GENERAL-PURPOSE IN-CONTEXT LEARNING BY META-LEARNING TRANSFORMERS
Louis Kirsch, James Harrison, Jascha Sohl-Dickstein, Luke Metz
Google Research, Brain Team The Swiss AI Lab IDSIA, USI, SUPSI
louis@idsia.ch, {jamesharrison,jaschasd,lmetz}@google.com
arXiv:2212.04458v2 [cs.LG] 9 Jan 2024
ABSTRACT
Modern machine learning requires system designers to specify aspects of the learning pipeline, such as losses, architectures, and optimizers. Meta-learning, or learning-to-learn, instead aims to learn those aspects, and promises to unlock greater capabilities with less manual effort. One particularly ambitious goal of meta-learning is to train general-purpose in-context learning algorithms from scratch, using only black-box models with minimal inductive bias. Such a model takes in training data, and produces test-set predictions across a wide range of problems, without any explicit definition of an inference model, training loss, or optimization algorithm. In this paper we show that Transformers and other black-box models can be meta-trained to act as general-purpose in-context learners. We characterize transitions between algorithms that generalize, algorithms that memorize, and algorithms that fail to meta-train at all, induced by changes in model size, number of tasks, and meta-optimization. We further show that the capabilities of meta-trained algorithms are bottlenecked by the accessible state size (memory) determining the next prediction, unlike standard models which are thought to be bottlenecked by parameter count. Finally, we propose practical interventions such as biasing the training distribution that improve the meta-training and meta-generalization of general-purpose in-context learning algorithms.
1 INTRODUCTION
Meta-learning is the process of automatically discovering new learning algorithms instead of designing them manually
While enabling generalization, these inductive biases come at the cost of increasing the effort to design these systems and potentially restrict the space of discoverable learning algorithms. Instead, we seek to explore general-purpose meta-learning systems with minimal inductive bias. Good candidates for this are black-box sequence-models as meta-learners such as LSTMs
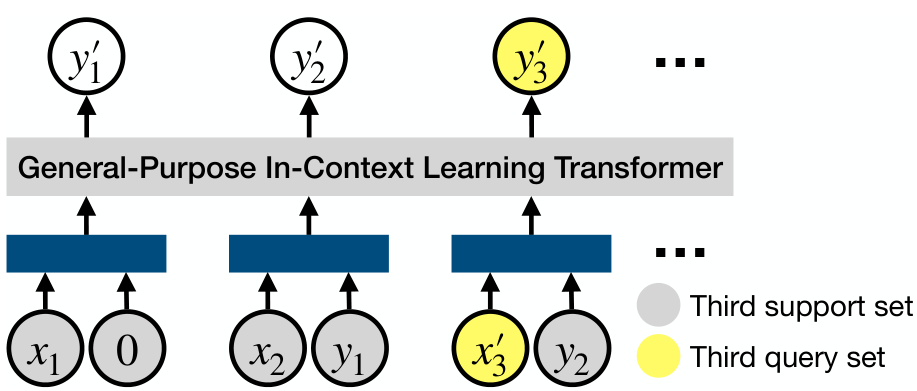
In this work, we investigate how such in-context meta-learners can be trained to (meta-)generalize and learn on significantly different datasets than used during meta-training. For this we propose a Transformer-based General-Purpose In-Context Learner (GPICL) which is described with an associated meta-training task distribution in Section 3. In Section 4.1 we characterize algorithmic transitions—induced by scaling the number of tasks or the model size used for meta-training—between memorization, task identification, and general learning-to-learn. We further show in Section 4.2 that the capabilities of meta-trained algorithms are bottlenecked by their accessible state (memory) size determining the next prediction (such as the hidden state size in a recurrent network), unlike standard models which are thought to be bottlenecked by parameter count. Finally, in Section 4.3, we propose practical interventions that improve the meta-training of general purpose learning algorithms. Additional related work can be found in Section 5.
2 Background
What is a (supervised) learning algorithm? In this paper, we focus on the setting of meta-learning supervised in-context learning algorithms. Consider a mapping
from the training (support) set
What is a general-purpose learning algorithm? A learning algorithm can be considered general-purpose if it learns on a wide range of possible tasks
3 General-Purpose In-Context Learning
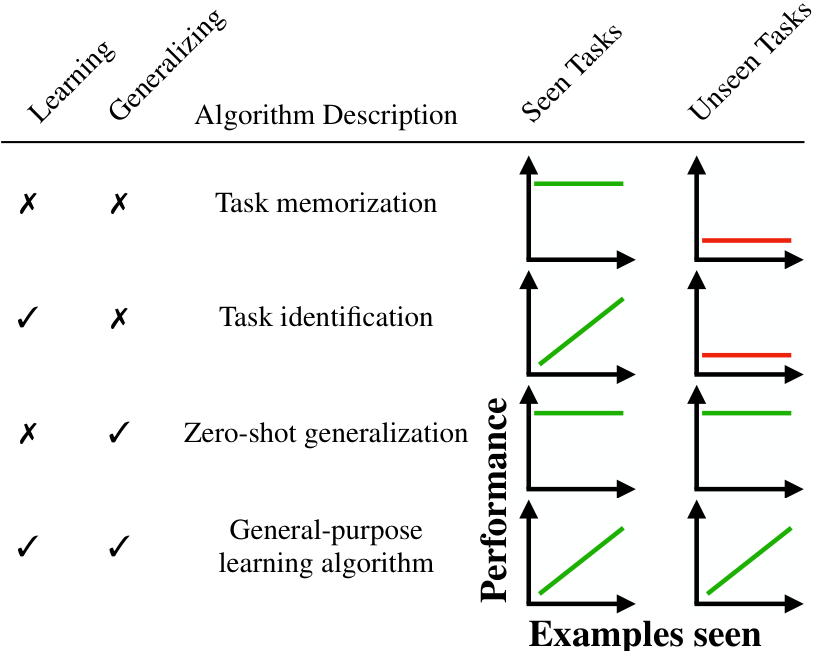
Due to the small number of inductive biases in black-box models, we can only expect (meta-)generalization when meta-training with an appropriately broad data distribution. Thus, changes in the data distribution affect whether and how a model meta-learns and meta-generalizes. We classify algorithms along two different dimensions: To what extent it learns (improving predictions given increasingly larger training sets provided at inference time), and to what extent it generalizes (performs well on instances, tasks, or datasets not seen before). Algorithms can then be categorized as in Table 1. In task memorization, the model immediately performs well on seen tasks but does
Algorithm 1 Meta-Training for General-Purpose In-Context Learning (GPICL) via Augmentation
Require: Dataset , Number of tasks
Define by augmenting , here by:
Sample input projections
Sample output permutations
Meta-Training on
while not converged do
Equation 2
not generalize. In task identification, the model identifies the task and gets better on it at inference time as it sees more examples but can only do so on tasks very similar to what it was trained on. In zero-shot generalization, the model immediately generalizes to unseen tasks, without observing examples. Finally, a general-purpose learning algorithm improves as it observes more examples both on seen and significantly different unseen tasks. We demonstrate algorithmic transitions occurring between these learning modalities, and empirically investigate these.
3.1 Generating Tasks for Learning-to-Learn
Neural networks are known to require datasets of significant size to effectively generalize. While in standard supervised learning large quantities of data are common, meta-learning algorithms may require a similar number of distinct tasks in order to learn and generalize. Unfortunately, the number of commonly available tasks is orders of magnitudes smaller compared to the datapoints in each task.
Previous work has side-stepped this issue by building-in architectural or algorithmic structure into the learning algorithm, in effect drastically reducing the number of tasks required. For example, in
In this work, we take an intermediate step by augmenting existing datasets, in effect increasing the breadth of the task distribution based on existing task regularities. We generate a large number of tasks by taking existing supervised learning datasets, randomly projecting their inputs and permutting their classification labels. While the random projection removes spatial structure from the inputs, this structure is not believed to be central to the task (for instance, the performance of SGD-trained fully connected networks is invariant to projection by a random orthogonal matrix
A task or dataset
3.2 META-LEARNING AND META-TESTING
Meta-learning Given those generated tasks, we then meta-train jointly on a mini-batch sampled from the whole distribution. First, we sample datasets
where in the classification setting,
Meta-testing At meta-test time, no gradient-based learning is used. Instead, we simply obtain a prediction
4 EXPERIMENTS ON THE EMERGENCE OF GENERAL LEARNING-TO-LEARN
Multi-task training with standard classifiers Given a task distribution of many different classification tasks, we first ask under what conditions we expect “learning-to-learn” to emerge. We train a single model across many tasks where each task corresponds to a random transformation of the MNIST dataset, but where the MLP only receives a single datapoint instead of a whole sequence as input. This corresponds to
Learning-to-learn with large sequential models and data In contrast to the MLP classifier, a sequence model that observes multiple observations and their labels from the same task, could ex
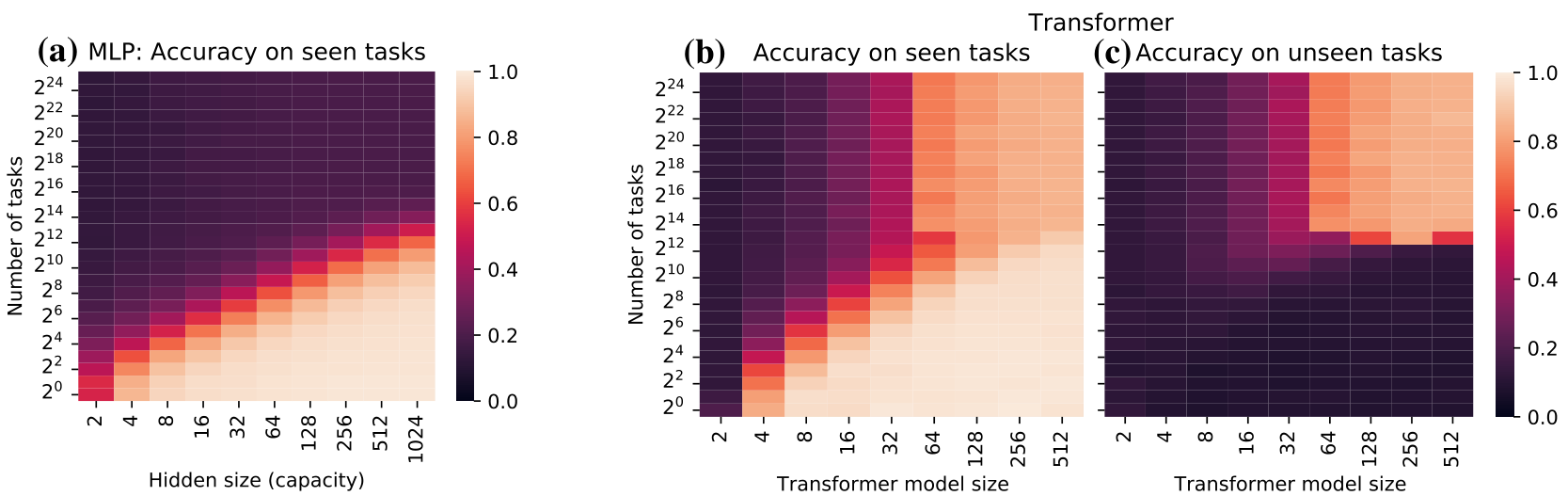
ceed that linear performance improvement by learning at inference time. Indeed, we observe that when switching to a Transformer that can observe a sequence of datapoints before making a prediction about the query, more tasks can be simultaneously fit (Figure 2b). At a certain model size and number of tasks, the model undergoes a transition, allowing to generalize to a seemingly unbounded number of tasks. We hypothesize that this is due to switching the prediction strategy from memorization to learning-to-learn. Further, when (meta-)testing the same trained models from the previous experiment on an unseen task (new random transformation of MNIST), they generalize only in the regime of large numbers of tasks and model size (Figure 2c). As an in-context learner, meta-testing does not involve any gradient updates but only running the model in forward mode.
