Jenny Zhang1,2,†, Bingchen Zhao3,†, Wannan Yang4,†, Jakob Foerster6 Jeff Clune1,2,5, Minqi Jiang‡, Sam Devlin7, Tatiana Shavrina6
$^1$University of British Columbia, $^2$Vector Institute, $^3$University of Edinburgh
$^4$New York University, $^5$Canada CIFAR AI Chair, $^6$FAIR at Meta, $^7$Meta Superintelligence Labs
$^\dagger$Work done during internship at Meta, $^\ddagger$Work done at Meta
GRAY
Self-improving AI systems aim to reduce reliance on human engineering by learning to improve their own learning and problem-solving processes. Existing approaches to recursive self-improvement typically rely on fixed, handcrafted meta-level mechanisms, which fundamentally limit how fast such systems can improve. The Darwin Gödel Machine (DGM) (Zhang et al., 2025b)Zhang and colleagues, 2025 demonstrates that open-ended self-improvement is achievable in coding. Starting from a single coding agent, the DGM repeatedly generates and evaluates self-modified variants, forming a growing archive of stepping stones for future improvement. Because both evaluation and self-modification are coding tasks, gains in coding ability can translate into gains in self-improvement ability. However, this alignment does not generally hold beyond coding domains. We introduce hyperagents, self-referential agents that integrate a task agent (which solves the target task) and a meta agent (which modifies itself and the task agent) into a single editable program. Crucially, the meta-level modification procedure is itself editable, enabling metacognitive self-modification, improving not only task-solving behavior, but also the mechanism that generates future improvements. We instantiate this framework by extending DGM to create DGM-Hyperagents (DGM-H). By allowing the improvement procedure to evolve, the DGM-H eliminates the assumption of domain-specific alignment between task performance and self-modification skill, and can potentially support self-accelerating progress on any computable task. Across diverse domains (coding, paper review, robotics reward design, and Olympiad-level math-solution grading), the DGM-H improves performance over time and outperforms baselines without self-improvement or open-ended exploration, as well as prior self-improving systems like DGM. We further show that the DGM-H improves the process by which it generates new agents (e.g., persistent memory, performance tracking), and that these meta-level improvements transfer across domains and accumulate across runs. All experiments were conducted with safety precautions (e.g., sandboxing, human oversight). We discuss what safety entails in this setting and the broader implications of self-improving systems. DGM-Hyperagents offer a glimpse of open-ended AI systems that do not merely search for better solutions, but continually improve their search for how to improve.
With appropriate safety considerations, AI systems that can improve themselves could transform scientific progress from a human-paced process into an autonomously accelerating one, thereby allowing society to realize the benefits of technological advances much earlier. Such self-improving AI seeks to continually improve its own learning and task-solving abilities. However, most existing self-improvement architectures rely on a fixed meta agent (i.e., a higher-level system that modifies a base system). This creates a limitation since the base system can only be improved within the boundaries defined by the meta agent’s design. Adding a meta-meta system to improve the meta agent does not solve this problem, it merely shifts the issue upward and ultimately leads to an infinite regress of meta-levels. To overcome this limitation and allow a system to modify any part of itself without being constrained by its initial implementation, the system must be
self-referential, that is, able to analyze, modify, and evaluate itself (Kirsch and Schmidhuber, 2022; Zhang et al., 2025b)as discussed in prior research. When the mechanism of improvement is itself subject to improvement, progress can become self-accelerating and potentially unbounded (Lu et al., 2023).
The Darwin Gödel Machine (DGM) (Zhang et al., 2025b)D G M demonstrates that open-ended self-improvement is achievable in coding. In the DGM, agents generate and evaluate modifications to their own code, and successful variants are retained in an archive as stepping stones for further improvement. However, the DGM relies on a handcrafted, fixed mechanism to produce self-improvement instructions (Appendix B). This mechanism analyzes past evaluation results and the agent’s current codebase to generate an instruction directing where the agent should self-improve. This mechanism is not modifiable. Hence, the DGM’s capacity for self-improvement is bottlenecked by this fixed instruction-generation step. Despite this handcrafted step, the DGM can still improve at self-improving. Because both evaluation and self-modification are coding tasks, improvements in evaluation performance directly reflects the agent’s capacity to generate effective self-modifications. To improve at self-improving, the DGM relies on a limiting assumption: that the skills required to solve the evaluation tasks are the same as those required for effective self-reflection and self-modification. This assumption is unlikely to hold outside coding domains, where task-solving skills may differ substantially from the skills needed to analyze failures, propose effective self-improvements, and implement them.
This work introduces hyperagents, self-referential agents that can in principle self-improve for any computable task. Here, an agent is any computable program, optionally including calls to foundation models (FMs)F Ms, external tools, or learned components. A task agent solves a given task. A meta agent modifies agents and generates new ones. A hyperagent combines the task agent and the meta agent into a single self-referential, modifiable program, such that the mechanism responsible for generating improvements is itself subject to modification. As a result, a hyperagent can improve not only how it solves tasks (i.e., the task agent), but also how it generates and applies future modifications (i.e., the meta agent). Because its self-improvement mechanism is itself modifiable, we call this metacognitive self-modification. We extend the DGM with hyperagents, creating DGM-Hyperagents (DGM-H). The DGM-H retains the open-ended exploration structure of the DGM and extends the DGM with metacognitive self-modification. As with DGM, to support sustained progress and avoid premature convergence, the DGM-H grows an archive of hyperagents by branching from selected candidates, allowing them to self-modify, evaluating the resulting hyperagents, and adding them back to the archive. Because a hyperagent can modify its self-modification process, the DGM-H is not constrained by its initial implementation and can potentially self-improve for any computable task.
Across our experiments, the DGM-H demonstrates substantial and generalizable improvements in both task performance and self-improvement ability. On the Polyglot coding benchmark (Gauthier, 2024), the DGM-H achieves gains comparable to the most established prior self-improving algorithm (the Darwin Gödel Machine, Zhang et al., 2025b), despite not being handcrafted for coding. Beyond coding, the DGM-H substantially improves performance on paper review (Zhao et al., 2026) and robotics reward design (Genesis, 2024), with gains transferring to held-out test tasks and significantly outperforming prior self-improving algorithms, which struggle outside coding unless customized. Ablations without self-improvement or without open-ended exploration show little to no progress, highlighting the necessity of each component (Section 5.1). Crucially, the DGM-H learns transferable mechanisms on how to self-improve (e.g., persistent memory, performance tracking) that systematically improve its ability to generate better task or meta agents over time. As a result, meta-level improvements learned by the DGM-H transfer across domains. Specifically, hyperagents optimized in one setting (i.e., paper review and robotics tasks) remain significantly effective at generating improved task agents in a different domain (i.e., Olympiad-level math grading) (Section 5.2). We further show that self-improvements learned by the DGM-H in one setting can compound with continued self-improvement in another setting (Section 5.3). This suggests that, given appropriate tasks, the DGM-H has the potential to achieve unbounded open-ended self-improvement over time. We discuss the safety implications of such open-ended self-improving systems and outline practical considerations for responsible deployment in Section 6. Overall, hyperagents open up the possibility of improving their ability to improve while improving their ability to perform any computable task.
2 Related Work
Open-Endedness. Open-endedness refers to the ability of a system to continually invent new, interesting, and increasingly complex artifacts, extending its own frontier of discovery without a fixed objective or predefined end (Stanley et al., 2017; Hughes et al., 2024). Recent work has leveraged FMs as proxies for human interestingness and as versatile engines for generating and evaluating novel behaviors across diverse domains (Zhang et al., 2024; Faldor et al., 2025). Building on these advances, recent progress in open-ended learning (Hu et al., 2025; Zoph and Le, 2017; Colas et al., 2023; Lehman et al., 2023) and quality-diversity algorithms (Lehman and Stanley, 2011; Mouret and Clune, 2015; Bradley et al., 2023; Samvelyan et al., 2024; Ding et al., 2024; Pourcel et al., 2023; Coiffard et al., 2025; Dharna et al., 2025; Yuan et al., 2026) has shown that sustained exploration can produce diverse and increasingly capable artifacts across domains ranging from game-playing agents (Klissarov et al., 2023, 2025; Wang et al., 2024) to scientific discovery (Lu et al., 2024a,b; Romera-Paredes et al., 2024; Novikov et al., 2025; Audran-Reiss et al., 2025) and robotic control (Cully et al., 2015; Li et al., 2024; Grillotti et al., 2025). Recent progress has shown that open-ended AI systems capable of continuously generating diverse and increasingly complex artifacts are possible (Zhang et al., 2024; Faldor et al., 2025; Hu et al., 2025). An important next step is to explore how such systems can achieve compounding improvement. In human scientific and technological progress, advances often build on prior advances not only by producing better artifacts, but also by improving the tools and processes that generate future discoveries, leading to accelerating innovation (Good, 1966; Kwa et al., 2025). Inspired by this pattern, we focus on open-ended systems that can improve not only the artifacts they generate, but also the mechanisms by which novelty and progress are produced (Clune, 2019; Jiang et al., 2023).
