Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui and Siddharth Gopal
Google
tsendsuren@google.com
Abstract
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
1 Introduction
Memory serves as a cornerstone of intelligence, as it enables efficient computations tailored to specific contexts. However, Transformers
The attention mechanism in Transformers exhibits quadratic complexity in both memory footprint and computation time. For example, the attention Key-Value (KV) states have 3TB memory footprint for a 500B model with batch size 512 and context length 2048
Compressive memory systems promise to be more scalable and efficient than the attention mechanism for extremely long sequences
In this work, we introduce a novel approach that enables Transformer LLMs to effectively process infinitely long inputs with bounded memory footprint and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention
Such a subtle but critical modification to the Transformer attention layer enables a natural extension of existing LLMs to infinitely long contexts via continual pre-training and fine-tuning.
Our Infini-attention reuses all the key, value and query states of the standard attention computation for long-term memory consolidation and retrieval. We store old KV states of the attention in the compressive memory, instead of discarding them like in the standard attention mechanism. We then retrieve the values from the memory by using the attention query states when processing subsequent sequences. To compute the final contextual output, the Infini-attention aggregates the long-term memory-retrieved values and the local attention contexts.
In our experiments, we show that our approach outperforms baseline models on long-context language modeling benchmarks while having 114x comprehension ratio in terms of memory size. The model achieves even better perplexity when trained with 100K sequence length. A 1B LLM naturally scales to 1M sequence length and solves the passkey retrieval task when injected with Infini-attention. Finally, we show that a 8B model with Infini-attention reaches a new SOTA result on a 500K length book summarization task after continual pre-training and task fine-tuning.
In summary, our work makes the following contributions:
- We introduce a practical and yet powerful attention mechanism – Infini-attention with long-term compressive memory and local causal attention for efficiently modeling both long and short-range contextual dependencies.
- Infini-attention introduces minimal change to the standard scaled dot-product attention and supports plug-and-play continual pre-training and long-context adaptation by design.
- Our approach enables Transformer LLMs to scale to infinitely long context with a bounded memory and compute resource by processing extremely long inputs in a streaming fashion.
