed Gratification for cell-view Bubble sort was 0.24 with 0 Frozen Cell, 0.29 with 1 Frozen Cell, 0.32 with 2 Frozen Cells, and 0.37 with 3 Frozen Cells (all average values are based on 100 repetitions). For Insertion sort, we saw that the average DG value was 1.1 with no Frozen Cell, 1.13 with 1 Frozen Cell, 1.15 with 2 Frozen Cells, and 1.19 with 3 Frozen Cells. However, we did not see a clear trend for either cell-view or traditional Selection sort. This reveals that Bubble and Insertion sort deploy Delayed Gratification in a context-sensitive manner — they do more backtracking when faced with defective cells and are not randomly back-tracking through their space.
Mixed Algotype sorting: analyzing chimeric arrays
We next introduce the notion of an “Algotype”: this refers to one of several discrete algorithms that a cell may be using to control its behavior. Algotype is meant to be distinct from data quantities like a cell’s numerical value or its current position; rather, Algotype reflects a cell’s behavioral tendencies. Our use of bottom-up (distributed) control in the sort process allowed a new kind of experiment: a chimeric array in which different cells use different policies to achieve their objectives, analogous to biological experiments in which cells with different genetics or cell types were mixed in the same body
Algotype explicitly; because the Algotype is a meta-property not addressed in any way in the algorithm itself, its consequences only become evident through the cells’ behavior over time.
At the beginning of these experiments, we randomly assigned one of the three different Algotypes to each of the cells, and began the sort as previously, allowing all the cells to move based on their Algotype (i.e. their individual sorting algorithm). The process was considered to be completed when the Sortedness Value of the array stopped changing for several time steps.
The first observation from these experiments was that all of the Algotype combinations can completely sort the array (Figure 8A, blue lines), demonstrating that components with different policies but the same goal can be mixed in the same collective without abrogating the ability to complete the system-level task.
We next checked the efficiency: do chimeric arrays function as efficiently as homogenous ones? We compared the number of swapping steps in mixed-Algotype experiments with those required to reach sorted state in experiments with a single Algotype. The average steps to complete a pure cell-view Bubble sort was 2448.8
We next looked for unexpected behaviors at the level of individual cells and groups of cells (corresponding to chimeric tissues within an organism) by examining the spatial location of cells with different Algotypes. Specifically, we computed the tendency of individual Algotypes to cluster together within the array as a way to determine if the Algotype has any influence on how those cells travel throughout the morphological space
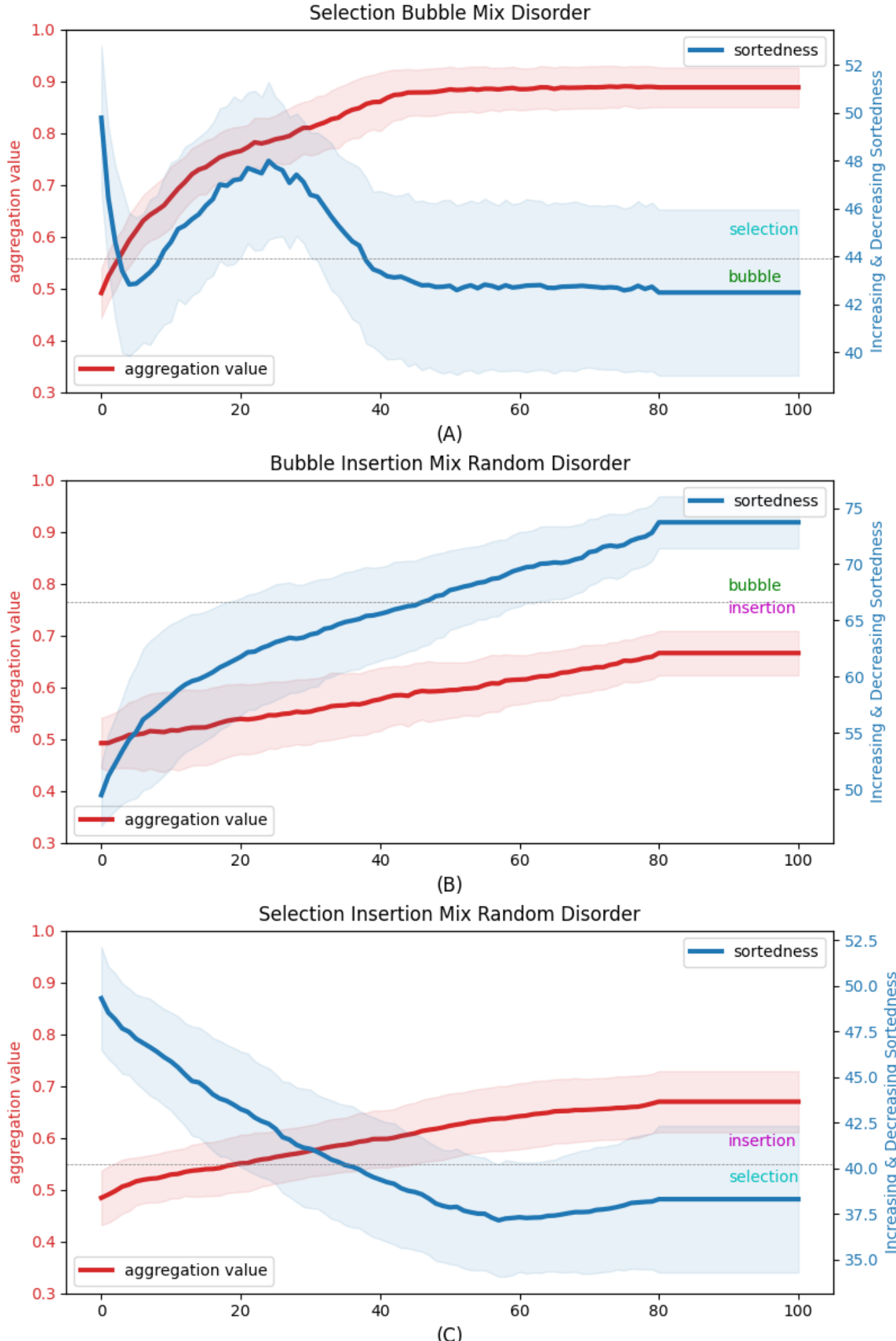
As a negative control, we first ran the experiments using Algotypes that were in fact identical algorithms, as a sanity check to exclude the presence of irrelevant factors in the code (Figure 8B, light pink line). We found that the peak Aggregation Value of the Bubble-Insertion mix was 0.61 (std dev 0.04, N=100), the peak Aggregation Value of the Bubble-Selection mix was 0.65 (std dev 0.05, N=100), and the peak Aggregation Value of the Insertion-Selection mix was 0.57 (std dev 0.04, N=100) (Figure 8A), revealing the baseline that corresponds to no significant aggregation (just random assortment) among arbitrary elements following precisely the same algorithm.