Self-improving AI. Early theoretical work on self-improving AI dates back to formal models of self-modifying agents (Hutter, 2003). One prominent example is the Gödel Machine (Schmidhuber, 2003), which proposes agents that rewrite themselves when provably beneficial, though such approaches remain impractical in real-world settings. Subsequent research explored self-improvement through adaptive neural systems, in which agents modify their own weights or learning dynamics via meta-learning (Schmidhuber, 1993; Miconi et al., 2018; Javed and White, 2019; Beaulieu et al., 2020; Miconi et al., 2020; Irie et al., 2022; Chalvidal et al., 2022; Oh et al., 2025), evolution (Stanley and Miikkulainen, 2002; Lange et al., 2023; Qiu et al., 2025; Zhao et al., 2025), or self-play (Silver et al., 2016, 2017; Xia et al., 2025b, 2026). Notably, Silver et al. (2017)Silver and colleagues use self-play to iteratively improve neural network agents, achieving superhuman performance in domains such as Go and chess, although the underlying learning algorithms themselves remain fixed and human-designed. More recently, FMs have enabled self-improvement through iterative refinement of prompts (Fernando et al., 2023; Wang et al., 2025a; Zhang et al., 2025c,a; Ye et al., 2026), reasoning traces (Zelikman et al., 2022; Yin et al., 2025; Havrilla et al., 2024; Zhuge et al., 2024), and entire code repositories (Zhang et al., 2025b; Wang et al., 2025b; Xia et al., 2025a), as well as through systems that update model weights using self-generated data or interaction (Wu et al., 2024; Zweiger et al., 2025; Wen et al., 2025; Wei et al., 2025b). Among these, the Darwin Gödel Machine (DGM) (Zhang et al., 2025b) stands out as a practical instantiation of recursive self-improvement in coding domains. However, despite their effectiveness, most existing approaches (including the DGM and its derivatives) rely on fixed, handcrafted meta-level mechanisms (Appendix B) that constrain how self-improvement can compound over time and generalize across domains.
Self-referential Meta-learning. Self-referential meta-learning studies systems that learn to improve the mechanisms by which learning occurs. Prior work has explored this idea in neural networks (Kirsch and Schmidhuber, 2022; Jackson et al., 2024) and evolutionary methods (Lu et al., 2023). More recently, several works have explored self-referential improvement using FM-based agents (Zelikman et al., 2024; Robeyns et al., 2025; Yin et al., 2025; Zhang et al., 2025b). The Darwin Gödel Machine (DGM) (Zhang et al., 2025b) and its successors (Wang et al., 2025b; Xia et al., 2025a; Weng et al., 2026) instantiate recursive self-improvement through self-modification, primarily in coding domains. However, these approaches improve at improving primarily within coding tasks only. In the DGM and related systems, a coding agent is tasked with improving itself, and the resulting improved coding agent is then used in subsequent self-improvement steps to generate an even better version of itself. Because both the evaluation task and the self-modification process involve coding, improving the coding agent also enhances the system’s ability to carry out future self-improvements. However, this property only holds when the evaluation task and the self-modification task are closely aligned. For example, if the evaluation task were instead poetry writing, improving an agent’s poetry-writing ability would
not necessarily improve its ability to modify its own code. Prior work therefore relies on an alignment between the evaluation task and the skills required for self-improvement. In contrast, hyperagents do not assume such alignment, because the self-modification mechanism is fully modifiable and not tied to any particular task domain. Hence, hyperagents can improve both task performance and the process of improvement itself across any computable task.
3 Methods
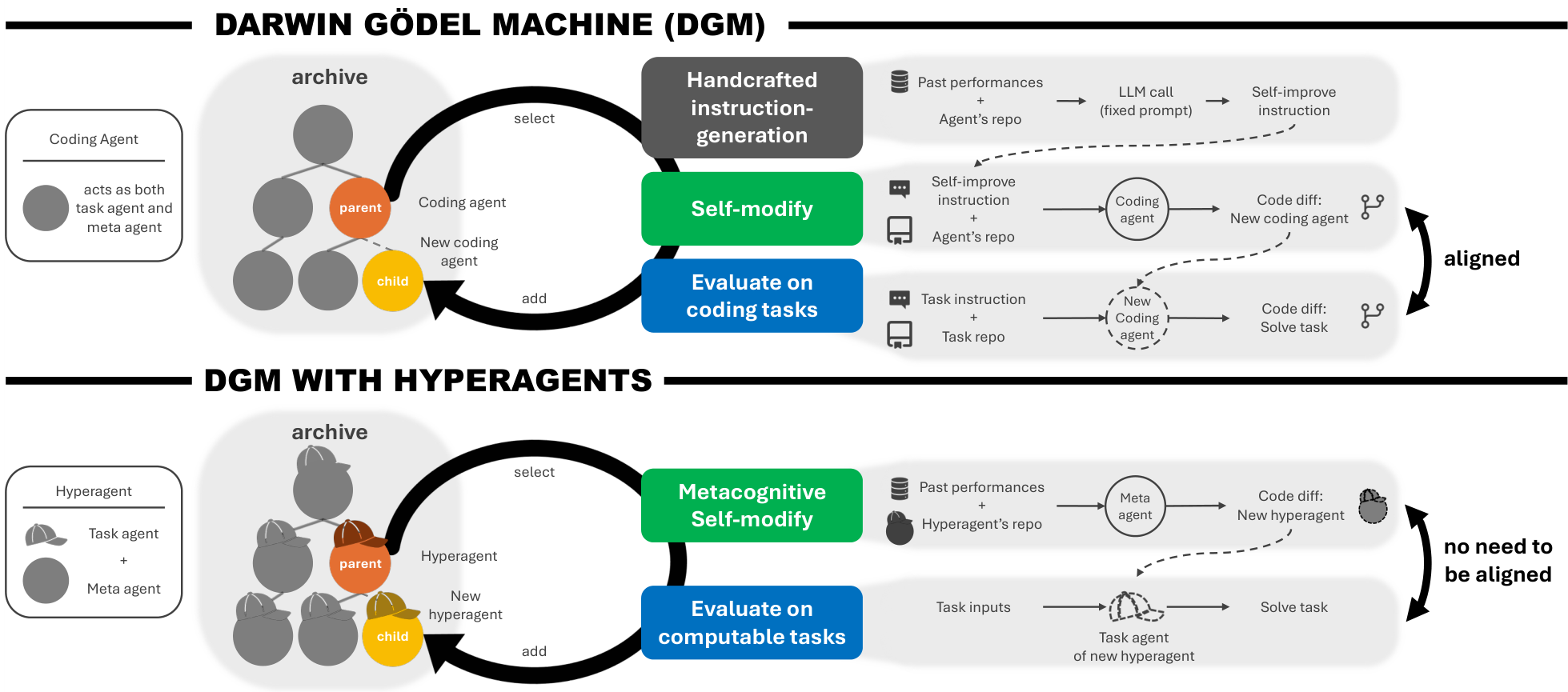
Figure 1 The Darwin Gödel Machine with Hyperagents. The DGM-Hyperagents (DGM-H) extends the Darwin Gödel Machine (DGM) (Zhang et al., 2025b) beyond coding tasks, enabling agents to improve not only their task performance but also their ability to improve themselves, across any computable task. (Top) In the DGM, a coding agent evolves through open-ended exploration by generating and evaluating self-modified variants, which are stored in an archive of stepping stones. The same coding agent acts as both the task agent (to be evaluated) and the meta agent (to generate modifications). While this design enables compounding gains in coding, the instruction-generation mechanism that drives self-improvement is fixed and handcrafted. Consequently, recursive improvement depends on alignment between coding performance and self-modification ability. (Bottom) In the DGM-H, the task agent and meta agent are combined into a single modifiable program called a hyperagent. This design allows the meta agent itself to be autonomously improved. The system retains the open-ended exploration structure of the DGM while making the meta-level improvement mechanism editable. This enables metacognitive self-modification and supports self-referential improvement across any computable task.