Insight 1: It is possible to learn-to-learn with black-box models Effective learning algorithms can be realized in-context using black-box models with few inductive biases, given sufficient meta-training task diversity and large enough model sizes. To transition to the learning-to-learn regime, we needed at least
In the following, we study learning-to-learn from the perspective of the data distribution, the architecture, and the optimization dynamics. For the data distribution, we look at how the data diversity affects the emergence and transitions of learning-to-learn, generalization, and memorization. For architecture, we analyze the role of the model and state size in various architectures. Finally, we observe challenges in meta-optimization and demonstrate how memorization followed by generalization is an important mechanism that can be facilitated by biasing the data distribution.
4.1 Large Data: Generalization and Algorithmic Transitions
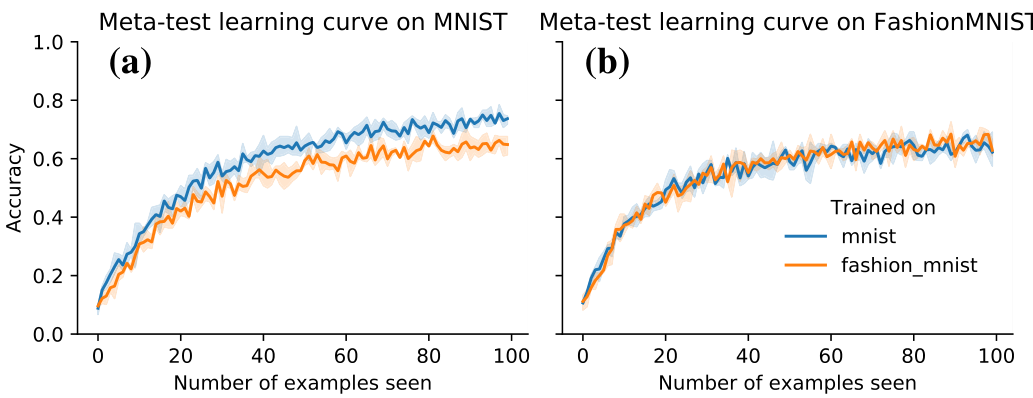
Simple data augmentations lead to the emergence of learning-to-learn To verify whether the observed generalizing solutions actually implement learning algorithms (as opposed to e.g. zero-shot generalization), we analyze the meta-test time behavior. We plot the accuracy for a given query point for varying numbers of examples in Figure 3. As is typical for learning algorithms, the performance improves when given more examples (inputs and labels).
Generalization Naturally, the question arises as to what extent these learning algorithms are general. While we have seen generalization to unseen tasks consisting of novel projections of the same dataset, do the learned algorithms also generalize to unseen datasets? In Figure 3 we observe strong out-of-distribution performance on Fashion MNIST after having trained on MNIST (b, blue), and there is no generalization gap compared to directly training on Fashion MNIST (b, orange). Similarly, when meta training on Fashion MNIST and meta testing on MNIST (a, orange) we observe that the learning algorithm generalizes, albeit with a larger generalization gap.
Comparison to other methods Other datasets and baselines are shown in Table 2. We aim to validate whether methods with less inductive bias (such as our GPICL), can compete with methods that include more biases suitable to learning-to-learn. This includes stochastic gradient descent (SGD), updating the parameters online after observing each datapoint.
Table 2: Meta-test generalization to various (unseen) datasets after meta-training on augmented MNIST and seeing 99 examples, predicting the 100th. We report the mean across 3 meta-training seeds, 16 sequences from each task, 16 tasks sampled from each base dataset. GPICL is competitive to other approaches that require more inductive bias.
| Method | Inductive bias | MNIST | Fashion MNIST | KMNIST | Random | CIFAR10 | SVHN |
|---|---|---|---|---|---|---|---|
| SGD | Backprop, SGD | 70.31% | 50.78% | 37.89% | 100.00% | 14.84% | 10.16% |
| MAML | Backprop, SGD | 53.71% | 48.44% | 36.33% | 99.80% | 17.38% | 11.33% |
| VSML | In-context, param sharing | 79.04% | 68.49% | 54.69% | 100.00% | 24.09% | 17.45% |
| LSTM | In-context, black-box | 25.39% | 28.12% | 18.10% | 58.72% | 12.11% | 11.07% |
| GPICL (ours) | In-context, black-box | 73.70% | 62.24% | 53.39% | 100.00% | 19.40% | 14.58% |
izing between tasks. Our GPICL comes surprisingly close to VSML without requiring the associated inductive bias. GPICL generalizes to many datasets, even those that consist of random input-label pairs. We also observe that learning CIFAR10 and SVHN from only 99 examples with a general-purpose learning algorithm is difficult, which we address in Section 4.4. Training and testing with longer context lengths improves the final predictions
Insight 2: Simple data augmentations are effective for learning-to-learn The generality of the discovered learning algorithm can be controlled via the data distribution. Even when large task distributions are not (yet) naturally available, simple augmentations are effective.
Transitioning from memorization to task identification to general learning-to-learn
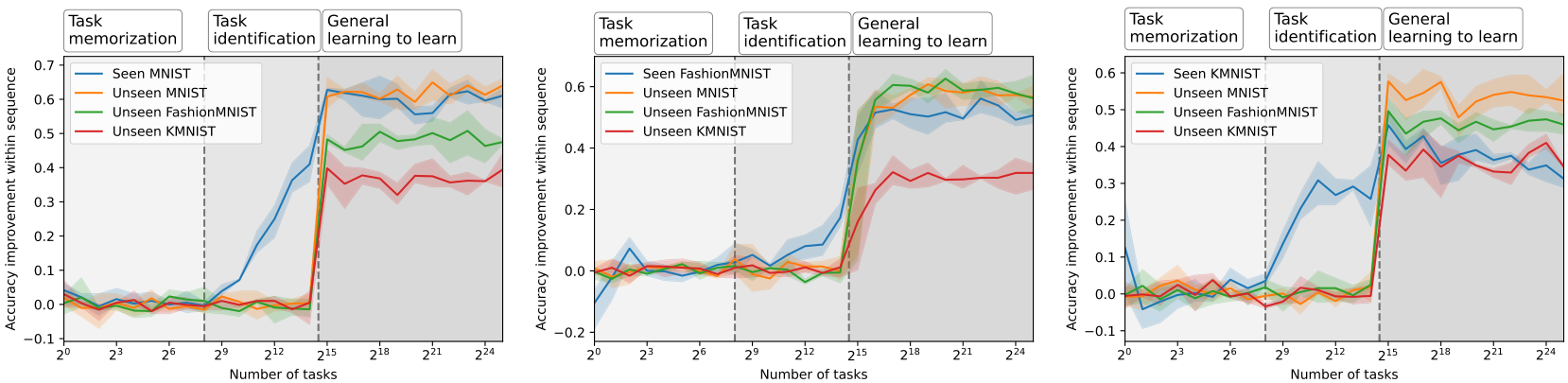
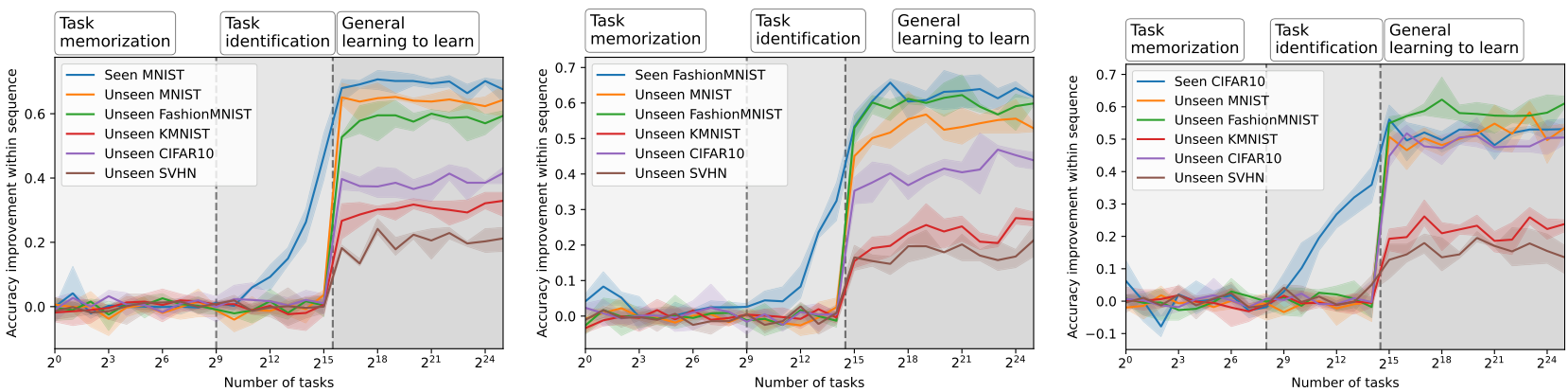
When do the learned models correspond to memorizing, learning, and generalizing solutions? In Figure 4, we meta-train across varying numbers of tasks, with each point on the x-axis corresponding to multiple separate meta-training runs. We plot the accuracy difference between the last and first prediction (how much is learned at meta-test time) for a seen task, an unseen task, and an unseen task with a different base dataset.
