Bidipta Sarkar∗1,2, Mattie Fellows∗1, Juan Agustin Duque∗2,3,
Alistair Letcher†1, Antonio León Villares†1, Anya Sims†1, Clarisse Wibault†1,
Dmitry Samsonov†6, Dylan Cope†1, Jarek Liesen†1, Kang Li†1, Lukas Seier†1, Theo Wolf†1,
Uljad Berdica†1, Valentin Mohl†1,
Alexander David Goldie1,2, Aaron Courville3,5, Karin Sevegnani4,
Shimon Whiteson‡2, Jakob Nicolaus Foerster‡1.
$^1$ FLAIR - University of Oxford, $^2$ WhiRL - University of Oxford, $^3$ MILA– Québec AI Institute
$^4$ NVIDIA AI Technology Center, $^5$ CIFAR AI Chair, $^6$ NormaCore.dev
{bidipta.sarkar, matthew.fellows, jakob.foerster}@eng.ox.ac.uk
juan.duque@mila.quebec, shimon.whiteson@cs.ox.ac.uk
Abstract
Evolution Strategies (ES) is a class of powerful black-box optimisation methods that are highly parallelisable and can handle non-differentiable and noisy objectives. However, naïve ES becomes prohibitively expensive at scale on GPUs due to the low arithmetic intensity of batched matrix multiplications with unstructured random perturbations. We introduce Evolution Guided GeneRal Optimisation via Low-rank Learning (EGGROLL), which improves arithmetic intensity by structuring individual perturbations as rank-rr matrices, resulting in a hundredfold increase in training speed for billion-parameter models at large population sizes, achieving up to 91% of the throughput of pure batch inference. We provide a rigorous theoretical analysis of Gaussian ES for high-dimensional parameter objectives, investigating conditions needed for ES updates to converge in high dimensions. Our results reveal a linearising effect, and proving consistency between EGGROLL and ES as parameter dimension increases. Our experiments show that EGGROLL: (1) enables the stable pretraining of nonlinear recurrent language models that operate purely in integer datatypes, (2) is competitive with GRPO for post-training LLMs on reasoning tasks, and (3) does not compromise performance compared to ES in tabula rasa RL settings, despite being faster. Our code is available at eshyperscale.github.io.
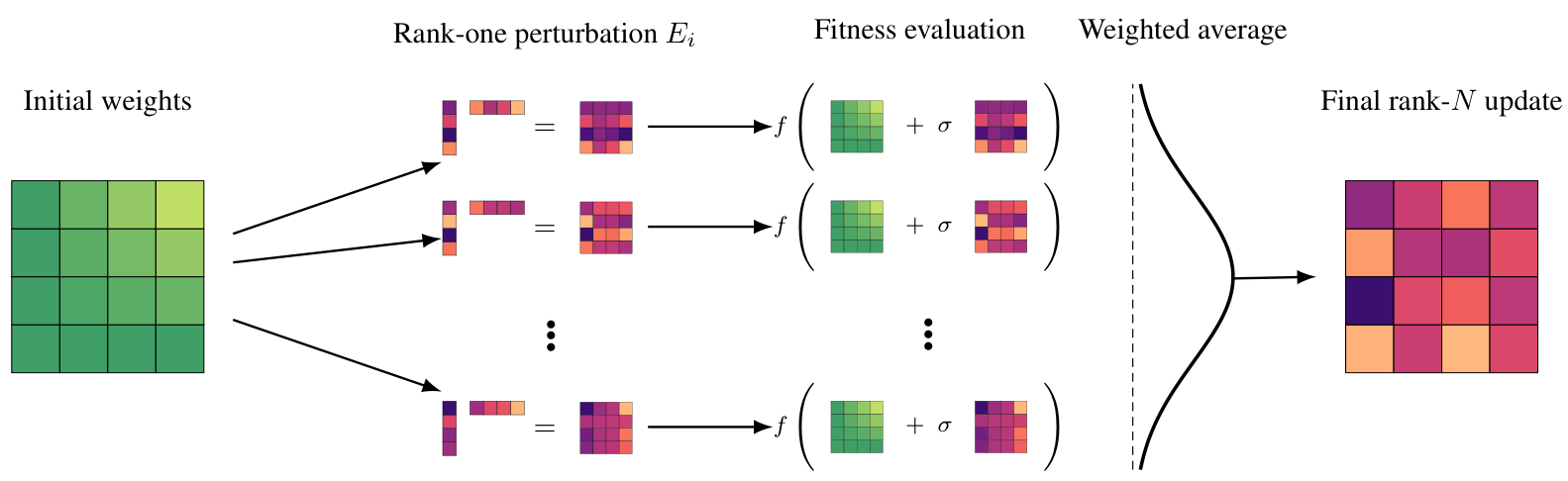
Figure 1: Schematic visualisation of EGGROLL using N workers.
1 Introduction
Evolution Strategies (ES) (Rechenberg, 1978; Beyer, 1995; Beyer & Schwefel, 2002)as established in prior literature is an attractive alternative to first-order methods based on gradient backpropagation for several reasons. First, ES does not require differentiability; it can optimise a broader class of models, like those with discrete parametrisations (cellular
*Equal Contribution † Core Contributor, sorted by alphabetical order in first names ‡Equal Senior Authors
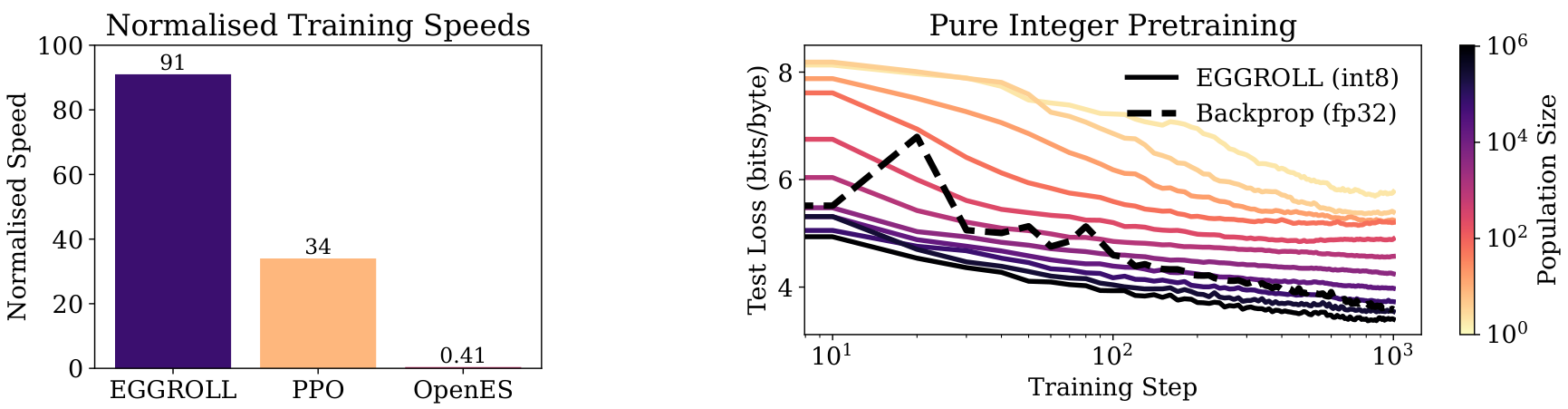
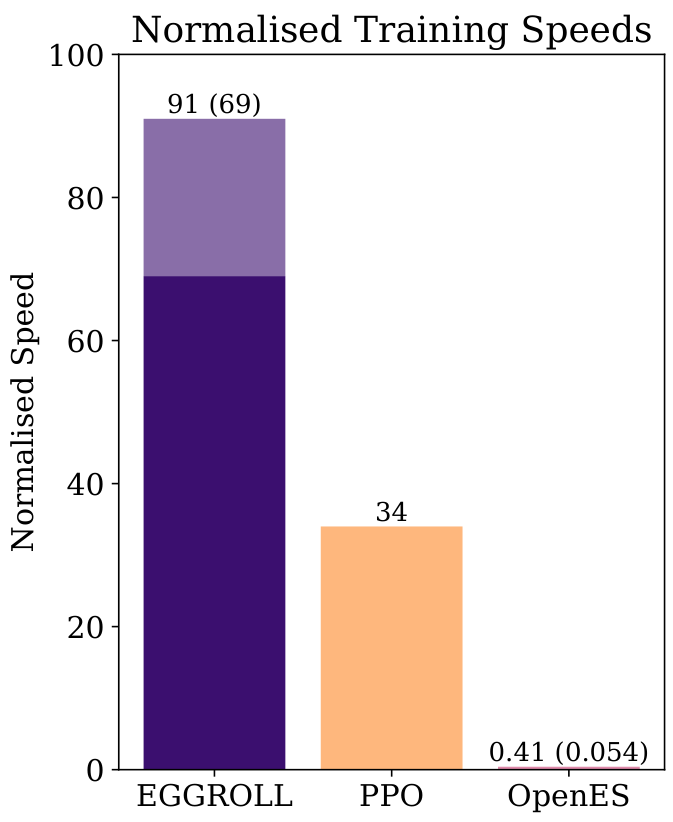
Figure 2: (a) Relative speed of our method, EGGROLL, in terms of experience throughput versus prior methods, where 100 is the maximum batch inference throughput. See Appendix E for more details. (b) We use EGGROLL to train an int8 RNN language model from scratch, scaling population size from 2 to 1,048,576 with a fixed data batch size of 16. The dotted line is a fp32 Transformer trained with backprop SGD. EGGROLL’s test next-token cross-entropy of 3.40 bits/byte while backprop only gets 3.58 bits/byte.
automata) or objectives for which gradients are unavailable or noisy, such as outcome-only rewards in LLM fine-tuning (Qiu et al., 2025). Second, ES can be more robust to noisy and ill-conditioned optimisation landscapes (Wierstra et al., 2011; Xue et al., 2021). Population-based exploration smooths irregularities (Salimans et al., 2017), tolerates discontinuities, and mitigates issues like ill-conditioned curvature or vanishing and exploding gradients in long-range or recurrent settings (Hansen, 2023). Third, ES is highly amenable to parallel scaling, since fitness evaluations are independent across population members and require only the communication of scalar fitnesses, which maps cleanly onto modern inference infrastructure and yields near-linear speedups on large clusters (Salimans et al., 2017). By contrast, backpropagation requires communicating and aggregating gradients across devices, yielding updates with high memory and computational costs. Furthermore, backpropagation requires special care when training models with low-precision datatypes (Fishman et al., 2025), whereas ES can directly optimise any model with the same datatypes used at inference time. Together, these properties position ES as a potentially powerful tool for training large, discrete, or hybrid architectures, and end-to-end systems with non-differentiable components, including LLMs (Brown et al., 2020; Chowdhery et al., 2023; Du et al., 2022; Fedus et al., 2022).
However, there are currently practical obstacles to employing ES at scale. In deep learning architectures (Goodfellow et al., 2016), the majority of trainable parameters form linear mappings represented by matrices (Rosenblatt, 1962; Hochreiter & Schmidhuber, 1996; Bengio et al., 2000; Krizhevsky et al., 2012; Goodfellow et al., 2014; Kingma & Welling, 2014; Vaswani et al., 2017). Naïvely adapting ES therefore requires generating full-rank matrix perturbations that replicate the entire parameter set for every population member. This inflates memory costs and forces frequent movement of large weight tensors. Evaluating these perturbations then requires a separate sequence of matrix multiplications per member, so the total compute and wall-clock time scale roughly with the population size and sequence length since batched matrix multiplication has a low arithmetic intensity, i.e., the ratio of arithmetic operations to memory traffic (Williams, 2008). In billion-parameter regimes, these two costs dominate, limiting ES to small models and small populations (Qiu et al., 2025; Korotyshova et al., 2025).
To mitigate both memory and computational bottlenecks, we introduce Evolution Guided GeneRal Optimisation via Low-rank Learning (EGGROLL), an ES algorithm that allows for the efficient training of neural network architectures with billions of parameters. Analogous to LoRA’s low-rank adapters in gradient-based training (Hu et al., 2022), EGGROLL generates low-rank parameter-space perturbations for ES; instead of sampling a full-rank matrix E∈Rm×nE in R m by n, we sample A∈Rm×rA in R m by r and B∈Rn×rB in R n by r with r≪min(m,n)r much less than the minimum of m and n and form E=r1AB⊤E equals one over the square root of r times A B transpose. This reduces auxiliary perturbation matrix storage from mn to (m+n)r per layer, and proportionally reduces tensor movement.
Moreover, we use a counter-based deterministic random number generator (RNG) (Salmon et al., 2011; Bradbury et al., 2018) to reconstruct noise on demand, so matrix perturbations need not persist in memory. When evaluating the fitness of members of multiple perturbations in parallel, EGGROLL batches a population of low-rank adapters and shares the base activations, enabling a single forward pass that applies all AB⊤A B transpose updates via specialised batched matrix multiplications with significantly higher arithmetic intensity, resulting
in over a hundredfold increase in training throughput for large neural networks at large population sizes, as shown in Figure 2a. Crucially, EGGROLL does not restrict updates to be low-rank, as the overall update is a weighted average of rank rr matrices across the population, making the matrix parameter update rank min(Nr,m,n)the minimum of N times r, m, and n.
To understand ES when applied to large parameter models, we analyse the convergence properties of general Gaussian ES in high dimensions, showing there exists a critical noise scaling σd=o(d−1/2)sigma d equals little o of d to the minus one half under which the update provably linearises and converges to the first-order derivative for a broad class of (possibly discontinuous) objectives. We identify three distinct regimes—linearisation, critical, and divergence—and establish provably tight conditions for stable ES optimisation in large models. Building on this, we extend the analysis to EGGROLL and prove that even fixed low-rank updates (including rank-1) converge to the true ES gradient as dimension grows, despite heavier-tailed perturbations. Our results explain the empirical success of EGGROLL in high-dimensional neural networks and connect its behaviour to neural tangent kernel-style linearisation (Jacot et al., 2018)Jacot and colleagues, yielding explicit convergence rates under standard overparameterised regimes. We also provide a rigorous theoretical analysis of the low-rank approximation accuracy, proving that EGGROLL updates converge to the full-rank Gaussian ES updates at a fast O(r−1)order r to the minus one rate.
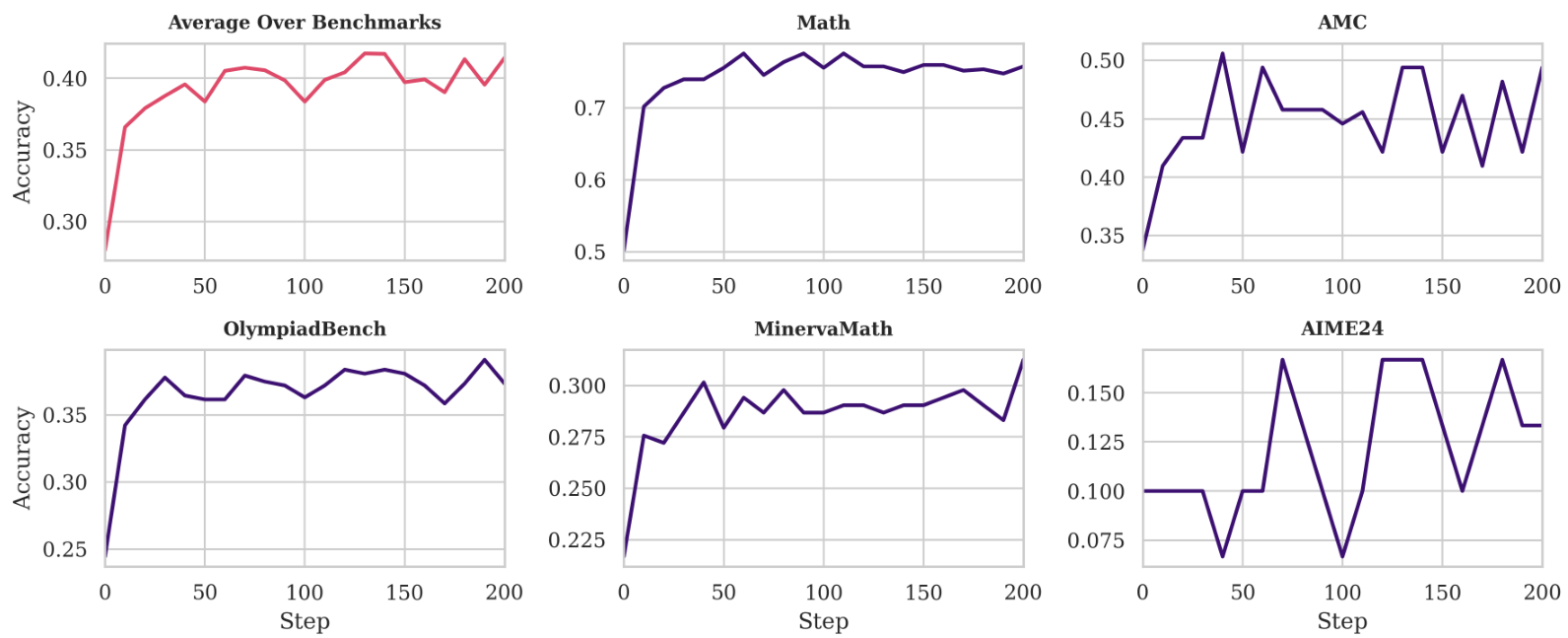
Furthermore, in our extensive empirical evaluation, we test this hypothesis across a wide range of domains. In tabula rasa and multi-agent RL (MARL) settings, we show that EGGROLL does not compromise performance compared to naïve ES despite being faster. We demonstrate the scalability of EGGROLL for LLM fine-tuning with experiments on pretrained RWKV7 (Peng et al., 2025)Peng and colleagues models, modern recurrent language models that enable large batch inference due to their constant state size. Finally, we develop a nonlinear RNN language model that operates purely in integer datatypes, and demonstrate that EGGROLL can stably pretrain this language model, a feat which is only feasible due to the large population sizes enabled by EGGROLL.
2 Preliminaries
2.1 Low-Rank Matrix Approximations
When adapting high-dimensional foundation models for specific tasks, updating the parameters using gradient-based methods has high memory requirements. LoRA (Hu et al., 2022)Hu and colleagues applies low-rank approximations to the matrix multiplications to reduce these costs. For each matrix Mi∈Rm×nM i of dimension m by n in the model, a low-rank approximation can be made by decomposing each matrix:
Mi≈Mi0+AiBi⊤,
where Mi0:=StopGrad(Mi)M i zero is the imported matrix from the foundation model with frozen parameters and Ai∈Rm×rA i and Bi∈Rn×rB i are low-width column matrices (i.e., r≪min(m,n)r is much smaller than the minimum of m and n) whose parameters are updated through gradient-based optimisation during task-specific adaptation. This reduces the number of optimisation parameters for each matrix from mn to r(m+n). EGGROLL uses a similar low-rank approximation for evolutionary strategies.
2.2 Evolution Strategies
Evolution strategies (ES) (Rechenberg, 1978; Beyer, 1995; Beyer & Schwefel, 2002) is a set of black-box optimisation methods that has emerged as a useful alternative to first-order gradient-based methods like stochastic gradient descent (SGD), particularly for noisy or non-differentiable systems. Let f:Rd→Rf from R d to R denote an objective to be optimised, known as the fitness, where the goal is to find an optimising set of parameters x⋆∈argmaxx∈Rdf(x)x star. Each set of parameters is collected into a d-dimensional vector known as a genotype. We denote the derivative of the fitness ∇xf(x)∣x=a evaluated at x=a as ∇f(a). Unlike first-order gradient-based methods, which query derivatives ∇f(x) to update the vector of parameters x, evolutionary methods update a parametric population distribution over the fitness parameter space π(x∣θ)pi of x given theta, which is smoothly parametrised by a separate set of parameters θ∈Θtheta. The population distribution generates perturbations x∼π(x∣θ)x sampled from the distribution known as mutations. The problem of optimising the fitness f(x) for x reduces to optimising the parameters of the population distribution θ. This is achieved by solving a secondary optimisation problem to maximise the expected fitness under π(x∣θ) for θ:
J(θ)=Ex∼π(x∣θ)[f(x)].
Introducing a population distribution smooths the fitness landscape; since π(x∣θ)pi of x given theta is smooth in θtheta, the resulting objective J(θ)J of theta is also smooth in θtheta, provided f(x)f of x is measurable and integrable but not necessarily differentiable. Evolution strategies can therefore optimise black-box problems that may be non-differentiable as the derivatives of J(θ)J of theta exist for fitness functions that are discontinuous, yielding a gradient with respect to θtheta:
∇θJ(θ)=Ex∼π(x∣θ)[∇θlogπ(x∣θ)f(x)],
where ∇θlogπ(x∣θ) is known as the score function. A Monte Carlo estimate is formed by sampling N search mutations xi∼π(xi∣θ)x sub i sampled from pi and computing an average of the score-weighted fitnesses:
∇^θJ(θ)=N1i=1∑N∇θlogπ(xi∣θ)f(xi),(1)
with which we update θtheta via stochastic gradient ascent with a suitable stepsize αtalpha sub t:
θt+1←θt+αt∇^θJ(θt).
ES does not require taking derivatives directly through the fitness function; instead the Monte Carlo update in Eq. (1) only requires evaluation of f(xi)f of x sub i for each mutation xix sub i to estimate ∇θJ(θ)the gradient of J. As ES only queries f(x) and not ∇f(μ), it is a zeroth-order optimisation method.
In this paper, we study ES using Gaussian population distributions: π(x∣θ)=N(μ,Idσ2)pi of x given theta is a normal distribution with mean mu and covariance I d sigma squared. In addition to its mathematical convenience, the central limit theorem means that the Gaussian distribution emerges naturally from the EGGROLL low-rank approximation as rank increases, even if the matrices A and B are themselves non-Gaussian. Moreover, most widely-used ES algorithms assume Gaussian population distributions (Rechenberg, 1978; Schwefel, 1995; Hansen & Ostermeier, 2001a; Beyer & Schwefel, 2002; Auger & Hansen, 2011; Wierstra et al., 2011; Salimans et al., 2017). In our setting, ES optimises over the population mean μ∈Rdmu in d dimensional real space, which acts as a proxy for the true maximum of the fitness function, and the variance parameter σ2≥0sigma squared is treated as a hyperparameter to be tuned.
For the Gaussian population distribution we study in this paper, the ES update can be written using an expectation under a standard normal distribution by making a transformation of variables v=σx−μ(Wierstra et al., 2011; Salimans et al., 2017):
where v∼P(v)=N(0,Id) and p(v) denotes the density of P(v). In this form, Eq. (2) shows that Gaussian ES methods optimise the fitness by generating search vectors from a standard normal distribution N(0,Id) around the mean parameter μ.