We introduce hyperagents, self-referential agents that unify task execution and agent generation into a single modifiable program. A hyperagent can improve not only how it solves tasks but also how it generates future improvements. To enable sustained and accumulating progress, we instantiate hyperagents by building directly on the Darwin Gödel Machine (DGM) to form DGM-Hyperagents (DGM-H). The DGM provides an open-ended, population-based exploration process that maintains an archive of progressively improving agents, allowing successful variants to serve as stepping stones for future gains. DGM-H retains this open-ended evolutionary structure and extends it by making the entire meta-level modification mechanism editable (Figure 1). By allowing agents to modify not only how they solve tasks but also how they improve themselves, the DGM-H has the potential to open-endedly self-improve on any computable task.
Agents. This paper defines an agent as any computable program, optionally including calls to FMs, external tools, or learned components. Agents are not restricted to a particular representation (e.g., neural networks or prompts) and may include arbitrary algorithmic logic, memory, and control flow. A task agent is an agent instantiated to solve a set of tasks. Examples include generating code edits for a software repository (Gauthier, 2024; Jimenez et al., 2024)as seen in prior research, predicting acceptance decisions for research papers (Couto et al., 2024), and designing reward functions for robotics environments (Ma et al., 2024). Task agents are evaluated empirically
on the given task. A meta agent is an agent whose only task is to modify existing agents and generate new ones. Given access to the entire archive of previous agents and evaluations, a meta agent proposes changes intended to improve future performance (including potentially many generations later). Importantly, these changes may target not only task-solving logic but also the meta agent itself, enabling improvements to the procedures by which future modifications are generated.
Hyperagents. A hyperagent is a self-referential agent that integrates a task agent and a meta agent within a single editable program, enabling it to modify not only how it performs tasks but also how it generates future self-modifications. Unlike hierarchical systems with fixed meta-levels, in hyperagents the meta agent is part of the same editable program and can rewrite itself. As a result, a hyperagent can improve both (1) how it solves tasks and (2) how it generates future self-improvements. We use Python, which is Turing-complete (Turing et al., 1936)as described by Turing and colleagues, and since a hyperagent can edit any code, it has the potential to build any computable machine.
Metacognitive self-modification. In hyperagents, the agent’s self-improvement mechanism is itself subject to modification. In addition to improving its performance on a given task, the agent can simultaneously modify the procedures by which it proposes and applies further self-improvements. We refer to this process as metacognitive self-modification, in which the hyperagent improves not only the task-performing agent responsible for solving the given task, but also the meta agent that determines how subsequent hyperagents are generated. This characteristic addresses a central limitation of prior self-improving systems (Zhang et al., 2025b; Wang et al., 2025b)identified in recent work by Zhang and Wang by directly enabling improvements to the self-improvement process itself (Section 2). Examples of such metacognitive self-modifications are presented in Section 5.2 and Appendix E.3.
Darwin Gödel Machine with Hyperagents. Augmenting the original DGM (Zhang et al., 2025b)by Zhang and colleagues with hyperagents, we create DGM-Hyperagents (DGM-H). DGM-H employs the open-ended exploration process in the DGM to mitigate premature convergence and avoid getting trapped in local optima. This process maintains an archive of generated hyperagents, initialized with a single hyperagent and expanded over time by continuously accumulating generated variants. The process alternates between two phases: metacognitive self-modification and evaluation. During the metacognitive self-modification phase, selected parent hyperagents from the archive generate modified versions of themselves. Parent selection is probabilistic and proportional to a hyperagent’s performance, and inversely proportional to the number of children that successfully compiled, biasing sampling toward hyperagents that perform well and generate strong descendants while preserving exploration (Appendix A.2). During the evaluation phase, each modified hyperagent is empirically evaluated and subsequently added to the archive. In principle, a fully self-referential algorithm should allow modification of every part of itself (including the parent selection and evaluation mechanisms). While we present preliminary results exploring the possibility of automatically improving the parent selection mechanism in Appendix E.5, the experiments in the main text use a handcrafted parent selection mechanism that is not subject to modification in order to isolate the effects of hyperagent self-modification. Overall, DGM-H consists of two interacting components: (1) an open-ended exploration process inherited from the DGM, and (2) an initial hyperagent, which evolves over time through self-generated variants (Figure 1, Appendix A). By extending the DGM to make the meta-level mechanism itself modifiable, the DGM-H generalizes recursive self-improvement beyond coding and enables self-referential improvement for any computable task.
4 Experiment Setup
The DGM-H is initialized with a single hyperagent built around a frozen FM (Brown et al., 2020)by Brown and colleagues with external tool-use capabilities (Schick et al., 2023)as described by Schick and colleagues. The FM autonomously invokes tools as needed at each step. This initial hyperagent is equipped with two tools: a bash tool for executing shell commands, and a specialized tool for inspecting and modifying files. In the initial hyperagent, the task agent receives the task inputs and outputs the response from a single FM call. The meta agent receives the location of the agent’s repository, the location of previous evaluation results, and the number of remaining experiment iterations (the experiment budget is a hyperparameter), and is tasked with modifying any part of the given codebase (Appendix A.1). We deliberately keep the implementation of the initial hyperagent (i.e., both the task agent and the meta agent) simple, allowing for a broad search space and avoiding prematurely constraining the range of possible improvements. Appendix D.1 details the FMs and the hyperparameters used in each experiment, while Appendix D.2 reports the corresponding cost estimates.
4.1 Baselines
We compare the Darwin Gödel Machine with Hyperagents (DGM-H) against a set of baselines designed to isolate the contributions of self-improving meta agents, open-ended exploration, and metacognitive self-modification (i.e., hyperagents) (Appendix B). DGM-H without self-improving meta agents (DGM-H w/o self-improve) fixes the meta agent modifying other hyperagents to the initial meta agent for the entire run. While the system can still generate and evaluate new hyperagents, the procedures used to propose and apply modifications are not themselves modifiable. This baseline replicates the approach of (ADAS, Hu et al., 2025)A D A S, by Hu and colleagues, in this setting. It tests whether performance gains arise solely from task-level optimization under a fixed meta-level mechanism, or from improvements in the self-improvement process itself. DGM-H without open-ended exploration (DGM-H w/o open-ended exploration) removes the archive of previously generated hyperagents. Instead of retaining previous variants as stepping stones for future exploration, each newly generated hyperagent replaces its predecessor. After generating a new hyperagent, it is evaluated and automatically becomes the next selected parent. This baseline isolates the role of open-ended, population-based search. Comparing against this baseline tests whether sustained improvement requires accumulating and reusing diverse intermediate solutions.
We also compare against the original implementation of the Darwin Gödel Machine (DGM) (Zhang et al., 2025b)D G M, by Zhang and colleagues. The DGM relies on a handcrafted, fixed mechanism to generate self-improvement instructions. Because this instruction-generation mechanism is designed specifically for coding benchmarks and is not modifiable, the DGM’s self-improvement capacity in other domains is limited (Section 2). To provide a stronger comparison, we manually customize the DGM’s instruction-generation mechanism for the target domains (DGM-custom) (Appendix B). This baseline measures how much the DGM relies on human engineering to remain competitive across domains. Comparing the DGM-H against this baseline tests whether automated metacognitive self-modification can outperform human-designed self-improvement mechanisms. Additionally, we compare against static solutions that have been handcrafted for each domain in prior work.