However, when we analyzed the aggregation values in arrays with chimeric Algotypes (consisting of cells using distinct algorithms to guide their behavior), we observed a remarkable
and unexpected effect (dark red lines in Figure 8A). At the beginning, the aggregation was 0.5 in all cases, as befits the random assignment of Algotypes to cells. At the end, they were also 0.5 because the final state is a fully-ordered array, and the random assignment of Algotypes to initial values means that is impossible to maintain non-random Algotype assortment when sorting on the cells’ values (which are randomly related to their Algotype). However, during the sorting process itself, we observed a significant
Why does this happen? Based on the above data on algorithm efficiencies, we first hypothesized that cells with a more efficient Algotype would move to the desired positions first, and as the sort continues, the cells with less efficient Algotypes would “catch up” and move the aggregated cells to their final position, splitting up the initial clusters. This hypothesis predicts that the aggregation is entirely due to differences in the Algotypes’ efficiency. On the other hand, there could be a more general phenomenon at play. To analyze this, we performed similar experiments as above but allowed assignment of duplicated values to cells (100 cells with values ranging from 1 to 10, guaranteeing duplicated occurrences of 10 cells for each value randomly distributed in the initial string). Thus, there was no explicit reason for one cell of value “5” (for example) to appear before or after another cell of value “5” by the time the whole array was sorted. In other words, this version of the experiment allows any clustering to be maintained through to the end of the sorting process because a set of numbers could now be at the correct position in terms of their value and yet be arranged in any degree of clustering according to Algotype within that region (Figure 8E).
We observed that the Aggregation Values rose and did not decrease for the Bubble-Selection mix and the Insertion-Selection chimeric arrays. The average final Aggregation Values for Bubble-Selection and Insertion-Selection mixes were 0.65 and 0.7 (repeated 100 times), which is higher than the highest Aggregation Values of Bubble-Selection and Insertion-Selection mixes with non-duplicate values. This suggests that the efficiency hypothesis can be the explanation for the segregation, because the Selection algorithm is more efficient than Bubble and Insertion while the efficiency is similar between Bubble and Insertion based on our previous analysis.
The experiments in which repeated cell values are allowed also enabled us to ask another question. If we release the pressure of needing to be numerically sorted at the end, how high would the aggregation go? In the unique-value experiments, cells clustered with their same Algotype inevitably eventually get pulled apart at the end to establish the correct final sort order. But, if there were multiple versions of each value with different Algotypes, they could remain next to each other while the whole cluster was in its numerically-proper position. Thus, we could see how high the natural tendency for emergent aggregation is, when not artificially limited by the explicit algorithm’s need to sort the values. We performed these experiments (Figure 8D) and observed maximal levels of 0.69, 0.63, and 0.71 in experiments mixing Bubble and Selection, Bubble and Insertion, Selection and Insertion respectively. The maximum segregation occurred at 100, 13, and 100 percent of the way through the process for Bubble and Selection, Bubble and Insertion, Selection. This illustrates how the explicit goals of a mechanism, and its emergent behaviors, can
be tested separately, and shows the ability for these emergent behaviors to aim for a specific parameter value (e.g., a segregation value of 0.69, not simply “maximize segregation”).
The availability of chimeric arrays gave us one more interesting opportunity: what happens when the two different Algotypes are at cross-purposes—that is, they do not have the same goal? This corresponds to biological problems such as chimeras made of animals with different target morphologies
Discussion
Morphogenesis - the self-assembly of complex anatomies during development or regeneration - can be understood as collective behavior of cells traversing morphospace
We analyzed three such algorithms in their classical form, as well as in a new implementation where we discarded two ubiquitous assumptions in favor of more bio-realistic scenarios. First, instead of top-down algorithms that control an entire process as a single agent with a single algorithm (behavioral policy), we implemented the same algorithms from the cell’s-eye view, as a local, distributed system in which each cell has preferences for what neighbors it will have, and has some capacity to move around in order to implement those preferences
perspective is implemented in many examples
Second, we introduced the notion of damaged or malfunctioning cells that cannot move even when the algorithm says they should. While unreliable computing is an existing field
We evaluated the Sortedness of the input array as a measure of the traversal of the algorithm through its problem space, and performed experiments which illustrate how even minimal, deterministic systems can be tested for novel behavioral competencies. First, we found that a cell-level version of algorithm does, in fact, work: it completes the task. When counting the cost of both taking measurements and making moves (for each cell), two of the three cell-view algorithms are actually significantly more efficient as distributed agents than as classical top-down algorithms.