2 Background
Recurrent Neural Networks (RNNs) process a single token
The RNN computation is very efficient since the model maintains only a fixed-size vector
MNM learns an additional memory state
entries, it forward-passes the query vectors through the memory FFN and retrieves its corresponding value. Like RNNs, the memory state is still bounded in MNM.
Unlike the RNNs, the attention mechanism however doesn’t maintain a recurrent state and only performs a feed-forward computation on input sequence segment
The attention output
3 Method
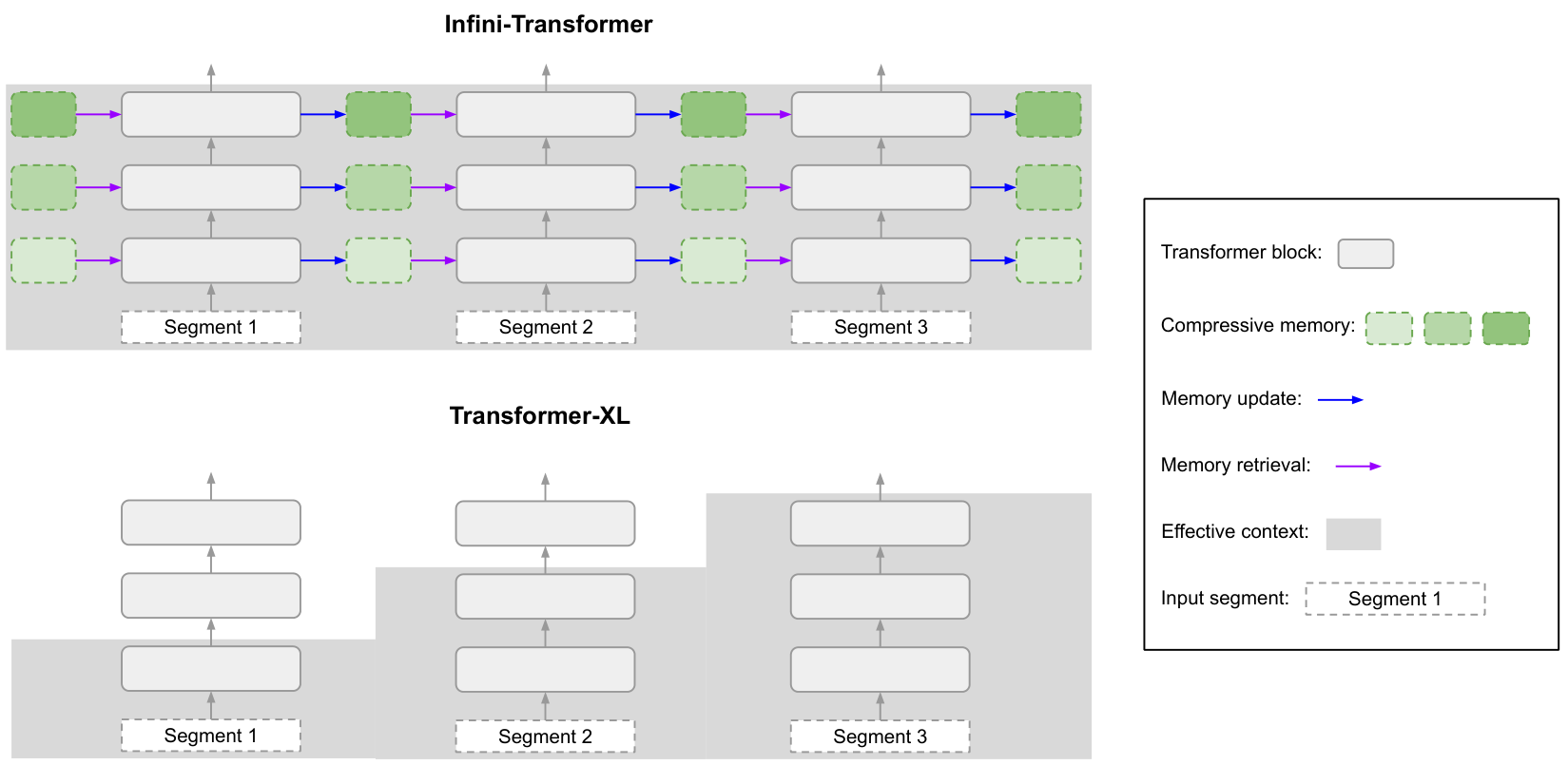
Figure 2 compares our model, Infini-Transformer, and Transformer-XL
The local attention
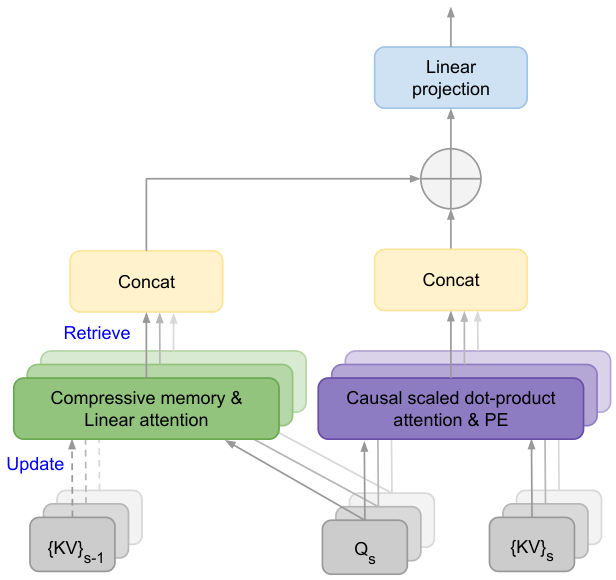
3.1 Infini-attention
As shown Figure 1, our Infini-attention is a recurrent attention mechanism that computes both local and global context states and combine them for its output. Similar to multi-head
attention
3.1.1 Scaled Dot-product Attention
The multi-head scaled dot-product attention
A single head in the vanilla MHA computes its attention context
Here, and
For MHA, we compute
3.1.2 Compressive Memory
In Infini-attention, instead of computing new memory entries for compressive memory, we reuse the query, key and value states (
While there are different forms of compressive memory proposed in the literature
Memory retrieval. In Infini-attention, we retrieve new content
Here,
| Model | Memory (cache) footprint | Context length | Memory update | Memory retrieval |
|---|---|---|---|---|
| Transformer-XL | Discarded | Dot-product attention | ||
| Compressive Transformer | Discarded | Dot-product attention | ||
| Memorizing Transformers | None | kNN + dot-product attention | ||
| RMT | Discarded | Soft-prompt input | ||
| AutoCompressors | Discarded | Soft-prompt input | ||
| Infini-Transformers | Incremental | Linear attention |
Table 1: Transformer models with segment-level memory are compared. For each model, the memory size and effective context length are defined in terms of their model parameters (
Memory update. Once the retrieval is done, we update the memory and the normalization term with the new KV entries and obtain the next states as
The new memory states
Inspired by the success of delta rule
This update rule (Linear + Delta) leaves the associative matrix unmodified if the KV binding already exists in the memory while still tracking the same normalization term as the former one (Linear) for numerical stability.
Long-term context injection. We aggregate the local attention state
This adds only a single scalar value as training parameter per head while allowing a learnable trade-off between the long-term and local information flows in the model