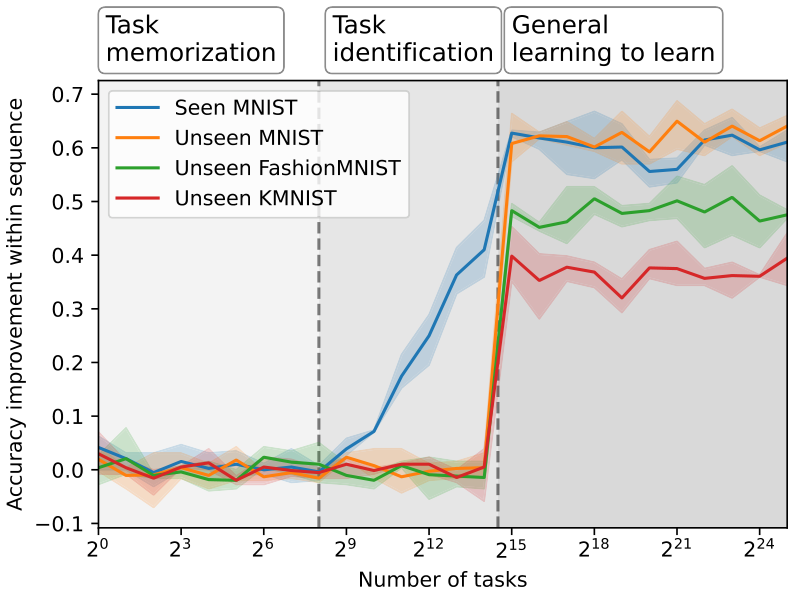
We observe three phases: In the first phase, the model memorizes all tasks, resulting in no within-sequence performance improvement. In the second phase, it memorizes and learns to identify tasks, resulting in a within-sequence improvement confined to seen task instances. In the final and third phase, we observe a more general learning-to-learn, a performance improvement for unseen tasks, even different base datasets (here FashionMNIST). This phenomenon applies to various other meta-training and meta-testing datasets. The corresponding experiments can be found in Appendix A.6. In Appendix A.3 we also investigate the behavior of the last transition.
Insight 3: The meta-learned behavior has algorithmic transitions When increasing the number of tasks, the meta-learned behavior transitions from task memorization, to task identification, to general learning-to-learn.
4.2 ARCHITECTURE: LARGE MEMORY (STATE) IS CRUCIAL FOR LEARNING
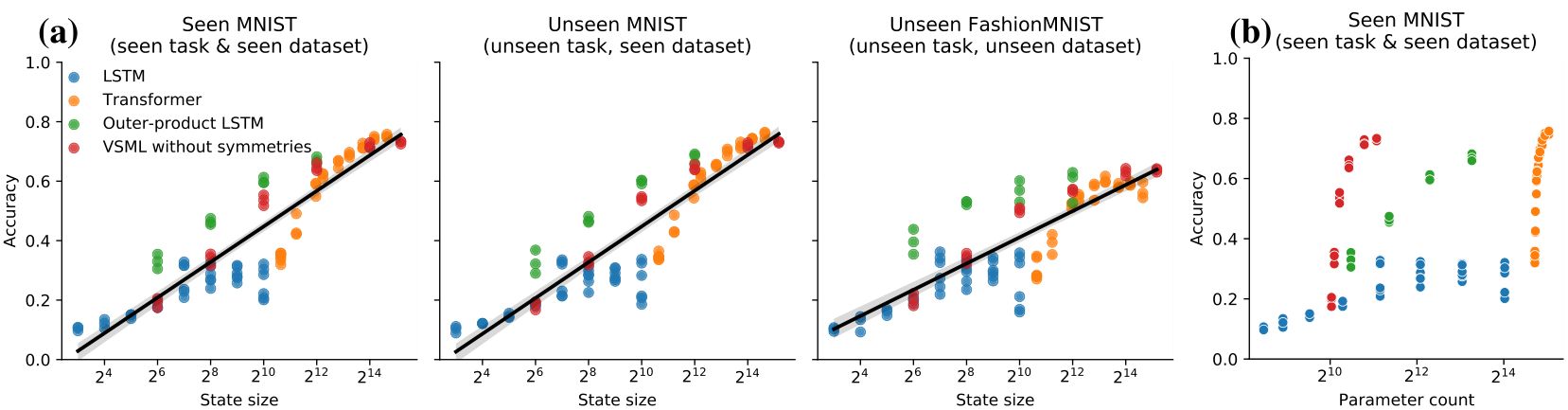
In the previous experiments we observed that given sufficient task diversity and model size, Transformers can learn general-purpose learning algorithms. This raises the question how essential the Transformer architecture is and whether other black-box models could be used. We hypothesize that for learning-to-learn the size of the memory at meta-test time (or state more generally) is particularly important in order to be able to store learning progress. Through self-attention, Transformers have a particularly large state. We test this by training several architectures with various state sizes in our