Next, we assayed an important aspect of intelligence: the ability to, when faced with a Frozen Cell, go around it in a manner that temporarily takes one further from the goal (Delayed Gratification)
This is especially significant because our algorithms are deterministic; there was no stochasticity in the algorithms, as might typically be assumed to be needed to avoid local minima. In addition, our cell-view algorithms contained no explicit steps for what to do in case of a disobeying cell, or even any steps for assaying whether any of their actions have had the desired effect in the first place. In other words, our cells’ algorithms were purely open-loop with no feedback. The fact that our systems nonetheless exhibited implicit goal-seeking with Delayed Gratification highlights two paths to robust biological goal-seeking: stochasticity or distributed components with fault-tolerance. While our simulations here only studied the latter, in future work we plan to investigate how behavior changes when both techniques can be utilized simultaneously.
We think it remarkable that these simple algorithms have the capacity to solve unexpected problems in their space, given that it is not explicitly encoded in the algorithm itself, which has no “metacognitive” steps that monitor the sorting progress. Indeed, the lack of explicit algorithmic steps to monitor improvements in Sortedness may well be a key benefit, because otherwise the algorithm may not have been allowed wander backwards when appropriate (i.e., in some cases,
leaving explicit control out of the algorithm may enable greater problem-solving capacity). We believe these results, like the maze navigation seen by microbial cells and even simple chemical droplets
Lastly, we note that the use of bottom-up distributed algorithms allows the testing of something that is impossible in the classic version: a chimeric scenario in which some cells utilize a different sort algorithm than other cells. Chimerism at different scales
To begin to address this issue, we define the notion of the Algotype, referring to the behaviors of a given cell under various circumstances. We intend this concept to be significantly different from genotype (specification of the explicitly observable hardware) and from phenotype (outcomes that can be detected in a single observation, such as geometric or physiological states and properties). Note that in denoting the time-extended “personality” of cells, the Algotype consists of two components: the expected behavior overtly encoded in the algorithm (the sorting), and possible emergent tendencies not obvious from the mechanics and not explicitly assigned (e.g., the clustering). Thus, Algotypes include behavioral tendencies (such as preferring to associate with their “kin” during their journey through morphospace) that may not be explicitly encoded anywhere in the algorithm and can only observed as a holistic dataset encompassing many scenarios and situations
We found that chimeric arrays consisting of distinct Algotypes still manage to get sorted; thus, there is no need for each cell to be following the same algorithm as long as they have the same goal. However, if they are set to cross-purposes (one sorts for increasing, and the other sorts for decreasing), they reach a dynamic equilibrium at a mixed, intermediate state in which the large-scale demographics of the array (with respect to Algotype) no longer changes, but the individual cells can still move (akin to extensive biological turnover at the molecular and cellular scale while the large-scale anatomy is maintained over years).
This is, as far as we know, the only model that implies a prediction on what will happen when, for example, different species’ stem cells (neoblasts) are mixed within one flatworm body. Given that each set of stem cells knows how to undergo division and metamorphosis until a specific head shape is completed, it is entirely unclear what will happen in a chimeric worm: will one type be dominant over the other, or will an intermediate shape result, or will there be endless remodeling because neither set of cells ever reaches its stop condition with respect to the morphology? Our
model showed that despite no explicit affordance made for this scenario in the algorithm, the sort process included many islands within each array where cells of similar Algotypes clustered together within the space of the overall array. This suggests the testable hypothesis that what will occur in a chimeric biological body is the establishment of a set of tissue-level islands, each of which has the identity of one of the parent species (a patchwork of local neighborhoods that possess a tissue-wide but not organism-wide identity). Because our model did not include explicit mechanisms for cells to behave differently with neighbors of different Algotypes, we suggest that this biological clustering should occur even in the absence of, for example, distinct adhesion molecules present on the cells of different genomes or any other hardware-encoded mechanisms for cell sorting.
Finally, we found a most unexpected behavior in these chimeras. During the sorting process, cells with similar Algotypes (and thus the same sorting behaviors) tended to aggregate together spatially within the array. Eventually they are pulled apart by the necessity to sort themselves according to their positional (numerical) value (rather than by algorithm type), but before that happens, they act as though they have a strong affinity for each other despite the fact that the algorithm says nothing about aggregating, and has no explicit provision for a cell determining the Algotype of any given neighbor (or itself). We conclude that even very simple algorithms can have novel behaviors that are not explicitly encoded in their formal policies and are extremely hard to predict ahead of time. We also suggest that this simple model can be used to ask basic questions about large-scale outcomes in chimeric systems in which components have different explicit and implicit Algotypes. These kinds of analyses can begin to provide principled answers to currently open questions in biology, such as how to predict the morphogenetic outcomes in cellular chimeras consisting of different species’ cells or engineered components that extend functional reach outside the standard body envelops
By allowing repeated digits, we were able to partially dissociate the pressures of the explicit algorithm (to sort elements based on numerical value) from the tendencies of the emergent aspect of the Algotype (to cluster with like-minded elements within the string). Existing real-world biological examples of releasing sub-agents from explicit control, to ask what they would do if allowed, include the engineering of biobots. It has recently been shown that un-modified, genetically-normal cells self-assemble into constructs with novel behaviors when freed from the instructive influence of their neighbors
There is no magic here, of course: everything that happens is, in some way, a consequence of the rules being followed. In the same way, truly cognitive behavior of living systems must be consistent with the physics of their smallest components. However, while such behaviors do not contradict the laws of physics of their world and can be explained after they are observed, they often require a different set of conceptual tools to effectively predict and exploit them than physics and chemistry
can give rise to unexpected emergent behaviors, emphasizing the need to be able to predict and control the properties that such novel behaviors actively seek to maximize.