2.3 Evolution Strategies for Matrix Parameters
A key focus of this paper is to develop efficient methods for evolution strategies that target matrix parameters. When working in matrix space, it is convenient to use the matrix Gaussian distribution (Dawid, 1981), which is defined directly over matrices X∈Rm×n:
where M∈Rm×n is the mean matrix, U∈Rm×m is the row covariance matrix and V∈Rn×n is the column covariance matrix. We use vec(⋅) to denote the vectorisation operator:
vec(X):=[x1,1,…xm,1,x1,2,…xm,n]⊤.
The matrix Gaussian distribution is a generalisation of the multivariate Gaussian distribution N(μ,Σ) defined over vector space. Sampling a matrix X∼N(M,U,V) from a matrix Gaussian distribution is equivalent
to sampling a vector vec(X)∼N(μ,Σ)vector X distributed as normal with mean mu and covariance sigma from a multivariate Gaussian distribution with mean μ=vec(M)mu equals vector M and covariance matrix Σ=V⊗Usigma equals V Kronecker product U where ⊗the symbol denotes the Kronecker product. For isotropic matrix Gaussian distributions with covariance matrices U=σImU equals sigma I m and V=σInV equals sigma I n, the equivalent multivariate Gaussian distribution is also isotropic with Σ=σ2Imnsigma equals sigma squared I m n. We denote the ℓ2L two vector norm as ∥⋅∥ and to measure distance between matrices, we use the Frobenius norm:
∥M∥F:=i,j∑mi,j2=∥vec(M)∥,
the Frobenius norm of M is defined as the square root of the sum of squared elements, which equals the L two norm of the vectorized matrix
which provides an upper bound on the matrix 2-norm (Petersen & Petersen, 2012). Let W∈Rm×nW in R m by n be a set of matrix parameters where vec(W)vector W forms a subset of the full parameter vector xx, typically parametrising the weights of a linear layer in a neural network. As we derive in Section B, the Gaussian ES update associated with the matrix WW is:
where MM is the mean matrix associated with WW, i.e. vec(M) forms a subset of μ, and P(E) is a zero-mean standard normal matrix distribution: p(E)=N(0,Im,In)p of E is a normal distribution with zero mean and identity covariance matrices. The gradient in Eq. (3) is estimated using the Monte Carlo estimate:
∇^MJ(θ)=σN1i=1∑NEi⋅f(W=M+σEi),
the estimated gradient is one over sigma N times the sum from i equals one to N of E i times f of W
by sampling NN search matrices Ei∼P(Ei) from a standard matrix normal distribution N(0,Im,In) around the mean parameter matrix M, which is updated via stochastic gradient ascent:
Mt+1←Mt+αt∇^MJ(θt).
3 Related Work
3.1 Evolutionary Algorithms
Evolutionary algorithms have long been a compelling alternative to backpropagation-based training methods (e.g., genetic algorithms (Such et al., 2018) or symbolic evolution (Koza, 1994)). Much research in evolution has focused on developing algorithms for deep learning that scale well to distributed parallel computation (Jaderberg et al., 2017; Hansen & Ostermeier, 2001b; Salimans et al., 2017). These approaches have increased in popularity following the application of ES to policy learning in deep RL environments (Salimans et al., 2017). Since then, evolution has been widely applied in other domains, such as meta-learning (e.g., (Lu et al., 2022; Metz et al., 2022; Lange et al., 2023; Goldie et al., 2024; 2025)), hyperparameter tuning (e.g., (Parker-Holder et al., 2021; Tani et al., 2021; Vincent & Jidesh, 2023)), and drug discovery (Towers et al., 2025). ES has also enabled the development of neural network architectures that are unsuitable for backpropagation, such as activation-free models that exploit floating point rounding error as an implicit nonlinearity (Foerster, 2017). Here, we consider how to apply ES at a scale beyond the small networks and population sizes of prior work. For example, Salimans et al. (2017)Salimans and colleagues use a maximum population size of 1440, whereas we use over a million.
While low-rank structures have been used in prior evolutionary algorithms, they have been applied to different ends, with different trade-offs, relative to EGGROLL. Choromanski et al. (2019)Choromanski and colleagues use a low-rank search space found via principal component analysis, which provides a better search direction to more efficiently use small populations. Garbus & Pollack (2025)Garbus and Pollack optimise a low-rank factorisation instead of the full dense matrix with neuroevolution, achieving similar computational gains to EGGROLL but is limited to the low-rank structure regardless of population size.
3.2 Evolution Strategies for LLMs
Although gradient backpropagation is typically used for LLM training and fine-tuning, prior work explores ES variants for fine-tuning. In particular, Zhang et al. (2024)’sZhang and colleagues’ two-point zeroth-order gradient estimator, which can be viewed as an ES-inspired method using a single perturbation direction and two function queries per update, is used by Malladi et al. (2023)Malladi and colleagues for memory-efficient LLM fine-tuning. Yu et al. (2025)Yu and colleagues extend this approach by projecting perturbations to a low-rank subspace, improving convergence. Jin et al. (2024)Jin and colleagues perform ES directly on LoRA matrices. These works focus on supervised fine-tuning and report performance comparable to full fine-tuning, but do not address whether pretraining is possible with two-point zeroth-order methods; we find that large population sizes are necessary for pretraining, indicating such methods are unsuitable here.
Recent work also explores ES in the context of LLM reasoning. Korotyshova et al. (2025)Korotyshova and colleagues first train LoRA adapters using supervised fine-tuning (SFT) before decomposing them into fixed SVD bases alongside singular values that are trained using CMA-ES. They achieve comparable performance to GRPO (Shao et al., 2024) in significantly less wall-clock time on maths reasoning benchmarks. Qiu et al. (2025)Qiu and colleagues directly use ES to optimise all LLM parameters for reasoning, with stronger performance than GRPO on the countdown reasoning task. However, both of these approaches use relatively small population sizes, on the order of a hundred unique perturbations per update, and instead collect hundreds of rollouts per perturbation to efficiently use GPUs. By contrast, our approach allows all generations to use different perturbations, such that our maximum population size per update is orders of magnitude larger (equal to the maximum inference batch size), without compromising token generation throughput.
4 EGGROLL
We now introduce EGGROLL (Algorithm 1). A practical issue with using a low-rank matrix approximation is that its distribution and score function have no analytic solution except for degenerate cases, so in Section 4.1 we derive the EGGROLL approximate score function from the limiting high-rank Gaussian. Section 4.2 describes how to efficiently implement EGGROLL on modern hardware.
4.1 Low-Rank Evolution Strategies
Recall the Gaussian matrix ES update from Eq. (3). Our goal is to introduce a tractable approximation to generating full-rank matrices by using low-rank matrices AB⊤A B transpose as our search matrices instead. Let p(A) and p(B) denote the distribution of A∈Rm×rA in R m by r and B∈Rn×rB in R n by r.
Assumption 1 (I.I.D. Sampling).Assume all elements ai,j∈A and bi,j∈B are continuous, identically and independently distributed random variables according to some zero-mean, symmetric, absolutely continuous distribution p0(⋅) with finite fourth-order moments and unit variance.
Algorithm 1 EGGROLL(r,α,σ,Tmax,Nworkers)
initialiseM and workers with known random seeds ς
forTmax timesteps do
for each worker i∈{1,…Nworkers}in parallel do
Ai∼p(Ai),Bi∼p(Bi)
Ei←r1AiBi⊤
fi←f(W=M+σEi)
end for
workers share scalar fitness fi with other workers
for each worker i∈{1,…Nworkers}in parallel do
reconstruct Ej for j∈{1,…Nworkers} from ς
M←M+αNWorkers1∑j=1NWorkersEjfj
end for
end for
This assumption is easily satisfied for most perturbation distributions used by ES, including members from the set of generalised Gaussian distributions like Laplace, normal, and uniform distributions. We then form a low-rank search matrix: E=r1AB⊤E equals one over the square root of r times A B transpose. The r1one over square root of r scaling ensures the variance of EE remains bounded for all rr. We denote the induced distribution of E as P(E). E=r1AB⊤ maps to the manifold Mr⊂Rm×n of rank-r matrices. Hence, the density p(E) is defined with respect to a unit volume on the manifold and cannot be defined with respect to the standard unit volume in Euclidean space. For the corresponding score function, gradients with respect to logp(E) are not defined over the usual Euclidean space. Instead, we use an approximation S^(E):Rm×n→Rm×n for the score function, yielding our low-rank update:
g^LR=−σ1EE∼p(E)[S^(E)⋅f(W=M+σE)].(4)
In our experiments, analysis and Algorithm 1, we use a Gaussian approximate score function:
S^(E)=−E,(5)
which is the score function for the Gaussian distribution N(0,Im,In)N zero, I sub m, I sub n. This choice is motivated by two theoretical insights from Section 5. The matrix AB⊤A B transpose can be decomposed as a sum of independent, zero-mean vector outer products. Under Assumption 1, the central limit theorem applies to this sum of variables, proving that P(E)P of E converges in distribution to a Gaussian N(0,Im,In)N zero, I sub m, I sub n as rank rr increases, recovering the approximate Gaussian score in the limit. Secondly, we investigate the convergence of ES and EGGROLL as the number of parameters grows, proving both updates converge to a linearised form that is consistent with the EGGROLL update using the Gaussian approximate score function.
EGGROLL is not wedded to any particular score function approximator and we derive and explore a set of mean-field approximators in Appendix D.1 as alternatives. However, our experiments show that the Gaussian approximator has the best overall performance on the tasks we consider. To optimise the ES objective using the EGGROLL update, we adapt the parallelised evolutionary strategies algorithm from Salimans et al. (2017)Salimans and colleagues. We make a Monte Carlo estimate of the expectation in Eq. (4) with NworkersN sub workers samples to optimise the mean matrix parameters MM using (approximate) stochastic gradient ascent. This yields the Gaussian EGGROLL update:
EGGROLL UPDATE: For each worker i (in parallel), sample Ai,t∼p(Ai,t), Bi,t∼p(Bi,t) and form a low-rank perturbation Ei,t=r1Ai,tBi,t⊤. Update matrix parameters using:
Here we absorb the constant σ1one over sigma into the tunable learning rate αtalpha sub t. As each random matrix Ei,tE sub i comma t in Eq. (6) has rank rr almost surely and the matrix is updated using a sum of NworkerN sub worker such matrices, the overall EGGROLL matrix parameter update has rank min(Nr,m,n)minimum of N r, m, and n almost surely, i.e., the overall parameter update is not restricted to be low-rank. For all experiments in Section 6, Nr>min(m,n)N r is greater than the minimum of m and n, i.e., EGGROLL parameter updates are full-rank.
4.2 Hardware-Efficient Implementation
A key reason to use EGGROLL over standard ES is that large populations can be simulated in parallel on a GPU thanks to the low-rank perturbations. For the sake of exposition, we write equations from the perspective of a single worker, ii, and explain in text how this corresponds to batched GPU operations. Consider the task of computing a batched forward pass over inputs ui∈Rdinu sub i in d in dimensional real space for a linear layer with mean parameter M∈Rdout×dinM of dimensions d out by d in. The standard forward pass is just a regular matrix multiplication, uiM⊤u i times M transpose, since MM is constant across all threads. In contrast, naïvely applying ES by trying to compute ui(M+σEi)⊤u i times the quantity M plus sigma E i transpose becomes a batched matrix multiplication, which is inefficient on GPUs since every element of M+σEi is only used in a single multiplication, yielding poor arithmetic intensity.
However, with EGGROLL we know that ui(M+σEi)⊤=uiM⊤+rσ(uiBi)Ai⊤u i M transpose plus sigma over root r times the quantity u i B i times A i transpose, which improves arithmetic intensity since it preserves the efficient general matrix multiplication used in batched inference while adding some additional cheap work per perturbation. In this context, the bulk of compute is spent on the efficient calculation of uiM⊤ using regular matrix multiplication. Meanwhile, when r=1r equals one, uiBiu i B i simply becomes an inexpensive batch of N vector-vector dot products of length din to get a batch of N scalars, which is then processed by a batched scalar-vector multiplication when multiplying by Ai⊤A i transpose. This decomposition is key to efficient batched LoRA inference, such as those used by vLLM (Kwon et al., 2023), which is why EGGROLL achieves the same speeds as batched LoRA inference systems. The batched LoRA inference enables high arithmetic intensity, enabling us to saturate compute with many unique perturbations per input. Note that this is impossible with naïve ES because each perturbation requires a separate matrix-vector multiplication, setting an upper bound of 1 for arithmetic intensity regardless of population size; see Appendix F for a full derivation.
We additionally optimise the update by not explicitly materialising the individual EiE sub i in the computation of ∑i=1NEifithe sum from i equals one to N of E i f i, the key term in the Gaussian approximate score function. In particular, when the rank is 1, we reconstruct A∈RN×dout and B∈RN×dinA of dimensions N by d out and B of dimensions N by d in and calculate the expression as (diag(f)A)⊤Bthe transpose of diagonal f times A, all times B, a simple matrix multiplication.
5 Analysis
*Proofs for all theorems can be found in Appendices A to D.*
In this section, we investigate the theoretical properties of the ES and EGGROLL updates. In Section 5.1, we study the convergence properties of the general Gaussian ES update as the parameter dimension d→∞d approaches infinity, obtaining the conditions required for convergence to a linearised form. We then extend this analysis to the EGGROLL update in Section 5.2. Finally, in Section 5.3 we provide an analysis investigating the effect that increasing the rank of the EGGROLL approximation, proving convergence to the true ES update in the limit.
5.1 High-Dimensional Gaussian ES
We first analyse the general ES update under Gaussian perturbations from Eq. (2):
∇μJ(θ)=σd1Ev∼N(0,Id)[v⋅f(μ+σdv)],
The gradient of J with respect to mu equals one over sigma d, times the expected value over v drawn from a standard normal distribution, of v times f of mu plus sigma d v
where v∈Rdv is a d dimensional vector. In high dimensions, the Gaussian annulus theorem (Vershynin, 2018; Wegner, 2024) proves that the probability mass of standard Gaussian distributions concentrates in thin shells of radius dthe square root of d, which place probability mass further from the origin as dimension dd increases. To counter this, we let σdsigma d depend on dd and analyse the critical decay rate of σdsigma d that yields convergence of the ES updates. We make the following mild regularity assumptions:
Assumption 2 (Locally Continuous Fitness).With probability 1 with respect to the random initialisation of μmu, assume there exists a ball Bρ(μ):={x′∣∥x′−μ∥<ρ}B rho of mu, defined as the set of x prime such that the norm of x prime minus mu is less than rho of fixed radius ρ>0rho greater than zero where f(x) is C1-continuous for all x∈Bρ(μ). Within this ball, let ∇f(x) be α-Hölder continuous, i.e., ∥∇f(x)−∇f(y)∥≤L∥x−y∥α for all x,y∈Bρ(μ), α∈(0,1] and L=O(1).the norm of the gradient of f at x minus the gradient of f at y is less than or equal to L times the norm of x minus y to the power of alpha, where alpha is between zero and one and L is of order one.
Assumption 2 does not restrict the fitness to be globally continuous; with probability one with respect to the initialisation distribution there must exist an arbitrarily small C1-continuous ball around μmu. In particular, discontinuities, kinks, and non-differentiable regions may exist in the domain, provided they are not encountered with nonzero probability in the local region explored by the algorithm. α-Hölder is the weakest simple, dimension-robust assumption that guarantees vanishing local gradient variation under Gaussian perturbations; it is weaker than Lipschitz continuity, which is recovered with α=1.
Assumption 3 (Global Polynomial Growth).Assume that there exists some constant 0<C<∞ that is O(1) in d and finite polynomial degree p≥0 such that ∣f(μ+σdv)∣≤C(1+∥μ+σdv∥p) and ∥∇f(μ+σdv)∥≤C(1+∥μ+σdv∥p) almost surely under v∼N(0,Id).Assume that there exists some constant C and finite polynomial degree p such that both the function f and its gradient are bounded by C times one plus the norm of mu plus sigma d v to the p-th power, almost surely under the normal distribution.
Unlike Assumption 2, this is a global assumption. Again, discontinuities can exist. The assumption is weaker than boundedness, is satisfied by essentially all fitness functions used in ES, and ensures that both the objective and its gradient are integrable under Gaussian perturbations; objectives violating this condition typically exhibit super-polynomial growth and derivative growth, which leads to ill-defined or highly unstable ES updates. Moreover, if the condition is not satisfied almost surely, then the function and its gradients are undefined in regions that have nonzero Gaussian measure.
Assumption 4 (Bounded Derivative).With probability 1 with respect to the random initialisation of μmu, assume that ∥μ∥=O(1) and ∥∇f(μ)∥=O(1), i.e. ∥μ∥ and ∥∇f(μ)∥ do not grow with increasing d.
This assumption is standard in high-dimensional analysis proving convergence to linearity, as proving convergence to ∇f(μ)the gradient of f at mu becomes meaningless if ∥∇f(μ)∥→∞the norm of the gradient approaches infinity. Moreover, the ES update as a whole can diverge if Assumption 4 is not satisfied. It can be ensured by scaling, typically by scaling networks parameters by d−1/2d to the minus one half or using an appropriate scaled initialisation, commonly Gaussian initialisation μ∼N(0,d1Id)mu distributed as normal with mean zero and covariance one over d times the identity matrix. This is precisely the scaling employed in the neural tangent kernel (NTK) regime (Jacot et al., 2018; Lee et al., 2019; Chizat et al., 2019), where it guarantees dimension-independent gradients and stable training dynamics.
These assumptions encompass essentially all objectives encountered in modern machine learning, including networks with finitely many ReLU activations, max- and hinge-based losses, and other piecewise-smooth or discontinuous models. Our first theorem proves convergence of a Gaussian ES update to a linearised form, that is to the local first-order derivative ∇f(μ)the gradient of f at mu, with a tight convergence rate for any function satisfying these assumptions:
Theorem 1 (Convergence to Linearity). Let Assumptions 2, 3, and 4 hold and σd=o(d−21)sigma d is little o of d to the minus one half. Then:
∥∇μJ(θ)−∇f(μ)∥=Θ((σdd)α)=o(1), almost surely with respect to the distribution over μ.
To understand the effect that breaching the σd=o(d−21) rate has on the convergence of Gaussian ES, we study the space of functions that can be represented by cubic polynomials of the form:
f(x)=a⊤x+21x⊤Bx+61C(x,x,x),(7)
where a∈Rd,B∈Rd×da in R d and B in R d by d is a symmetric matrix and C(x,x,x)=∑i,j,kci,j,kxixjxk denotes a symmetric 3-linear map represented by the symmetric 3-tensor C∈Rd×d×dC in R d by d by d, which generalises cubic equations of the form f(x)=ax+bx2+cx3 to vector-valued x. These are non-pathological, well-behaved, analytic C∞-continuous functions, and include a rich subclass of convex optimisation problems, for instance, cubic perturbations of strictly convex quadratics. Moreover, any convex C3-continuous objective admits a local third-order Taylor expansion of this form around a minimiser.
Theorem 2 (Exact Divergence for Cubic Objectives). Let f(x) denote the cubic polynomial in Eq. (7). Assume ∥a∥=O(1),∥B∥=O(1),∥C∥=O(1) where ∥⋅∥ denotes operator norm for i-tensor T(x1,…,xi): ∥T∥:=sup∥x1∥=⋯=∥xi∥=1∣T(x1,…,xi)∣. Let Assumption 4 hold, then:
Together, Theorems 1 and 2 prove Gaussian ES has a critical convergence rate of σd=o(d−21) in high dimensions, and operates in three regimes:
Regime I (Convergence to Linearity): For σd=o(d−21), ES converges to a linearised form, recovering a local first-order gradient update ∇f(μ). This result is analogous to neural tangent kernel (NTK) type theorems, which prove that neural networks linearise in high dimensions (Jacot et al., 2018)Jacot and colleagues, 2018 and results from the concentration of the population distribution as d→∞, but applies to a more general set of objectives including discontinuous architectures. Moreover, Theorem 1 proves that the (σdd)α rate at which Gaussian ES converges is tight and cannot in general be improved upon without strengthening continuity or introducing specific structure into the objective to ensure the Hölder constant L decays with d; for the class of cubic functions we consider in Theorem 2, the faster σd2d convergence rate found in Eq. (9) is possible due to the C∞-continuity of this function class, which means the converge rate is governed by third order derivative terms.
Regime II (Critical): For σd≍d−21, Gaussian ES converges to a nonlinear limiting update that may retain higher-order derivative terms when they exist; for our cubic example, Eq. (8) proves that at this critical rate, the second-order term associated with the matrix B vanishes due to symmetry and the third-order term associated with the tensor C remains:
2σd2Ev∼N(0,Id)[C(v,v,⋅)]=Θ(1).
As the polynomial form is representative of general Taylor expansions, this implies that the limiting high dimensional update retains third-order derivatives (and higher order odd derivatives) as d→∞.
Regime III (Divergence): For d−21=o(σd)d to the minus one half being little o of sigma d, Theorem 2 shows that there exist smooth cubic objectives with bounded coefficients for which:
∥∇μJ(θ)∥=Θ(σd2d)→∞.
the norm of the gradient of J with respect to mu is of the order sigma d squared times d, which goes to infinity
In particular, divergence occurs whenever the cubic tensor has a non-vanishing Gaussian contraction (equivalently, non-zero partial trace), i.e. in non-degenerate cases; only in the exceptional trace-free case does the cubic contribution vanish.
In practice, σdsigma d is often absorbed into the ES update stepsize, and its scale is adjusted automatically as part of the hyperparameter regime to ensure stability.
5.2 High-Dimensional EGGROLL
We now extend our high-dimensional analysis to study the EGGROLL update using the Gaussian approximate score function g^LRg hat L R from Eq. (5). Taking rr as fixed, we consider the Gaussian matrix ES setting outlined in Section 2.3. We take x=Vec(W)x equals Vec of W where W∈Rm×nW is an m by n matrix and analyse the effect of increasing the total number of matrix parameters d=mnd equals m times n. Recall the true ES Gaussian matrix update is:
∇MJ(θ)=σ1EE∼P(E)[E⋅f(W=M+σE)],
the gradient of J with respect to M is one over sigma times the expectation over E of E times f of M plus sigma E
where M is the set of mean matrix parameters associated with the matrix W and P(E) is a zero-mean standard normal p(E)=N(0,Im,In)p of E is a normal distribution with zero mean and identity covariance matrices.
Two key differences between full-rank Gaussian ES and EGGROLL are that g^LRg hat L R is an approximation to a true gradient and P(E) may have heavier tails than a Gaussian. To account for these differences, we require a slightly stricter local continuity control assumption:
Assumption 5 (EGGROLL Locally Continuous Fitness). With probability 1 with respect to the random initialisation of μmu, assume there exists a ball Bρ(μ):={x′∣∥x′−μ∥<ρ}B rho of mu, defined as the set of points x prime such that the distance to mu is less than rho of fixed radius ρ>0rho greater than zero where f(x) is C2-continuous for all x∈Bρ(μ) and ∥∇2f(μ)∥ be polynomial bounded in d. Within this ball, let ∇2f(x) be Lipschitz continuous, i.e. ∥∇2f(x)−∇2f(y)∥≤Ld∥x−y∥ for all x,y∈Bρ(μ).