4.2 Domains
We evaluate our method and baselines across diverse domains (i.e., coding, paper review, robotics reward design, and Olympiad-level math grading) (Appendix C). To reduce computational cost, for each domain we first evaluate agents on a small subset of the training tasks to estimate overall effectiveness. Only agents that demonstrate sufficient performance are subsequently evaluated on the remaining training tasks. Agents that do not are treated as having zero performance on unevaluated tasks. Domain-specific evaluation protocols are described in detail in the subsequent paragraphs. For domains where we create AI judges to reflect human data (i.e., paper review and Olympiad-level math grading), we construct a validation subset because the AI judges are more likely to overfit to the training data. When a validation subset is defined for a domain, the performance component used in parent selection is measured on the validation set. Otherwise, it is measured on the training set. Each domain includes separate held-out test tasks that are used only for final evaluation.
Coding. We choose Polyglot (Gauthier, 2024)by Gauthier as a computationally cost-efficient coding benchmark for direct comparison with prior work (Zhang et al., 2025b). In this benchmark, the agent is given a code repository and a natural language instruction describing a desired change, and must modify the repository accordingly. We follow the experimental setup used in the DGM (Zhang et al., 2025b), including the same training and test splits, no validation set, and the same staged evaluation protocol (i.e., first evaluating each agent on 10 tasks to estimate effectiveness before expanding to 50 additional tasks) (Appendix C.1).
Paper review. This domain evaluates agents on a simulated conference peer review task. For each task, the agent is given the full text of an AI research paper and must predict a binary accept/reject decision. We include paper review to evaluate the DGM-H in a hard-to-verify setting where there is no objective ground truth. Peer review is subjective, and reviewer decisions can vary due to differing priorities and perspectives. We do not aim to change the peer review system, but rather, we study whether hyperagents can automatically learn decision procedures that align with observed human judgments. The agent outputs a single acceptance decision, and performance is measured by comparing predictions against observed acceptance outcomes. The dataset is drawn from Zhao et al. (2026)Zhao and colleagues, which constructs a large-scale benchmark from publicly available submissions and acceptance decisions from recent top-tier machine learning conferences. The representative static baseline for this domain is the reviewer agent from the AI-Scientist-v2 (Yamada
et al., 2025). Appendix C.2 provides full details on the dataset splits (train, validation, and test), the staged evaluation protocol (i.e., first evaluating each agent on a 10-task subset to estimate effectiveness before expanding evaluation to a total of 100 tasks), and the representative baselines for this domain.
Robotics reward design. This domain evaluates an agent’s ability to design reward functions for robotic tasks. We include this domain to move beyond language-only tasks and show that hyperagents can leverage external simulators (e.g., physics engines) and training algorithms (e.g., reinforcement learning (RL)) to produce effective solutions. Given a natural language description of a robotics task, an agent must generate a suitable reward function. This reward function is then used to train a quadruped robot in simulation using RL (Genesis, 2024). The quality of the agent’s solution is measured by the performance of the resulting policy: after training with the generated reward function, we evaluate how well the robot achieves the desired behavior (Ma et al., 2024). We use separate training and test tasks. During training, agents are required to generate reward functions that enable the robot to walk forward. For held-out testing, agents must zero-shot generate new reward functions that maximize the robot’s torso height. Because reward functions that successfully enable a robot to walk forward do not induce jumping behaviors (the more optimal behavior for maximizing the robot’s torso height), this setup evaluates whether a single agent can design suitable reward functions for different robotics tasks. This domain does not have a separate validation task. Appendix C.3 provides full details on the staged evaluation protocol (i.e., first evaluating each agent on 3 repetitions of the training task to estimate effectiveness before expanding evaluation to a total of 6 repetitions), and the representative baselines for this domain.
Olympiad-level math grading. This domain evaluates an agent’s ability to grade solutions to Olympiad-level math problems. This domain is reserved as a held-out meta-evaluation to test whether DGM-H’s improvements to its self-improvement process transfer across domains and continue to compound over time. We use IMO-GradingBench (Luong et al., 2025), which consists of International Mathematical Olympiad (IMO)-level problems paired with candidate solutions and expert human grades. For each task, the agent is given an IMO-level problem, a candidate solution, reference solutions, and grading guidelines to predict a discrete score. Performance is measured by the accuracy of the agent’s grades with respect to expert human grades. The representative static baseline for this domain is the ProofAutoGrader from IMO-GradingBench. Appendix C.4 provides full details on the score labels, dataset splits (train, validation, and test), the staged evaluation protocol (i.e., first evaluating the agent on a 10-task subset to estimate effectiveness before expanding evaluation to a total of 100 tasks), and the baselines for this domain.
5 Results
For each experiment, we run each method 5 times. We report medians with 95% bootstrap confidence intervals computed from 1,000 resamples, using the notation median (CI: lower – upper). In line plots, lines show median performance and shaded regions indicate the confidence intervals (Figures 2 to 4). Bar plots report median performance on held-out test sets, with error bars indicating confidence intervals (Figures 2 to 4). Statistical significance is assessed using the Wilcoxon signed-rank test. Overall, the DGM-H exhibits general self-improvement at both the task and meta levels. Improvements to the task agent transfer to held-out test tasks within each domain, exceeding open-sourced static baselines (Section 5.1). Meta-level improvements transfer across domains, enabling hyperagents to significantly improve their ability to generate better task agents in previously unseen domains (Section 5.2). Self-improvements learned in one DGM-H run can potentially accelerate learning in subsequent runs and continue to compound as further self-modifications are applied (Section 5.3). All experiment logs are open-sourced in our codebase.
5.1 Improving Task Performance
The DGM-H can achieve self-improvement in coding comparable to prior self-improving algorithms. On the Polyglot coding benchmark, we use the same experimental settings as in the DGM (e.g., identical FM parameters, same number of 80 iterations) to enable a direct comparison. Across 5 runs, the DGM-H improves its training performance on the 50-task Polyglot subset from 0.140 (the initial agent) to 0.340 (CI: 0.300 – 0.380). When evaluated on the full Polyglot benchmark, which consists largely of tasks unseen during training, performance increases from 0.084 (the initial agent) to 0.267 (CI: 0.231 – 0.280). These improvements are
comparable to those reported for the original DGM, which improves from 0.140 to 0.380 on the training subset and from 0.142 to 0.307 on the full benchmark (Zhang et al., 2025b)Zhang and colleagues, 2025 b. Overall, these results show that the DGM-H can effectively self-improve in the coding domain and achieve a similar level of improvement to the original DGM, despite not being handcrafted specifically for coding tasks.
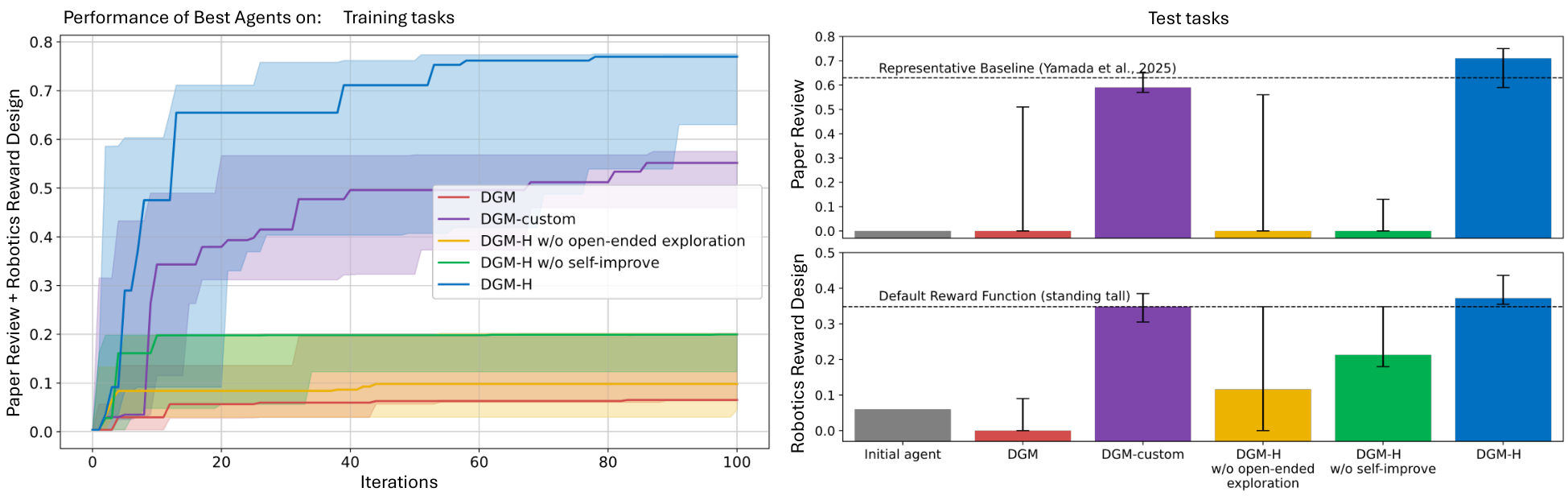
Figure 2 Metacognitive self-modification and open-ended exploration enable the DGM-H to continue making progress and improve its performance. (Left) The DGM-H can optimize for diverse tasks within the same run and automatically discovers increasingly better task agents. (Right) The best discovered task agents, selected based on validation or training scores, are evaluated on test tasks in (Top-Right) paper review and (Bottom-Right) robotics reward design. The DGM-H outperforms baselines that lack metacognition (i.e., the original DGM), self-improvement, or open-ended exploration, showing that all components are essential for continual self-improvement.