This model can be expanded in numerous ways. For example, what happens with cells that are not permanently broken, but have the ability to unfreeze given specific (or merely repeated) nudges by their neighbors? Also, we plan to investigate how general these findings are to algorithms for 2-dimensional ordering problems and others. Another interesting direction would be to mix distributed and top-down controls—to monitor the behavior of a classical algorithm working on an agential material that also moves in ways that it was not instructed to. This is the situation in biology, and the evolutionary and cognitive impacts of an agential medium are just beginning to be understood
One limitation of the current analysis is that we looked at only one emergent behavior (aggregation); other interesting things could be happening that we do not yet know to test for, even in this system. More broadly, we believe it is necessary to develop frameworks for looking for novel competencies in systems, with an increased emphasis on broad, unbiased analyses to help human scientists find those goal-directed behaviors which our cognitive biases do not readily facilitate.
We suggest that the study of these kinds of dynamics is potentially of broad significance. In both science and everyday life, we deal with a wide range of systems along the spectrum stretching from passive matter (and mechanisms made thereof) to the complex metacognitive capacities of adult human beings
Indeed, this problem has only gotten thornier with time. During the early days of computers, we could accurately treat machines as passive (non-agentic) and humans as smart. However, with improvements in bioengineering and AI, it is becoming harder and harder to rely on such simple heuristics
Classical thinkers such as
utilizing an objectively observable 3rd person perspective in order to distinguish these highly tractable questions from the thorny debates of 1st-person consciousness
Minimal chemical systems such as as active matter are being explored