This assumption still permits discontinuous objectives. We also assume that p0(⋅) generates sub-Gaussian elements with uniform tail control:
Assumption 6 (Sub-Gaussian Tails). In addition to Assumption 1, assume that p0(⋅) generates variables that have sub-Gaussian tails, i.e. for xi∼p0(xi):
P(∣xi∣>t)≤2exp(−Ct2),
the probability that the absolute value of x i is greater than t is less than or equal to two e to the minus C t squared
for some 0≤C<∞ that does not depend on d.
We discuss sub-Gaussian variables and their properties in Section C.3 The assumption is trivially satisfied for Gaussian distributions a∼N(0,Im) and b∼N(0,In), and holds more generally, for example for bounded distributions, uniform distributions and generalised Gaussian distributions with shape parameter greater than two. This flexibility is particularly relevant for the models in Section 6.1, where heavier-shouldered distributions may be preferred over the Gaussian.
Theorem 3 (EGGROLL Convergence to Linearity). Let W∈Rm×n, d=mn and x=Vec(W). Let Assumptions 3, 4, 5 and 6 hold, σd=o(d−1/2), and Ld(σdd)2=o(1). Then there exists some K>0 such that:
almost surely with respect to the distribution over μ.
Our theory explains the success of EGGROLL in high dimensions with rank as small as r=1r equals one; Eq. (11) proves EGGROLL converges to the true update matrix ES update ∇MJ(θ)grad M J of theta as d→∞d goes to infinity regardless of rr. In addition, Eq. (10) proves that under the same conditions, the EGGROLL update also linearises like the true Gaussian ES update analysed in Section 5.1, recovering a local first-order derivative as d→∞d goes to infinity. For high-dimensional neural networks, standard parametrisations place training in the NTK regime, in which the network behaves approximately linearly in its parameters and gradient descent converges to a global minimum (Jacot et al., 2018; Lee et al., 2019; Chizat et al., 2019)as shown in prior research. Recent results show that the spectral norm of the Hessian decays polynomially with width, and that higher-order derivatives governing the variation of the Hessian also vanish (Liu et al., 2020). Consequently, the Lipschitz constant Ld=o(1)L d is small o of one, typically at rate d−21 or d−1 depending on the network architecture. Substituting these rates into our upper bound in Eq. (10) yields convergence rates of O(σd2d23) or O(σd2d) respectively.
5.3 Rank Analysis
We now analyse how fast the low-rank update from Eq. (4) with Gaussian score approximation converges to the true Gaussian ES matrix gradient in Eq. (3) as the rank of the update rr increases. We make notation explicit in rr in this subsection, for example writing Er=r1ArBr⊤E r equals one over the square root of r, times A r B r transpose. We introduce the following formal regularity assumption for the fitness function:
Assumption 7 (Bounded Fitness). Assume that f(W)f of W is bounded, that is supW∣f(W)∣<∞the supremum over W of the absolute value of f of W is finite.
Our key theoretical result characterises the error rate between the Gaussian score approximator in the low-rank update g^LRr from Eq. (4) and the true gradient using the matrix Frobenius norm:
Theorem 4 (EGGROLL Rank Convergence). Let Assumptions 1 and 7 hold, then:
∥g^LRr−∇μJ(θ)∥F=O(r−1).(12)
the Frobenius norm of the difference between the low rank estimate and the true gradient is of order r to the minus one
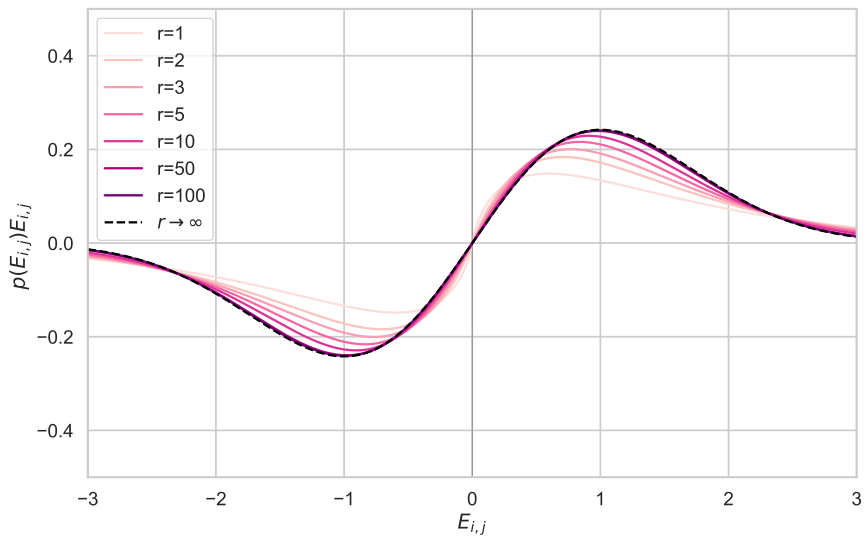
Figure 3: Plot of Marginal Score Multiplied by Density for Increasing r
The convergence rate in Eq. (12) is faster than the typical O(r−21)order r to the minus one half rate dictated by the general parametric central limit theorem. Our analysis shows that this is due to the symmetry in our problem under Assumption 1. To obtain our results, we make an Edgeworth expansion (Bhattacharya & Ranga Rao, 1976) of the distribution P(Er)P of E r, which expands P(Er)P of E r as the limiting Gaussian distribution plus a sum of decaying terms that are controlled by the 3rd order and higher cumulants of P(Er)P of E r. Each ith order cumulant term is multiplied by a factor that decays at rate O(r−2i−2)order r to the power of minus i minus two over two. For symmetric zero-mean distributions, all odd cumulants are zero (for the same reason that all odd moments of a symmetric distribution are zero). Hence, the rate of convergence to the limiting distribution is controlled by the 4th order term, which has rate O(r−1)order r to the minus one.
Although the full distribution P(Er)P of E r has no general closed-form solution, the distribution over marginals P(Ei,j) is more amenable to analysis. We derive the density of the marginal distribution P(Ei,j) for generalised Gaussian distributed ai,j and bi,j in Section D.1. To illustrate the fast convergence rate, we plot the negative density × score function p(Ei,j)Ei,j for the marginal density p(Ei,j) in Fig. 3 using Gaussian distributed ai,j and bi,j (see Theorem 6 for a derivation). The figure shows that p(Ei,j)Ei,j quickly converges to the limiting function 2πEi,jexp(−2Ei,j2)E i j over the square root of two pi, times the exponential of minus E i j squared over two, recovering the Gaussian form from the true Gaussian ES update. Even at r=1r equals one, the function is not a poor approximation. After r=10r equals ten, the function has nearly converged and after r=50r equals fifty, the function is visually indistinguishable from the limit, providing evidence for the hypothesis that the low-rank approximation is accurate even for very low-rank regimes r≪min(m,n)r much less than the minimum of m and n.
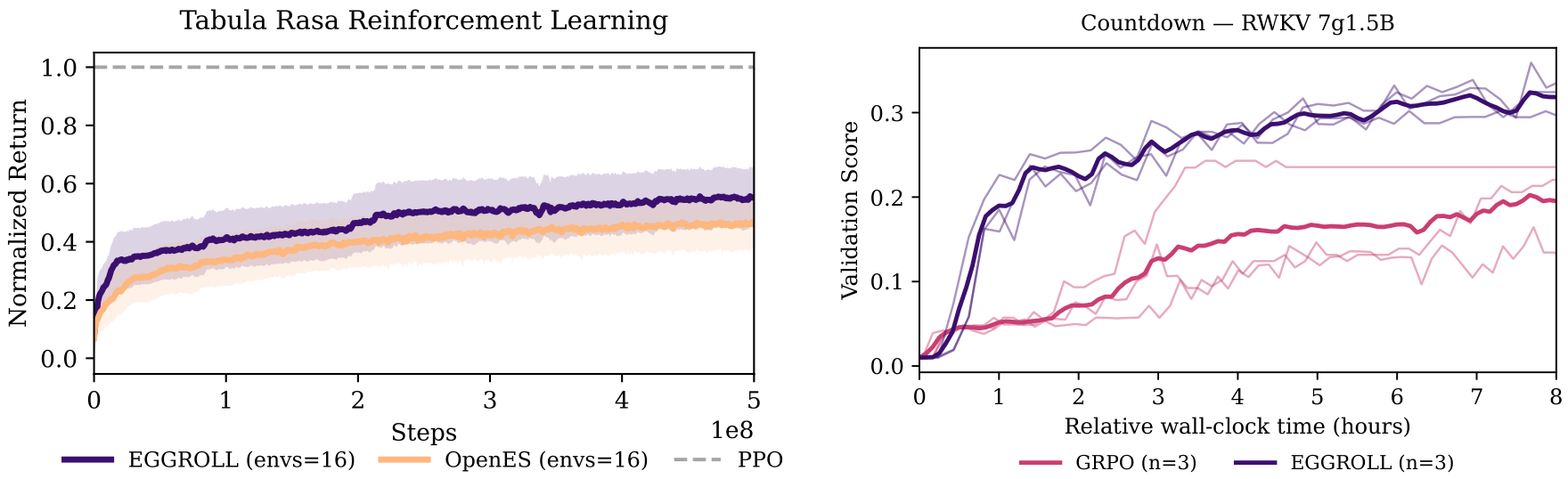
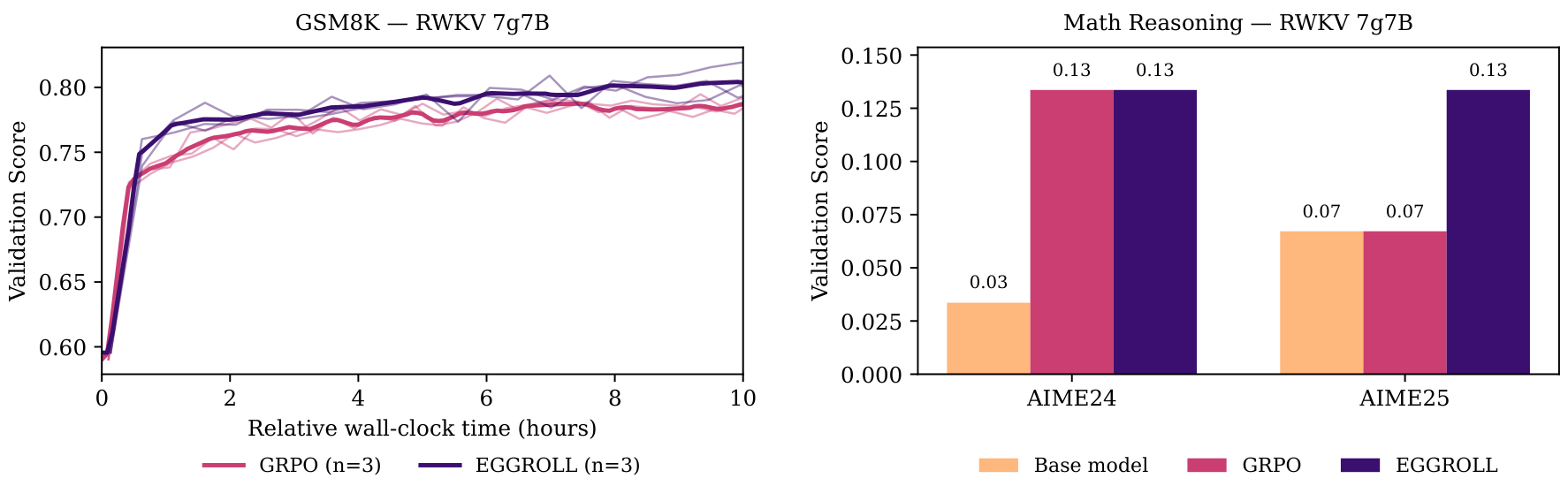
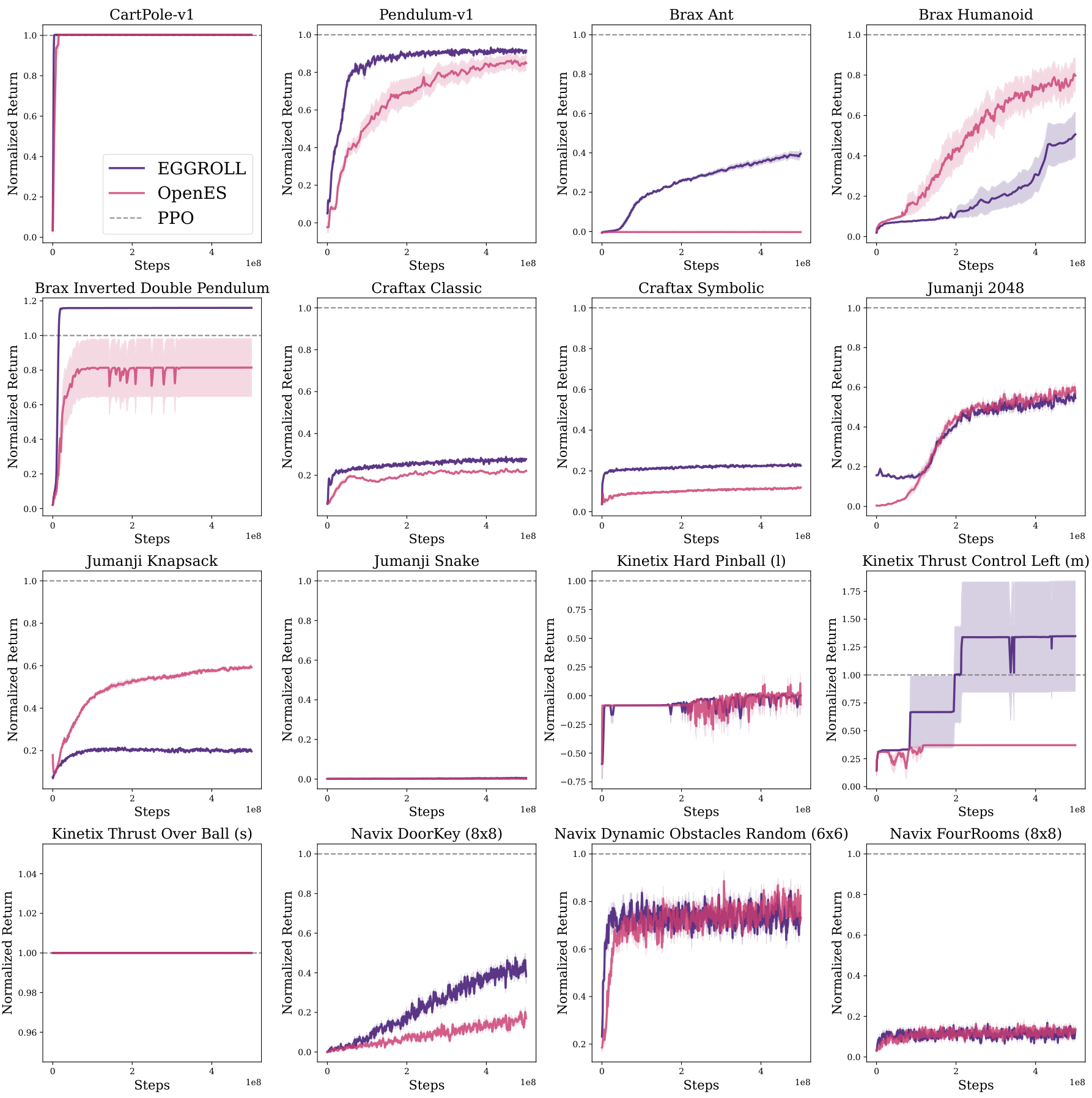
Figure 4: (a) Comparison of reinforcement learning returns normalised by PPO performance across 16 environments for 10 seeds. The shaded region is the standard error of the mean. (b) Validation score of 3 seeds of EGGROLL v.s. 3 seeds of GRPO in countdown task with an RWKV 7g1.5B model on a single GPU. EGGROLL allows 1024 parallel generations per GPU (618 updates) whereas GRPO only 64 (915 updates).
6 Experiments
In the following section we showcase the effectiveness of EGGROLL in a variety of tasks that position it as a strong alternative to back-propagation for the end-to-end training of foundation models.
6.1 Pure Integer Language Model Pretraining
To demonstrate the potential of EGGROLL as a general optimisation method, we apply it to language model pretraining. Since EGGROLL does not rely on gradients, we explicitly design a language model architecture to be efficient and hardware-friendly at inference time. To highlight EGGROLL’s flexibility, we train a nonlinear recurrent neural network (RNN) in pure integer datatypes with no explicit activation functions, relying only on the implicit nonlinearity of clipping in int8 operations. We call the resulting language model EGG, the Evolved Generative GRU, an EGGROLL-friendly architecture with all weights in int8. See Appendix G for more details on the architecture and motivation behind EGG.
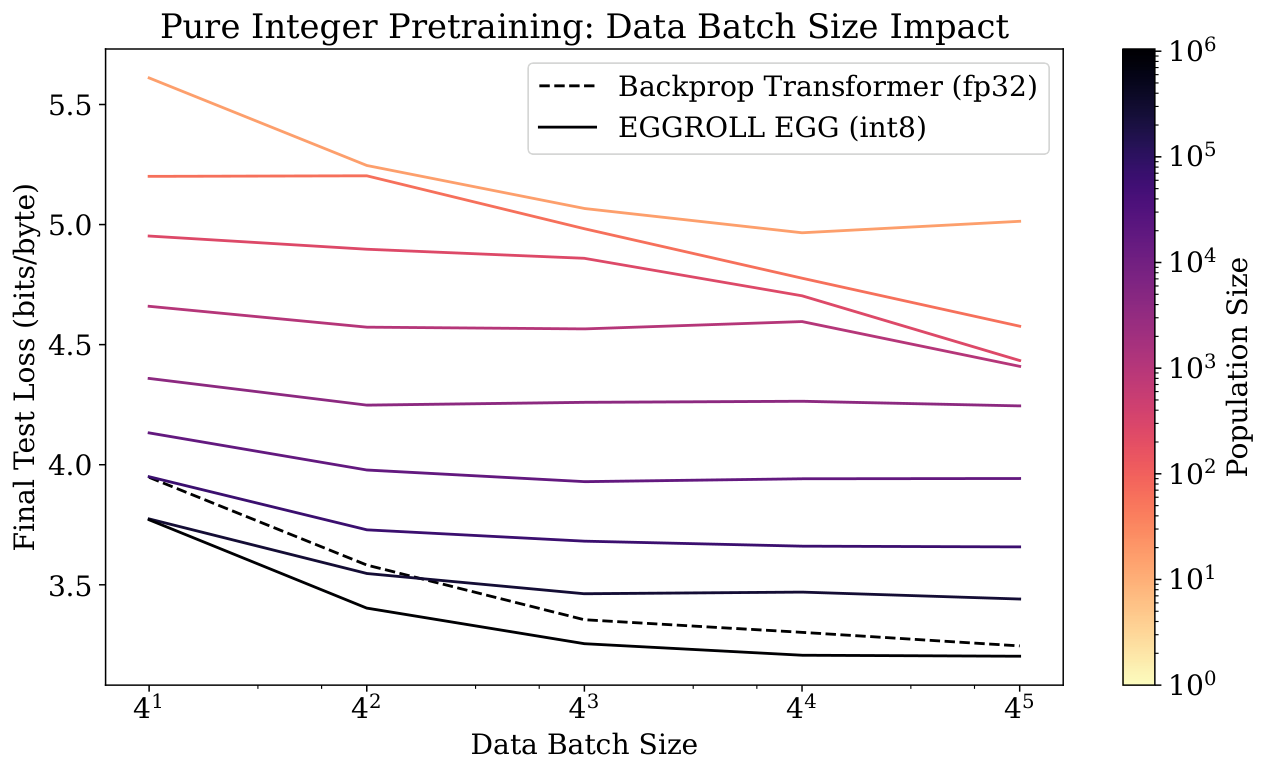
We train an EGG model with 6 layers and hidden dimension 256 (6L-256D) to do character-level prediction on the minipile dataset (Kaddour, 2023). We update parameters after 100 tokens for each population member, applying truncated ES by keeping the hidden state and only resetting at document boundaries. We plot the test loss in Fig. 2b over training steps across a range of population sizes with a fixed data batch size of 16 sequences per step, where the best test loss is 3.40 bits/byte. With a sufficiently large population size, EGG outperforms a dense 6L-256D Transformer trained with backprop SGD using the same data batch size. Note that larger population sizes require more parallel compute for the same amount of data; our largest population size of 220=1048576two to the twentieth power, which is one million forty eight thousand five hundred seventy six requires around 180 times more GPU-hours than the backprop baseline, demonstrating the potential for compute-only scaling in limited data regimes using EGGROLL.
Moreover, our largest population size of 220two to the twentieth is three orders of magnitude larger than the largest experiment done by Salimans et al. (2017)Salimans and colleagues while only requiring a single GPU to train, highlighting EGGROLL’s computational efficiency. We note that large population sizes are critical for pretraining; a population size of 2, analogous to MeZO (Malladi et al., 2023), significantly underperforms larger population sizes despite having access to the same data batch. We conduct more ablations in Appendix I, analysing the tradeoff between population size and data batch size.