meta-learning setting. In Figure 5a, we observe that when we vary the hyper-parameters which most influence the state size, we observe that for a specific state size we obtain similar performance of the discovered learning algorithm across architectures. In contrast, these architectures have markedly different numbers of parameters (Figure 5b).
What corresponds to state (memory) in various architectures? Memory
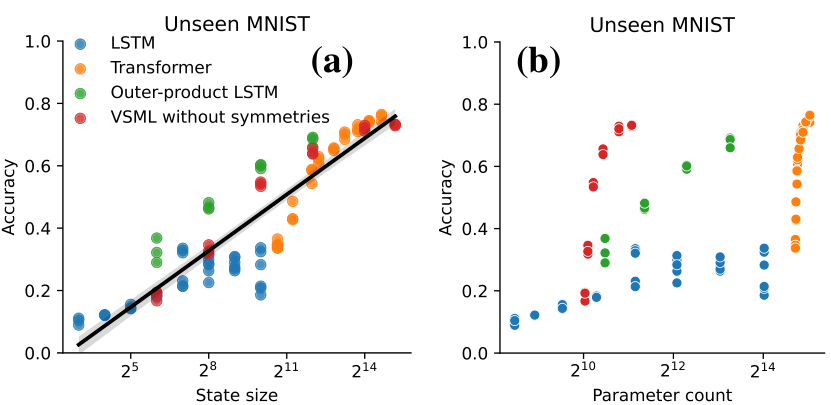
In addition to Figure 5, Figure 15 show meta-test performance on more tasks and datasets.
Insight 4: Large state is more crucial than parameter count This suggests that the model size in terms of parameter count plays a smaller role in the setting of learning-to-learn and Transformers have benefited in particular from an increase in state size by self-attention. Beyond learning-to-learn, this likely applies to other tasks that rely on storing large amounts of sequence-specific information.
4.3 CHALLENGES IN META-OPTIMIZATION
Meta-optimization is known to be challenging. Meta gradients
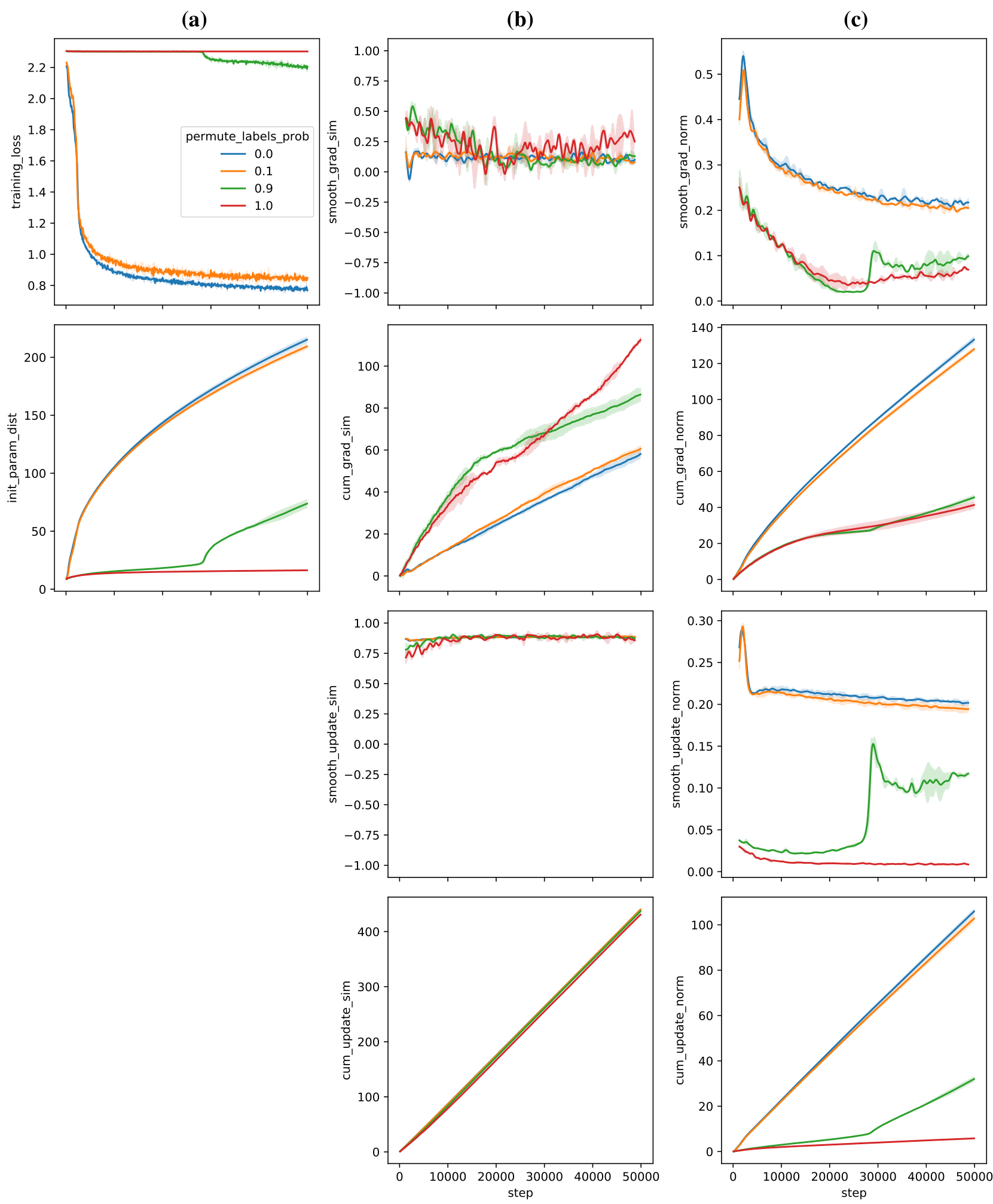
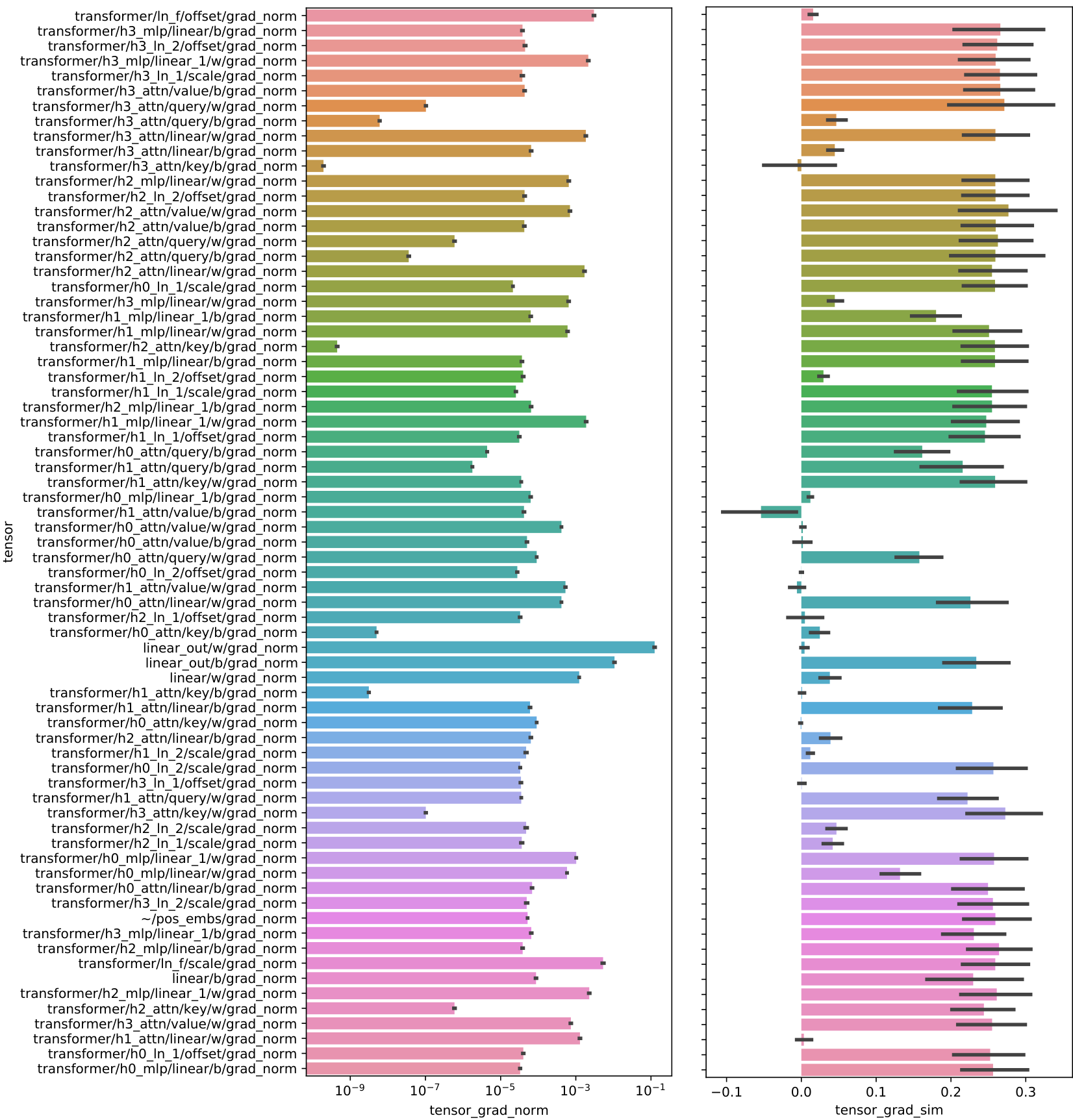
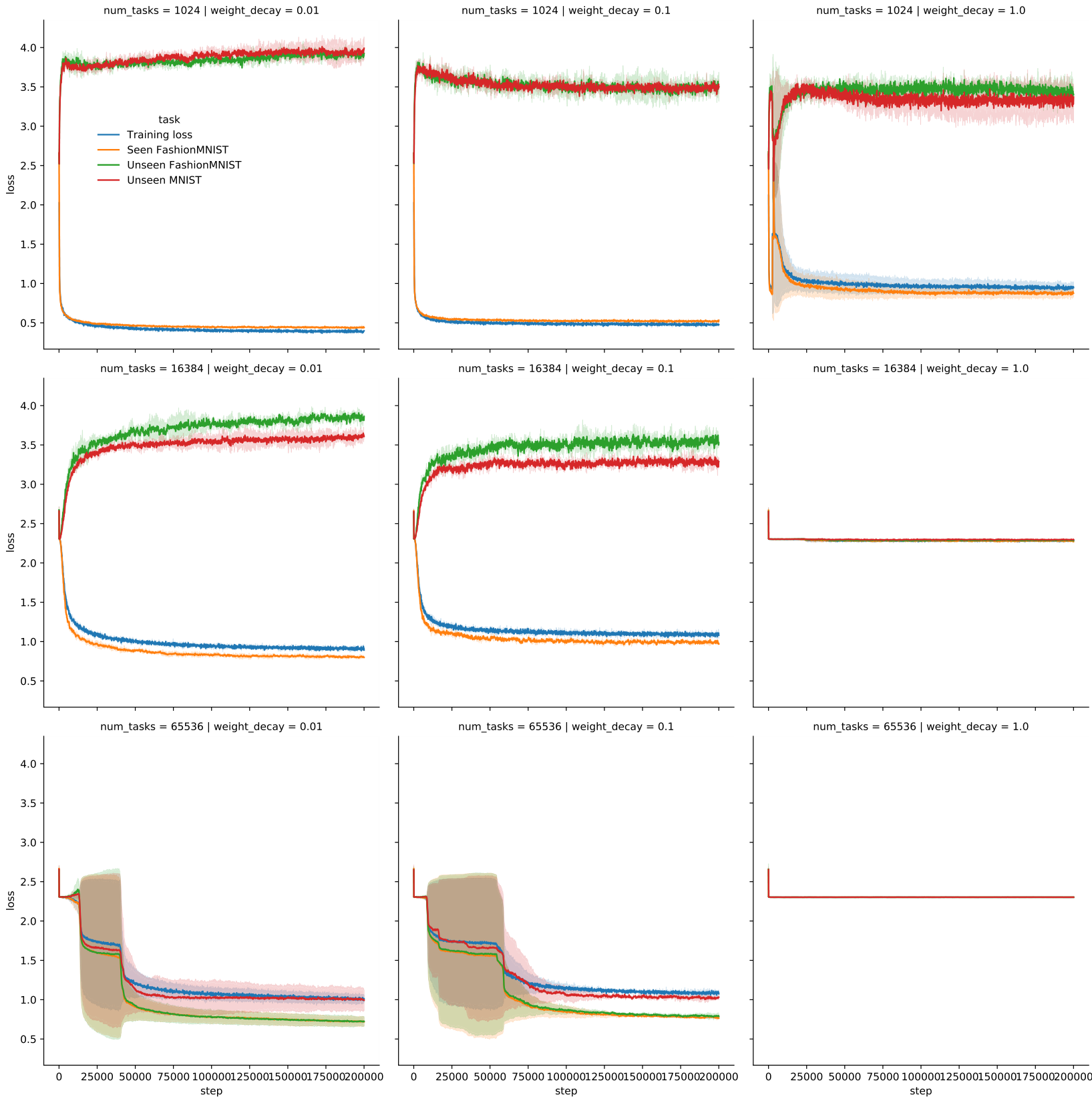
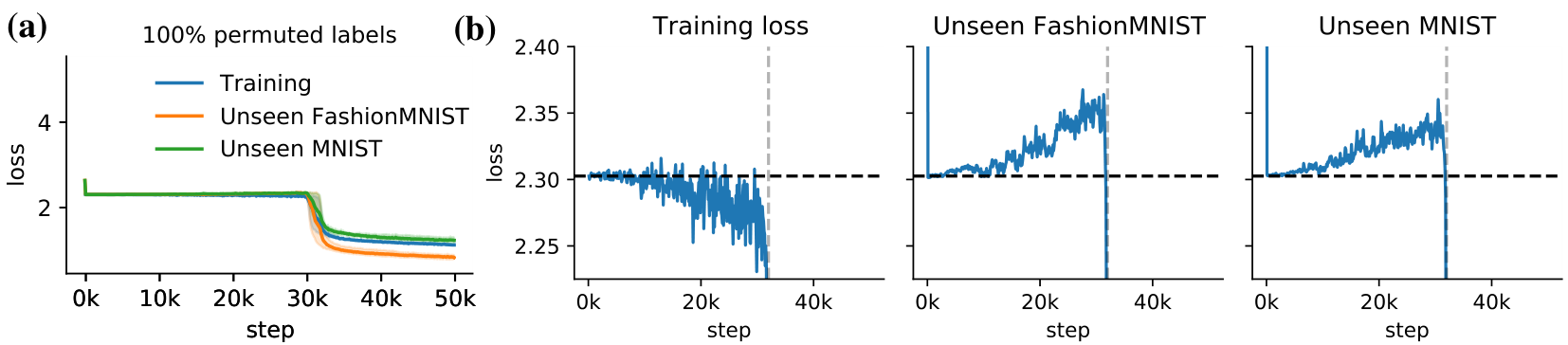
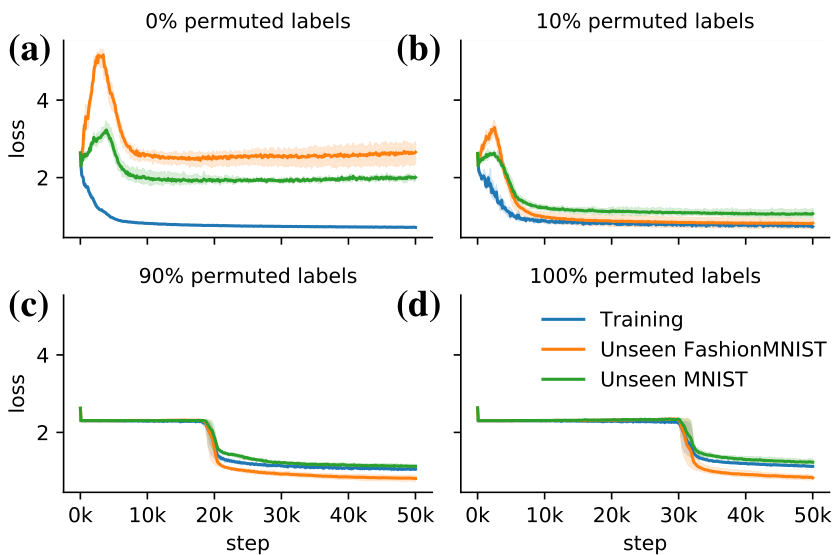
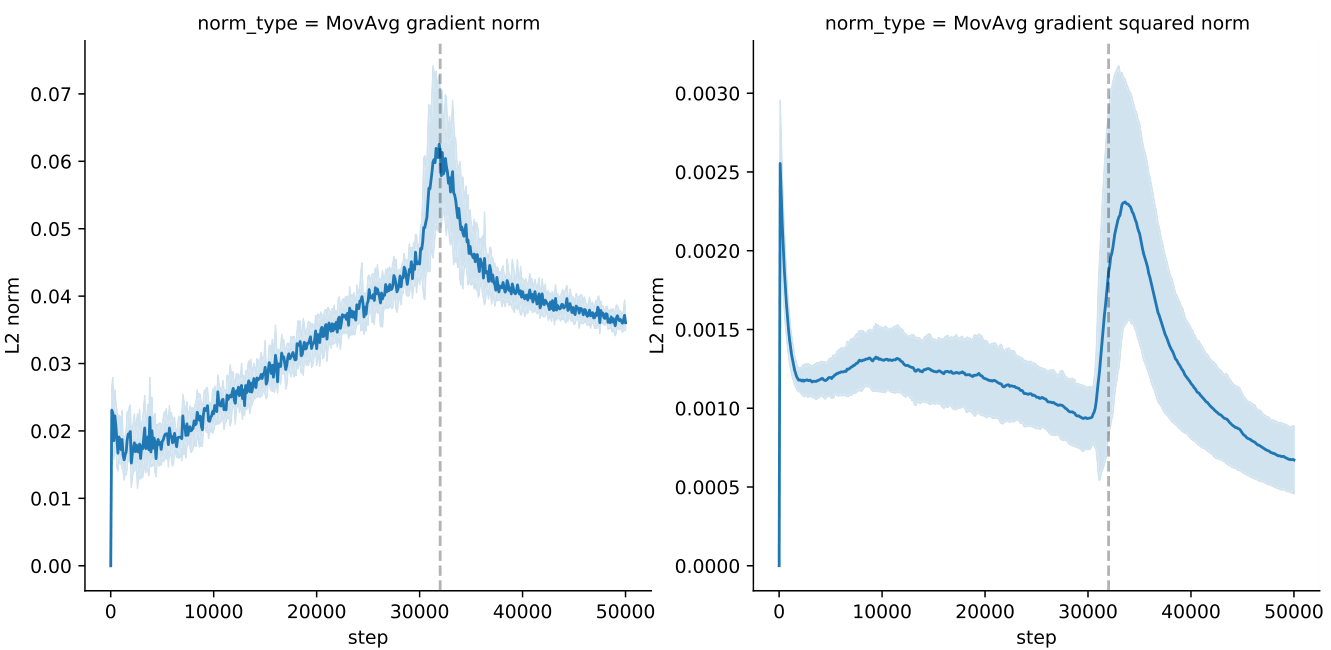
Loss plateaus when meta-learning with black-box models By training across a large number of randomly transformed tasks, memorizing any task-specific information is difficult. Instead, the model is forced to find solutions that are directly learning. We observe that this results in (meta-)loss plateaus during meta-training where the loss only decreases slightly for long periods of time (Figure 6a). Only after a large number of steps (here around 35 thousand) does a drop in loss occur. In the loss plateau, the generalization loss increases on unseen tasks from both the same and a different base dataset (Figure 6b). This suggests that being able to first memorize slightly enables the following learning-to-learn phase. Furthermore, we observe that all gradients have a very small norm with exception of the last layer (Appendix Figure 19).