Similar to the standard MHA, for the multi-head Infini-attention we compute
where
3.2 Memory and Effective Context Window
Our Infini-Transformer enables an unbounded context window with a bounded memory footprint. To illustrate this, Table 1 lists the previous segment-level memory models with their context-memory footprint and effective context length defined in terms of model parameters and input segment length. Infini-Transformer has a constant memory complexity of
Transformer-XL computes attention over KV states cached from the last segment in addition to the current states. Since this is done for each layer, Transformer-XL extends the context window from
RMT and AutoCompressors allow for a potentially infinite context length since they compress the input into summary vectors and then pass them as extra soft-prompt inputs for the subsequent segments. However, in practice the success of those techniques highly depends on the size of soft-prompt vectors. Namely, it is necessary to increase the number of soft-prompt (summary) vectors to achieve a better performance with AutoCompressors
4 Experiments
We evaluated our Infini-Transformer models on benchmarks involving extremely long input sequences: long-context language modeling, 1M length passkey context block retrieval and 500K length book summarization tasks. For the language modeling benchmark, we train our models from scratch while for the passkey and book summarization tasks, we continually pre-train existing LLMs in order to highlight a plug-and-play long-context adaptation capability of our approach.
4.1 Implementation details
Segment chunking. we forward-pass the entire input text a Transformer model and then perform segment chunking at each Infini-attention layer - in this way, perform a minimal modification to the existing Transformer implementation. The Infini-attention layer segments the input and process it segment by segment and concatenates back the segments to pass the original-length segment as output to the next layer.
Back-propagation through time (BPTT). Each Infini-attention layer is trained with back-propagation through time
| Model | Memory size (comp.) | XL cache | Segment length | PG19 | Arxiv-math |
|---|---|---|---|---|---|
| Transformer-XL | 50M (3.7x) | 2048 | 2048 | 11.88 | 2.42 |
| Memorizing Transformers | 183M (1x) | 2048 | 2048 | 11.37 | 2.26 |
| RMT | 2.5M (73x) | None | 2048 | 13.27 | 2.55 |
| Infini-Transformer (Linear) | 1.6M (114x) | None | 2048 | 9.65 | 2.24 |
| Infini-Transformer (Linear + Delta) | 1.6M (114x) | None | 2048 | 9.67 | 2.23 |
Table 2: Long-context language modeling results are compared in terms of average token-level perplexity. Comp. denotes compression ratio. Infini-Transformer outperforms memorizing transformers with memory length of 65K and achieves 114x compression ratio.