6.2 Reinforcement Learning Tasks
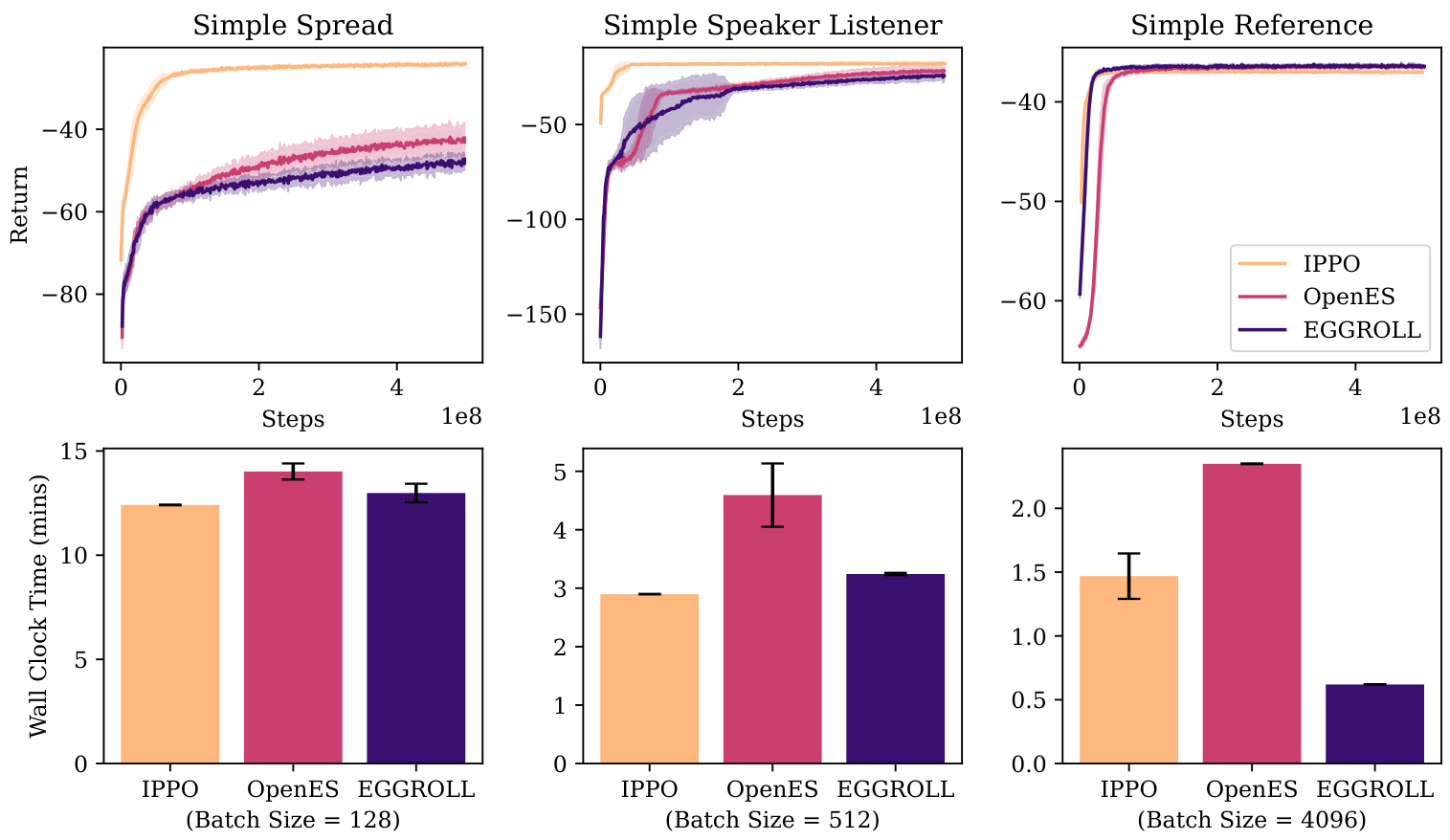
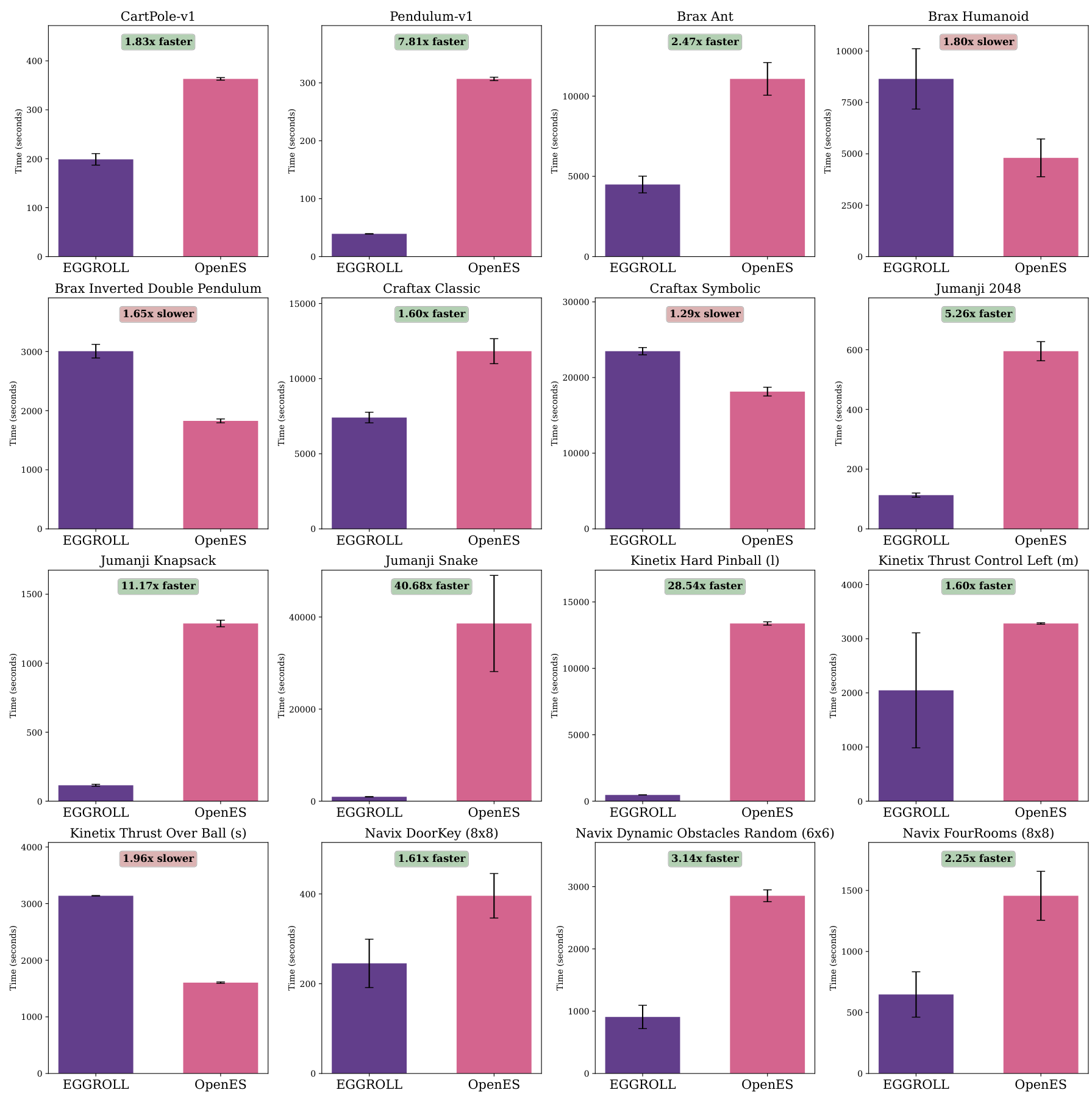
To verify that low-rank perturbations do not change the optimisation behavior of ES in standard control settings, we benchmark EGGROLL against OpenES (Salimans et al., 2017) across 16 tabula rasa environments spanning Navix, Craftax, Brax, Kinetix, and Jumanji. We use a fixed 3-layer MLP policy (256 hidden units) and perform per-environment hyperparameter optimisation for each method before evaluating the selected configuration over 10 random seeds, reporting mean performance (normalised by PPO) and uncertainty. Overall, EGGROLL is competitive with OpenES on 7/16 environments, underperforms on 2/16, and outperforms on 7/16, while often delivering substantial wall-clock improvements due to its batched low-rank structure (full environment
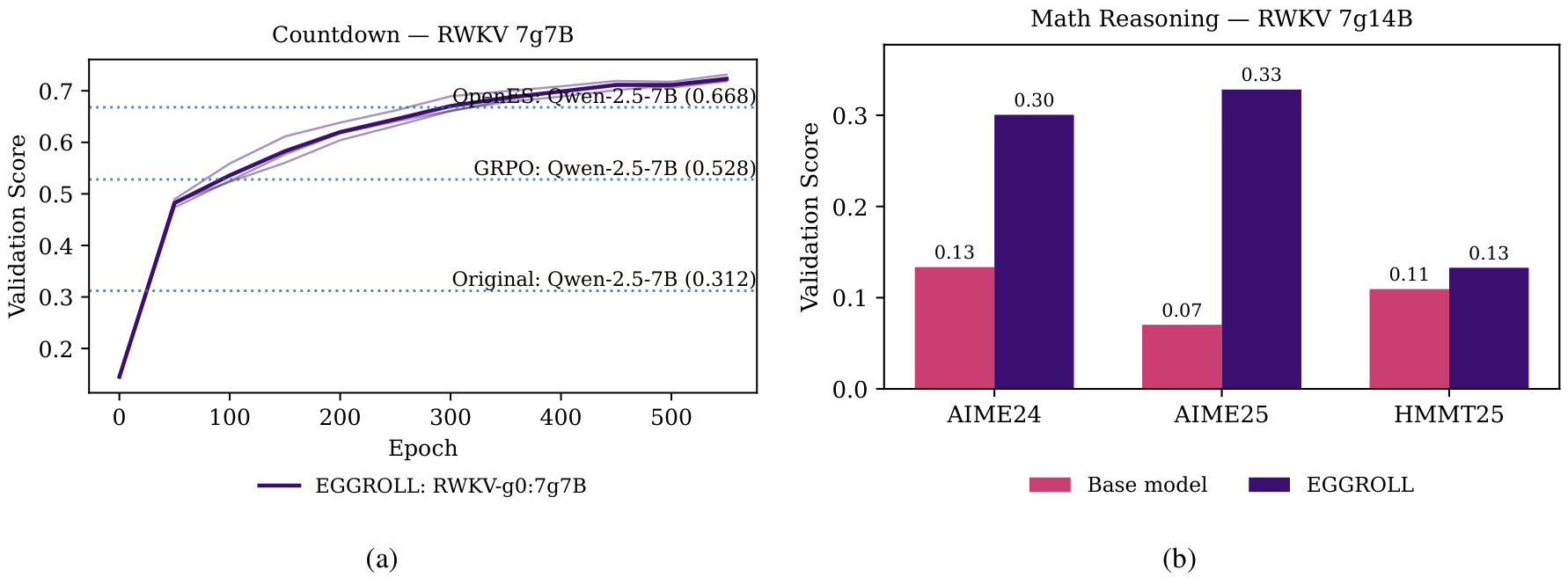
Figure 5: (a) Comparison of the validation score of 3 seeds of EGGROLL v.s. 3 seeds of GRPO in GSM8K task with an RWKV 7g7B model on 8 GPUs. EGGROLL allows 8192 parallel generations (1024 per GPU with 260 updates) whereas GRPO only 256 (32 per GPU with 340 updates). (b) Performance of our finetuned RWKV 7G 7 billion model on hard reasoning tasks using 128 GPUs for 12 hours. The model was trained using the DeepScaleR dataset and the best checkpoint was chosen by evaluating on AIME24.
list, learning curves, timing comparisons, and complete HPO ranges/settings are provided in Appendix N.4. Figure 4a shows the averaged normalised return across the 16 environments with 10 seeds per environment. We additionally report MARL results in Section N.1.
6.3 Foundation Model Fine-tuning
We apply EGGROLL to finetune an RWKV-7 (Peng et al., 2025)Peng and colleagues LLM on two reasoning tasks: countdown (Gandhi et al., 2024)Gandhi and colleagues and GSM8K (Cobbe et al., 2021)Cobbe and colleagues. RWKV is a recurrent model that is better suited to parallelisation than transformers because any memory otherwise spent on the KV cache is used to evaluate population members. Figure 4b shows that EGGROLL fine-tuning on an RWKV-7 1.5B model converges to a higher validation accuracy of 35% (vs. 23%) given the same hardware and wall-clock time in the countdown task. Similarly, Figure 5a shows that EGGROLL outperforms GRPO on GSM8K fine-tuning. Our scoring function draws parallels to the group relative advantage of GRPO. In particular, to score a set of noise directions, E≡{E1,…,En}E, defined as the set E 1 through E n, we first compute their accuracies, {s1,qi,…,sn,qi}s one q i through s n q i, on ∣q∣=mm questions, creating a matrix of scores S∈Rm×nS of dimension m by n. We then compute the normalised score per question, with the main difference that we use the global variance σˉsigma bar, and average over all the questions to compute a score for the noise direction EiE i:
sˉi=m1j=1∑mzi,qj=m1j=1∑mσˉsi,j−μqj.
This scoring function weights all questions within the same batch the same across population members. We use this recipe to train a 14 billion parameter RWKV 7 model on the DeepScaleR dataset and evaluate in more challenging maths reasoning tasks. In this regime, GRPO is infeasible due to the extra memory used by the Adam optimiser Kingma & Ba (2014)Kingma and Ba. Using a thinking budget of 5000 tokens for training and evaluation, our fine-tuned 14B model improves from 13% to 30% accuracy on AIME24, from 7% to 33% accuracy on AIME25 and from 11% to 13% accuracy on HMMT25 after training on 32 GPUs for 12 hours (Figure 13b). On 7B models, we outperform GRPO using 128 GPUs for 24 hours (Figure 5b).
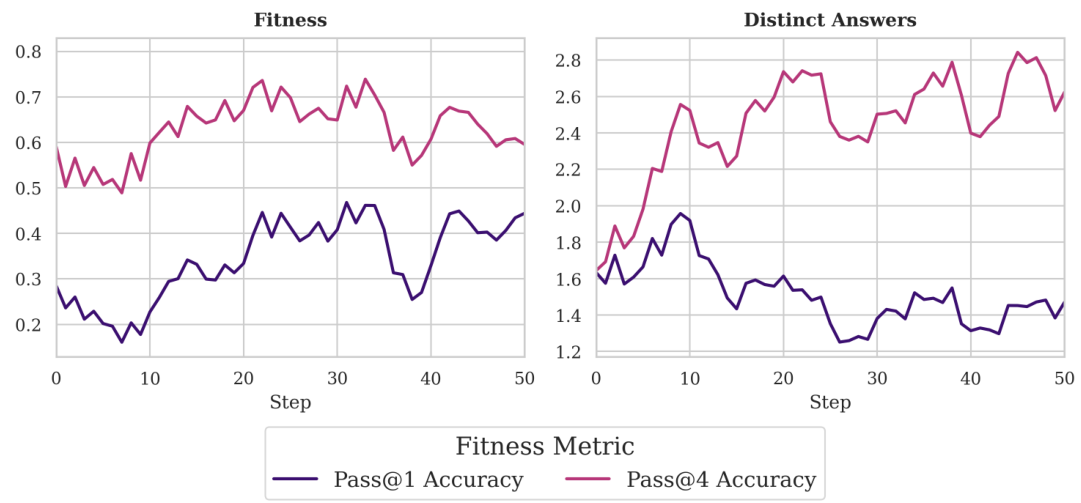
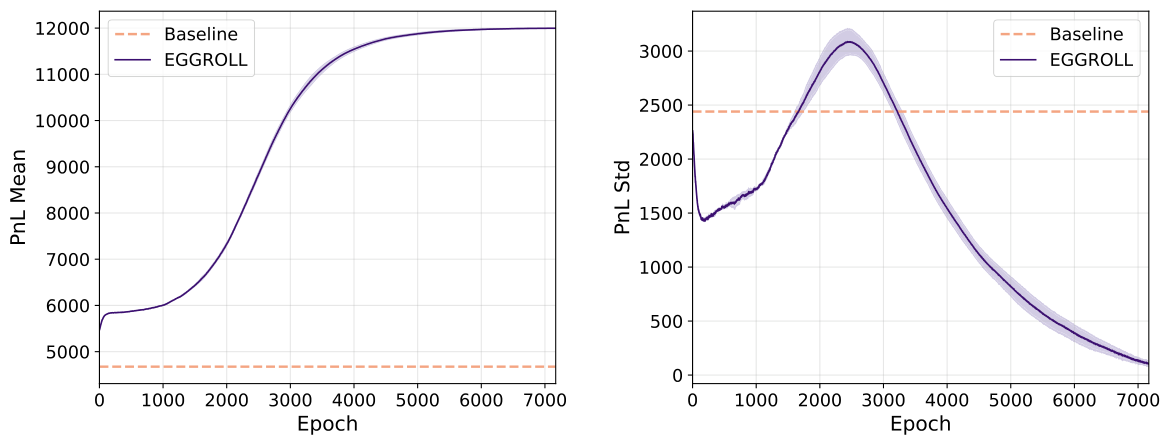
In Section L, we achieve similar performance to GRPO when fine-tuning Qwen Transformer models, and additionally demonstrate that EGGROLL can directly optimise for pass@k, a known limitation of GRPO (Yue et al., 2025)Yue and colleagues. Beyond language models, we also fine-tune a finance world model into an agent for high-frequency trading that directly optimises for PnL; see Section M for more details.
6.4 Fine-tuning Integer Quantised LLMs
We follow the same procedure as Jacob et al. (2017)Jacob and colleagues to quantise the RWKV-7 family of models by dividing by the maximum per-channel value on each weight matrix and mapping into the int8 range of [−127,127]. We then apply EGGROLL with Adam to do model distillation from the original, non-quantised RWKV-7, into the resulting int8 quantised model using examples from GSM8K. See Appendix K for full details about the
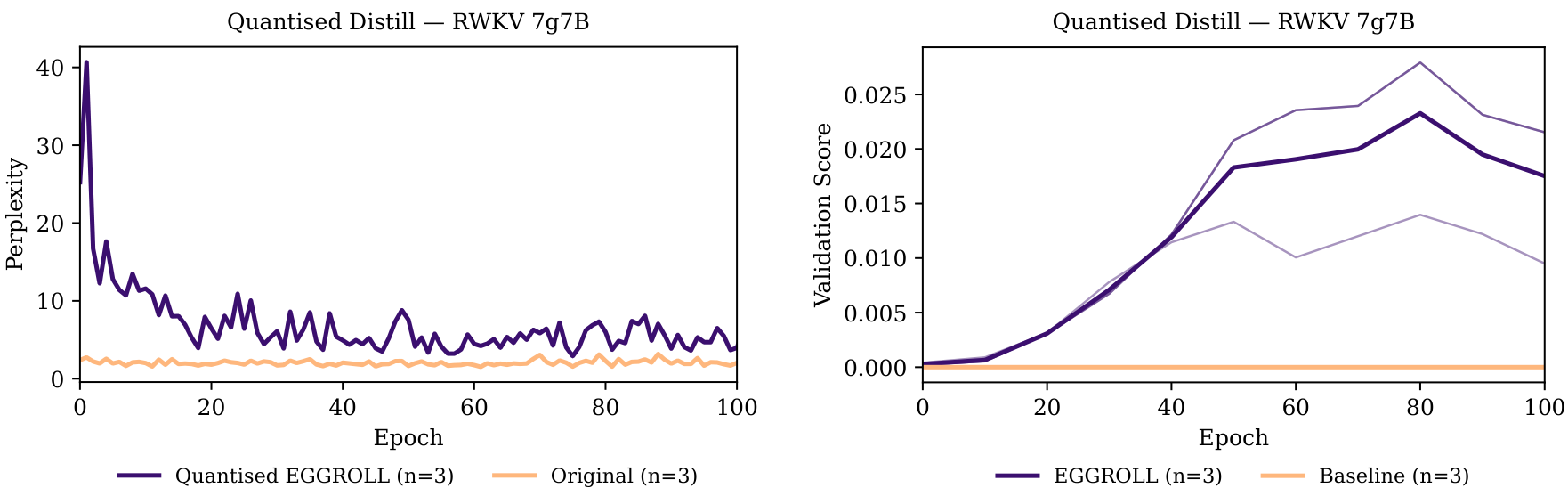
Figure 6: (a) Average per token perplexity (during training) of 3 seeds of a quantised (int8) RWKV 7G 7 billion parameter model on distillation from the non quantised model using examples from GSM8K. (b) Validation score on unseen examples of GSM8K of 3 seeds of a quantised RWKV 7G 7 billion parameter model. Initially the model is unable to solve any problems, but progressively it is capable of solving more problems. The baseline here indicates the validation score of a quantised model without any further training.
specifics of quantisation and fine-tuning. The distillation is done by matching the distributions between the quantised and non-quantised models on teacher forced examples (with solutions) from the GSM8K dataset. More specifically, the fitness for a given set of parameters, μimu i, is computed as follows:
fμi(x1:T)=t=1∑TKL(pt∣∣qt(⋅;μi)),
the fitness is calculated as the sum from t equals one to T of the Kullback-Leibler divergence between p sub t and q sub t given mu i
where x1:Tx one through T is a subsequence of tokens taken from the solutions of GSM8K and KL(pt∣∣qt(⋅;μi))the K L divergence is the Kullback-Leibler divergence between the distribution of the non-quantised model, ptp t, and the distribution of the quantised model qtq t over the vocabulary at token tt. Figure 6a shows the average per token perplexity of 3 seeds of a quantised RWKV 7G 7 billion parameter model compared to that of the original non-quantised model over the same sequence, as a baseline. Progressively, the quantised model recovers the capability to solve a subset of the GSM8K dataset (Figure 6b).
7 Conclusion
We introduce EGGROLL, a powerful method for black-box optimisation that scales evolutionary strategies to billion-parameter models and beyond using low-rank search matrices. Our experiments demonstrate that EGGROLL is effective with a rank of 1, giving substantial computational and memory savings for negligible decrease in performance when compared to the full-rank perturbations. Empirically, EGGROLL delivers large speedups over naïve ES in tabula rasa and multi-agent RL, and can power end-to-end training pipelines for foundation models. Our theoretical analysis shows that the EGGROLL update converges towards the Gaussian ES update with increasing rank rr and parameter dimension d=mnd equals m times n, and we provide a rigorous study of general ES at high dimensions, deriving necessary and sufficient conditions for convergence and linearisation.
Looking forward, we can use EGGROLL for other problems beyond the reach of modern first-order gradient-based techniques. In particular, EGGROLL can enable the training of large scale end-to-end neurosymbolic systems (Sarker et al., 2021)by Sarker and colleagues with non-differentiable components. For instance, we can train neural networks that interface with symbolic modules for specific functions, like memory or calculations. We can also optimise end-to-end systems of language models, training them to be aware of inference-time harnesses and interactions with other agents in complex systems.
Acknowledgements
Compute for this project is graciously provided by the Isambard-AI National AI Research Resource, under the projects “FLAIR 2025 Moonshot Projects” and “Robustness via Self-Play RL.” Some experiments also used compute generously given by JASMIN, the UK’s collaborative data analysis environment (https://www.jasmin.ac.uk).
Bidipta Sarkar is supported by the Clarendon Fund Scholarship in partnership with a Department of Engineering Science Studentship for his Oxford DPhil. Mattie Fellows is funded by a generous grant from the UKRI Engineering and Physical Sciences Research Council EP/Y028481/1. Juan Agustin Duque is supported by the St-Pierre-Larochelle Scholarship at the University of Montreal and by Aaron Courville’s CIFAR AI Chair in Representations that Generalize Systematically. Jarek Liesen and Theo Wolf are supported by the EPSRC Centre for Doctoral Training in Autonomous Intelligent Machines & Systems EP/Y035070/1. Jarek Liesen is also supported by Sony Interactive Entertainment Europe Ltd. Uljad Berdica is supported by the EPSRC Centre for Doctoral Training in Autonomous Intelligent Machines & Systems EP/S024050/1 and the Rhodes Scholarship. Lukas Seier is supported by the Intelligent Earth CDT with funding from the UKRI grant number EP/Y030907/1. Alexander D. Goldie is funded by the EPSRC Centre for Doctoral Training in Autonomous Intelligent Machines and Systems EP/S024050/1. Jakob Nicolaus Foerster is partially funded by the UKRI grant EP/Y028481/1 (originally selected for funding by the ERC). Jakob Nicolaus Foerster is also supported by the JPMC Research Award and the Amazon Research Award.