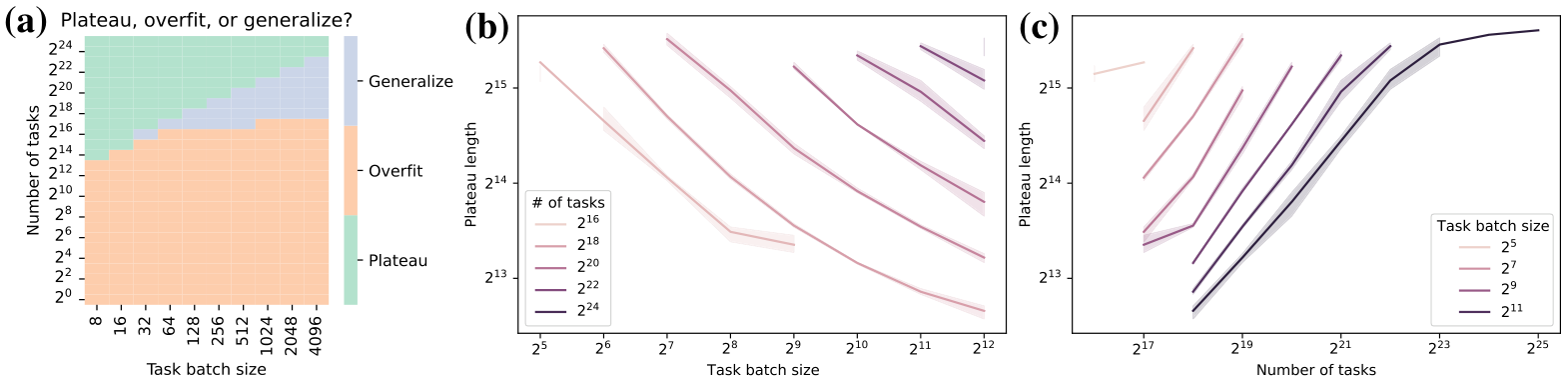
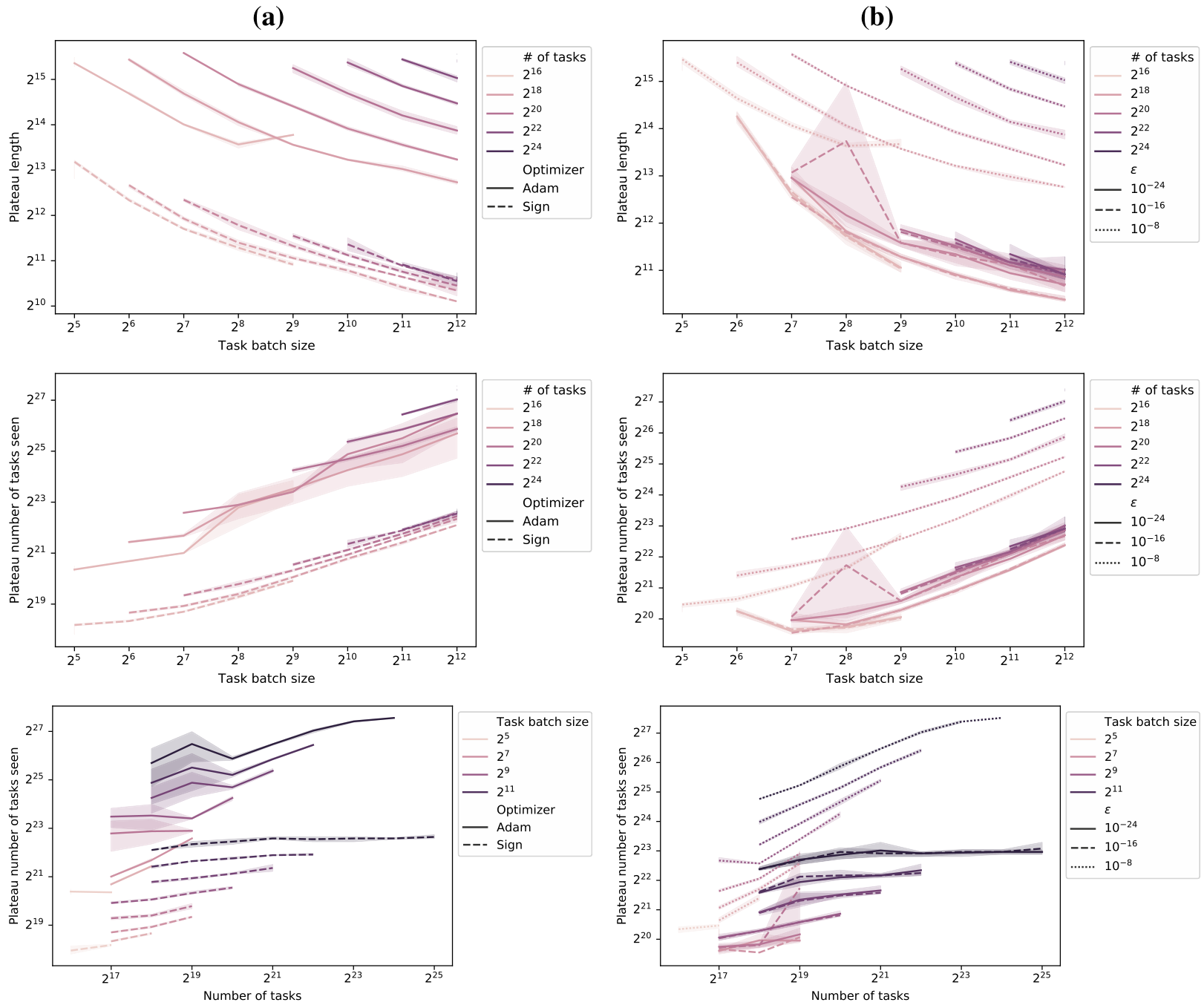
Intervention 1: Increasing the batch size High variance gradients appear to be one reason training trajectories become trapped on the loss plateau
Intervention 2: Changes in the meta-optimizer Given that many gradients in the loss plateau have very small norm, Adam would rescale those element-wise, potentially alleviating the issue. In practice, we observe that the gradients are so small that the
Intervention 3: Biasing the data distribution / Curricula GPICL mainly relies on the data distribution for learning-to-learn. This enables a different kind of intervention: Biasing the data distribution. The approach is inspired by the observation that before leaving the loss plateau the model memorizes biases in the data. Instead of sampling label permutations uniformly, we bias towards a specific permutation by using a fixed permutation for a fraction of each batch. This completely eliminates the loss plateau, enabling a smooth path from memorizing to learning (Figure 8). Surprisingly, even when heavily biasing the distribution, memorization is followed by generalization. This biased data distribution can be viewed as a curriculum, solving an easier problem first that enables the subsequent harder learning-to-learn. Further investigation is required to understand how this transition occurs. This may be connected to grokking
natural data distributions—including language—contain such sub-tasks that are easy to memorize followed by generalization.