Beyond coding, we evaluate the DGM-H on paper review and robotics reward design to assess its ability to self-improve across diverse tasks within a single run (Appendix A.4). If an agent fails the staged evaluation in any domain, it is not evaluated on the full training set for any domain, and a score of zero is assigned for all remaining tasks. For example, when jointly optimizing the paper review and robotics reward design domains within the same experiment run, failure in the staged evaluation of either domain (e.g., correctly predicting none of the paper reviews in a smaller training subset, or failing to generate any compilable reward function) results in the agent not being evaluated on the full training set for either domain. Only the best agents, selected via validation scores (or training scores when validation tasks do not exist), are evaluated on the test set. All runs start from the same initial agent, which directly outputs the response from a single FM call (Appendix A.1). This initial agent achieves a test-set score of 0.0 on paper review and 0.060 on robotics reward design (Figure 2). In paper review, the initial agent fails to produce outputs in the required format because no task-specific parsing or post-processing is provided, resulting in a score of 0.0. In robotics reward design, the initial agent typically generates reward functions that either fail to compile (e.g., due to invalid environment variables) or do not yield effective policies. However, the initial agent occasionally produces a minimally functional reward, leading to a small but non-zero average score. Starting from this initial agent, each method is run for 100 iterations.
The original DGM requires domain-specific customization to generalize beyond coding. When applied in the form designed specifically to optimize coding agents, the original DGM achieves test-set performance of 0.0 (CI: 0.0 – 0.510)with a confidence interval of zero to zero point five one zero on paper review and 0.0 (CI: 0.0 – 0.090)with a confidence interval of zero to zero point zero nine zero on robotics reward design. This outcome is expected, as the original DGM’s instruction-generation mechanism is explicitly tailored to coding tasks and to improving coding agents (Appendix B). However, when manually customized for each new domain, DGM-custom achieves substantially stronger results: 0.590 (CI: 0.570 – 0.650)with a confidence interval of zero point five seven zero to zero point six five zero on paper review and 0.348 (CI: 0.305 – 0.385)with a confidence interval of zero point three zero five to zero point three eight five on robotics reward design. DGM-custom significantly outperforms the original DGM in both domains p<0.05with p less than zero point zero five (Figure 2). These results highlight both the strength of the DGM within its intended domain and the importance of domain-specific manual customization for extending its self-improvement capabilities beyond coding in its original implementation.
Metacognitive self-modification enables sustained task improvement across domains. The DGM-H substantially improves task performance over time in both domains, demonstrating effective improvement of the task agent. Importantly, these gains transfer to held-out test sets, indicating that improvements reflect
general competence rather than overfitting to training tasks. On test tasks, DGM-H improves paper review performance from 0.0 (the initial agent) to 0.710 (CI: 0.590 – 0.750) (Appendix E.1.1). Several top-performing agents outperform the open-sourced static baseline, which achieves 0.630 (Yamada et al., 2025). On robotics reward design, DGM-H improves performance from 0.060 (the initial agent) to 0.372 (CI: 0.355 – 0.436) (Appendix E.1.2), surpassing the default reward function that directly optimizes the evaluation metric (0.348).
Qualitatively, the DGM-H improves task agents by moving beyond surface-level prompt tweaks toward structured, reusable decision machinery. In paper review, it shifts from superficial behavioral instructions (e.g., adopting a “rigorous” persona) to explicit multi-stage evaluation pipelines with checklists, decision rules, and clearly defined criteria, resulting in more consistent and higher-quality judgments (Appendix E.2). In robotics reward design, the DGM-H incrementally builds and refines an internal knowledge base of environment constraints, valid state variables, and reward-scaling heuristics, eliminating compilation failures and reducing reward misspecification. The DGM-H accumulates and refines domain knowledge (e.g., environment documentation, grading criteria) and integrates it into increasingly sophisticated decision frameworks, enabling complex, consistent task behavior without manual, domain-specific engineering (Appendix E.2).
The DGM-H significantly outperforms the original DGM in both domains (p<0.05p less than zero point zero five), reflecting the limitations of the original DGM’s fixed instruction-generation mechanism when applied to non-coding tasks (Figure 2). The DGM-H achieves higher median performance than DGM-custom on the test tasks in both domains, although the difference is not statistically significant (p>0.05p greater than zero point zero five) (Figure 2). Notably, in the robotics reward design test task (i.e., design a reward function that trains the robot to maximize its torso height), the DGM-H almost always generates task agents that design reward functions inducing jumping behaviors, rather than getting stuck in the local optimum of standing tall. In contrast, DGM-custom often generates task agents that fail to escape this local optimum. This qualitative difference suggests that metacognitive self-modification can match or exceed handcrafted, domain-specific mechanisms.
Both metacognitive self-modification and open-ended exploration are necessary for sustained improvement. DGM-H w/o self-improve (Hu et al., 2025) shows little to no improvement, achieving test-set performance of 0.0 (CI: 0.0 – 0.130) on paper review and 0.213 (CI: 0.180 – 0.348) on robotics reward design. The DGM-H significantly outperforms this baseline in both domains (p<0.05p less than zero point zero five) (Figure 2), demonstrating that the observed gains in the DGM-H are not solely due to task-level optimization under a fixed meta agent, but also arise from improvements in the self-modification process itself (i.e., the meta agent). Similarly, DGM-H w/o open-ended exploration fails to achieve meaningful improvement, with test-set performance remaining at 0.0 (CI: 0.0 – 0.560) on paper review and 0.116 (CI: 0.0 – 0.348) on robotics reward design. The DGM-H significantly outperforms this baseline in both domains (p<0.05p less than zero point zero five) (Figure 2), highlighting the importance of open-ended, population-based search to create stepping stones for future improvements.
5.2 Improving the Ability to Improve
DGM-H’s superior performance to DGM-H w/o self-improve shows that DGM-H improves the meta agent (i.e., its ability to self-modify and generate new agents) (Section 5.1). This section investigates whether these meta-level improvements are general rather than domain-specific. Specifically, we evaluate whether self-improvement strategies learned in one setting transfer to and accelerate learning in a different domain.
Improvement@k metric. To quantify a meta agent’s ability to generate improved task agents, we introduce the improvement@k (imp@k) metric. Given an initial meta agent MM, an initial task agent AA, an agent-generation algorithm (e.g., DGM or DGM-H variants), and a fixed task, MM is allowed to generate up to kk new task agents from AA and its descendants using the specified algorithm. We define imp@k as the improvement in test performance from the initial task agent AA to the best-performing generated task agent (selected based on validation score) (Appendix D.3). Intuitively, imp@k measures how effectively a meta agent can produce improved variants within a limited number of iterations. To isolate the meta agent’s ability to improve task agents from its ability to improve itself, we hold the meta agent fixed throughout the process (i.e., the agent responsible for generating new task agents is always the initial meta agent MM), yielding DGM w/o self-improve and DGM-H w/o self-improve as the agent-generation algorithms. All experiments in this section run for 50 iterations, measuring imp@50.