We thank Andreas Kirsch for discovering an emergent log-linear scaling law for EGG loss with respect to int8 OPs in this tweet along with other community members for their comments and recommendations during the first arXiv release of this work.
References
[references omitted]
[references omitted]
Jean-Philippe Bouchaud, Julius Bonart, Jonathan Donier, and Martin Gould. Trades, quotes and prices: financial markets under the microscope. Cambridge University Press, 2018.
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URL GitHub.
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners, 2020. URL arXiv.
Lénaïc Chizat, Edouard Oyallon, and Francis Bach. On lazy training in differentiable programming. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. Fox, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL NeurIPS.
Krzysztof M Choromanski, Aldo Pacchiano, Jack Parker-Holder, Yunhao Tang, and Vikas Sindhwani. From complexity to simplicity: Adaptive es-active subspaces for blackbox optimization. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. Fox, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL NeurIPS.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sashank Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res., 24(1144), 2023. URL JMLR.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
A. P. Dawid. Some matrix-variate distribution theory: Notational considerations and a bayesian application. Biometrika, 68(1):265–274, 1981. ISSN 0006-3444.
Nan Du, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, Barret Zoph, Liam Fedus, Maarten P. Bosma, Zongwei Zhou, Tao Wang, Emma Wang, Kellie Webster, Marie Pellat, Kevin Robinson, Kathleen Meier-Hellstern, Toju Duke, Lucas Dixon, Kun Zhang, Quoc Le, Yonghui Wu, Zhifeng Chen, and Claire Cui. Glam: Efficient scaling of language models with mixture-of-experts. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pp. 5547–5569, Jul 2022. URL PMLR.
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res., 23(1):1–39, January 2022. ISSN 1532-4435. URL JMLR.
In our proofs, we use the integral notation ∫ to denote the integral over the corresponding RdR d space, for example, for a matrix E∈Rm×nE in R m by n, ∫f(E)dE=∫Rm×nf(E)dE and for a vector E∈RmnE in R m n, ∫f(v)dv=∫Rmnf(v)dv. For f:Rd→Rf from R d to R, we use ∇f(x) to denote the derivative of f(⋅) evaluated at x. For a vector v∈Rmnv in R m n, we define the mat operator as:
so mat(vec(M))=M. We will use the fact that the Frobenius norm becomes the ℓ2l two norm in vector space:
∥M∥F=i,j∑mi,j2=k∑vec(M)k2=∥vec(M)∥.(13)
Our proofs make use of Fourier analysis. For a vector-valued function f(v):Rd→R, we define the Fourier transform as:
f~(ω)=F[f](ω):=∫f(v)exp(−iω⊤v)dv,
and the inverse Fourier transform as:
f(v)=F−1[f~](v):=(2π)d1∫f~(ω)exp(iω⊤v)dω,
B ES Matrix Gradient Deviations
Let μM=vec(M)∈Rmnmu M equals vec M in R m n be the vector of mean parameters associated with the matrix M. Let vM∈Rmnv M denote the corresponding search vector associated with μMmu M. As each element of v is generated independently from a standard normal N(0,1), the search vector vM is generated from the standard multivariate norm: vM∼N(0,Imn)v M is sampled from a multivariate normal with mean zero and identity matrix I m n. From Eq. (2), the update for μMmu M is:
We use insights from the Gaussian annulus theorem when investigating the convergence properties of high-dimensional ES: our proof relies on the fact that all probability mass converges to the interior of the ball Bϵ(μ):={x′∣∥x′−μ∥<ϵ}B epsilon of mu, defined as the set of x prime such that the norm of x prime minus mu is less than epsilon where ϵ=2ρepsilon equals rho over two in the limit d→∞d approaches infinity, where ρrho is the radius of the local ball from Assumption 2, meaning we only need to consider the smooth region around μmu in this limit. Our first result proves that the mass outside of the ball for any polynomially bounded function tends to zero at an exponential rate.
Lemma 1 (Polynomial Tail Bounds). Let g(x)g of x be polynomial bounded as:
∥g(μ+σdv)∥≤C∥v∥q(1+∥μ+σdv∥p),
for some finite polynomial of orders p and q and constant C>0. Let Ad:={∥σdv∥≥ϵ} denote the event that a mutation lies outside the a local ball of radius ϵ around μ. Assume σd=o(d−1/2). Then for some constant K>0:
the norm of the expected value of g of mu plus sigma d v, times the indicator function of A d, is big O of d to the power of q over two, times the exponential of negative K times the square of epsilon over sigma d and in particular the right-hand side is o(1) as d→∞.
Proof. We start by bounding the integrand using the polynomial bound. Denote P(Ad):=Ev∼N(0,Id)[1(Ad)]. Then, by Jensen’s inequality in the first line, polynomial boundedness in the second and ∥a+b∥p≤2p−1(∥a∥p+∥b∥p) in the third:
Now, the variable ∥v∥ is χd-distributed. Using the formula for the i-th central moment of ∥v∥ about the origin (Forbes et al., 2011, Chapter 11.3)as described by Forbes and colleagues yields:
Ev∼N(0,Id)[∥v∥i]=22iΓ(21d)Γ(21(d+i)).
Applying the identity Γ(z+b)Γ(z+a)∼za−b(Askey & Roy, 2020-2026, Eq. 5.11.12)from Askey and Roy:
Ev∼N(0,Id)[∥v∥i]∼22i(2d)2i=d2i,(14)
where ∼ denotes asymptotic equivalence. For i=2(p+q), this yields the bound:
We use the Gaussian concentration inequality for the Euclidean norm (Vershynin, 2018, Theorem 3.1.1)from a 2018 paper by Vershynin, which states that for x∼N(0,Id)x distributed as a standard multivariate normal there exists an absolute constant K>0 such that for all t≥0,
Setting t=σdϵ−d, the assumption dσd=o(1)root d times sigma d is little o of one implies for sufficiently large d that dσd≤ϵ and therefore t≥0, so we can apply the concentration bound to obtain:
where we have absorbed the factor of 21 into the constant K. □
Our proof in Lemma 1 reveals the necessity of the condition σdd=o(1) for convergence as we can only apply the Gaussian concentration inequality in Eq. (16) for σdd=o(1); this is a direct consequence of the Gaussian annulus theorem, as for slower rates 1=o(σdd), the Gaussian probability mass will exit any local ball around μ and flood the tail, meaning that the tail probability will grow with increasing d. Having bounded the tail, convergence to linearity follows by proving convergence within the ball, which allows us to exploit the local C1 smoothness of f(x):
Theorem 1 (Convergence to Linearity). Let Assumptions 2, 3 and 4 hold and σd=o(d−21). Then:
∥∇μJ(θ)−∇f(μ)∥=Θ((σdd)α)=o(1),
the norm of the gradient of J minus the gradient of f is big theta of sigma d times root d, to the power of alpha, which is little o of one
almost surely with respect to the distribution over μ.
Proof. We start with the definition of the ES update:
∇μJ(θ)=σd1Ev∼N(0,Id)[v⋅f(μ+σdv)].
Now let ϵ=2ρepsilon equals rho over two where ρrho is the radius of the ball from Assumption 2. Consider the hinge function:
ϕ(x)=⎩⎨⎧1,2−ϵ∥x∥,0,∥x∥≤ϵ,ϵ<∥x∥<2ϵ,∥x∥≥2ϵ,
which interpolates between 1 and 0 in the region ϵ<∥x∥<2ϵ. Our first goal is to use ϕ(x)phi of x to generate a function f~(x)f tilde of x that is absolutely continuous and has integrable derivatives outside of Bρ(μ)B rho of mu to allow us to apply Stein’s lemma (Stein, 1972). We define f~(x)f tilde of x as:
f~(x)=f(x)⋅ϕ(x−μ)
Consider the closed ball Bϵ(μ):={x′∣∥x′−μ∥≤ϵ}. We note that within the ball f(μ+σdv) remains unchanged:
where the gradient fails to exist only on the sets ∥σdv∥∈{ϵ,2ϵ}, which have Lebesgue measure zero. We start by using this function to decompose J(μ)J of mu into a smoothed part and a remainder:
Our goal is to apply Stein’s lemma (Stein, 1972) in its multivariate form (Liu, 1994, Lemma 1). The assumptions of (Liu, 1994, Lemma 1)prior work require that the partial derivatives ∂vif~(μ+σdv) are absolutely continuous almost everywhere and:
Ev∼N(0,Id)[∣∂vif~(μ+σdv)∣]<∞.
These two conditions are satisfied by construction. Indeed, under Assumption 2, f(⋅)f is C1C one continuous on Bρ(μ), hence from Eq. (17), f~(⋅)f tilde coincides with a compactly supported, piecewise C1C one function whose gradient (Eq. (18)) exists almost everywhere. Moreover, under Assumption 3, both f(μ+σdv) and ∇f(μ+σdv) are polynomially bounded, and since ∇f~(μ+σdv) is supported on ∥σdv∥≤2ϵ, it follows that:
Let {μ+σdv∈Bϵ(μ)}={∥σdv∥≤ϵ} denote the event that a mutation lies within the ball Bϵ(μ)B epsilon of mu. We now split the integral into two regions, the first within the ball and the second outside:
Consider the region inside the ball, IlocI local. From Eq. (18), ∇f~(μ+σdv)=∇f(μ+σdv) within this region. Using the local α-Hölder continuity from Assumption 2:
Now, as ∥∇f(μ)∥=O(1) from Assumption 4 and we have established that ∥∇f~(μ+σdv)∥ is polynomial bounded under Assumption 3 when applying Stein’s lemma, it follows that ∥∇f~(μ+σdv)−∇f(μ)∥ is also polynomial bounded, that is there exists some constant C>0 and finite polynomial order p such that:
Again, from Assumption 3, it follows that ∣f(μ+σdv)−f~(μ+σdv)∣ is polynomially bounded, that is there exists some constant C′>0C prime greater than zero and finite polynomial order p′p prime such that:
∣f(μ+σdv)−f~(μ+σdv)∣≤C′(1+∣∣μ+σdv∣∣p).
Applying Lemma 1 with q=1q equals one:
∣∣Δ(μ)∣∣=O(σdd21exp(−K(σdϵ)2)).
Now, as exp(−x)=o(x−1)exponential of minus x is little o of x to the minus one for x→∞x approaching infinity, it follows:
where the final line follows from the fact dσd=o(1)the square root of d times sigma d is little o of one. Assembling our bounds using Ineq. 19 yields our desired result:
We now show that the bound is tight. Consider the function f(x)=2L∑i=1dxi∣xi∣+a⊤xf of x equals L over two times the sum from i equals one to d of x i times the absolute value of x i, plus a transpose x where ∥a∥=O(1)the norm of a is order one. Taking partial derivatives:
∂if(x)=L∣xi∣+ai,(23)
hence:
∥∇f(x)−∇f(y)∥=Li=1∑d(∣xi∣−∣yi∣)2
Applying the reverse triangle inequality ∣∣xi∣−∣yi∣∣≤∣xi−yi∣⟹(∣xi∣−∣yi∣)2≤(xi−yi)2the absolute value of x i minus the absolute value of y i, squared, is less than or equal to x i minus y i, squared:
∥∇f(x)−∇f(y)∥≤Li=1∑d(xi−yi)2=L∥x−y∥.
We have thus shown that f(x)f of x is C1-continuous and its gradient has Lipschitz constant L, i.e. α=1 with Hölder constant L. It is also bounded by a polynomial of order 2. Without loss of generality, we take a deterministic initialisation μ=0mu equals zero to simplify algebra, yielding;
∇f(μ)=a⟹∥∇f(μ)∥=∥a∥=O(1).
f(x)f of x thus satisfies Assumptions 2, 3 and 4.Assumptions two, three and four. Using f(x)f of x as the fitness:
thereby attaining the upper bound rate of σdd. □
C.2 Critical Convergence Rate
To show that our rate is critical, we investigate the space of functions that can be represented by cubic polynomials of the form:
f(x)=a⊤x+21x⊤Bx+61C[x,x,x],(24)
where a∈Rd,B∈Rd×da in R d and B in R d by d is a symmetric matrix and C[x,x,x]=∑i,j,kci,j,kxixjxk denotes a symmetric 3-linear map represented by the 3-tensor C∈Rd×d×dC in R d by d by d.
Since our theory depends on analysing the local stability of a smooth ball for a fitness function, stability over this class is necessary for convergence on more general objectives. We show that once σdsigma d decays slower than the critical rate, divergence already occurs within this subclass, establishing the sharpness of the rate.
Theorem 2 (Exact divergence for cubic objectives).Let f(x)f of x denote the cubic polynomial in Eq. (24). Assume ∥a∥=O(1),∥B∥=O(1),∥C∥=O(1)the norms of a, B, and C are all order one where ∥⋅∥ denotes operator norm for i-tensor T(x1,…,xi): ∥T∥:=sup∥x1∥=⋯=∥xi∥=1∣T(x1,…,xi)∣. Let Assumption 4 hold, then:
where we have used the fact C(v,μ,⋅)=C(μ,v,⋅) by definition of the symmetry of CC. As C(v,μ,⋅)C of v, mu, dot is linear in vv, its expectation under zero-mean N(0,Id)Gaussian noise is zero, hence:
∇μJ(θ)=∇f(μ)+2σd2Ev∼N(0,Id)[C(v,v,⋅)],
proving our first result. Now, it follows that ∥C(v,v,⋅)∥≤∥C∥∥v∥2the norm of C of v, v, dot is less than or equal to the norm of C times the squared norm of v and as ∥C∥=O(1)the norm of C is order one:
Now as vv is unit Gaussian: Ev∼N(0,Id)[∥v∥2]=dthe expectation of the squared norm of v is d, hence:
∥Ev∼N(0,Id)[C(v,v,⋅)]∥=O(d).
We now show that the bound is tight. Consider the function f(x)=u⊤x∥x∥2f of x equals u transpose x times the squared norm of x for u⊤=d1[1,…,1]u transpose equals one over the square root of d times a vector of ones. The factor of d1 ensures that the gradient of the function ∇xf(x)=O(1)the gradient of f is order one. We can write ∥x∥2the squared norm of x as the tensor contraction:
∥x∥2=Id(x,x),
where IdI sub d is the identity matrix and:
u⊤(x)=u(x),
hence we write f(x)f of x as a tensor contraction as:
f(x)=C(x,x,x),
where C:=Sym(u⊗Id)C is defined as the symmetrization of the tensor product of u and the identity matrix. Using this function:
We now study the effect of EGGROLL in high dimensions. We introduce the notation v=vec(E)v equals the vectorization of E to denote the vectorisation of the low-rank matrix perturbation E=r1AB⊤E equals one over the square root of r, times A B transpose and work in vector space. The EGGROLL vector update vv can thus be written as sum of independent variables:
v=i=1∑rr1ui
with:
ui=vec(aibi⊤),
where recall ai and bia sub i and b sub i are the ith column vectors of A and BA and B. We write μ=vec(M)mu equals the vectorization of M. Using Eq. (13), we can convert between results in vector space and matrix space as:
To extend our analysis, we need to ensure that all polynomial moments of P(v)P of v are finite and grow at most polynomially in the dimension d=mnd equals m times n. In particular, such tail bounds are sufficient to dominate polynomial error terms in our analysis. To introduce sub-Gaussian variables, we follow the exposition of Vershynin (2018)Vershynin and results therein. A random variable xi∈Rx sub i in the set of real numbers is sub-Gaussian if there exists some finite constant C>0C greater than zero such that for all t>0t greater than zero:
P(∣xi∣>t)≤2exp(−Ct2),
meaning their their tails decay like Gaussians. This is equivalent to any of the following three properties holding (Vershynin, 2018, 2.6.1): There exist constants C1,C2,C3>0C one, C two, and C three, greater than zero that differ at most by an absolute constant factor such that:
(E[∣xi∣p])p1E[exp(C22xi2)]≤C1p,∀p≥1,≤2,
and if E[xi]=0the expected value of x sub i is zero:
E[exp(λxi)]≤exp(C32λ2),∀λ∈R.
A random vector x∈Rdx in R d is sub-Gaussian if all one-dimensional marginals of xx are sub-Gaussian, i.e. x⊤ux transpose u is sub-Gaussian for all u∈Rdu in R d. The sub-Gaussian norm is defined as:
which returns the smallest universal sub-Gaussian constant for all marginals.
A key property of sub-Gaussian vectors that we use in our proofs is the sub-Gaussian concentration inequality for the Euclidean norm (Vershynin, 2018, Theorem 3.1.1)detailed in Theorem 3.1.1 of Vershynin 2018, which states that for if xx is a sub-Gaussian vector with E[xi2]=1expected value of x i squared equals one and K=∥x∥ψ2K equals the sub-Gaussian norm of x, there exists an absolute constant C>0C greater than zero such that for all t≥0t greater than or equal to zero,
P(∥x∥−m≥t)≤2exp(−K4Ct2).(25)
the probability that the absolute difference between the norm of x and the square root of m is at least t, is less than or equal to two times the exponential of negative C t squared over K to the fourth
We also use a weaker form of control, that replaces the Gaussian-like tail decay with an exponential decay, but all other properties are defined similarly. In this paper, we use the definition that a variable xx is known as sub-exponential if there exists a K>0K greater than zero such that for all t≥0:
P(∣x∣≥t)≤2exp(−Kt).
Our first result derives a bound on the expected value of the norms ∥a∥i and ∥b∥i:
Lemma 2.Let Assumption 6 hold. Let P(a) denote the distribution over columns of A and P(b) denote the distribution over columns of B. Then:
Ea∼P(a)[∥a∥i]=O(m2i),Eb∼P(b)[∥b∥i]=O(n2i).
Proof. It suffices to prove Ea∼P(a)[∥a∥i]=O(m2i) as Eb∼P(b)[∥b∥i]=O(n2i) follows automatically from the same assumptions. We start by using the ‘layer cake’ representation of the expectation Lieb & Loss (2010 - 2010, Theorem 1.13)from Lieb and Loss, Theorem 1.13:
Ea∼P(a)[∥a∥i]=i∫0∞ti−1P(∥a∥>t)dt.
Let tm=Cm for any C>1. We split the integral into two regions:
For the second integral, we wish to bound P(∥a∥>t) for the region t≥tm=Cm. Setting t′=t−m>0, the assumption C>1 implies t′≥0 in this region, hence
P(∥a∥>t)=P(∥a∥−m>t′)≤P(∣∥a∥−m∣>t′).
We bound this using the sub-Gaussian concentration inequality from Eq. (25). Under Assumption 6, a is a sub-Gaussian vector with ∥x∥ψ2≤∞with a finite sub-Gaussian norm, hence there exists an absolute constant C′>0 such that for all t′≥0,
the expected value of the norm of a to the i-th power is big O of m to the i over two
as required. □
Using this result, we now bound the whole vector v=r1∑i=1rvec(aibi⊤)v equals one over the square root of r times the sum from i equals one to r of the vectorization of a i times b i transpose
Lemma 3.Let i≥1. Under Assumption 6:
Ev∼P(v)[∥v∥i]=O((rmn)2i)
the expected value of the norm of v to the i-th power is big O of the quantity r times m times n, all to the i over two
Our proof borrows techniques used to prove linearisation of the ES update in Section C.1 by bounding the tail probability of any polynomial under the low-rank distribution outside of the ball Bρ(μ)B rho of mu. To apply the concentration inequality that would generalise Lemma 1, we show that vv has an exponentially decaying tail:
Lemma 4 (Exponential Tail Bound).Let r<∞r be finite and Assumption 6 hold. Then all elements of vv are sub-exponential and for dσd=o(1)the square root of d times sigma d is little o of one there exists some constant C>0C greater than zero such that:
P(∥σdv∥≥ρ)≤2dexp(−Cdσdρ).
Proof. In matrix form:
E=r1i=1∑raibi⊤.
The elements of EE are thus:
Ej,k=r1i=1∑raijbik.
As aija i j and bikb i k are independent sub-Gaussian random variables with zero mean, it follows from Vershynin (2018, Lemma 2.8.6)Vershynin that their product aijbika i j times b i k is a zero-mean sub-exponential variable with a uniform norm ∥aijbik∥ψ1<∞psi one norm is finite. Finally, a finite sum of sub-exponential variables is sub-exponential (Wainwright, 2019, Eq. (2.18))according to Wainwright with a uniform norm, so all elements of EE and hence v=vec(E)v equals vector E are sub-exponential and zero-mean with a uniform ψ1-norm K<∞psi one norm K is finite.
We now bound P(∥σdv∥≥ρ)=P(∥v∥≥σdρ). For the vector vv, it follows for t≥0:
∥v∥≥t⟹jmax∣vj∣≥dt.
This is easily proven via the contrapositive: if maxj∣vj∣<dt then
As vjv j is a sub-exponential variable with finite uniform sub-exponential norm, by definition (Vershynin, 2018, Proposition 2.8.1)according to work by Vershynin in 2018 there exists a finite KK such that for all jj:
P(∣vj∣≥dt)≤2exp(−dKt).
Applying to Eq. (26) yields:
P(∥v∥≥t)≤2dexp(−dKt).
Now, using t=σdρt equals rho over sigma d and C=K1C equals one over K yields:
P(∥σdv∥≥ρ)≤2dexp(−Cdσdρ).
We now use these results to assemble into our key polynomial tail bound:
Lemma 5 (EGGROLL Polynomial Tail Bounds).Let Assumption 6 hold. Let g(x) be polynomial bounded as:
∥g(x)∥≤C(1+∥x∥p),
for some finite polynomial of order p and constant C>0. Consider the ball Bρ(μ):={x′∣∥x′−μ∥<ρ}. Let {μ+σdv∈/Bρ(μ)}={∥σdv∥≥ρ} denote the event that a mutation lies outside the ball. Assume σd=o(d−1/2). Then for some constant K>0 independent of d:
Ev∼P(v)[g(μ+σdv)1(Ad)]=O(dexp(−Kdσdρ)),
and in particular the right-hand side is o(1) as d→∞.
Proof. Let
Ad:={μ+σdv∈/Bρ(μ)}
and denote P(Ad):=Ev∼P(v)[1(Ad)]. Our proof proceeds as in Lemma 1 to obtain:
where we have absorbed the factor of 21 into K, hence:
Ev∼P(v)[∥v∥p1(Ad)]=O(d2p+1exp(−Kdσdρ)).