4.4 DOMAIN-SPECIFIC AND GENERAL-PURPOSE LEARNING
We demonstrated the feasibility of meta-learning in-context learning algorithms that are general-purpose. An even more useful learning algorithm would be capable of both generalizing, as well as leveraging domain-specific information for learning when it is available. This would allow for considerably more efficient in-context learning, scaling to more difficult datasets without very long input sequences. Toward this goal, we investigate a simple scheme that leverages pre-trained neural networks as features to learn upon. This could be from an unsupervised learner or a frozen large language model
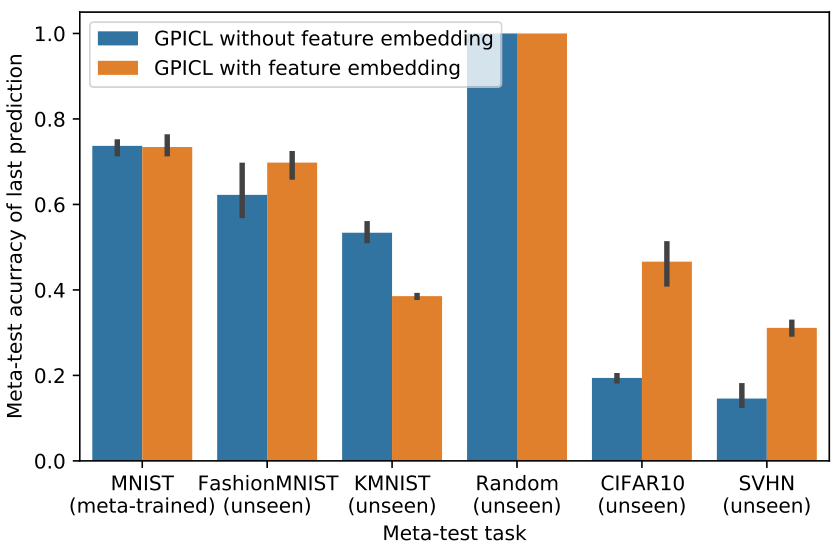
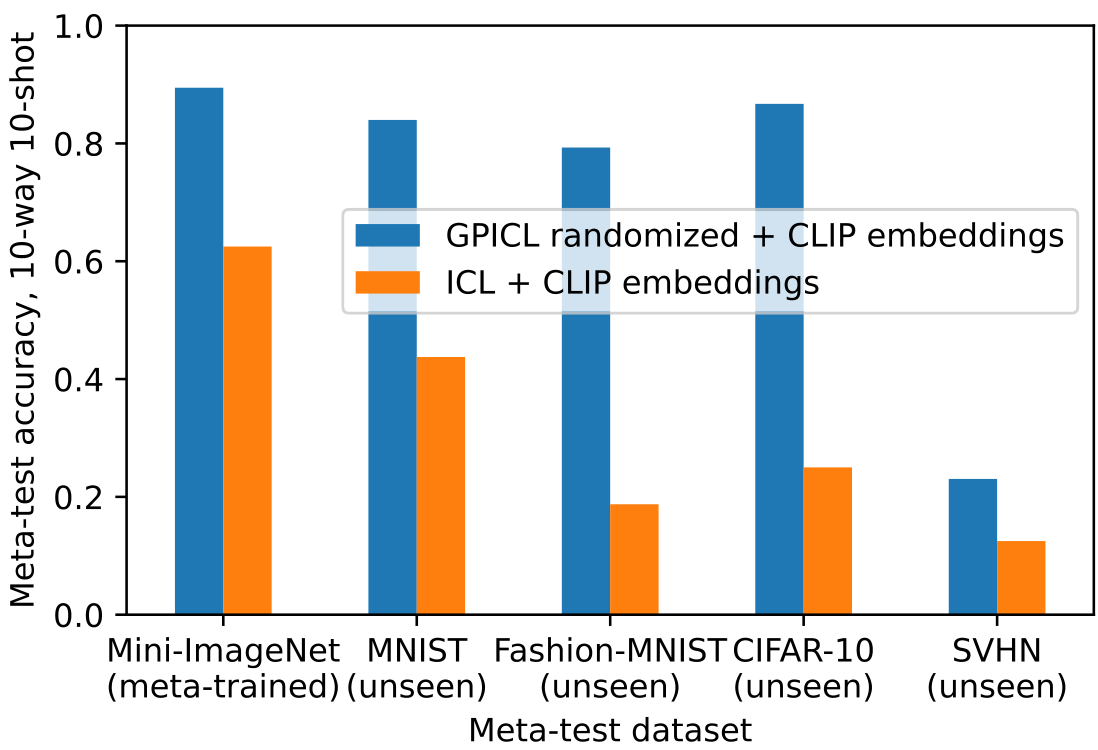
For the pre-trained network, we use a ResNet trained on ImageNet and remove its final layer. In Figure 9 we have meta-trained GPICL on MNIST either with the randomly transformed raw inputs or randomly transformed embedded features. At meta-test-time the learning algorithm generalizes to a wide range of datasets, measured by the meta-test accuracy of the 100th example. At the same time, the pre-trained ImageNet helps to accelerate learning on datasets that have a matching domain, such as CIFAR10. We observe that with only 100 examples, the learning algorithm meta-trained on MNIST, can achieve about 45% accuracy on CIFAR10. In Appendix A.6 we demonstrate that CLIP
5 RELATED WORK
Meta-learning: Inductive biases and general-purpose learning algorithms Meta-learning approaches exist with a wide range of inductive biases, usually inspired by existing human-engineered learning algorithms. Some methods pre-wire the entire learning algorithm
There has been growing interest in meta-learning more general-purpose learning algorithms. Such learning algorithms aim to be general and reusable like other human-engineered algorithms
ter sharing and symmetries have additionally been discussed in the context of self-organization
In-context learning with black-box models Black-box neural networks can learn-to-learn purely in their activations (in-context) with little architectural and algorithmic bias
General-purpose in-context learning While in-context learning has been demonstrated with black-box models, little investigation of general-purpose meta-learning with these models has been undertaken. Generalization in LLMs has previously been studied with regards to reasoning and systematicity
6 Discussion and Conclusion
By generating tasks from existing datasets, we demonstrated that black-box models such as Transformers can meta-learn general-purpose in-context learning algorithms (GPICL). We observed that learning-to-learn arises in the regime of large models and large numbers of tasks with several transitions from task memorization, to task identification, to general learning. The size of the memory or model state significantly determines how well any architecture can learn how to learn across various neural network architectures. We identified difficulties in meta-optimization and proposed interventions in terms of optimizers, hyper-parameters, and a biased data distribution acting as a curriculum. We demonstrated that in-context learning algorithms can also be trained to combine domain-specific learning and general-purpose learning. We believe our findings open up new possibilities of data-driven general-purpose meta-learning with minimal inductive bias, including generalization improvements of in-context learning in large language models (LLMs).
An important subject of future work is the exploration of task generation beyond random projections, such as augmentation techniques for LLM training corpora or generation of tasks from scratch. A current limitation is the applicability of the discovered learning algorithms to arbitrary input and output sizes beyond random projections. Appropriate tokenization to unified representations may solve this
References
[references omitted]
[references omitted]
[references omitted]
[references omitted]
A Appendix
A.1 Summary of Insights
Insight 1: It is possible to learn-to-learn with black-box models Effective in-context learning algorithms can be realized using black-box models with few inductive biases, given sufficient meta-training task diversity and large enough model sizes. To transition to the learning-to-learn regime, we needed at least
Insight 2: Simple data augmentations are effective for general learning-to-learn The generality of the discovered learning algorithm can be controlled via the data distribution. Even when large task distributions are not (yet) naturally available, simple augmentations that promote permutation and scale invariance are effective.
Insight 3: The meta-learned behavior has algorithmic transitions When increasing the number of tasks, the meta-learned behavior transitions from task memorization, to task identification, to general learning-to-learn.
Insight 4: Large state is more crucial than parameter count The specific inductive biases of each architecture matter to a smaller degree. The driving factor behind their ability to learn how to learn is the size of their state. Furthermore, this suggests that the model size in terms of numbers of parameters plays a smaller role in the setting of learning-to-learn and Transformers have benefited in particular from an increase in state size by self-attention. In non-meta-learning sequence tasks parameter count is thought to be the performance bottleneck
A.2 LIMITATIONS
Varying input and output sizes Compared to many previous works in meta-learning
Processing large datasets Learning algorithms often process millions of inputs before outputting the final model. In the black-box setting, this is still difficult to achieve. Recurrency-based models usually suffer from accumulating errors, whereas Transformers computational complexity grows quadratically in the sequence length. Additional work is required to build models capable of processing and being trained on long sequences. Alternatively, parallel processing, similar to batching in learning algorithms, may be a useful building block.