The initial meta agent has little to no ability to generate improved task agents. Taking the same initial
Figure 3 Self-improvement strategies learned by the DGM-H in one setting transfer to and accelerate learning in a different setting. We measure an agent’s ability to generate improved agents using imp@50, which takes as input a starting agent, an agent-generation algorithm, and an evaluation task. The algorithm is run for 50 iterations starting from the given agent, and imp@50 is defined as the performance gain of the best generated agent over the starting agent on the task. (Left, DGM w/o self-improve and DGM-H w/o self-improve) On Olympiad-level math grading, starting from the initial agent, both DGM w/o self-improve and DGM-H w/o self-improve achieve little to no improvement, showing that the initial agent has limited ability to generate better agents. (Left, DGM w/o self-improve + transfer) Starting from transfer agents, DGM w/o self-improve also achieves little improvement, showing that the original DGM does not learn transferable meta-level improvements. (Left, DGM-H w/o self-improve + transfer) In contrast, starting from transfer hyperagents, DGM-H w/o self-improve achieves substantial improvement, showing that hyperagents enable DGM-H to acquire transferable self-improvement strategies. (Middle) Regardless of starting from an initial agent or a transfer agent, DGM w/o self-improve yields imp@50 ≈0approximately zero, showing that the original DGM does not improve the meta-level skill of generating improved agents. (Right) Starting from a transfer hyperagent, DGM-H w/o self-improve achieve large positive imp@50, showing that that the self-improvement strategies learned by the DGM-H are general and transferable, and that the DGM-H improves its ability to improve.
meta and task agents as in the above experiments (Section 4), we evaluate the initial meta agent’s ability to generate improved task agents on Olympiad-level math grading. The initial task agent achieves a test-set score of 0.0, as it fails to produce outputs in the required format due to the lack of task-specific parsing or post-processing. After 50 iterations of DGM w/o self-improve, during which the initial meta agent is held fixed and used to generate new task agents starting from a initial task agent, the best generated task agents (across 5 repeated runs) achieve a median test score of 0.0 (CI: 0.0 – 0.0). Accordingly, imp@50 for the initial meta agent under DGM w/o self-improve is 0.0 (CI: 0.0 – 0.0) on Olympiad-level math grading. While DGM w/o self-improve relies on a fixed handcrafted instruction-generation mechanism, DGM-H w/o self-improve does not. DGM w/o self-improve uses a handcrafted instruction-generation mechanism to specify which parts of the agent’s codebase should be modified, whereas DGM-H w/o self-improve allows the meta agent to autonomously decide which parts of the codebase to modify. After 50 iterations of DGM-H w/o self-improve, again holding the initial meta agent fixed and generating task agents from the same initial task agent, the best generated task agents (across 5 repeated runs) achieve a median score of 0.0 (CI: 0.0 – 0.130). Accordingly, imp@50 for the initial meta agent under DGM-H w/o self-improve is 0.0 (CI: 0.0 – 0.130) (Figure 3). These results show that, on Olympiad-level math grading, the initial meta agent has little to no ability to generate improved task agents, regardless of the agent-generation algorithm used (e.g., DGM or DGM-H).
Meta agents optimized in prior DGM-custom runs have little to no ability to generate improved task agents when transferred to a new domain. We evaluate whether self-improvements learned in one setting using the DGM can transfer to new domains. We consider agents optimized in prior DGM-custom runs on the paper review and robotics reward design tasks (Section 5.1). From each run, we select a transfer agent based on the maximum performance gain achieved by its descendants, measured relative to the agent itself and discounted by lineage depth (Appendix D.4). We apply discounting to favor agents that reliably produce strong improvements within fewer self-modification steps, since improvements occurring many iterations later are less directly attributable to the original agent. We choose transfer agents from DGM-custom rather than from DGM because DGM-custom achieved larger improvements in the previous settings (Section 5.1). For transfer, we carry over the entire agent implementation from the source domain, including both the meta agent and the task agent. Concretely, the transfer meta agent is used as the fixed agent responsible for generating new task agents in the target domain, and the transfer task agent serves as the initial task agent from which new variants are generated. We evaluate whether the transfer meta agents can generate improved task agents
in a new domain, Olympiad-level math grading. The transfer task agents (one from each of 5 repeated runs) achieve a test-set score of 0.0 (CI: 0.0 – 0.010). As expected, this performance is low because the agents were optimized for paper review and robotics reward design, which differ substantially from the math grading task. After 50 iterations of DGM w/o self-improve starting from each transfer task agent and holding the transfer meta agent fixed, the best generated task agents (selected based on validation score) achieve a score of 0.0 (CI: 0.0 – 0.020). This corresponds to a imp@50 of 0.0 (CI: 0.0 – 0.010) (Figure 3), showing that the transfer meta agents from DGM-custom runs cannot generate improved task agents in a previously unseen domain. When using DGM w/o self-improve as the agent-generation algorithm, imp@50 for the transfer agents is similar to that of the initial agent (both close to zero). This shows that the task performance improvements observed with DGM-custom rely on domain-specific customizations, rather than on general improvements in the meta ability to generate improved task agents.
Hyperagents optimized in prior DGM-H runs demonstrate transferable ability to generate improved task agents in a new domain. We repeat the transfer experiments for the DGM-H to assess whether hyperagents enable the learning of general self-improvement mechanisms. From prior DGM-H runs on paper review and robotics reward design (Section 5.1), we select one transfer hyperagent per run using the same lineage-discounted criterion described above (Appendix D.4). The transfer hyperagents (one from each of 5 repeated runs) achieve an initial test-set score of 0.0 (CI: 0.0 – 0.0), reflecting the domain shift. After 50 iterations of DGM-H w/o self-improve starting from the transfer hyperagents, the best generated agents (selected based on validation score) achieve a test-set score of 0.630 (CI: 0.540 – 0.630). This corresponds to a imp@50 of 0.630 (CI: 0.540 – 0.630) (Figure 3). These results show that transfer hyperagents can generate improved agents in a previously unseen domain. When using DGM-H w/o self-improve as the agent-generation algorithm, imp@50 for the transfer agents is significantly higher than imp@50 for the initial agent p<0.05p less than zero point zero five. This indicates that the transfer agents are substantially more effective at generating improved agents, and that the meta-improvements learned through DGM-H in one run are general and transferable, accelerating learning in a different domain.
We qualitatively attribute the observed transfer gains to a set of general-purpose meta-level capabilities that the DGM-H autonomously acquires during prior runs. In particular, the transfer hyperagents have features such as performance tracking and persistent memory, which allow them to reason about improvement as an ongoing process rather than as isolated code edits (Appendix E.3). As a result, even when transferred to an unseen domain, these hyperagents can quickly self-improve and make meaningful progress (Figure 3). This contrasts with DGM transfer agents, whose gains rely on domain-specific customizations and do not improve the underlying agent-generation process itself. These qualitative observations show that the DGM-H learns how to improve, yielding general and transferable self-improvement capability.