Position Embeddings (PE). As shown Figure 1, we don’t use position embeddings for the key and query vectors of the compressive memory to store only global contextual information in the long-term memory. The PEs were applied to the QK vectors only after the compressive memory reading and update.
4.2 Long-context Language Modeling
We trained and evaluated small Infini-Transformer models on PG19
We set the Infini-attention segment length
The main results from the language modeling experiments are summarized in Table 2. Our Infini-Transformer outperforms both Transformer-XL
100K length training. We further increased the training sequence length to 100K from 32K and trained the models on Arxiv-math dataset. 100K training further decreased the perplexity score to 2.21 and 2.20 for Linear and Linear + Delta models.
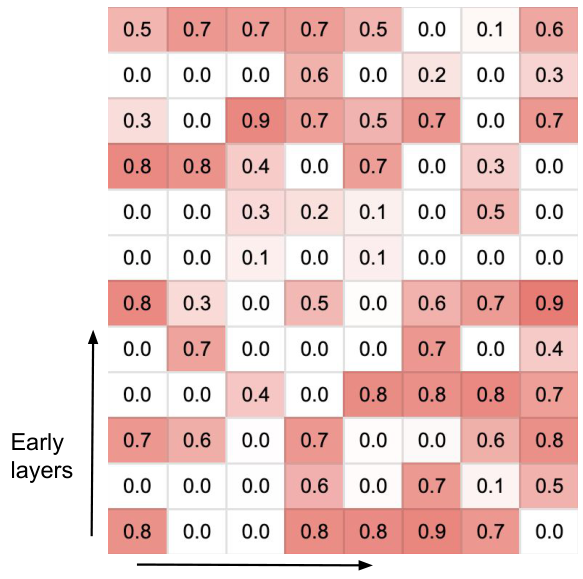
Gating score visualization. Figure 3 visualizes the gating score,
| Zero-shot | |||||
|---|---|---|---|---|---|
| 32K | 128K | 256K | 512K | 1M | |
| Infini-Transformer (Linear) | 14/13/98 | 11/14/100 | 6/3/100 | 6/7/99 | 8/6/98 |
| Infini-Transformer (Linear + Delta) | 13/11/99 | 6/9/99 | 7/5/99 | 6/8/97 | 7/6/97 |
| FT (400 steps) | |||||
| Infini-Transformer (Linear) | 100/100/100 | 100/100/100 | 100/100/100 | 97/99/100 | 96/94/100 |
| Infini-Transformer (Linear + Delta) | 100/100/100 | 100/100/99 | 100/100/99 | 100/100/100 | 100/100/100 |
Table 3: Infini-Transformers solved the passkey task with up to 1M context length when fine-tuned on 5K length inputs. We report token-level retrieval accuracy for passkeys hidden in a different part (start/middle/end) of long inputs with lengths 32K to 1M.
| Model | Rouge-1 | Rouge-2 | Rouge-L | Overall |
|---|---|---|---|---|
| BART | 36.4 | 7.6 | 15.3 | 16.2 |
| BART + Unlimiformer | 36.8 | 8.3 | 15.7 | 16.9 |
| PRIMERA | 38.6 | 7.2 | 15.6 | 16.3 |
| PRIMERA + Unlimiformer | 37.9 | 8.2 | 16.3 | 17.2 |
| Infini-Transformers (Linear) | 37.9 | 8.7 | 17.6 | 18.0 |
| Infini-Transformers (Linear + Delta) | 40.0 | 8.8 | 17.9 | 18.5 |
Table 4: 500K length book summarization (BookSum) results. The BART, PRIMERA and Unlimiformer results are from
observed an interleaving of long and short-term content retrievals throughout the forward computation.