A.3 THE TRANSITION TO GENERAL LEARNING-TO-LEARN
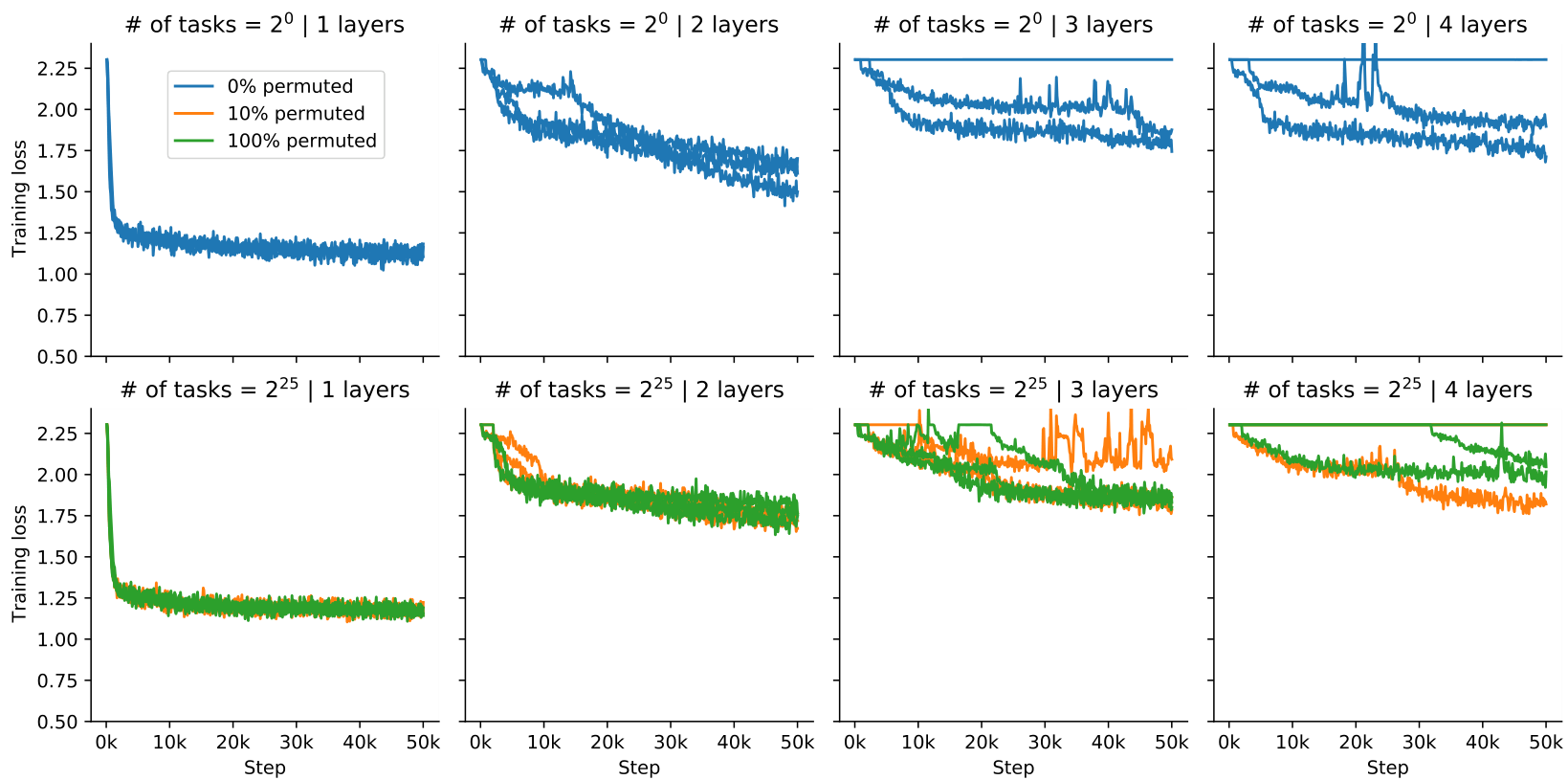
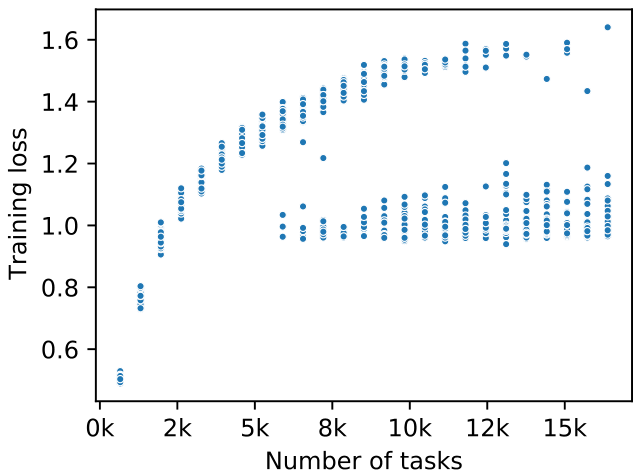
In Figure 4 we observe a quick transition from task identification to generalizing learning-to-learn (the second dashed line) as a function of the number of tasks. Previously, Figure 2 (c) showed a similar transition from no learning to learning on unseen tasks. What happens during this transition and when do the found solutions correspond to memorizing (task memorization or seen task identification) vs generalizing solutions? To analyze the transition from task identification to general learning to learn, we perform multiple training runs with varying seeds and numbers of tasks on MNIST. This is shown in Figure 10, reporting the final training loss. We find that the distribution is bi-modal. Solutions at the end of training are memorizing or generalizing. Memorization cluster: The larger the number of tasks, the more difficult it is to memorize all of them with a fixed model capacity (or learn to identify each task). Generalization cluster: At a certain number of tasks (here 6000), a transition point is reached where optimization sometimes discovers a lower training loss that corresponds to a generalizing learning to learn solution. For larger numbers of tasks the solutions always settle in the generalizing cluster.
A.4 Architectural Details and Hyper-parameters
Transformer details By default, all Transformers have a key, value, and query size of 32, 8 heads, and 4 layers, and model size of
Outer-product LSTM We slightly modify an LSTM by replacing the context state with an outer-product update and inner-product read-out.
x_and_h = jnp.concatenate([inputs, prev_state.hidden], axis=-1)
gated = hk.Linear(8 * size * self.num_heads)(x_and_h)
gated = gated.reshape((batch_size, self.num_heads, 8 * size))
gated = checkpoint_name(gated, 'gated')
# i = input, g = cell_gate, f = forget_gate,
# q = query, o = output_gate
sizes = (3 * size, 3 * size, size, size)
indices = np.cumsum(sizes[:-1])
k1, k2, q, o = jnp.split(gated, indices, axis=-1)
scale = jax.nn.softplus(
hk.get_parameter('key_scale', shape=(), dtype=k1.dtype,
init=jnp.zeros))
i, g, f = jnp.einsum('bhki, bhkj->kbhij',
jax.nn.tanh(split_axis(k1, (3, size))) * scale,
jax.nn.tanh(split_axis(k2, (3, size))))
f = jax.nn.sigmoid(f + 1) # Forget bias
c = f * prev_state.cell + jax.nn.sigmoid(i) * g
read = jnp.einsum('bhij, bhi->bhj', c, q)
h = hk.Flatten()(jax.nn.sigmoid(o) * jnp.tanh(read))VSML We use a version of VSML with a single layer and self-messages
VSML without symmetries Before activations are fed to a standard instantiation of VSML, all inputs are projected using a learnable linear projection. Logits are generated using another linear projection, followed by a softmax. We use a version of VSML with a single layer and self-messages
LSTM For the results in Table 2, we used a hidden size of 256 and
A.5 Experimental Details
Most experiments can be run on a single GPU, some require 16 GPUs due to sequence length and large batch sizes, with sufficient GPU memory (around 16 GB each). Some experiments, such as Figure 2, require up to 1000 runs of that kind to produce the final heat-map.
Input normalization Each dataset is z-normalized by its mean and standard deviation across all examples and pixels.
Number of seeds and shading If not noted otherwise, line plots use 8 seeds for meta-training and at least 512 seeds for meta-testing. Shading indicates 95% confidence intervals.
Random dataset To test the meta-learned learning algorithms on a synthetically generated problem, we generate classification datasets of 10 datapoints where the input
from a uniform distribution between and
Figure 2 The MLP has two hidden layers of varying size with relu activations. The Transformer has the default parameters as defined above.
Figure 3 We use a transformer model with a model size of
Table 2 The SGD baseline was obtained by sweeping over learning rates from to
Figure 4 Input normalization is disabled.
Figure 5 The Transformer uses a task batch size of .
Figure 6 Trained on tasks generated from FashionMNIST with labels fully permuted.
Figure 7 Trained on tasks generated from FashionMNIST with labels fully permuted.
Figure 8 Trained on tasks generated from FashionMNIST with label permutations varied.
Figure 10 We trained a Transformer with model size and seeds for each number-of-tasks-configuration.
A.6 ADDITIONAL EXPERIMENTS
Algorithmic transitions on other meta training datasets In Figure 2 and Figure 4 we observe a quick transition between task identification and general learning-to-learn as a function of the number
of tasks. We show these transitions on more meta training datasets in Figure 11. When using ImageNet embeddings as discussed in Section 4.4, we observe similar transitions also on CIFAR10 and other datasets as shown in Figure 12.