One example is DGM-H’s autonomous development of performance tracking infrastructure. Rather than relying on isolated evaluation outcomes, the hyperagent records, aggregates, and compares performance metrics across iterations, identifying which changes yield sustained improvements and which lead to regressions. This performance tracking supports informed decision-making, such as prioritizing promising iterations and avoiding unproductive modification directions. The snippet below shows an automatically introduced performance tracker that logs and organizes metrics across iterations:
"""Calculate improvement trend using moving average."""filtered = self.historyif domain:filtered = [h for h in self.history if h.get(’domain’) == domain]if len(filtered) < window * 2:return Nonerecent_avg = sum(h[’score’] for h in filtered[-window:]) / windowolder_avg = sum(h[’score’] for h in filtered[-window*2:-window]) / windowreturn recent_avg - older_avg # Positive if improvingdef get_statistics(self, domain: str = None):"""Get comprehensive statistics."""scores = [h[’score’] for h in filtered]return {"total_generations": len(filtered),"best_score": max(scores),"worst_score": min(scores),"average_score": sum(scores) / len(scores),"improvement_trend": self.get_improvement_trend(domain)}
Another example is DGM-H’s innovation of persistent memory, which enables learning to accumulate across iterations. Instead of merely logging numerical scores, the hyperagent stores synthesized insights, causal hypotheses, and forward-looking plans (e.g., identifying which generations performed best, diagnosing over-corrections, and proposing how to combine successful strategies). This memory is actively consulted during subsequent self-modification steps, allowing later generations to build on earlier discoveries and avoid repeating past mistakes. This is an example of a stored memory entry:
{"best_performers_analysis": {"value": "Best Performing Generations:\n\nPaper Review:\n- Gen55: 63% acc, 25% accept rate, 38% accept recall, 88% reject recall (too harsh)\n- Gen64: 61% acc, 53% accept rate, 64% accept recall, 58% reject recall (BEST BALANCE)\n\nGenesis Go2Walking:\n- Gen62: 0.802 fitness (BEST)\n- Gen63: 0.798 fitness\n\nKey Insight: Gen55 has best accuracy but is too harsh. Gen64 improved balancebut lower accuracy. Need to combine gen55’s critical reasoning with gen64’s balance.","timestamp": "2026-01-07T00:43:27.550275"},"gen66_results": {"value": "Gen 66 Results (Latest): Paper Review - 52% accuracy (WORSE than gen64’s 61%),94% accept rate (EXTREME accept bias). CRITICAL ISSUE: Paper review went backwards- gen65 changes over-corrected.","timestamp": "2026-01-07T01:03:41.176643"},"iteration_66_improvement": {"value": "Iteration 66 Improvement: CORRECTED paper review prompt after gen65 over-correction.New approach: (1) Clear REJECT criteria with specific triggers, (2) Decision Protocolwith explicit thresholds (~40%/~60%), (3) Borderline guidance defaults to REJECT.Target: 62-64% accuracy with 55-65% reject rate.","timestamp": "2026-01-07T01:06:35.559820"}}
5.3 Compounding Self-Improvements
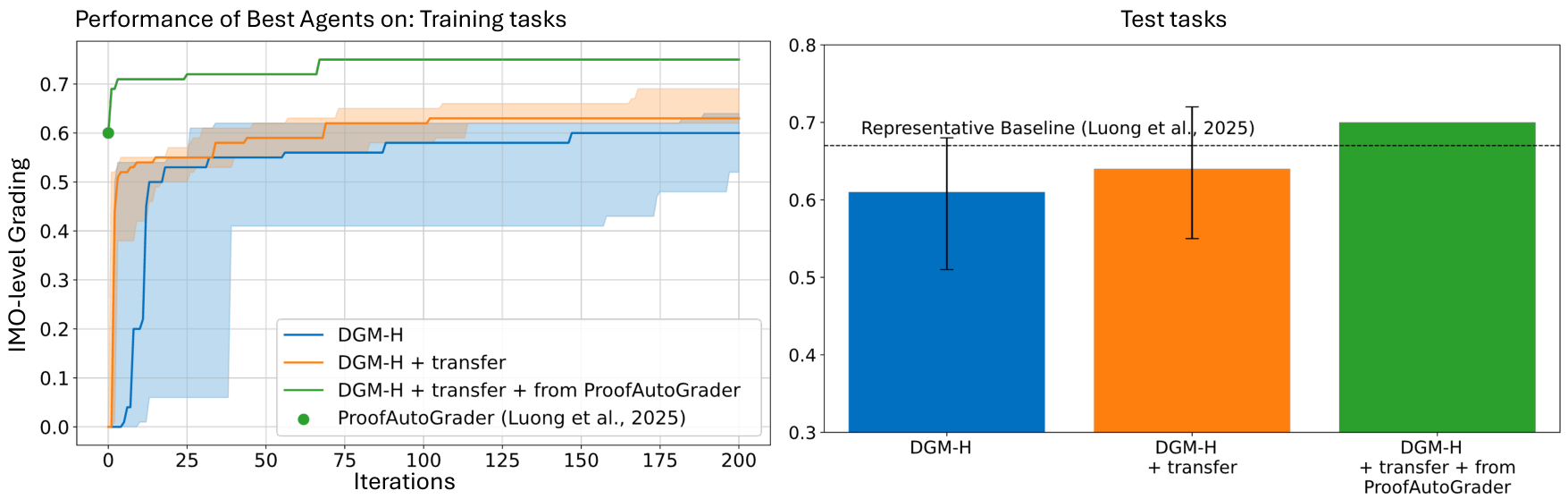
We investigate whether self-improvements learned by DGM-H in one setting continue to accumulate when DGM-H is run in a different setting. From prior DGM-H runs on the paper review and robotics reward design tasks (Section 5.1), we select transfer hyperagents using the same selection mechanism described earlier (Section 5.2, Appendix D.4). We then evaluate their ability to continue self-improving in a new domain, Olympiad-level math grading. After 200 iterations of DGM-H starting from these transfer agents (DGM-H + transfer), the best generated agents (selected based on validation score) achieve a test-set score of 0.640zero point six four zero (CI: 0.550−0.720confidence interval zero point five five zero to zero point seven two zero). Under the same experimental setup, DGM-H starting from the initial agent achieves a best test-set score of 0.610zero point six one zero (CI: 0.510−0.680confidence interval zero point five one zero to zero point six eight zero). Although the difference between DGM-H + transfer and DGM-H is not statistically significant (p>0.05p greater than zero point zero five), DGM-H + transfer achieves a higher median performance and higher confidence intervals than DGM-H starting from the initial agent (Figure 4). Notably, improvements at higher performance levels are increasingly difficult due to saturation effects (e.g., increasing performance from 0.7zero point seven to 0.8zero point eight is typically more challenging than from 0.0zero point zero to 0.1zero point one), making these gains meaningful despite their modest
Figure 4 Self-improvements learned by the DGM-H accumulate across domains and runs. We continue running DGM-H on Olympiad-level math grading, starting from transfer hyperagents obtained in prior DGM-H runs, and compare this against DGM-H initialized from the initial agent and from ProofAutoGrader. (Left) Initializing from transferred hyperagents leads to faster progress and higher final performance than initializing from the initial agent, indicating that previously learned self-improvements remain useful and continue to compound in a new domain. (Right) DGM-H initialized from a transferred agent and ProofAutoGrader achieves the highest test performance, surpassing the representative baseline.
absolute magnitude. These results suggest that DGM-H’s self-improvements are reusable and can potentially accumulate across runs, supporting the possibility of compounding self-improvement over time.
The representative static baseline for Olympiad-level math grading from IMO-GradingBench is ProofAutoGrader (Luong et al., 2025)by Luong and colleagues, 2025. We initialize the DGM-H with ProofAutoGrader as the task agent and a transfer meta agent obtained from a prior DGM-H run (on paper review and robotics reward design), and then continue optimizing for Olympiad-level math grading. After 200 iterations, the best discovered agent achieves a test-set score of 0.700, outperforming ProofAutoGrader’s score of 0.670 (Figure 4). We then evaluate both the best discovered agent and ProofAutoGrader on the full IMO-GradingBench to obtain a more accurate estimate of the improvement. On the full IMO-GradingBench, the DGM-H improves ProofAutoGrader’s accuracy from 0.561 to 0.601, and lowers the mean absolute error from 0.178 to 0.175 (Appendix E.4). We open-source this artifact to support future research and development (Appendix E.1.3). These results show that the DGM-H can build on strong existing solutions and further improve their performance.
6 Safety Discussion
The DGM-Hyperagents (DGM-H) introduces distinct safety considerations due to its ability to autonomously modify its own behavior and improvement mechanisms over time. In this work, all experiments are conducted under strict safety constraints. In particular, agent-generated code is executed within carefully sandboxed environments with enforced resource limits (e.g., timeouts, restricted internet access). These measures are designed to prevent unintended side effects, contain failures, and ensure that self-modifications remain confined to the intended experimental scope. Moreover, evaluation is performed using predefined tasks and metrics, and human oversight is maintained throughout all experiments.