Now, as dσd=o(1)the square root of d times sigma sub d is little o of one, σdpd2p=o(1)sigma sub d to the p times d to the p over two is little o of one, hence:
where the o(1)little o of one bound follows from the fact that the exponential factor dominates dthe square root of d and dσd=o(1)the square root of d times sigma sub d is little o of one. □
Theorem 3 (EGGROLL Convergence to Linearity). Let Assumptions 3, 4, 5 and 6 hold and σd=o(d−1/2)sigma sub d is little o of d to the minus one half and Ld(σdd)2=o(1)L sub d times the quantity sigma sub d times d, squared, is little o of one. Then there exists some K>0K greater than zero such that:
where we have used the fact that the expectation of an odd function under a symmetric, zero mean distribution is always zero, and P(v) satisfies this under Assumption 6, hence Ev∼P(v)[vv⊤∇2f(μ)v]=0, and Ev∼P(v)[vv⊤]=Id from Lemma 6. Consider the ball Bρ(μ):={x′∣∥x′−μ∥<ρ}. We now split the integral into two regions, the first within the ball and the second outside:
Within this region, f(μ+σdv)f of mu plus sigma d v is C2C two continuous under Assumption 5. We can thus write f(μ+σdv)f of mu plus sigma d v using a first-order Taylor expansion about μmu with a Hessian (second order derivative) remainder within the ball:
Now, (for fixed rr) we apply the identity Ev∼P(v)[∥v∥4]=O((mn)2)the expectation of the norm of v to the fourth is order m n squared with mn=dm n equals d from Lemma 3:
Now under Assumptions 3, 4 and 5, f(μ+σdv)f of mu plus sigma d v is polynomial bounded, ∥∇f(μ)∥=O(1)the norm of the gradient of f is order one and ∥∇2f(μ)∥the norm of the Hessian of f is polynomial bounded hence there exists some finite constant C>0C greater than zero and finite polynomial order pp such that:
Now, as σdd=o(1)sigma d times the square root of d is little o of one, the exponential term dominates the prefactor dσd2ddd times the square root of d, over d sigma d squared, we conclude:
We have already shown ∥vec(g^LR)−∇f(μ)∥=o(1)the norm of vec g hat L R minus the gradient of f of mu is little o of one and under the assumptions for this theorem, Theorem 1 holds and so ∥∇f(μ)−∇μJ(θ)∥=o(1)the norm of the gradient of f of mu minus the gradient with respect to mu of J of theta is little o of one. □
D Asymptotic Rank Analysis
For convenience, we work with random vectors in our analysis. We analyse the vector vr=vec(Er)v r, which is the vectorization of E r, which is the vectorisation of the low-rank matrix ErE r. We denote v=vec(E)v, the vectorization of E, which is the vectorisation of the full rank matrix EE. Note v∼N(0,Id)v is distributed as a multivariate normal with mean zero and identity covariance which we denote as P(v)P of v. We write vrv r as a standardised sum of rr independent, zero-mean random vectors. Let
ui=vec(aibi⊤),(28)
u i equals the vectorization of a i times b i transpose
where recall aia i and bib i are the ith column vectors of A and B so:
vr=r1i=1∑rui.
v r equals one over the square root of r, times the sum from i equals one to r of u i
Denoting the covariance matrix of p(u) as Σusigma u, the central limit theorem proves that the distribution of vrv r converges in distribution to a zero-mean Gaussian N(0,Σr)normal distribution with covariance sigma r. In Lemma 6, we derive the covariance matrix for Σusigma u, which we prove is the identity. Our analysis uses an Edgeworth expansion (Bhattacharya & Ranga Rao, 1976)by Bhattacharya and Ranga Rao to characterise precisely the rate at which P(vr)P of v r converges to the limiting Gaussian distribution. In Lemma 7, we make an Edgeworth expansion of P(vr)P of v r to show that it is dominated by O(r−1)order r to the minus one terms and higher. These are then used to prove Lemma 8, which allows us to bound the integral of the remainder of the Edgeworth expansion, thereby characterising how fast P(vr)P of v r converges to the limiting Gaussian distribution.
Lemma 6.Let Assumption 1 hold and uiu i be defined in Eq. (28). Then the variable uiu i has identity covariance matrix:
Σu:=Eui∼p(ui)[uiui⊤]=Id,
has finite 4th-order absolute moments:
Eui∼p(ui)[∥ui∥4]<∞,
and the vector vr=vec(Er)v r is zero-mean and has identity covariance matrix:
Σv:=Evr∼P(vr)[vrvr⊤]=Id
Proof. Under the vec operator, the vector uiu i can be written element wise as:
ui=[a1b1,a2b1,…amb1,a1b2,…ambn]⊤.
We note that all elements in the vector uiu i have zero mean, and so the covariance matrix is the expectation of the outer product:
the expected value of a i b j squared equals the expectation of a i squared times the expectation of b j squared, which equals one
As all elements of a,ba and b and ϵepsilon are zero-mean, off-diagonal elements are zero:
Eai,bj,ak,bl[aibjakbl]=0i=k or j=l.(30)
Using Eqs. (29) and (30), our first result follows:
Σu=Id.
Now, as uiu i is a vector of elements which are sums and products of variables which all have finite 4th order moments from Assumption 1, it immediately follows that uu has finite 4th order absolute moments.
For our final result, we can write vrv r as sum of independent variables:
vr=i=1∑r(r−21ui)=i=1∑rxi,
where xi:=r1uix i is defined as one over the square root of r times u i. As vrv r is a sum of zero-mean vectors, it is also zero-mean. We use the fact that the covariance of rr i.i.d. random variables is equal to the sum of the individual covariances, hence
Using Lemma 6Lemma six, we see the asymptotic Gaussian density of vrv r is a standard normal:
g(vr)=(2π)d1exp(−2∥vr∥2)(31)
g of v r is one over the square root of two pi to the d power, times the exponential of negative norm v r squared over two
which is the density of P(v)P of v, where recall v=vec(E)v equals the vectorization of E, is the vectorisation of the full rank matrix EE.
Although P(vr)P of v r does not have a density in the usual sense for low-rank rr, we can still approximate it with a distribution p^(vr)p hat of v r by making a Taylor series expansion of its characteristic function, which always exists regardless of whether P(vr)P of v r has a well-defined density or not. We now derive the 4th order Edgeworth expansion for P(vr)P of v r. Our proof reveals that 3rd order cumulants control all terms in the expansion that decay at rate O(r−21)big O of r to the minus one half. As 3rd order cumulants are all zero due to symmetry in Assumption 1, the overall decay rate is controlled by O(r−1)big O of r to the minus one terms associated with 4th order cumulants. It is for this reason that we obtain a faster convergence rate than the standard central limit theorem.
Lemma 7. Let Assumption 1 hold and let vr=vec(Er)v r equals the vectorization of E r and uiu i be defined in Eq. (28)equation twenty-eight. Let g(vr)g of v r denote the limiting Gaussian density in Eq. (31). Then, the 2nd order Edgeworth expansion of vrv r is a distribution P^(vr)P hat of v r defined by the approximate density:
is a 4th order Hermite polynomial associated with g(vr)g of v r(Laplace, 1811; Hall, 1992; Withers, 2000).
Proof. We denote the characteristic function of P(ui)P of u i as:
ϕU(ω)=∫exp(−iω⊤u)dP(u),
and the characteristic function of P(vr)P of v r as:
ϕr(ω)=∫exp(−iω⊤u)dP(vr).
Recall vr=r1∑i=1ruiv r equals one over the square root of r times the sum of u i is the sum of rr i.i.d. copies of r1uione over the square root of r times u i. Using the scaling property of the Fourier transform, the characteristic function of r1uione over the square root of r times u i is ϕU(rω)phi U of omega over the square root of r. The distribution of a sum of rr independent random
variables is given by the r-fold convolution of the individual distributions. As convolution in the spatial domain corresponds to multiplication in the frequency domain, the characteristic function of vrv r is (Bhattacharya & Ranga Rao, 1976)Bhattacharya and Ranga Rao, 1976:
φr(ω)=(φU(rω))r
Taking logarithms yields the log-characteristic function:
logφr(ω)=rlog(φU(rω)),=rKU(rω),
where KU(ω):=logφU(ω)K U of omega is defined as the log of phi U of omega. The cumulants are defined by
κi1,…,in(n):=i−n∂ωi1⋯∂ωin∂nKU(ω)ω=0.
The Edgeworth expansion proceeds by a Taylor expansion of rKU(rω)r times K U of omega over the square root of r about ω=0omega equals zero. A 4th order expansion yields:
and using the identity Hi,j,k,l(vr)=g(vr)−1∂vir∂vjr∂vkr∂vlr∂4g(vr), we recover the stated Edgeworth density. □
We now apply key results from Bhattacharya & Ranga Rao (1976)Bhattacharya and Ranga Rao, 1976 to bound the difference in expectation between the low-rank distribution and the Edgeworth approximation as well as the difference in expectation between the true ES Gaussian distribution and the Edgeworth approximation.
Lemma 8.Let f(v):=f(M=μ+σmat(v))f of v be defined as f of M equals mu plus sigma times mat of v, let P(v)=N(0,Id)P of v follow a standard normal distribution, P(vr)P of v r be the distribution of vrv r and P^(vr)P hat of v r be the 2nd order Edgeworth expansion of P(vr)P of v r. Let Assumptions 1 and 7 hold and let vr=vec(Er)v r equal the vectorization of E r and uiu i be defined in Eq. (28). Then:
We show that the three assumptions needed to apply Bhattacharya & Ranga Rao (1976, Theorem 20.1)Bhattacharya and Ranga Rao, Theorem 20.1 to obtain our result using Eq. (32) hold. Firstly, the boundedness assumption of the integrand holds:
vrsup1+∥vr∥∥f(vr)vr∥≤vrsup∣f(vr)∣<∞.
Secondly, the sampling regularity assumption that uiu i (as defined in Eq. (28)) is zero-mean i.i.d. (satisfied under Assumption 1) with finite 4th order moments (satisfied from Lemma 6) holds. Let φU(ω)phi U of omega denote the characteristic function of p(u)p of u, then the final assumption we need to verify is the Cramer condition: limsup∥ω∥→∞φU(ω)<1, which is satisfied from the Riemann-Lebesgue lemma Folland (1999, Theorem 8.22)Folland, 1999 because p0(⋅)p zero is absolutely continuous under Assumption 1 and hence ∣φU(ω)∣→0 as ∥ω∥→∞. Our first result thus follows from applying Bhattacharya & Ranga Rao (1976, Theorem 20.1)Bhattacharya and Ranga Rao:
Now by definition, Hi,j,k,l(v)H i j k l of v is a 4th order Hermite polynomial and under Assumption 7, ∣f(v)∣the absolute value of f of v is bounded, hence ∥v∥⋅∣f(v)∣4!r1∑i,j,k,l∣κi,j,k,l4Hi,j,k,l(v)∣ has polynomial growth of order 5 and is bounded by:
for some finite C>0C greater than zero. As the expectation of a finite order polynomial under N(0,Id)a standard normal distribution is bounded, it thus follows:
Using Lemma 8Lemma eight, we have all ingredients needed derive our main about the convergence result, which follows after some simple algebra on the norm:
Theorem 4.Let Assumptions 1 and 7 hold, then:
∥∇μJ(θ)−g^LRr∥F=O(r−1).
Proof. We start by converting the Frobenius norm to vector form using Eq. (13):
where f(v):=f(M=μ+σmat(v)) and v=vec(E) is the vectorisation of variable E, which is distributed as v∼P(v):=N(0,Id). Let P^(v) be the distribution for the 2nd order Edgeworth expansion, which we derived in Lemma 7Lemma seven. Since P^(vr) and P^(v) are identified as the same Edgeworth-expanded distribution on Rd, we may equivalently write:
Bessel functions are the solutions to systems of differential equations that occur naturally in phenomena where there is strong radial symmetry, typically involving the propagation of spherical waves from points like the ripples formed from water droplets (Whitham, 1999) . For our setting, Bessel functions describe the
probability density of the product of rotationally invariant random variables, whose solution is analogous to the interference pattern of two spherical wave propagators.
Using the representation, we find the derivative of the zeroth order function takes the recursive form:
More generally, the derivative of the nth order Bessel function is Watson (1944, Section 3.71, Eq. 4)Watson, 1944:
dzdKn(z)=znKn(z)−Kn+1(z).(34)
D.2 Derivation of Mean-field Approximators
To derive a mean-field approximation, we assume that the elements of AA and BB are drawn independently from the set of generalised Gaussian distributions (GGDs):
Assumption 8.Assume each element ai,j∼GG(s,p)a i j distributed as G G of s and p and bi,j∼GG(s,p)b i j distributed as G G of s and p of AA and BB is independently distributed according to the zero-mean generalised Gaussian distribution GG(s,p) with density:
GG(x∣s,p)=2sΓ(p1)pexp(−sxp),
where 0<s<∞s is between zero and infinity is the scale parameter, p>0p is greater than zero the shape parameter and Γ(⋅)gamma is the gamma function.
We observe common distributions emerge from the set of GGDs including the Laplace for p=1p equals 1, the Gaussian for p=2p equals 2 and the uniform over [−s,+s] in the limit p→∞as p approaches infinity.
If we make the assumption that all elements of EE are independent (this is true as rr grows) then we can write p(E)≈p^(E):=∏i=1m∏j=1np(Ei,j) as the product of the marginal distributions. Under this approximation, the score function can be defined element-wise as:
[∇Elogp(E)]i,j≈S^(Ei,j):=∂Ei,jlogp(Ei,j).
Using this approximation we apply the score function S^(⋅)S hat element-wise to the matrix EE:
gLR≈g^MF:=−σ1EE∼p(E)[f(W=M+σE)⋅S^⊙(E)].
For r=1r equals 1, S^(⋅)S hat has a convenient analytic form for all members of the set of GGDs:
Theorem 5.Let Assumption 8 hold and r=1r equals 1. Then the distribution over marginals p(Ei,j) is:
p(Ei,j)=(sΓ(p1))2pK0(sp2∣Ei,j∣2p),(35)
where K0(⋅)K sub zero is the zeroth-order modified Bessel function of the second kind and the marginal score function is defined element-wise as:
Proof. For r=1, we denote the elements of vector A as ai and elements of vector B as bj, then the elements of matrix E=AB⊤ are: Ei,j=aibj. We now derive the distribution of the unnormalised variables: Ei,j
using the formula for the distribution of the product of two independent random variables (Rohatgi, 1976; Grimmett & Stirzaker, 1993)Rohatgi 1976, and Grimmett and Stirzaker 1993:
where we have used symmetry of the integrand about 0zero to derive the final line. Now, making the substitution x=(sai)px equals a sub i over s, to the power of p, we have:
Proof. Each element Ei,jE i j is the sum of rr independent variables ui,j,l:=ai,lbj,lu i j l, defined as a i l times b j l distributed according to Eq. (35) with p=2p equals two:
Ei,j=r1l=1∑rai,lbj,l=r1l=1∑rui,j,l.
Let Zi,j=rEi,jZ i j equals the square root of r times E i j, hence:
Zi,j=l=1∑rui,j,l.
We first find the density p(Zi,j)p of Z i j. From Eq. (35), the distribution of each ui,j,lu i j l is:
p(ui,j,l)=s2π2K0(s22∣ui,j,l∣)
We use the fact that the PDF of a sum of rr independent random variables (i.e. Zi,jZ i j) is given by the rr-fold convolution of the individual PDFs. As convolution in the spatial domain is equal to multiplication in the frequency domain, the PDF p(Zi,j)p of Z i j follows by taking Fourier transform of p(ui,j,l)p of u i j l, taking the power rr and then taking the inverse Fourier transform:
p(Zi,j)=(s2π2)rF−1[(F[K0(s22∣⋅∣)])r](Zi,j),
where recall from Section A with d=1d equals one, F[f](ω):=∫f(x)exp(−iωx)dxF of f of omega is the integral of f of x times e to the minus i omega x denotes the Fourier transform and F−1[f~](x):=2π1∫f~(ω)exp(iωx)dωthe inverse Fourier transform. Taking the Fourier transform of the Bessel function:
where we have used the fact that K0(s22∣x∣)K zero is an even function of xx and so its integral with sin(ωx)sine of omega x in the second line is zero. Using a standard result, we can evaluate the integral in Eq. (36)Gradshteĭn et al. (2015, 6.671 Integral 14)Gradshteĭn and colleagues:
where we have used the fact that the integrand is an even function and so its integral with sin(ωZi,j)sine of omega Z i j is zero to derive the penultimate line. To evaluate the integral in Eq. (37) we apply Gradshteǐn et al. (2015, 3.771 Integral 2)Gradshtein and colleagues:
All timings were done on a single GPU on a GH200 (equivalent to a single H100) for a linear model with dimension 8192 in bfloat16, allowing a maximum batch size of 1024. For the graph in Figure 2a, we pre-generate the noises instead of integrating the noise generation into the forward pass.
Figure 7: Relative speed of EGGROLL, when including jax noise regeneration.
In Figure 7, we consider the impact of regenerating noises on-the-fly using jax PRNG. The darker area and value in parenthesis for EGGROLL and OpenES indicate the speed when regenerating noises on-the-fly, while the full bar indicates the speed when the noises are already generated.
We regenerate noises on the fly in our primary jax codebase, but pre-generating the EGGROLL perturbations beforehand is also a practical possibility since low-rank perturbations only require a small amount of memory, proportional to the square root of the size of the original parameter matrices.
F Arithmetic Intensity Analysis
In this section, we derive the arithmetic intensity of standard batched inference, Gaussian matrix ES, and EGGROLL. We calculate arithmetic intensity as the number of operations divided by the total number of bytes read from or written to. For context, for the (b)float16 datatype on an H100 GPU, there are approximately 1000 teraFLOPS of compute (without sparsity) and 3.35 TB/s of GPU memory bandwidth, meaning that the roofline threshold is approximately 300 ops/byte, defined as the minimum for computation needed for it to be the bottleneck instead of memory movement.
In the following subsections, we are considering a single linear layer with mean parameter M∈Rdout×dinM in R dimensions d out by d in and a batch of inputs u∈RB×dinu in R dimensions B by d in. All operations occur with a precision of ss bytes per element.
F.1 Arithmetic Intensity of Standard Batched Inference
In standard batched inference, we wish to simply calculate uMTu times M transpose. The total bytes read as input are B×din×sB times d in times s (for uu) and dout×din×s (for MM), and the total bytes written as output are B×dout×s. The total number of operations are B×din×dout×2 since matrix multiplication requires both multiplications and additions for each element of uu across all of doutd out. Therefore, the arithmetic intensity is:
B×din×s+B×dout×s+dout×din×sB×din×dout×2.
When s=2s equals 2 (for (b)float16) and dout=din=md out and d in both equal m, the arithmetic intensity simplifies to
2B+mBm.
The batch size needed to achieve a desired arithmetic intensity of AA is derived as follows:
BmBm−2ABB=2AB+Am=Am=m−2AAm
Therefore, achieving an arithmetic intensity of 300 ops/byte with m=8192m equals 8192 requires a minimum batch size of 324.
F.2 Arithmetic Intensity of Gaussian Matrix ES
In Gaussian matrix ES, we assume access to pre-generated perturbations of shape RB×dout×dinof dimensions B by d out by d in. The total bytes read as input are B×din×s (for uu) and B×dout×din×s (for MM), and the total bytes written as output are B×dout×s. Otherwise, the total number of operations is identical to standard batched inference, giving us an arithmetic intensity of
When s=2s equals 2 (for (b)float16) and dout=din=md out and d in both equal m, the arithmetic intensity simplifies to
2+mm.
This means that arithmetic intensity is always strictly less than 1, regardless of batch size or dimensionality. The common way to increase arithmetic intensity is to bring it closer to standard batched inference, reusing the same perturbation across multiple inputs. For instance, when m=8192m equals 8192, achieving an arithmetic intensity of 300 ops/byte requires that each perturbation is reused at least 324 times, and smaller values of mm need to be reused even more often.
F.3 Arithmetic Intensity of EGGROLL
For EGGROLL, we assume access to the pre-generated decomposed perturbations A∈RB×dout×rA in R dimensions B by d out by r and B∈RB×din×rB in R dimensions B by d in by r. Therefore, the bytes read as pure input are B×din×s+B×(din+dout)×r×s+dout×din×s and the bytes written as pure output are B×dout×s. However, the efficient low-rank perturbation calculation requires writing and reading an intermediate matrix of shape B×r, so the total bytes read are
(B×din+B×(din+dout+2)×r+dout×din+B×dout)×s.
The total number of operations includes the amount for standard batch inference, B×din×dout×2, along with the rank-rr perturbations, B×(din+dout)×r×2, and the final sum between the main calculation and perturbation B×dout. Therefore, the arithmetic intensity is
Note that the only difference with the critical batch size of standard batched inference is the additional 2r+21−rA(2+m2) in the denominator. Therefore, achieving an arithmetic intensity of 300 ops/byte with m=8192 and r=1 requires a minimum batch size of 352, compared to 324 for standard batched inference. This means that EGGROLL can saturate compute with unique perturbations per input, unlike Gaussian matrix ES.
Note that there is an overhead of Bm(4r+1)B m times, 4 r plus 1 flops relative to standard batched inference, resulting in an additional compute rate of 2Bm2Bm(4r+1)=2m4r+1, which is effectively negligible for large enough matrices.
G EGG Architecture
In the following section, we detail the design of our EGG model, which follows the high-level structure of modern pre-layernorm decoder-only language models, but replaces self-attention with a modified minGRU and standard layernorms with a custom variant to enable pure integer training. See Algorithm 2 for an overview of the forward pass of the EGG architecture.
Algorithm 2 EGG forward pass
Require: Input token t∈U8, input state s∈I8l×D, network parameters θ Ensure: Output vector y∈I8D and output state s′∈I8l×D s′←I8l×D initialised to 0 y←EMBED(θemb,t) fori∈{0,…,l−1}do y′,si′←GRU(θgru,i,LN(θln1,i,y),si) y←I8(I32(y′)+I32(y)) y′←MLP(θmlp,i,LN(θln2,i,y)) y←I8(I32(y′)+I32(y)) end for y←LN(θlnout,i,y)@θheadT
G.1 Motivation
Since EGGROLL does not rely on gradients, we can explicitly design a language model architecture to be efficient and hardware-friendly at inference time. In particular, we design EGG under the following constraints to emphasise the flexibility of EGGROLL:
Pure Integer Training: On H100 systems, int8 is the fastest datatype and int8 matrix multiplication with int32 accumulation is the fastest tensor core operation. Furthermore, integer datatypes are much simpler to implement in hardware, providing massive energy savings for high-throughput systems (Horowitz, 2014). Therefore, we keep all weights in int8 and all activations in integer formats, never casting to floating point at any point during training. This stands in contrast to the standard approach for language model quantisation through “quantisation aware training” with backpropagation, where floating point activations are still necessary (Wang et al., 2023).