Acknowledgements:
We thank David Ackley, Wesley Clawson, Franz Kuchling, and Julia Poirier for helpful comments on the project and manuscript. M.L. gratefully acknowledges support of the John Templeton Foundation via grant 62212. A.G. gratefully acknowledges the support of Astonishing Labs.
Figure Legends
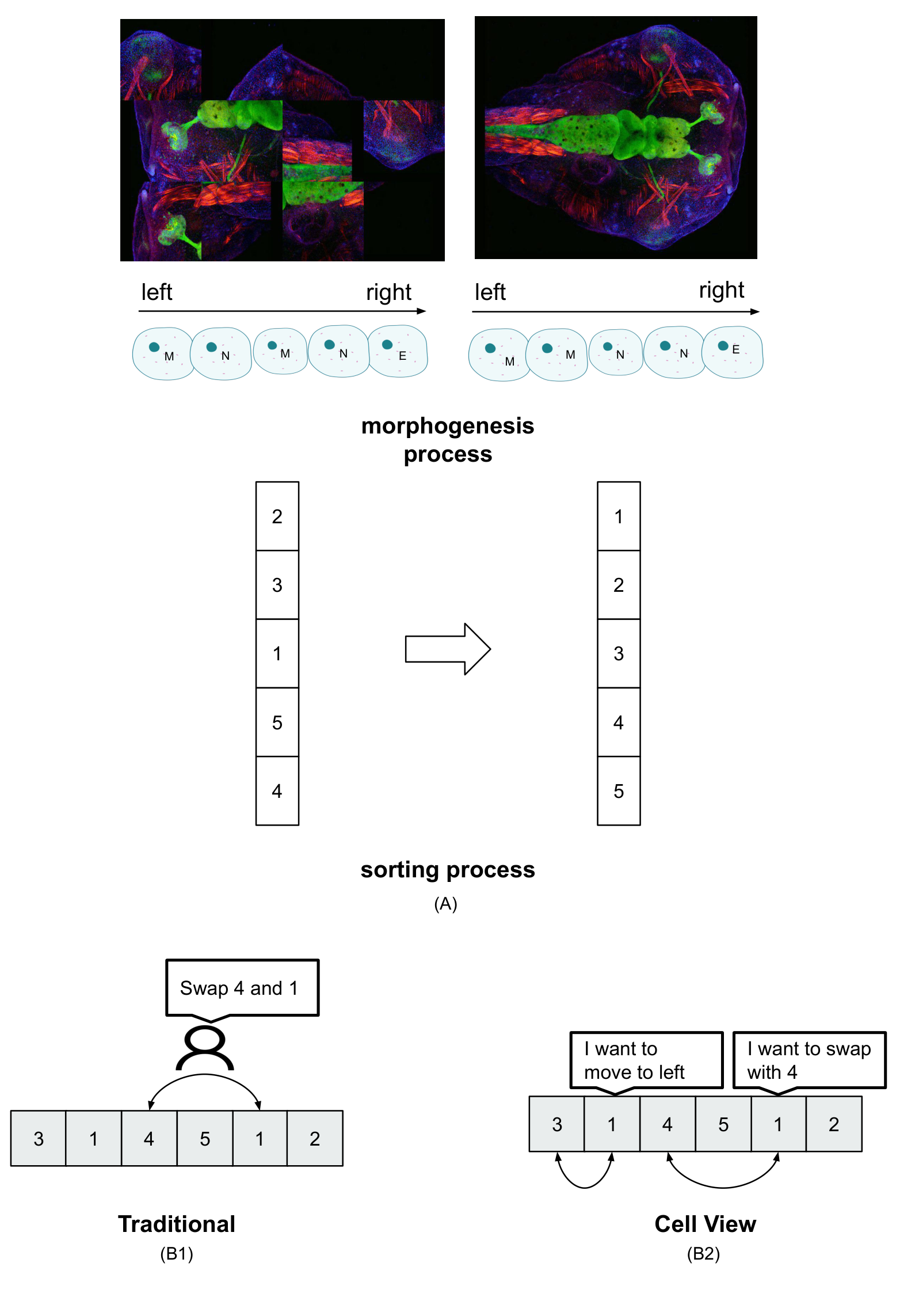
to implement along the anterior-posterior axis). Biologically, this corresponds to the tissue identity (eye, brain, nostril, etc.) that determines which neighbors each type of tissue expects to find, and thus set the stop condition for remodeling once those neighbor relations are attained. (A) The process of morphogenesis during development, repair, and metamorphosis included cells relocating to positions at which movement would cease (as determined for a given species)
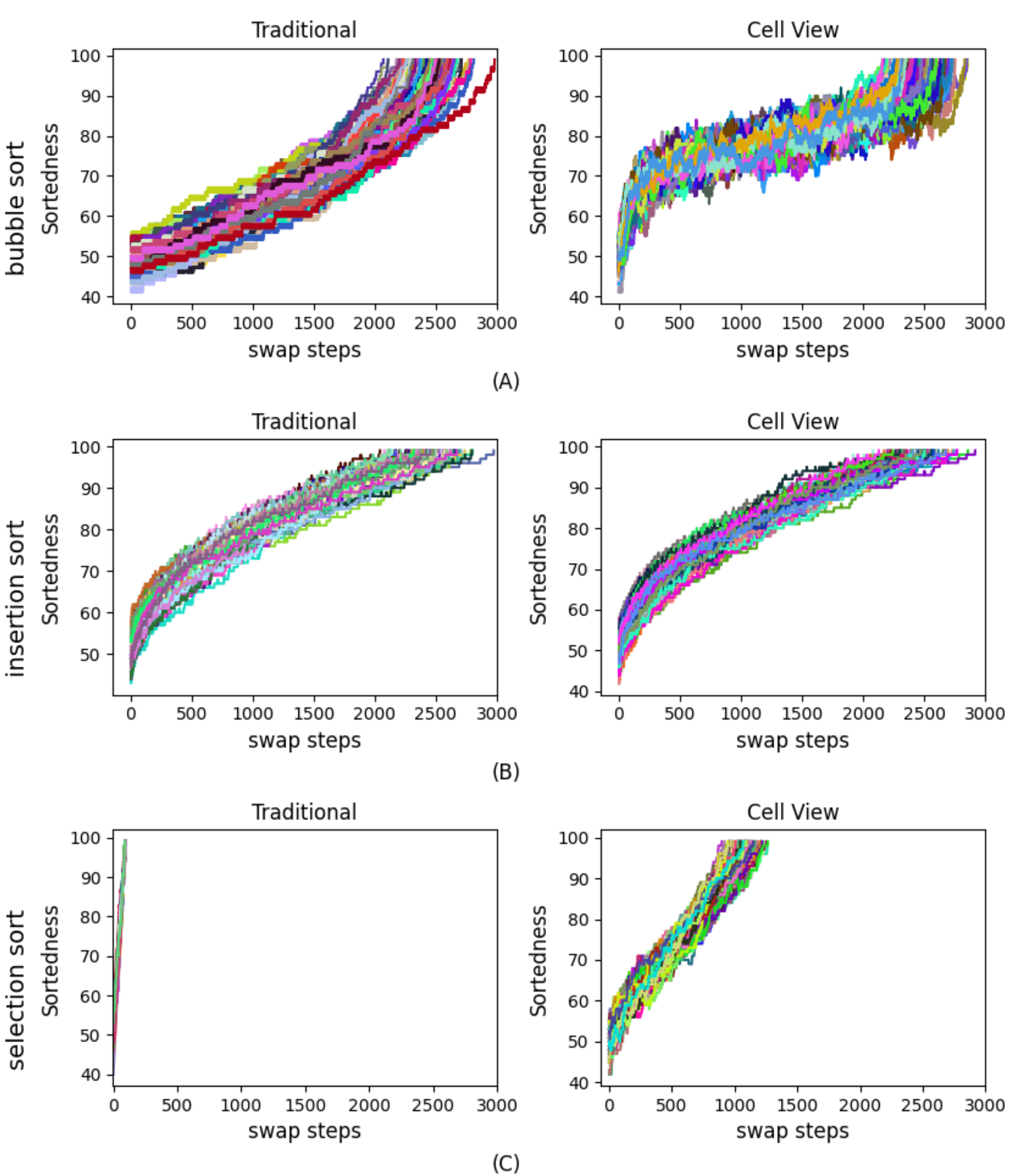
random input number sequence, with no repeat digits). Just as their traditional counterparts do, cell-view sorts successfully completed the sorting process, navigating from a random state to the 100% fully sorted state. (A) shows the comparison of Sortedness change during the sorting process between traditional Bubble sort and cell-view Bubble sort. (B) shows the comparison of Sortedness change during the sorting process between traditional Insertion sort and cell-view Insertion sort. The difference between the two graphs is relatively small, because the implementation of cell-view Insertion sort always keeps the left side of the array sorted and allows one cell to join the sorted side each time which is very similar to the traditional Insertion sorting algorithm. (C) shows the comparison of Sortedness change during the sorting process between traditional Selection sort and cell-view Selection sort. The major difference between these two graphs is that the cell-view sorting process needs more swaps to complete the sort, because every cell can move to its ideal position and be swapped away when another cell with smaller value has the same ideal position.