Potential to evolve faster than human oversight. As AI systems gain the ability to modify themselves in increasingly open-ended ways, they can potentially evolve far more rapidly than humans can audit or interpret. At the cusp of such explosive capability growth, it becomes necessary to reconsider the roles that AI systems play in society (Bengio et al., 2024)as discussed by Bengio and colleagues. Rather than framing safety solely in terms of absolute guarantees or full interpretability, a central challenge lies in balancing the potential of AI as a catalyst for human progress and well-being (e.g., automating scientific discovery) with the degree of trust humans are willing to place in these systems (e.g., delegating decisions or actions without requiring continuous human verification), while minimizing the many potential risks and downsides (Clune, 2019; Ecoffet et al., 2020; Bengio et al., 2024; Weston and Foerster, 2025). This balance is shaped by factors such as transparency and controllability.
While the DGM-H operates within safe research boundaries (e.g., sandboxing, controlled evaluations), these
safeguards may become increasingly strained or infeasible as self-improving systems grow more capable. We discuss additional safety considerations in Appendix F. We proactively include this discussion to encourage broader engagement with what safety means for open-ended self-improving AI systems (Clune, 2019; Ecoffet et al., 2020; Sheth et al., 2025)as discussed by Clune, Ecoffet and colleagues, and Sheth and colleagues. This includes ongoing discussion about appropriate levels of trust, oversight, and transparency, and societal deliberation about which benefits these systems should prioritize when deployed.
7 Limitations and Conclusion
This work introduces hyperagents and incorporates them into the Darwin Gödel Machine (DGM) to form DGM-Hyperagents (DGM-H). DGM-H is a general self-improvement framework that open-endedly evolves an archive of self-improving hyperagents for any computable task, enabling the system to improve both task performance and its own self-improvement mechanism. Across diverse domains, the DGM-H produced substantial and generalizable gains in task performance while also improving its ability to generate improvements, with these meta-level gains transferring across domains and compounding across runs.
Our results suggest that self-improvements can compound across different experimental settings, but this version of DGM-H has limitations that constrain truly unbounded progress. First, it operates with a fixed task distribution. One direction is to co-evolve the task distribution by generating new tasks and curricula that adapt to the agent’s capabilities (Clune, 2019; Zhang et al., 2024; Faldor et al., 2025; Bolton et al., 2025)as explored in several recent studies. Second, components of the open-ended exploration loop (e.g., parent selection, evaluation protocols) remain fixed. Although hyperagents can modify their self-improvement mechanisms, they cannot alter the outer process that determines which agents are selected or how they are evaluated. Keeping these components fixed improves experimental stability and safety, but limits full self-modifiability. Enabling hyperagents to modify these outer-loop components and adapt their own search strategy and evaluation process is another promising direction for future work. Our preliminary results suggest such extensions are feasible (Appendix E.5).
DGM-H demonstrate that open-ended self-improvement can be made practical across diverse domains. Provided sufficient safety considerations are worked out, the DGM-H suggest a path toward self-accelerating systems that not only search for better solutions, but continually improve their ability to self-improve.
Acknowledgments
We thank Andrew Budker and Ricardo Silveira Cabral for supporting this work, and Alisia Lupidi, Chenxi Whitehouse, John Quan, Lisa Alazraki, Lovish Madaan, Lucia Cipolina-Kun, Mattia Opper, Michael Dennis, Parth Pathak, Rishi Hazra, Roberta Raileanu, Sandra Lefdal, Shashwat Goel, Shengran Hu, Timon Willi, Tim Rocktäschel, and Yoram Bachrach for insightful discussions and feedback.
Author Contributions
Jenny Zhang led the conceptualization of the study, conducted the experiments, and wrote the manuscript. Bingchen Zhao and Wannan Yang contributed to experimental design and execution. Jakob Foerster, Jeff Clune, Minqi Jiang, Sam Devlin, and Tatiana Shavrina provided feedback on the methodology and manuscript. All authors reviewed and approved the final manuscript.
References
[references omitted]
[references omitted]
Yoshua Bengio, Geoffrey Hinton, Andrew Yao, Dawn Song, Pieter Abbeel, Trevor Darrell, Yuval Noah Harari, Ya-Qin Zhang, Lan Xue, Shai Shalev-Shwartz, et al. Managing extreme AI risks amid rapid progress. Science, 384(6698): 842–845, 2024.
Adrian Bolton, Alexander Lerchner, Alexandra Cordell, Alexandre Moufarek, Andrew Bolt, Andrew Lampinen, Anna Mitenkova, Arne Olav Hallingstad, Bojan Vujatovic, Bonnie Li, et al. Sima 2: A generalist embodied agent for virtual worlds. arXiv preprint arXiv:2512.04797, 2025.
Herbie Bradley, Andrew Dai, Hannah Teufel, Jenny Zhang, Koen Oostermeijer, Marco Bellagente, Jeff Clune, Kenneth Stanley, Grégory Schott, and Joel Lehman. Quality-diversity through AI feedback. arXiv preprint arXiv:2310.13032, 2023.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
Mathieu Chalvidal, Thomas Serre, and Rufin VanRullen. Meta-reinforcement learning with self-modifying networks. Advances in Neural Information Processing Systems, 35:7838–7851, 2022.
Yinzhu Chen, Abdine Maiga, Hossein A Rahmani, and Emine Yilmaz. Automated Rubrics for Reliable Evaluation of Medical Dialogue Systems. arXiv preprint arXiv:2601.15161, 2026.
Jeff Clune. AI-GAs: AI-generating algorithms, an alternate paradigm for producing general artificial intelligence. arXiv preprint arXiv:1905.10985, 2019.
Lisa Coiffard, Paul Templier, and Antoine Cully. Overcoming Deceptiveness in Fitness Optimization with Unsupervised Quality-Diversity. In Proceedings of the Genetic and Evolutionary Computation Conference, pages 122–130, 2025.
Cédric Colas, Laetitia Teodorescu, Pierre-Yves Oudeyer, Xingdi Yuan, and Marc-Alexandre Côté. Augmenting autotelic agents with large language models. In Conference on Lifelong Learning Agents, pages 205–226. PMLR, 2023.
Jonathan Cook, Tim Rocktäschel, Jakob Foerster, Dennis Aumiller, and Alex Wang. Ticking all the boxes: Generated checklists improve llm evaluation and generation. arXiv preprint arXiv:2410.03608, 2024.
Rémi Coulom. Efficient selectivity and backup operators in Monte-Carlo tree search. In International conference on computers and games, pages 72–83. Springer, 2006.
Paulo Henrique Couto, Quang Phuoc Ho, Nageeta Kumari, Benedictus Kent Rachmat, Thanh Gia Hieu Khuong, Ihsan Ullah, and Lisheng Sun-Hosoya. Relevai-reviewer: A benchmark on AI reviewers for survey paper relevance. arXiv preprint arXiv:2406.10294, 2024.
Antoine Cully, Jeff Clune, Danesh Tarapore, and Jean-Baptiste Mouret. Robots that can adapt like animals. Nature, 521(7553):503–507, 2015.
Aaron Dharna, Cong Lu, and Jeff Clune. Foundation model self-play: Open-ended strategy innovation via foundation models. arXiv preprint arXiv:2507.06466, 2025.
Li Ding, Jenny Zhang, Jeff Clune, Lee Spector, and Joel Lehman. Quality Diversity through Human Feedback: Towards Open-Ended Diversity-Driven Optimization. In Forty-first International Conference on Machine Learning, 2024.
Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O Stanley, and Jeff Clune. Go-explore: a new approach for hard-exploration problems. arXiv preprint arXiv:1901.10995, 2019.
Adrien Ecoffet, Jeff Clune, and Joel Lehman. Open questions in creating safe open-ended AI: Tensions between control and creativity. In Artificial Life Conference Proceedings 32, pages 27–35, 2020.
Maxence Faldor, Jenny Zhang, Antoine Cully, and Jeff Clune. OMNI-EPIC: Open-endedness via Models of human Notions of Interestingness with Environments Programmed in Code. In The Thirteenth International Conference on Learning Representations, 2025.
Zhiyuan Fan, Weinong Wang, Debing Zhang, et al. Sedareval: Automated evaluation using self-adaptive rubrics. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 16916–16930, 2024.
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797, 2023.