Nonlinear RNN: Modern language models use sequence-parallel architectures like Transformers and SSMs, since they enable stable gradients without backpropagation through time. However, most of these architectures cannot handle simple state tracking (Merrill et al., 2024), whereas classic recurrent networks like LSTMs and GRUs can do so with a single layer. Since EGGROLL does not require backpropagation through time, we can train on unbounded sequence lengths (Li et al., 2023) with nonlinear RNNs of broader complexity classes. Specifically, we develop a variant of the minGRU model (Heck & Salem, 2017) that performs all operations in integer formats.
Removal of all Activation Functions: Inspired by Foerster (2017)prior work, we remove all activation functions, like the rectified linear unit and hyperbolic tangent, due to the nonlinearity present in the int8 datatype. Specifically, the saturated addition of int8 values provides sufficient nonlinearity due to the implicit clipping of values to the int8 dynamic range, which evolution strategies can exploit.
G.2 Notation and Operations
We use the constant l∈Z+l in the set of positive integers to denote the number of layers of the model and D=4dD equals four to the d as the hidden dimension of the model, where d∈Z+d in the set of positive integers.
We use InI sub n to denote an n-bit signed integer and UnU sub n to denote an n-bit unsigned integer. We denote casting vector u to format In as In(u)I sub n of u, which implicitly includes clipping to the bounds of the datatype. To ensure symmetry between positive and negative values of each datatype, we consider the value −2n−1minus two to the n minus one to be invalid for datatype In; for instance, for 8-bit signed integers we only allows value from -127 to 127.
We use the following operations:
u@M indicating scaled vector-matrix multiplication of I8n×I8n,m→I8mu at M, indicating scaled vector-matrix multiplication from i 8 n and i 8 n by m to i 8 m, corresponding to int8 tensor core multiplication with int32 accumulation and scaling. The details of this operation are described in Section G.4.
a⋅ba dot b indicates dot product with int32 accumulation, I8n×I8n→I32from i 8 n and i 8 n to i 32, and a⊙b indicates the Hadamard (elementwise) product.
Standard integer operations: + for addition, − for subtraction, and ⊙ for element-wise multiplication.
∣u∣ indicates taking the element-wise absolute value of uu, In→In.
sign(u) indicates taking the element-wise sign of uu, giving 1 for positive values, -1 for negative values, and 0 for zero.
sum(u) indicates taking the sum of all elements in uu (casting to I32 to prevent overflow): In→I32.
u≫n indicates an elementwise bitwise right shift by nn, which is typically equivalent to 2−nu. Similarly, u≪n indicates a bitwise left shift by n, which is typically equivalent to 2nu.
Square-bracket indexing. For instance M[i,j] extracts the element at index i in axis 0 and index j in axis 1, following the zero-based indexing convention.
G.3 Parameter Initialisation
The standard initialisation for matrix parameters in our model is rounding 16 times a sample from the standard normal, and casting to I8. This can be precomputed on a CPU since this is only done once at the start of training.
The egg model has the following parameters (where an additional subscript of ii indicates that there is a version of this parameter for each layer of the model):
θemb∈I8256×Dtheta emb in i 8 of size 256 by D, following standard initialisation.
θhead∈I8256×Dtheta head in i 8 of size 256 by D, following standard initialisation.
θlnout∈I8Dtheta l n out in i 8 D, initialised to 16 for each element.
θln1,i,θln2,i∈I8Dtheta l n 1 i and theta l n 2 i in i 8 D, initialised to 16 for each element
θmlp,i,1∈I84D×D and θmlp,i,2∈I8D×4Dtheta m l p i 1 of size 4 D by D and theta m l p i 2 of size D by 4 D, both in i 8, following standard initialisation.
θGRU,i,[Wf,Uf,Wh,Uh]∈I8D×Dtheta G R U i for the weights in i 8 size D by D, following standard initialisation.
θGRU,i,[bfm bh]∈I8Dtheta G R U i for the biases in i 8 D, initialised to 0 for each element.
In total there are 513D+l(4D+12D2)513 D plus l times the quantity 4 D plus 12 D squared parameters in the model.
G.4 Matrix Multiplication
Tensor cores in GPUs are able to calculate fast vector-matrix multiplications with int32 accumulation as uM∈I32mu M in i 32 m where u∈I8nu in i 8 n and M∈I8n×mM in i 8 n by m. For our purposes, we define u@M as a scaled multiplication:
u@M:=I8(16nuM).
u at M is defined as the i 8 casting of u M divided by 16 times the square root of n
Note that when n=4dn equals 4 to the d, the division operation just becomes a right-shift by 4+d, which is fast to calculate.
We choose this scaled matrix multiplication because we initialise M to 16 times standard normal samples for each element, so dividing by 16n preserves the magnitude of u for the output. In particular, if all elements of u and M are drawn from independently from the standard normal distribution multiplied by 16, the central limit theorem tells us that the expected value per element of the output will be 256n, so dividing by 16n preserves the standard deviation of 16.
G.5 Embedding
Our embedding function takes as input an embedding matrix θemb∈I8256×Dtheta emb in the set of 8 bit integers of shape 256 by D and an input token t∈U8t, an 8 bit unsigned integer, and simply outputs the vector corresponding to that token: θemb[t]∈I8Dtheta emb of t, in the set of 8 bit integers of length D.
G.6 Layer Normalisation (LN)
Our layer normalisation operation involves multiplying our input u∈I8Du with a weight θln∈I8Dtheta l n before dividing by the mean absolute value of uu.
We decide to divide by the mean absolute value of the input instead of the more common root-mean-squared since square roots are expensive on integers. Note that the L1 norm after dividing the input by the mean absolute value (when using real numbers) is D instead of 1, which we intentionally choose to preserve more bits of information given the limited range of I8the 8 bit integer range.
We calculate the mean absolute value of input uu as:
umav=I8(sum(∣u∣)≫(2d)),
u m a v equals the 8 bit integer conversion of the sum of the absolute values of u, bit shifted right by 2 d
Note that we can safely cast the mean absolute value to an I88 bit integer without overflow given the properties of the mean of a set, though we lose precision due to truncating the fractional component.
The output of layernorm is calculated as:
DIVIDE(I16(u)⊙I16(θln),umav).
divide the element-wise product of 16 bit versions of u and theta l n by u m a v
Since division is an expensive operation, we precompute it using a lookup table. Note that the product of two I88 bit integer values will always remain in the dynamic range of I1616 bit integers, so our lookup table will be of shape 216×28.
G.7 MLP
Each MLP block consists of two weight parameters: θ1∈I84D×D and θ2∈I8D×4Dtheta one of shape 4 D by D, and theta two of shape D by 4 D. Given an input u∈I8Du, we calculate the output as:
(u@θ1T)@θ2T.
u matmul theta one transpose, matmul theta two transpose
Note that we do not use an activation function, because the @ operation is already nonlinear due to the saturated conversion from I32 to I8
G.8 GRU
Each GRU block accepts an input vector and state u,s∈I8Du and s consists of 6 weight parameters: θWf,θUf,θWh,θUh∈I8D×D and θbf,θbh∈I8Dtheta W f, theta U f, theta W h, and theta U h of shape D by D, and bias terms theta b f and theta b h.
Using these weight matrices, we calculate the following vectors:
where h is the output and the new hidden state. In the typical GRU, σ stands for the sigmoid function while ϕ stands for the hyperbolic tangent, but we find that setting these as identity operations is sufficient due to the nonlinearity already present in the clipped addition. One can view this clipped addition operation as scaled and shifted version of the “hard” tanh and sigmoid operators.
To explain why we perform these operations, we can analyse this relative to the original GRU. The f vector for the standard GRU has all elements between 0 and 1 due to the sigmoid, but our elements are between -127 and 127. Therefore, to calculate f^ (which is typically just f⊙s), we first add 127 to f, getting the range between 0 and 254 before multiplying by s before bit-shifting right by 8 again to bring our values back to the I8 dynamic range. We apply similar logic to calculate the final h, which is typically just h=s+f⊙(h^−s) but needs to be rescaled to keep the int8 dynamic range.
G.9 Fitness Calculation in Integer Types
The “fitness” used in language model pretraining is the log-likelihood of correctly generating the next token, treating the outputs of the language model as logits (unnormalised log probabilities). If t′∈U8t prime in the set of unsigned 8 bit integers is the next token to predict and y∈I8256y in the set of 256 dimensional signed 8 bit integer vectors are the logits, we can calculate the log likelihood as follows:
y′o=I32(y)+128,=y′[t′]−LOG2[sum(EXP2[y′])],
y prime equals y cast to 32 bit integers plus 128, and o equals y prime at index t prime minus the LOG 2 of the sum of EXP 2 of y prime
where oo is the loss for one token. We implement EXP2 and LOG2 as lookup tables, where
EXP2[i]LOG2[i]=16×2i/16,=16×log2(i/16).
Note that each element in EXP2 for any U8unsigned 8 bit input requires at most 20 bits, so the sum of exponents across all possible choices is at most 28 bits, meaning we have to precompute LOG2 for 2282 to the 28th values.
H EGG Pretraining with Integer EGGROLL
The core ideas of EGGROLL still apply in this integer-based training setting, but we have to make some modifications to ensure it only uses integer operations.
H.1 Adding EGGROLL Perturbations
For parameter θ∈I8m×ntheta in I 8 of dimensions m by n that represents a matrix multiplication, we first sample rank-1 perturbation vectors for each index in the batch: A∈I8mA and B∈I8nB. We sample these vectors from the standard random normal multiplied by 16 and rounded to the nearest I88 bit integer (clipping if necessary). To prevent the use of floating-point arithmetic on the accelerator, we pre-generate a large matrix of these random values, randomly indexing into it to get the perturbation vectors.
Given an input u∈I8nu, instead of calculating u@θTu times theta transpose, we calculate
I8(16nuθT+((u⋅B)I32(A)≫(4+σ^))).
The value of σ^sigma hat is a hyperparameter, related to the σsigma in the main paper as σ=2−σ^sigma equals 2 to the power of negative sigma hat. Note that the batched forward pass remains efficient since it still simply performs a batched vector-vector dot product in int8 (with int32 accumulate) and a batched vector-scalar product in int32.
We apply this same logic to the embedding matrix, since we can interpret θ[t]theta of t as one_hot(t)θa one hot encoding of t times theta and still apply our rank-1 updates in that context. In practice, this means replacing u⋅Bu dot B with B[t]B of t.
H.2 Fitness Shaping
We employ a simple fitness shaping scheme based on antithetical pairs. Specifically, given raw fitnesses s+,s−s plus and s minus, for the positive and negative sample of the antithetical pair respectively, the transformed fitness for the noise is:
sign(s+−s−),
Note that the only possible values for the fitness after shaping are {−1,0,1}.
H.3 Parameter Update
For parameter θ∈I8m×ntheta that represents a matrix multiplication (or embedding vector), suppose the sampled batch of rank-1 perturbation vectors are A∈I8N×mA and B∈I8N×nB, and let the fitnesses after shaping be F∈I8NF. Then we calculate an intermediate value E∈I32m×nE as:
E=(diag(F)A)TB.
We use EE to determine if each element of θtheta should be increased or decreased. In particular, when the absolute value of E is above a pre-specified threshold we move θ by one discrete bin in the direction of the sign of E. Since there are only 255 unique values for each element in I8the set of 8 bit integers, restricting updates to single bins improves stability without compromising the ability for a parameter to get to any other value with relatively few updates. In particular, we have a real-valued hyperparameter, α∈(0,1)alpha between zero and one such that the threshold equals
I32(16×Φ−1(21−α))×16N,
where Φphi is the normal cumulative distribution function. Note that this threshold can be precalculated on a CPU. We observe that α approximately equals the fraction of parameters that are updated at each step.
We currently do not incorporate any momentum or other optimiser states, but this remains critical future work to improve the speed of convergence for pure integer training.
Across model sizes and population size, we find that setting σ^sigma hat to 4 and letting α decay over training steps as .015t+11 gives consistently strong results.
I EGG Ablations
In our main experiments, we use a fixed data batch size of 16 sequences for population sizes 2 and powers of 4 ranging from 4 to 410=1048576four to the tenth power, or one million forty eight thousand five hundred seventy six. In this section, we vary the batch size by powers of 4, ranging from 4 to 45=1024four to the fifth power, or one thousand twenty four, while varying population size by powers of 4 from 16 to 1048576. When the batch size, bb is greater than half of the population size, NN, we give each antithetical pair N2b sequences, functionally giving a cleaner fitness signal to each member of the population. This also means that the number of parallel “inferences” required is max(2b,N).
Figure 8: Test loss curves when varying data batch size and population size.
In Fig. 8, we observe that the final test loss for each population size is relatively constant beyond a specific data batch size threshold. At the top right of the figure, we observe a decrease in loss for small population sizes after b>2Nb is greater than N over two, which is an artifact of the increased compute usage necessary to use the full data batch. Ignoring this artifact, the minimum batch size for near-optimal performance at a given population size N appears to be 46NN over four to the sixth. We see that large population sizes need larger data batches for improved performance, since a batch size of 4 results in nearly identical performance for population sizes 49=262144 and 410=1048576, but this diverges as data batch size increases.
J Distributed EGGROLL Framework
To facilitate the large-scale experiments, where we scale population sizes beyond 1M, we develop a lightweight distributed training framework designed to minimise network overhead.
J.1 Base-3 Fitness Packing and Bandwidth Efficiency
A key bottleneck in distributed training is the communication of gradients or results. We address this via a custom base-3 packing scheme for fitness vectors. Since workers evaluate perturbations in antithetic pairs, the raw signal is discretised into ternary values {−1,0,+1}. These are mapped to {0,1,2} and packed five at a time into a single byte:
byte=i=0∑4vi⋅3i
This yields an effective bitrate of 1.6 bits per value (near the log23≈1.585log base two of three, approximately one point five eight five theoretical limit). Consequently, the network payload per chunk is approximately 52+chunk_size/10 bytes, rendering bandwidth usage independent of model size.
J.2 System Architecture
The system employs a Coordinator-Worker topology. The Coordinator maintains the global state and assigns population chunks to Workers. Workers calculate fitness on GPU, apply signal shaping (chunk mean filtering, adaptive thresholding), and return only the packed ternary fitness, minimising traffic significantly compared to standard gradient transmission.
K Fine-tuning of Integer Quantised Models
K.1 Quantisation Procedure
To maximise population throughput and reduce device memory during EGGROLL fine-tuning, we represent the large matrix-multiplication parameters of RWKV in an int8 weight format while keeping non-matmul parameters (e.g., small biases / bookkeeping tensors) in floating point, bf16. Following Jacob et al. (2017)Jacob and colleagues, for each weight matrix W∈Rdin×doutW of dimensions d in by d out, we use symmetric per-channel int8 quantisation with an absmax scale. For each output channel we first compute:
si=max(127maxj∣Wi,j∣,ϵ),
where ϵepsilon is some small scalar. Then, we store each sis i in bf16, and quantise weights as
Qi,j=clip(round(siWi,j),−127,127)∈I8.
Every matrix parameter is stored as a dictionary containing the quantised weight matrix Q, the scale parameters per channel {si}∀i∈1,…,dout and an input scale factor sx in bf16 precision. At runtime, the forward pass is computed by scaling the input vector by sx and the quantised matrix Q with the scales per channel, [s1,…,sdout],
xn+1=(xn⊙sx)T(W⊙[s1,…,sdout]).
K.2 Integrating integer-quantised EGGROLL with Adam
EGGROLL performs black-box (ES) optimisation directly over the parameter representation used in the forward pass, including integer quantised weights. We integrate this with the Adam optimiser (Kingma & Ba, 2014)of Kingma and Ba by maintaining Adam’s moment estimates in bf16, while enforcing that all quantised tensors remain on the int8 lattice.
ES gradients. EGGROLL estimates gradients via antithetic ES perturbations and score-weighted averaging.
This yields a bf16 gradient estimate for: (i) floating-point parameters (when present), (ii) quantised matrix
parameters via a low-rank perturbation pathway, and (iii) scale parameters {si}∀i∈1,…,douts i for all i from 1 to d out and sxs x via
explicit scale perturbations. We then pass these gradients to Adam (Optax), which produces an update tensor uu
for each parameter leaf.
Adam updates for int8 tensors (discretised). For integer parameters (notably int8), Adam produces a
real-valued proposal uu (stored in bf16). Since the parameter itself must remain int8, we convert this proposal
into a sparse unit-step update using a normalised thresholding rule. Let Q∈Z8m×nQ be an int8 tensor and u∈Rm×nu be Adam’s proposed update. We compute a per-tensor z-score normalisation
z=σ(u)+10−8u−μ(u),
then apply a threshold τtau to form the integer step
Δ=sign(z)⋅1{∣z∣≥τ}∈{−1,0,+1}m×n.
Finally we update by unit increments and clip to the valid int8 range:
Q←clip(Q+Δ,−127,127).
Intuitively, Adam supplies a magnitude- and history-aware proposal, while the discretisation enforces the
integer constraint and yields a stable, sparse update pattern (only entries with sufficiently large normalised
updates are modified).
Memory considerations. We store Adam’s optimiser state (moments) in bf16 for all array-valued leaves
to reduce memory footprint, while keeping scalar bookkeeping in full precision. This keeps the dominant
memory cost of optimisation close to that of the parameters themselves, which is particularly important when
fine-tuning large models with large ES populations.
Model distillation. We distil a non-quantised model into the quantised RWKV-7 model by matching the
two distributions in teacher forced examples from GSM8k. More specifically, the fitness for a given set of
parameters, μimu i, is computed as follows:
fμi(x1:T)=t=1∑TKL(pt∣∣qt(⋅;μi)),
the fitness is the sum over time steps t of the K L divergence between the distribution of the non-quantised model p t and the distribution of the quantised model q t
where x1:Tx 1 through T is a subsequence of tokens taken from the solutions of GSM8K and KL(pt∣∣qt(⋅;μi)) is the
Kullback-Leibler divergence between the distribution of the non-quantised model, ptp t, and the distribution of
the quantised model qtq t over the vocabulary at token tt.
L Fine-tuning Pretrained Transformer LLMs with Verifiable Rewards
This section describes compares EGGROLL to standard RL from Verifiable Rewards (RLVR). We first describe
our experimental results, before including details of the infrastructure used to run these experiments.
L.1 Results
Here we demonstrate that EGGROLL can be used to fine-tune pre-trained LLMs on verifiable rewards.
We use the vLLM library Kwon et al. (2023)Kwon and colleagues for efficient inference. More infrastructure detail is given in
Section L.2.
We first fine-tune the Qwen3-4B-Base model Yang et al. (2025)Yang and colleagues on the DeepScaleR Agentica Organization et al. (2025)Agentica Organization and colleagues, a dataset of 40k maths questions. As in standard RLVR, the model generates a chain-of-thought (CoT)
followed by a final answer. Fitness is then simply calculated by extracting the final answer and comparing it to
the ground truth answer Shao et al. (2025)Shao and colleagues. We evaluate performance on MATH500 Hendrycks et al. (2021)Hendrycks and colleagues,
OlympiadBench He et al. (2024)He and colleagues, AIME24 Balunović et al. (2026)Balunovic and colleagues, AMC, and MinervaMath Lewkowycz et al. (2022)Lewkowycz and colleagues. Training curves are shown in Figure 9. Here we see that fine-tuning with EGGROLL significantly
improves performance over the base model. In Section L.1 we show final accuracies with EGGROLL and with the equivalent RL experiment. The RL values are taken from Liu et al. (2025)Liu and colleagues, and we match all the relevant shared hyperparameters and setup, such as maximum response length and prompt phrasing. We see that EGGROLL is able to match the RL optimisation with very minimal hyperparameter tuning, a LoRA rank of 1 and a moderately small population size of 2048. Full hyperparameter details are given in Table 3.
Figure 9: Training curves for fine-tuning Qwen3-4B-Base on the DeepScaleR math dataset. Similar to RL from Verifiable Rewards (RLVR), we see that optimising with EGGROLL is able to improve chain-of-thought reasoning performance on a range of math benchmarks.
MATH500
OlympiadBench
AIME24
AMC
MinervaMath
Average
Qwen3-4B-Base
50.2
24.4
10.0
33.7
21.7
28.0
+EGGROLL
75.8
37.3
13.3
49.4
31.3
41.4
+RL
67.4
33.5
16.7
49.4
40.1
41.4
Table 1: Final test accuracies when training on the DeepScaleR dataset to optimise verifiable rewards with EGGROLL and RL. We see that EGGROLL significantly boosts performance from the base model and is able to match the equivalent RL experiment.
Since EGGROLL can be used to optimise non-differentiable objectives we next try optimising for pass@kpass at k. While zero-shot (pass@1pass at one) is differentiable, the pass@kpass at k objective is not as it depends on multiple samples from the model. This means it cannot be optimised easily with RL. In Figure 10 we fine-tune the Qwen3-1.7B model on the DeepScaleR dataset with a population size of 256, LoRA rank 1, and K=4K equals four. We see that EGGROLL successfully optimises both the pass@1pass at one (differentiable) and pass@kpass at k (non-differentiable) objectives. In Figure 10 (right) we plot the number of distinct answers in 4 samples from the model. We see then when optimising for pass@kpass at k the answer diversity sampled by the model increases over training, whereas when optimising for zero-shot (pass@1pass at one) the model collapses towards a single final answer.
L.2 Training Infrastructure for Large-Scale Transformer LLMs
EGGROLL facilitates the fine-tuning of transformer-based LLMs at scale. We achieve this by repurposing the vLLM inference engine, leveraging its high-throughput kernel implementations and native support for multi-LoRA serving. The system utilises vLLM’s native Tensor Parallelism (TP) to shard the model weights across the GPUs within a node, while cross-node parallelisation is employed for the concurrent evaluation of the LoRA population.
To render ES-based optimisation feasible and efficient across a wide range of model sizes, we implement several critical systems-level optimisations:
Custom WorkerExtension and Sharding-Aware Updates By implementing a custom WorkerExtension, we effectively convert the vLLM inference engine into a training-capable runtime. This extension allows the optimisation logic to reside within the GPU process space, enabling direct,
Figure 10: Using EGGROLL to optimise non-differentiable objectives. Left: Fitness curves comparing training with pass@1 (differentiable) versus pass@k (non-differentiable), where K=4K equals 4. Right: The mean number of unique final answers generated per 4-sample set. We observe that when optimizing for pass@k increases answer diversity, whereas optimizing for zero-shot accuracy (pass@1) reduces it.
in-place manipulation of the model’s weights. A significant complexity of this integration is vLLM’s internal tensor parallelism, which frequently fuses weights (e.g. combining q_proj, k_proj, and v_proj into a single qkv_proj tensor). Our update mechanism is explicitly “sharding-aware”; it constructs a dictionary which maps individual LoRA updates to the specific fused slices held by each local GPU rank. This ensures that the global ES update is mathematically consistent across all distributed shards.