4.3 LLM Continual Pre-training
We performed a lightweight continual pre-training for long-context adaptation of existing LLMs. The pre-training data includes the PG19 and Arxiv-math corpus as well as C4 text
1M passkey retrieval benchmark. We replaced the vanilla MHA in a 1B LLM with Infini-attention and continued to pre-train on inputs with length of 4K. The model was trained for 30K steps with batch size of 64 before fine-tuning on the passkey retrieval task
The passkey task hides a random number into a long text and asks it back at the model output. The length of the distraction text is varied by repeating a text chunk multiple times. The previous work
Table 3 reports the token-level accuracy for test subsets with input lengths ranging from 32K to 1M. For each test subset, we controlled the position of the passkey so that it is either located around the beginning, middle or the end of the input sequence. We reported both zero-shot accuracy and fine-tuning accuracy. Infini-Transformers solved the task with up to 1M context length after fine-tuning on 5K length inputs for 400 steps.
500K length book summarization (BookSum). We further scaled our approach by continuously pre-training a 8B LLM model with 8K input length for 30K steps. We then fine-tuned on a book summarization task, BookSum
We set the input length to 32K for fine-tuning and increase to 500K for evaluating. We use a generation temperature of 0.5 and
Table 4 compares our model against the encoder-decoder models that were built particularly for the summarization task
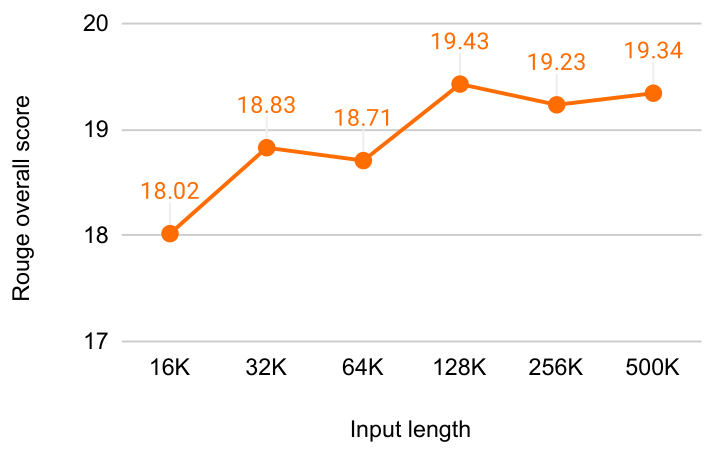
results and achieves a new SOTA on BookSum by processing the entire text from book. We have also plotted the overall Rouge score on validation split of BookSum data in Figure 4. There is a clear trend showing that with more text provided as input from books, Our Infini-Transformers improves its summarization performance metric.
5 Related Work
Compressive memory. Inspired by the plasticity in biological neurons
Compressed input representations can be viewed as a summary of past sequence segments
Long-context continual pre-training. There is a line of work that extends the dot-product attention layers and continues to train LLMs for long-context
The attention mechanism is also prone to the issues of attention sink
Efficient attention. The efficient attention techniques attempt to improve the efficiency of the dot-product attention with an approximation or a system-level optimization. Multiple directions have been explored for different forms of efficient attention approximation, including sparsity-based
6 Conclusion
An effective memory system is crucial not just for comprehending long contexts with LLMs, but also for reasoning, planning, continual adaptation for fresh knowledge, and even for learning how to learn. This work introduces a close integration of compressive memory module into the vanilla dot-product attention layer. This subtle but critical modification to the attention layer enables LLMs to process infinitely long contexts with bounded memory and computation resources. We show that our approach can naturally scale to a million length regime of input sequences, while outperforming the baselines on long-context language modeling benchmark and book summarization tasks. We also demonstrate a promising length generalization capability of our approach. 1B model that was fine-tuned on up to 5K sequence length passkey instances solved the 1M length problem.