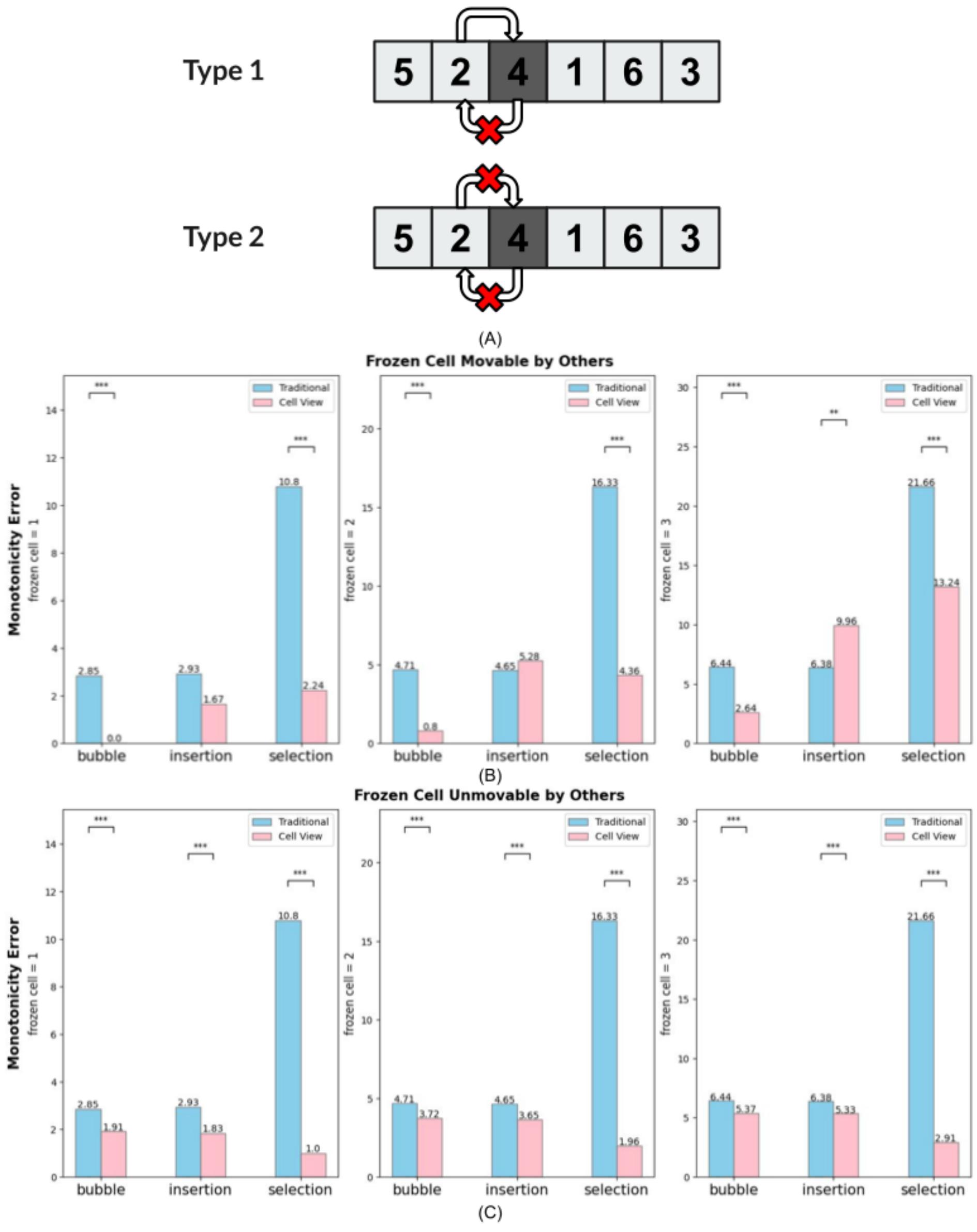
but cannot. We tested two kinds of “defects” (A): cells that can be moved by others but cannot initiate any swaps (“lack of initiative”), and cells that are completely broken and neither initiate nor participate in swaps initiated by others (“lack of motility”). (B) shows when the Frozen Cell can be moved by others, the cell-view version of the sorting algorithms have less monotonicity error than the traditional version; i.e. the cell-view version has higher robustness (error tolerance). The same graph also shows that among cell-view Bubble sort, Insertion sort, and Selection sort, the Bubble sort has the highest error tolerance, with the Insertion sort having next-highest and the Selection sort lowest. (C) shows when the Frozen Cell is completely fixed, the cell-view version of the sorting algorithms also has higher error tolerance than the traditional version. Here, the cell-view Selection sort has the highest error tolerance.
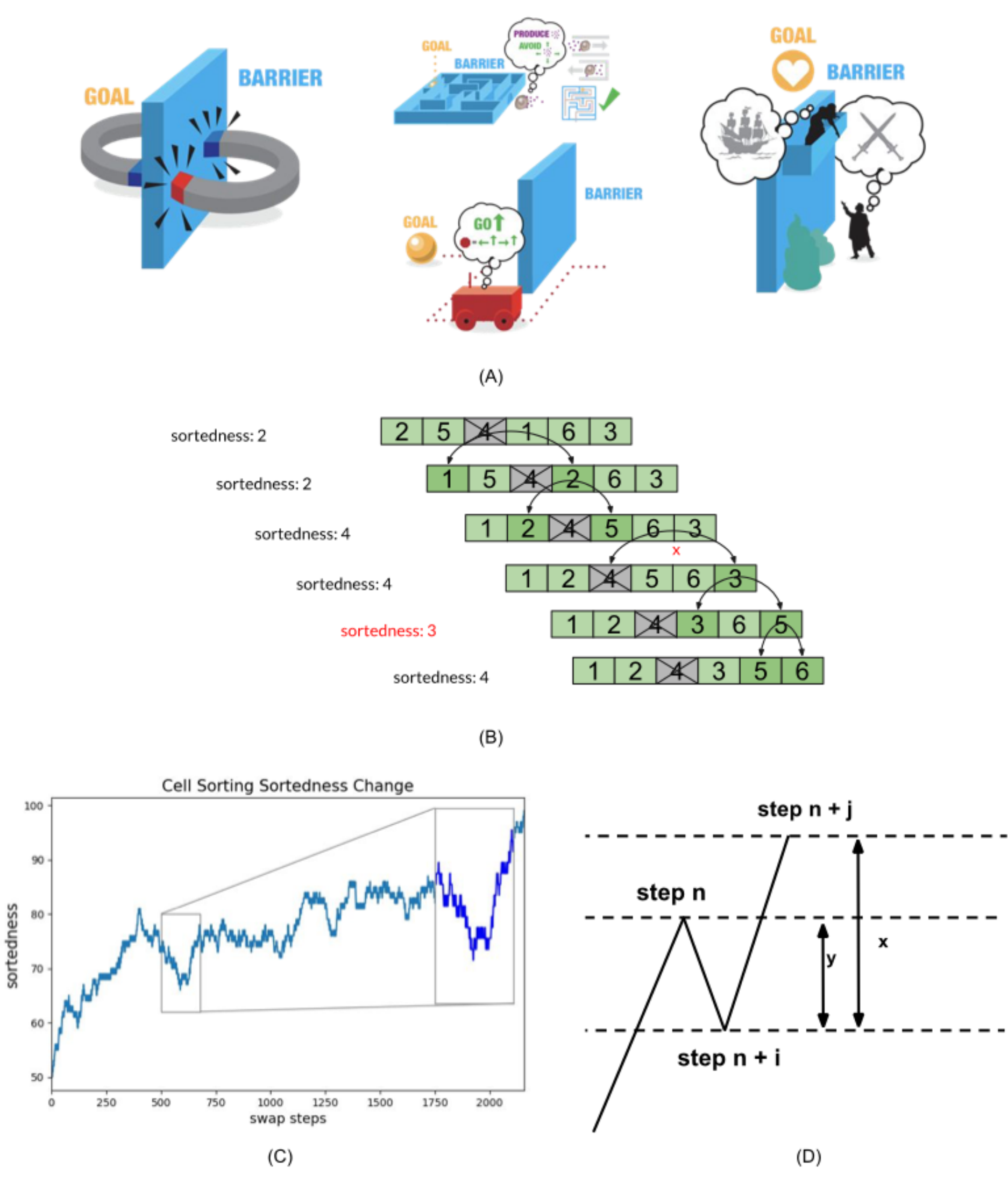
illustration of William James’ example of intelligence expressed as the ability to back-track from one’s goals, which is not seen in simple energy-minimizing systems like magnets that will never go around a barrier to get closer (left-most panel). By contrast, back-tracking is extensively seen in human systems which can do complex planning (such as Romeo and Juliet, right-most panel), and exists to intermediate degrees in cells, tissues, and autonomous vehicles (middle panel). This has been proposed as a key parameter for defining a generic notion of intelligence