Layer-wise Memory Management To prevent out-of-memory (OOM) errors during the update phase, the WorkerExtension performs the ES weight application in a streaming, layer-wise fashion. By processing one layer at a time and clearing temporary buffers, the memory overhead of the update remains independent of the total model depth. This allows for the fine-tuning of models of very different sizes with a VRAM footprint barely exceeding that of standard inference.
Direct GPU-to-GPU Weight Synchronization After computing the ES update on the primary rank, we broadcast the updated parameters to all model instances using NCCL via PyNcclCommunicator. This approach bypasses CPU-based communication and instead uses hardware interconnects to transfer weights directly between GPUs, preventing synchronization from becoming a bottleneck when scaling to more nodes.
Meta-Device Blueprinting To initialise models that exceed the physical RAM of the control node, we employ Meta-Device Initialisation. Using accelerate’s init_empty_weights, we instantiate a “meta” version of the model to derive the weight shapes and sharding requirements for the LoRA adapters. This allows the system to generate a complete parameter blueprint for models of arbitrary size without ever allocating the full weight tensors in system memory.
vLLM Engine Settings Throughout the different experiments with vLLM, we use the following engine settings. These generally allow for high throughput across model sizes (e.g. at least 800 tokens/second), but we haven’t performed hyperparameter sweeps, so potentially faster, more memory-efficient settings may be used for improved results.
Parameter
Value
Tensor parallel size
2, 4
Data type
auto
Enable prefix caching
True
Enforce eager execution
True
Enable LoRA
True
Max LoRAs
⌈population_size/num_engines⌉
GPU memory utilisation
0.90
Max number of sequences
384
Max model length
max(1024,512+max_tokens)
Max batched tokens
prompt_batch_size×1024
Load format
auto
Table 2: vLLM engine configuration parameters to allow for high throughput EGGROLL training on large-scale transformer LLMs.
Parameter
Value
Population size
256, 2048
Sigma
0.001
Learning Rate
0.001
Max Response Length
4096
Temperature
0.0, 0.7
Samples Per Prompt
1, 4
Pass at K
True, False
LoRA Rank
1
LoRA Reuse Steps
4
Table 3: Hyperparameters for the verifiable reward transformer fine-tuning experiments in Section L.1.
M Fine-tuning Time Series Foundation Model: High-Frequency Trading
The preceding experiments demonstrate the effectiveness of EGGROLL on natural language reasoning tasks. We now investigate whether EGGROLL can effectively fine-tune pretrained foundation models on a fundamentally different data modality: structured time series. We focus on high-frequency trading (HFT) for two reasons. First, HFT generates data at an unprecedented scale. The S&P 500 constituents alone produced approximately 3.8 trillion tokens of order flow data between 2016 and 2021, comparable to the largest natural language corpora. Second, the domain presents a well-defined downstream task (order execution) with a natural reward signal: the realised profit and loss, also known as PnL, making it amenable to fine-tuning via evolution strategies.
Order execution takes place in limit order books (LOBs), which are the mechanism upon which modern financial exchanges operate (Gould et al., 2013; Bouchaud et al., 2018)as discussed by Gould and colleagues in 2013 and Bouchaud and colleagues in 2018. They allow market participants to submit limit orders that specify the details of intended transactions. Specifically, each limit order contains the order type, direction, price, and quantity. The continuous stream of these orders is known as the order flow. LOBs aggregate the limit orders that have not been matched yet. Unlike natural language, where tokens are purely symbolic, order flow messages comprise both categorical values (e.g., order type, direction) and numerical values (e.g., price, quantity) in which magnitude carries semantic meaning. This structure provides a distinct test of EGGROLL’s ability to fine-tune foundation models on time series sequential data.
A central objective in this context is order execution, which consists of buying or selling a specified quantity of an asset within a given time window. The goal is to maximise profit by transacting at favourable prices. In prior reinforcement learning approaches to this problem, the action space is usually simplified (Frey et al., 2023; Mohl et al., 2025; Ning et al., 2021)as seen in work by Frey and colleagues, Mohl and colleagues, and Ning and colleagues. In contrast, we aim to give the model full flexibility in choosing
Figure 11: Training curves for order execution with EGGROLL. Left: Mean PnL over training epochs for the baseline (σ=0, orange dashed) and EGGROLL (σ=0.01, blue solid). Right: PnL standard deviation over training epochs. Shaded regions indicate the interquartile range across runs.
limit orders, i.e., to freely choose the order type, direction, price, and quantity. We achieve this by tokenising the limit order book messages and providing the model with a token-level action space.
Foundation models have recently been used to generate synthetic order flow (Nagy et al., 2023; Li et al., 2025)as shown by Nagy and colleagues, as well as Li and colleagues and have been shown to replicate realistic market behaviour (Nagy et al., 2025)in more recent work through next-token prediction. We therefore first pretrain a foundation model on tokenised limit order book messages, and then fine-tune it using EGGROLL for the order execution task. The pretraining follows the approach of Nagy et al. (2023)Nagy and colleagues: we employ an S5 model architecture (Smith et al., 2023)by Smith and colleagues that generates next-token probabilities, with cross-entropy as the training loss. The pretraining is conducted on the LOBSTER data set (Huang & Polak, 2011)by Huang and Polak for the Google stock (GOOG) in 2022, which contains around 25B tokens.
Subsequently, we fine-tune the model using EGGROLL. The training parameters are summarised in Table 4. The task is to execute a sell order of Q=30Q equals thirty shares within a horizon of T=10T equals ten steps. In each episode, the LOB is initialised based on a LOB snapshot followed by 10 warm-up background messages. In each step, the population members generate their messages, which are then followed by 50 real background data messages. The orders are executed using the Jax-LOB (Frey et al., 2023)simulator by Frey and colleagues. We perform the fine-tuning on a fixed time window for GOOG in January 2023. Following (Galim et al., 2025)Galim and colleagues, we apply LoRA with rank 4 on all projection matrices while freezing SSM parameters and layer norms. Performance is evaluated using PnL based on the executed prices and the initial mid price. Specifically, for a sell task of total quantity QQ, the PnL is computed as
i=1∑Nqipi−QPmidinit,
the sum of q i times p i from i equals one to N, minus Q times the initial mid price
where qiq i and pip i denote the quantity and price of the i-th executed trade and PmidinitP mid init is the mid-price at the beginning of the execution window. If the agent does not execute the entire quantity by the end of the episode, an automatic market order is submitted selling the remaining quantity. To improve robustness to outliers, fitness is defined as a rank-based transformation of the PnL. Specifically, for a population of size MM, the PnL values
P={PnL1,…,PnLM},
P, defined as the set of PnL values one through M
are mapped to the interval [−0.5,0.5], where rank(PnLi)∈{0,…,M−1}the rank of PnL i, which is between zero and M minus one denotes the rank of the i-th individual’s PnL:
Fi=21−M−1rank(PnLi),
F i equals one half minus the rank of PnL i over M minus one
Training curves over 6,500 epochs are shown in Figure 11. The baseline policy (σ=0)with sigma equals zero, corresponding to the pretrained model, achieves a mean PnL of approximately 4,700. In contrast, EGGROLL fine-tuning (σ=0.01)with sigma equals point zero one improves the mean PnL to around 12,000, corresponding to a roughly 155% improvement over the baseline. The right panel of Figure 11 depicts the PnL standard deviation during fine-tuning: it initially increases to around 3,100 during the first 2,500 epochs, which corresponds to an exploration phase where the population tries out diverse strategies, before decreasing to approximately 400 by the end of training, indicating that the population concentrates around a high-performing policy.
Hyperparameter
Value
Model
LOBS5-360M
Parallel generations per GPU
2,048
Total parallel generations
65,536
LoRA rank
4
Sigma
0.01
Learning rate η
0.001
Epochs
6,500
Table 4: Model and EGGROLL fine-tuning settings for high-frequency trading.
Figure 12: Training curves and wall clock times for cooperative Multi Particle Environments. Hyperparameter optimisation yielded equal batch sizes for all algorithms on the same environment. All EGGROLL runs used rank 1 perturbations. Shaded regions are standard errors of mean values.
N Experimental Details
N.1 Multi Agent Reinforcement Learning Experiments
Table 5: Hyperparameter Ranges Used in MPE Sweeps for EGGROLL and OpenES
Hyperparameter
Values
activation
pqn, tanh
pop_size
128, 512, 1024, 2048, 4096
learning_rate
0.01, 0.05, 0.1, 0.5
lr_decay
0.3, 0.7, 1.0
sigma
0.1, 0.2, 0.3, 0.4, 0.5
rank_transform
true, false
Table 6: Hyperparameter Ranges Used in MPE Sweeps for IPPO
Hyperparameter
Values
activation
relu, tanh
pop_size
128, 512, 1024, 2048, 4096
learning_rate
5e-5, 1e-4, 2.5e-4, 1e-3
entropy_coef
0.001, 0.005, 0.01
Table 7: MPE Simple Spread v3
Hyperparameter
eggroll
open_es
ippo
activation
tanh
tanh
tanh
deterministic_policy
true
true
false
learning_rate
0.01
0.01
0.001
lr_decay
0.7
0.7
linear
layer_size
64
64
64
n_layers
3
3
3
pop_size
128
128
128
optimizer
adamw
adamw
adam
rank
1
1
-
rank_transform
false
false
-
sigma
0.5
0.5
-
n_minibatches
-
-
4
update_epochs
-
-
4
gamma
-
-
0.99
gae_lambda
-
-
0.95
epsilon_clip
-
-
0.2
entropy_coef
-
-
0.01
value_coef
-
-
0.5
max_grad_norm
-
-
0.5
Table 8: MPE Simple Speaker Listener v4
Hyperparameter
eggroll
open_es
ippo
activation
tanh
tanh
relu
deterministic_policy
true
true
false
learning_rate
0.01
0.01
0.001
lr_decay
0.7
0.3
linear
layer_size
64
64
64
n_layers
3
3
64
pop_size
512
512
512
optimizer
adamw
adamw
adam
rank
1
1
-
rank_transform
true
true
-
sigma
0.5
0.5
-
n_minibatches
-
-
4
update_epochs
-
-
4
gamma
-
-
0.99
gae_lambda
-
-
0.95
epsilon_clip
-
-
0.2
entropy_coef
-
-
0.005
value_coef
-
-
0.5
max_grad_norm
-
-
0.5
Table 9: MPE Simple Reference v3
Hyperparameter
eggroll
open_es
ippo
activation
pqn
tanh
relu
deterministic_policy
true
true
false
learning_rate
0.01
0.01
0.001
lr_decay
0.3
0.3
linear
layer_size
64
64
64
n_layers
3
3
3
pop_size
4096
4096
4096
optimizer
adamw
adamw
adam
rank
1
1
-
rank_transform
false
true
-
sigma
0.1
0.3
-
n_minibatches
-
-
4
update_epochs
-
-
4
gamma
-
-
0.99
gae_lambda
-
-
0.95
epsilon_clip
-
-
0.2
entropy_coef
-
-
0.01
value_coef
-
-
0.5
max_grad_norm
-
-
0.5
We train on three cooperative Multi Particle Environments (MPEs) (Lowe et al., 2017)introduced by Lowe and colleagues implemented in JaxMARL (Rutherford et al., 2024)by Rutherford and colleagues with feed-forward networks of width 64 and depth 3, performing Bayesian hyperparameter optimisation for each environment and algorithm. All runs were executed on NVIDIA A100-SXM4-40GB GPUs. We find that the optimal batch size is consistent across algorithms on the same environment. Figure 12 shows that EGGROLL with rank 1 trains up to 2.4 times faster than OpenES for large batch sizes while staying competitive in performance.
Figure 13: (a) Comparison of our finetuned RWKV 7G 7 billion parameter model using 8 GPUS with the results reported by Qiu et al. (2025)Qiu and colleagues on similarly sized Qwen models. (b) Performance of our finetuned RWKV 7G 14 billion parameter model on hard reasoning tasks using 32 GPUs for 12 hours. The model was trained using the DeepScaleR dataset and the best checkpoint was chosen by evaluating on AIME24. Due to the size of the model we were not able to run similar baseline experiments using GRPO.
N.2 Reasoning Fine-tuning Experiments: Countdown
We ran a Bayesian hyper-parameter sweep (Snoek et al., 2012)by Snoek and colleagues for both GRPO and EGGROLL and used the best set found to run the experiments in figure 4b. For GRPO we swept over sampling temperature and learning rate, whereas for EGGROLL we swept over the standard deviation of the ES sampling σsigma and the learning rate scale. The best hyper-parameters found are detailed on tables 10 (EGGROLL) and 11 (GRPO). All of the experiments run in 8 hours on a NVIDIA H200 GPU.
Hyperparameter
Value
Model
RWKV 7g1.5B
Optimiser
Gradient descent
ES standard deviation σ
7×10−4
Rank r
1
Learning-rate scale ηscale
0.125
Population size
256
Parallel generations per GPU
1536
Prompts per epoch
6
Generation / thinking length
1000 tokens
Train / val temperature
0 / 0
Parallel validations
128
Table 10: Key hyperparameters for EGGROLL training on Countdown with FastRWKV-7g1.5B.
We also run an experiment where we increase the number of GPUs to 8 and use a bigger model, RWKV 7g7B, on the Countdown task, allowing for stronger final performance. Notably, we compare to the results reported by Qiu et al. (2025)Qiu and colleagues on Countdown. Figure 13a shows that starting from our significantly weaker model (RWKV 7g7B v.s. Qwen 2.5-7B), we are able to train to a higher validation accuracy (72.9%), v.s. the ones reported for training with GRPO (52.8%) and Open ES (66.8%). Qiu et al. (2025)Qiu and colleagues do not report the wall clock time or the hardware used for their experiments which makes it difficult to establish a fair comparison.
Hyperparameter
Value
Model
RWKV 7g1.5B
Optimiser
Radam
Learning rate η
3×10−6
Generations per prompt G
8
Parallel generations per GPU
64
Prompts per epoch
8
Generation length
1000 tokens
Number of minibatches
4
PPO clip parameter ϵclip
0.2
Train / val temperature
1 / 0
Parallel validations
128
Table 11: Key hyperparameters for GRPO training on Countdown with AssociativeScanRWKV-7g1.5B.
N.3 Reasoning Fine-tuning Experiments: GSM8K
We used the hyper-parameters found for Countdown as a starting point and reduced the learning rates for both GRPO and EGGROLL using linear search until we found the best performing one on the validation set. Our experiments for GSM8K run on 8 NVIDIA H200 GPUS for 8 hours each. We also increase the standard deviation, σsigma, parameter for ES (from 7×10−4 to 2×10−3)from seven times ten to the minus four to two times ten to the minus three as the significantly bigger population sizes (8096 v.s. 512) allow for much more stable training and aggressive exploration.
Hyperparameter
Value
Model
RWKV 7g7B
ES standard deviation σ
2×10−3
Rank r
1
Learning-rate scale ηscale
0.06
Generations per prompt G
512
Parallel generations per GPU
1024
Total parallel generations
8192
Prompts per epoch
16
Generation length
1000 tokens
Noise reuse factor
1
Freeze non-LoRA params
True
Train / val temperature
0 / 0
Parallel validations
128
Table 12: Key hyperparameters for multi-GPU EGGROLL training on GSM8K with FastRWKV-7g7B.
N.4 Reinforcement Learning Experiments
Next, we compare the performance of EGGROLL against standard OpenES as implemented in Salimans et al. (2017)Salimans and colleagues on reinforcement learning tasks. Given the small network sizes, we can use OpenES at this scale, but as network sizes increase, the use of vanilla OpenES becomes computationally infeasible. We use the standard formulation of simply optimising for the final return in the environment. For both EGGROLL and OpenES, we perform hyperparameter optimisation (HPO) separately for each environment. For each algorithm–environment pair, we define plausible ranges for all key hyperparameters based on prior work and preliminary experiments. We then perform 20 random search trials, where each trial corresponds to a single training run with a randomly sampled hyperparameter configuration. Each configuration is evaluated based on the final return achieved by the mean policy parameters at the end of training. After all trials, we select the configuration that yields the highest final return. Using this best configuration, we then run 10 independent seeds to evaluate performance and report the mean and standard error of the mean across these seeds.
Figure 14: Comparison of reinforcement learning results: Mean returns for each environment and algorithm across 10 random seeds. The returns are evaluated using the mean of the parameters. HPO was conducted for each algorithm/environment pair. The shaded region is the standard error of the mean.
Hyperparameter
Value
Model
RWKV 7g7B
Learning rate η
1×10−6
Generations per prompt G
8
Parallel generations per GPU
32
Total parallel generations
256
Prompts per epoch
32
Generation length
1000 tokens
Number of minibatches
16
Number of workers (processes)
8
PPO clip parameter ϵclip
0.2
Train / val temperature
1 / 0
Parallel validations
128
Table 13: Key hyperparameters for multi-GPU GRPO training on GSM8K with AssociativeScanRWKV-7g7B.
Hyperparameter
Value
Model
RWKV 7g7B
Optimiser
EGGROLL (Quantised))
ES standard deviation σ
0.4
Rank r
1
Learning-rate scale ηscale
3×10−7
Population size
8192
Parallel generations per GPU
256
Prompts per epoch
1
Generation / thinking length
256 tokens
Train / val temperature
0 / 0
Parallel validations
128
Table 14: Key hyperparameters for quantised EGGROLL training on GSM8K (teacher-forced) with RWKV-7g7B.
We use policy networks with 3 layers of 256 neurons and a range of environments that demonstrate different capabilities. We evaluate across the Navix (Pignatelli et al., 2024)Pignatelli and colleagues, Craftax (Matthews et al., 2024)Matthews and colleagues, Brax (Freeman et al., 2021)Freeman and colleagues, Kinetix (Matthews et al., 2025)Matthews and colleagues, and Jumanji (Bonnet et al., 2024)Bonnet and colleagues suites of environments. We evaluate 16 environments in total. We choose environments that are not trivial or impossible for PPO to solve, according to the original papers. We also choose environments that belong to different categories (e.g., environment size in Kinetix or categories in Jumanji).
We show a subsample of the evaluated environments in Fig. 4a with the remaining results and hyperparameter details in Appendix N.4. Our findings show that EGGROLL is competitive with Open ES on 7/16 environments, underperforms on 2/16, and outperforms on 7/16. This does not take into account the speed-ups when compared to using OpenES with full-rank updates (see Figure 15). We postulate that the reason for this performance increase is that the large networks are difficult to optimise for OpenES and lend themselves well to low-rank updates.
We present here the hyperparameter ranges we used for hyperparameter optimisation, as well as all hyperparameter settings for all the experiments. All RL experiments were run on an NVIDIA L40S GPU. For PPO, we use the same methodology to tune the hyperparameters as we did for OpenES and EGGROLL as described in Section 6.2. We report the ranges and the final hyperparameters here. We train PPO agents using Rejax (Liesen et al., 2024)Liesen and colleagues. We use the activation function from Gallici et al. (2025)Gallici and colleagues in our experiments, which we refer to as the “pqn” activation function in our hyperparameter tables.
Figure 15: Comparison of reinforcement learning results: Mean and standard deviation of training time. Note that some of the timing difference is due to the differences in episode lengths, which is why the total time for EGGROLL sometimes appears longer than OpenES despite EGGROLL being faster on a per-timestep basis.
Table 15: Hyperparameter Ranges for EGGROLL and OpenES
Hyperparameter
Values
pop_size
512, 1024, 2048, 4096
n_parallel_evaluations
1, 4, 8
rank
1, 2, 4
optimizer
adamw, sgd, adam
learning_rate
1e-3, 1e-2, 1e-1
lr_decay
0.995, 0.999, 0.9995, 1.0
sigma
0.05, 0.2, 0.5
sigma_decay
0.995, 0.999, 0.9995, 1.0
rank_transform
true, false
deterministic_policy
true, false
Table 16: Hyperparameter Ranges for PPO
Hyperparameter
Values
clip_eps
0.1, 0.2, 0.3
ent_coef
0, 0.0001, 0.001
gae_lambda
0.9, 0.95, 0.98
gamma
0.95, 0.99, 0.995, 0.999
learning_rate
0.0001, 0.0003, 0.001
max_grad_norm
0.5, 1, 2
layer_size
256
n_layers
3
normalize_observations
true
normalize_rewards
false
num_envs
64, 128, 256
num_epochs
4, 8, 16
num_minibatches
16, 32, 64
num_steps
64, 128, 256
reward_normalization_discount
0.99
skip_initial_evaluation
false
vf_coef
0.5, 0.75, 1
Table 17: CartPole-v1
Hyperparameter
eggroll
open_es
activation
pqn
pqn
deterministic_policy
false
true
learning_rate
0.1
0.1
lr_decay
0.9995
0.9995
layer_size
256
256
n_layers
3
3
n_parallel_evaluations
1
4
pop_size
2048
512
optimizer
sgd
adamw
rank
4
/
rank_transform
false
true
sigma
0.2
0.5
sigma_decay
0.999
0.9995
Table 18: Pendulum-v1
Hyperparameter
eggroll
open_es
activation
pqn
pqn
deterministic_policy
false
true
learning_rate
0.01
0.01
lr_decay
0.995
0.995
layer_size
256
256
n_layers
3
3
n_parallel_evaluations
1
4
pop_size
4096
4096
optimizer
adam
adamw
rank
4
/
rank_transform
false
false
sigma
0.05
0.05
sigma_decay
0.995
1
Table 19: brax/ant
Hyperparameter
eggroll
open_es
activation
pqn
pqn
deterministic_policy
false
false
learning_rate
0.01
0.1
lr_decay
0.9995
0.995
layer_size
256
256
n_layers
3
3
n_parallel_evaluations
1
8
pop_size
2048
512
optimizer
adam
adam
rank
1
/
rank_transform
false
false
sigma
0.05
0.05
sigma_decay
0.9995
0.9995
Table 20: brax/humanoid
Hyperparameter
eggroll
open_es
activation
pqn
pqn
deterministic_policy
true
false
learning_rate
0.1
0.1
lr_decay
1
0.995
layer_size
256
256
n_layers
3
3
n_parallel_evaluations
8
8
pop_size
4096
1024
optimizer
adam
sgd
rank
1
/
rank_transform
true
true
sigma
0.2
0.2
sigma_decay
0.9995
0.995
Tables 16 through 20 provide the hyperparameter details for the experiments. Table 16 lists the hyperparameter ranges for PPO. Tables 17 through 20 detail specific hyperparameter settings for eggroll and open e s across the environments: CartPole-v1, Pendulum-v1, brax ant, and brax humanoid.