Acknowledgments
We would like to thank Dongseong Hwang for their help implementing efficient sequence unrolling mechanism with the jax scan function. We would also like to thank Aditya Gupta, Kalpesh Krishna, Tu Vu and Alexandra Chronopoulou for their feedback.
References
Jimmy Ba, Geoffrey E Hinton, Volodymyr Mnih, Joel Z Leibo, and Catalin Ionescu. Using fast weights to attend to the recent past. Advances in neural information processing systems, 29, 2016.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv, 2014.
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv, 2020.
Amanda Bertsch, Uri Alon, Graham Neubig, and Matthew Gormley. Unlimiformer: Long-range transformers with unlimited length input. Advances in Neural Information Processing Systems, 36, 2024.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
Aydar Bulatov, Yury Kuratov, and Mikhail Burtsev. Recurrent memory transformer. Advances in Neural Information Processing Systems, 35:11079–11091, 2022.
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation. arXiv, 2023a.
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. Longlora: Efficient fine-tuning of long-context large language models. arXiv, 2023b.
Jianpeng Cheng, Li Dong, and Mirella Lapata. Long short-term memory-networks for machine reading. arXiv, 2016.
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. Adapting language models to compress contexts. arXiv, 2023.
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv, 2019.
Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). arXiv, 2015.
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv, 2019.
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, and Furu Wei. Longnet: Scaling transformers to 1,000,000,000 tokens. arXiv, 2023.
Yao Fu, Rameswar Panda, Xinyao Niu, Xiang Yue, Hannaneh Hajishirzi, Yoon Kim, and Hao Peng. Data engineering for scaling language models to 128k context. arXiv, 2024.
Tao Ge, Jing Hu, Xun Wang, Si-Qing Chen, and Furu Wei. In-context autoencoder for context compression in a large language model. arXiv, 2023.
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. arXiv, 2014.
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. Olmo: Accelerating the science of language models. arXiv, 2024.
Donald Olding Hebb. The organization of behavior: A neuropsychological theory. Psychology press, 2005.
Geoffrey E Hinton and David C Plaut. Using fast weights to deblur old memories. In Proceedings of the ninth annual conference of the Cognitive Science Society, pp. 177–186, 1987.
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9 (8):1735–1780, 1997.
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences, 79(8):2554–2558, 1982.
Dongseong Hwang, Weiran Wang, Zhuoyuan Huo, Khe Chai Sim, and Pedro Moreno Mengibar. Transformerfam: Feedback attention is working memory. arXiv, 2024.
Łukasz Kaiser and Ilya Sutskever. Neural gpus learn algorithms. arXiv, 2015.
Pentti Kanerva. Sparse distributed memory. MIT press, 1988.
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pp. 5156–5165. PMLR, 2020.
Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, and Siva Reddy. The impact of positional encoding on length generalization in transformers. Advances in Neural Information Processing Systems, 36, 2024.
Wojciech Kryściński, Nazneen Rajani, Divyansh Agarwal, Caiming Xiong, and Dragomir Radev. Booksum: A collection of datasets for long-form narrative summarization. arXiv, 2021.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near-infinite context. arXiv preprint arXiv:2310.01889, 2023.
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157–173, 2024.
Wolfgang Maass, Thomas Natschläger, and Henry Markram. Real-time computing without stable states: A new framework for neural computation based on perturbations. Neural computation, 14(11):2531–2560, 2002.
Thomas Miconi, Kenneth Stanley, and Jeff Clune. Differentiable plasticity: training plastic neural networks with backpropagation. In International Conference on Machine Learning, pp. 3559–3568. PMLR, 2018.
Amirkeivan Mohtashami and Martin Jaggi. Random-access infinite context length for transformers. Advances in Neural Information Processing Systems, 36, 2024.
Jesse Mu, Xiang Li, and Noah Goodman. Learning to compress prompts with gist tokens. Advances in Neural Information Processing Systems, 36, 2024.
Tsendsuren Munkhdalai and Hong Yu. Meta networks. In International conference on machine learning, pp. 2554–2563. PMLR, 2017a.