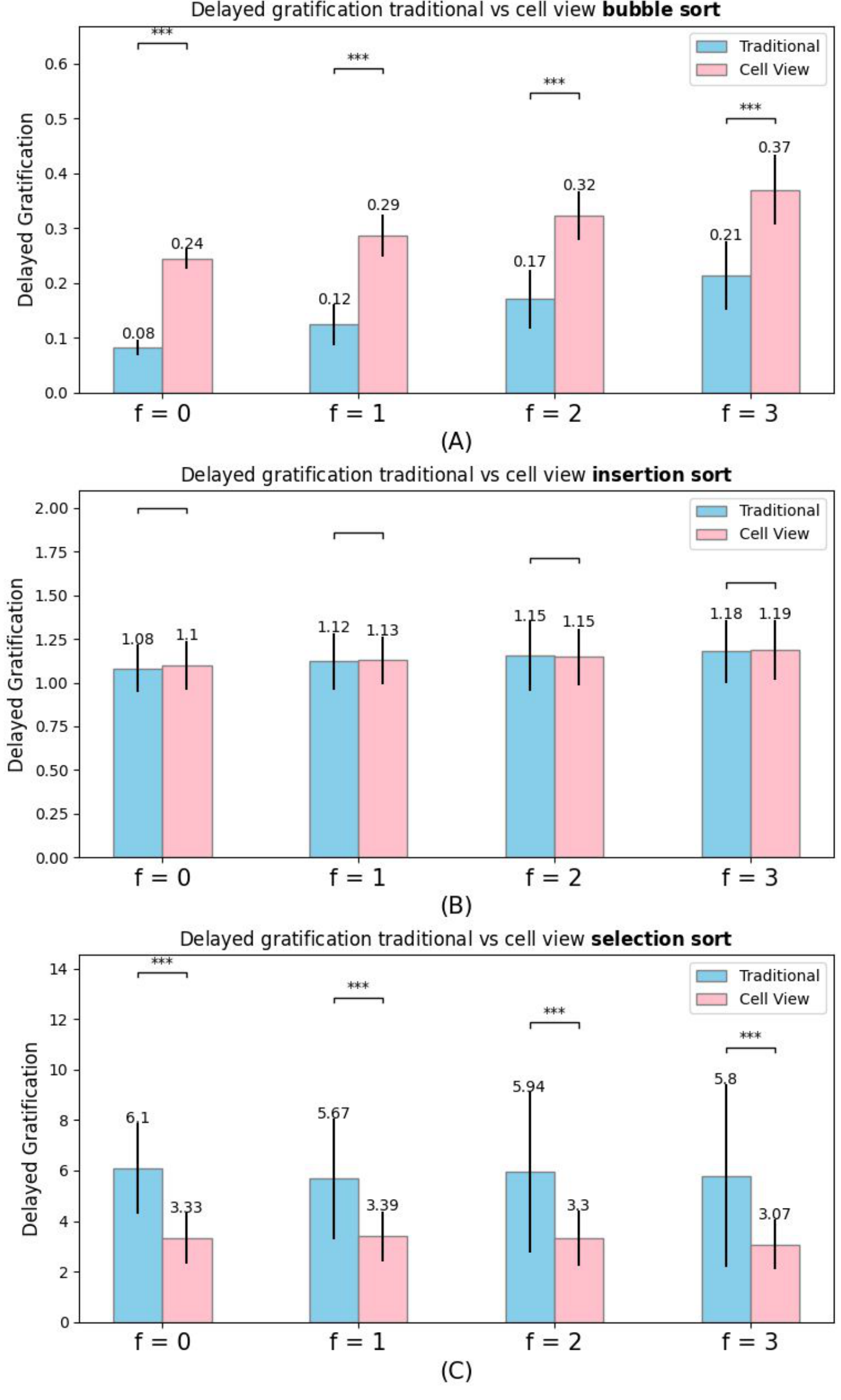
Delayed Gratification is not merely evaluating the inefficient movements that randomly go backwards, because the figures reflect the increasing trend of Delayed Gratification as the number of Frozen Cells increases. (A) shows that the cell-view Bubble sort gets more Delayed Gratification than the traditional algorithm
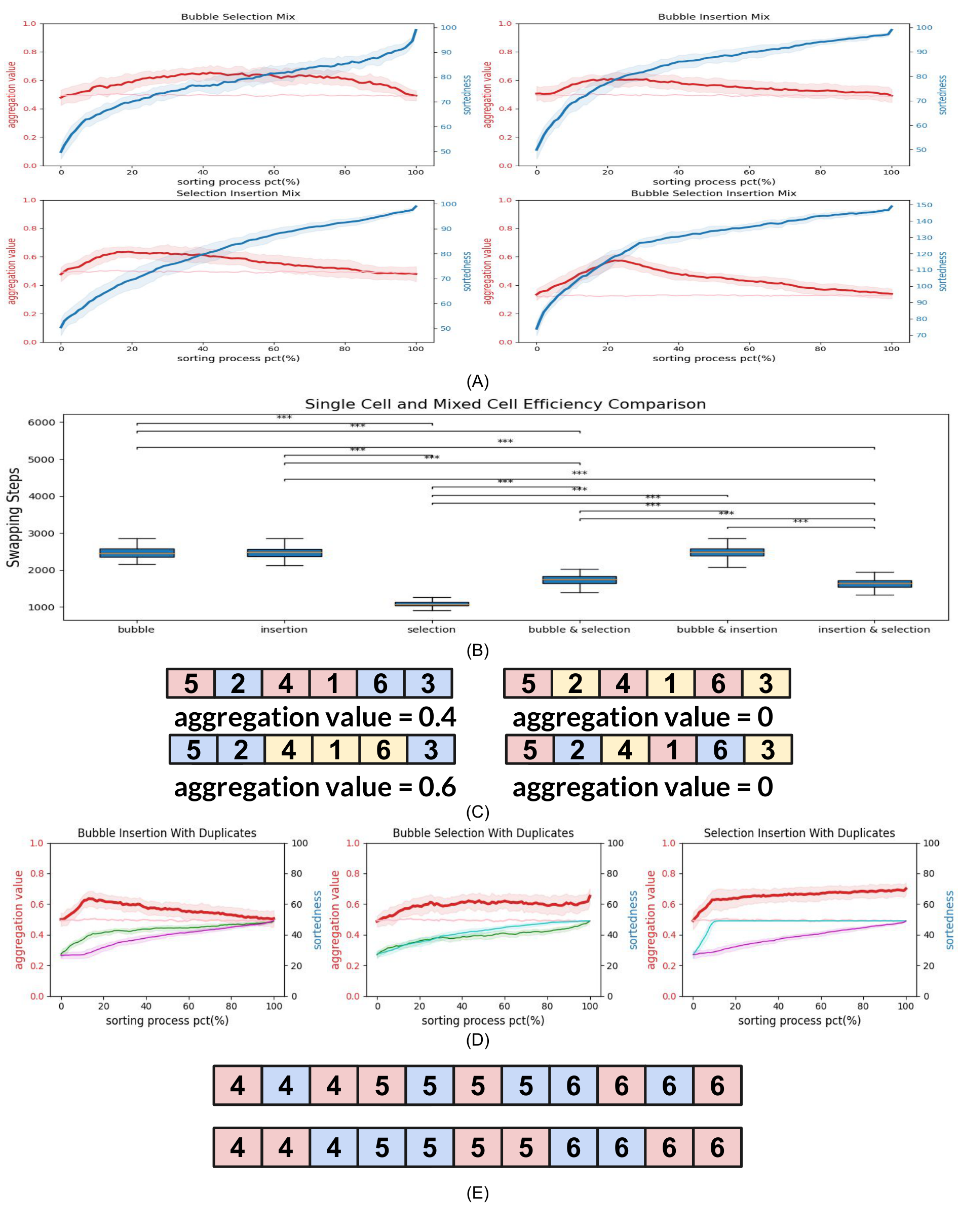
efficiencies of such chimeric individuals are shown in Supplemental Panel (B). To study how such chimeric collectives behave, we investigated 100 repeats of scenarios where each combination of the 3 sort algorithms was represented equally; note that the algorithms were not modified in any way and thus do not have any provision for knowing their own Algotype or that of their neighbors. (C). To understand the relative spatial distribution of cells executing each algorithm within the array during the sorting process, we defined aggregation value: the probability that a cell’s neighbor is of the same type as itself. Algotypes were assigned to each cell randomly in each experimental array and did not change during the course of the sort. Panel (A) shows the results of each possible combination of sort algorithms within an array. The blue lines indicate the progress of the sort itself (the Sortedness value). The pink lines indicate the Aggregation Value when two identical sorts are used - this negative control shows, as expected, that there is no significant deviation from 50% chance. The red line indicates the Aggregation Value of each kind of sort. As expected, at the beginning the Aggregation Value is 50%, since types are assigned to cells randomly. Likewise, at the end, the Aggregation Value is back to 50% since the array is sorted only by each cell’s Value, with no regard for Algotype, and the Algotypes were randomly assigned. Remarkably, significant aggregation was observed during the sorting process, peaking at 60% (with peaks that occur at slightly different times during the sorting process for each of the chimeric combinations). (D) We then allowed duplicate digits in the arrays, so that some instances of each number would be of each of the types, in order to see what maximum aggregation could be achieved if the explicit (monotonic numbers) and implicit (aggregation of types) goals were made compatible. We observed that the final Aggregation Values in (D) were larger than the final Aggregation Values in (A).
References
[references omitted]
[references omitted]
[references omitted]
[references omitted]
[references omitted]
[references omitted]
[references omitted]
[references omitted]