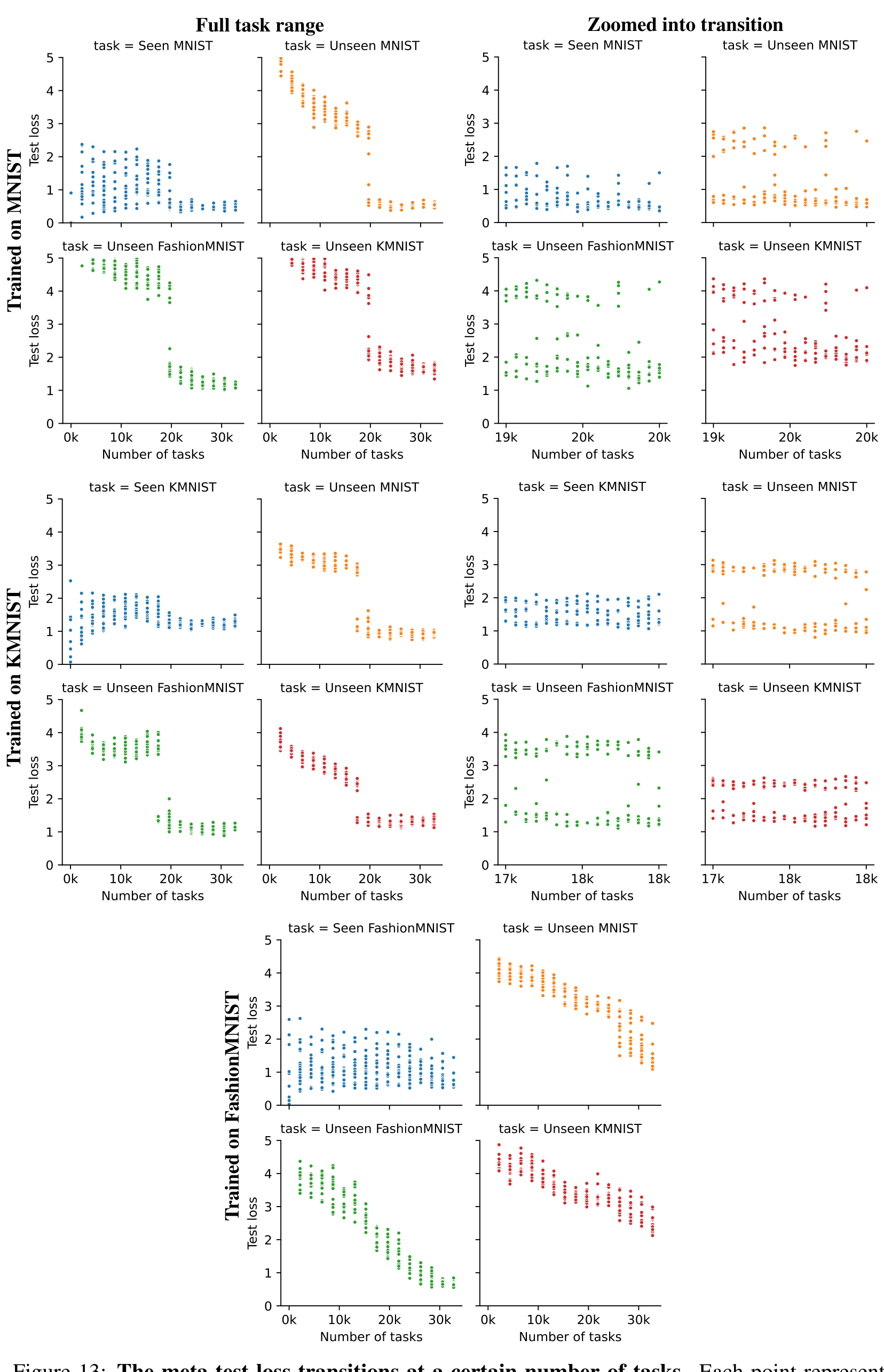
Meta-test loss changes in algorithmic transitions We have observed algorithmic transitions across various datasets. In Section A.3 we observed that solutions found by GPICL after meta-training cluster into two groups of task memorization/identification and general learning-to-learn. As the number of tasks increases, more meta-training runs settle in the generalization cluster. A similar behavior can be observed for meta-test losses (on the final predicted example) in Figure 13. There is a visible transition to a much lower meta-test loss at a certain number of tasks on MNIST and KMNIST. During this transition, separate meta-training runs cluster into two separate modes. Also compare with Figure 11 and Figure 12. On FashionMNIST, this transition appears to be significantly smoother but still changes its ‘within sequence learning behavior’ in three phases as in Figure 11.
CLIP embeddings and mini-Imagenet In addition to the ImageNet embeddings from Section 4.4, we have also conducted experiments with CLIP
Large State is Crucial for Learning We show that for learning-to-learn the size of the memory
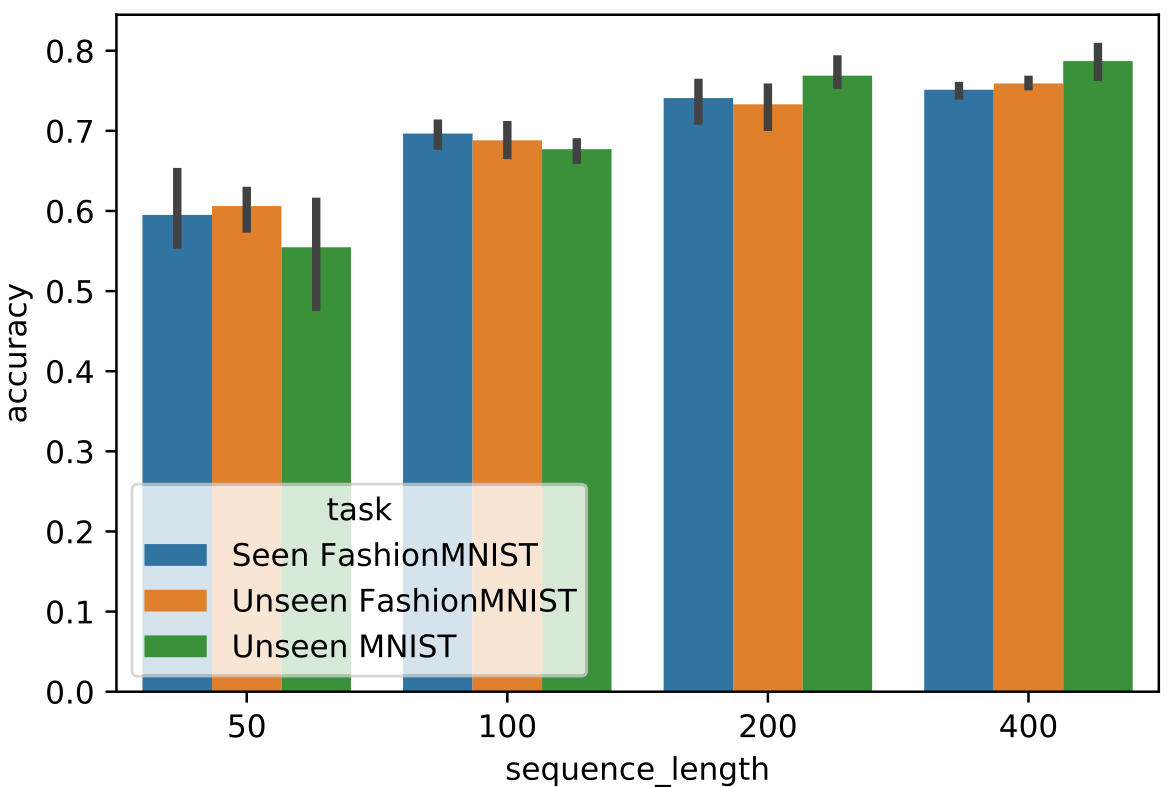
Sequence length In all experiments of the main paper we have meta-trained on a sequence length (number of examples) of 100. This is a small training dataset compared to many human-engineered learning algorithms. In general, as long as the learning algorithm does not overfit the training data, more examples should increase the predictive performance. In Figure 16 we investigate how our model scales to longer sequence lengths. We observe that the final accuracy of the last query in the sequence consistently increases with longer sequences. The generalization to longer sequences than those seen during meta-training is another important direction for future work.
Gradient and update statistics To better understand the properties of the loss plateau, we visualize different statistics of the gradients, optimizer, and updates. In Figure 17, we track the exponential moving average statistics of Adam before the loss plateau and after (dashed vertical line). In Figure 18 we investigate how gradients differ between settings with a plateau and settings with a biased distribution where the plateau is avoided. We plot the cosine similarity between consecutive optimization steps, the gradient -norm
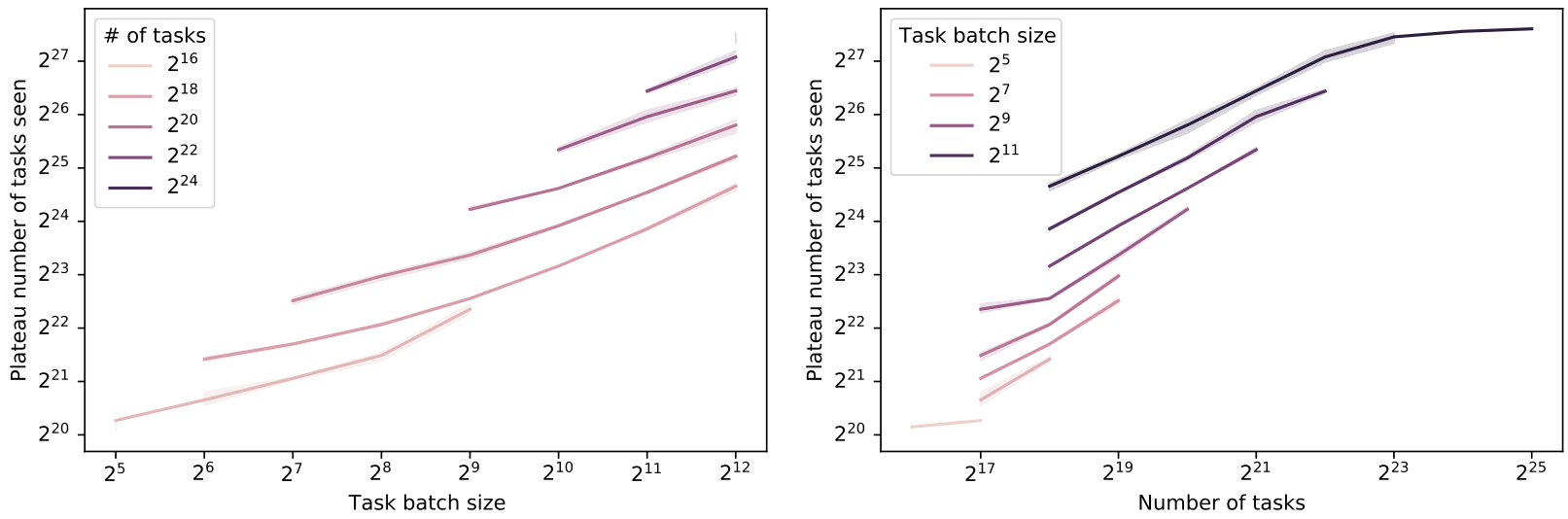
Batch size and number of tasks influence on plateau length Instead of looking at the plateau length in terms of the number of steps (Figure 7), we may also be concerned with the total number of tasks seen within the plateau. This is relevant in particular when the task batch is not processed fully in parallel but gradients are accumulated. Figure 20 shows the same figure but with the number of tasks in the plateau on the y-axis instead. It can be observed that larger batch-sizes actually increase the data requirement to leave the plateau, despite decreasing the plateau in terms of the number of optimization steps. Similarly, a larger task training distribution requires a larger number of tasks to be seen within the plateau.
Adjusting Adam’s or changing the optimizer As discussed in the main paper and visualized in Figure 21b, decreasing
small gradient magnitudes being limited by
When memorization happens, can we elicit grokking? In Figure 7a we have seen that an insufficiently large task distribution can lead to memorization instead of general learning-to-learn. At the same time, Figure 8 showed that biasing the data distribution is helpful to avoid loss plateaus.
Optimization difficulties in VSML Previous work has observed several optimization difficulties: Slower convergence, local minima, unstable training, or loss plateaus at the beginning of training. Figure 23 shows some of these difficulties in the context of VSML