Tsendsuren Munkhdalai and Hong Yu. Neural semantic encoders. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 1, pp. 397. NIH Public Access, 2017b.
Tsendsuren Munkhdalai, John P Lalor, and Hong Yu. Citation analysis with neural attention models. In Proceedings of the Seventh International Workshop on Health Text Mining and Information Analysis, pp. 69–77, 2016.
Tsendsuren Munkhdalai, Alessandro Sordoni, Tong Wang, and Adam Trischler. Metalearned neural memory. Advances in Neural Information Processing Systems, 32, 2019.
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models. arXiv preprint arXiv:2309.00071, 2023.
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. Proceedings of Machine Learning and Systems, 5, 2023.
Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409, 2021.
Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive transformers for long-range sequence modelling. arXiv preprint arXiv:1911.05507, 2019.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
Nir Ratner, Yoav Levine, Yonatan Belinkov, Ori Ram, Omri Abend, Ehud Karpas, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. Parallel context windows improve in-context learning of large language models. arXiv preprint arXiv:2212.10947, 2022.
Imanol Schlag, Paul Smolensky, Roland Fernandez, Nebojsa Jojic, Jürgen Schmidhuber, and Jianfeng Gao. Enhancing the transformer with explicit relational encoding for math problem solving. arXiv preprint arXiv:1910.06611, 2019.
Imanol Schlag, Tsendsuren Munkhdalai, and Jürgen Schmidhuber. Learning associative inference using fast weight memory. arXiv, 2020.
Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. Linear transformers are secretly fast weight programmers. In International Conference on Machine Learning, pp. 9355–9366. PMLR, 2021.
Jürgen Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks. Neural Computation, 4(1):131–139, 1992.
Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. In International Conference on Machine Learning, pp. 4596–4604. PMLR, 2018.
Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi, and Hongsheng Li. Efficient attention: Attention with linear complexities. arXiv, 2018.
Paul Smolensky. Tensor product variable binding and the representation of symbolic structures in connectionist systems. Artificial intelligence, 46(1-2):159–216, 1990.
Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. End-to-end memory networks. Advances in neural information processing systems, 28, 2015.
Sainbayar Sukhbaatar, Da Ju, Spencer Poff, Stephen Roller, Arthur Szlam, Jason Weston, and Angela Fan. Not all memories are created equal: Learning to forget by expiring. In International Conference on Machine Learning, pp. 9902–9912. PMLR, 2021.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv, 2023.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
Paul J Werbos. Generalization of backpropagation with application to a recurrent gas market model. Neural networks, 1(4):339–356, 1988.
Yuhuai Wu, Markus N Rabe, DeLesley Hutchins, and Christian Szegedy. Memorizing transformers. arXiv, 2022.
Chaojun Xiao, Pengle Zhang, Xu Han, Guangxuan Xiao, Yankai Lin, Zhengyan Zhang, Zhiyuan Liu, Song Han, and Maosong Sun. Infllm: Unveiling the intrinsic capacity of llms for understanding extremely long sequences with training-free memory. arXiv, 2024.
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. arXiv, 2023.
Wen Xiao, Iz Beltagy, Giuseppe Carenini, and Arman Cohan. Primera: Pyramid-based masked sentence pre-training for multi-document summarization. arXiv, 2021.
Wenhan Xiong, Jingyu Liu, Igor Molybog, Hejia Zhang, Prajjwal Bhargava, Rui Hou, Louis Martin, Rashi Rungta, Karthik Abinav Sankararaman, Barlas Oguz, et al. Effective long-context scaling of foundation models. arXiv, 2023.
A Additional Training Details
For the long-context language modeling task, we set the learning rate to
B Passkey Retrieval Task
Below we showed the input format of the passkey task.
There is an important info hidden inside a lot of irrelevant text. Find it and memorize them. I will quiz you about the important information there. The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. (repeat x times)