RECURRENT ACTION TRANSFORMER WITH MEMORY
Egor Cherepanov, Aleksei Staroverov, Alexey K. Kovalev, Aleksandr I. Panov
AXXX, MIRIAI
ABSTRACT
Transformers have become increasingly popular in offline reinforcement learning (RL) due to their ability to treat agent trajectories as sequences, reframing policy learning as a sequence modeling task. However, in partially observable environments (POMDPs), effective decision-making depends on retaining information about past events – something that standard transformers struggle with due to the quadratic complexity of self-attention, which limits their context length. One solution to this problem is to extend transformers with memory mechanisms. We propose the Recurrent Action Transformer with Memory (RATE), a novel transformer-based architecture for offline RL that incorporates a recurrent memory mechanism designed to regulate information retention. We evaluate RATE across a diverse set of environments: memory-intensive tasks (ViZDoom-Two-Colors, T-Maze, Memory Maze, Minigrid-Memory, and POP-Gym), as well as standard Atari and MuJoCo benchmarks. Our comprehensive experiments demonstrate that RATE significantly improves performance in memory-dependent settings while remaining competitive on standard tasks across a broad range of baselines. These findings underscore the pivotal role of integrated memory mechanisms in offline RL and establish RATE as a unified, high-capacity architecture for effective decision-making over extended horizons. Code: https://sites.google.com/view/rate-model/.
1 INTRODUCTION
Originally developed for Natural Language Processing (NLP), transformers
In RL, memory usually refers either to using past information within an episode
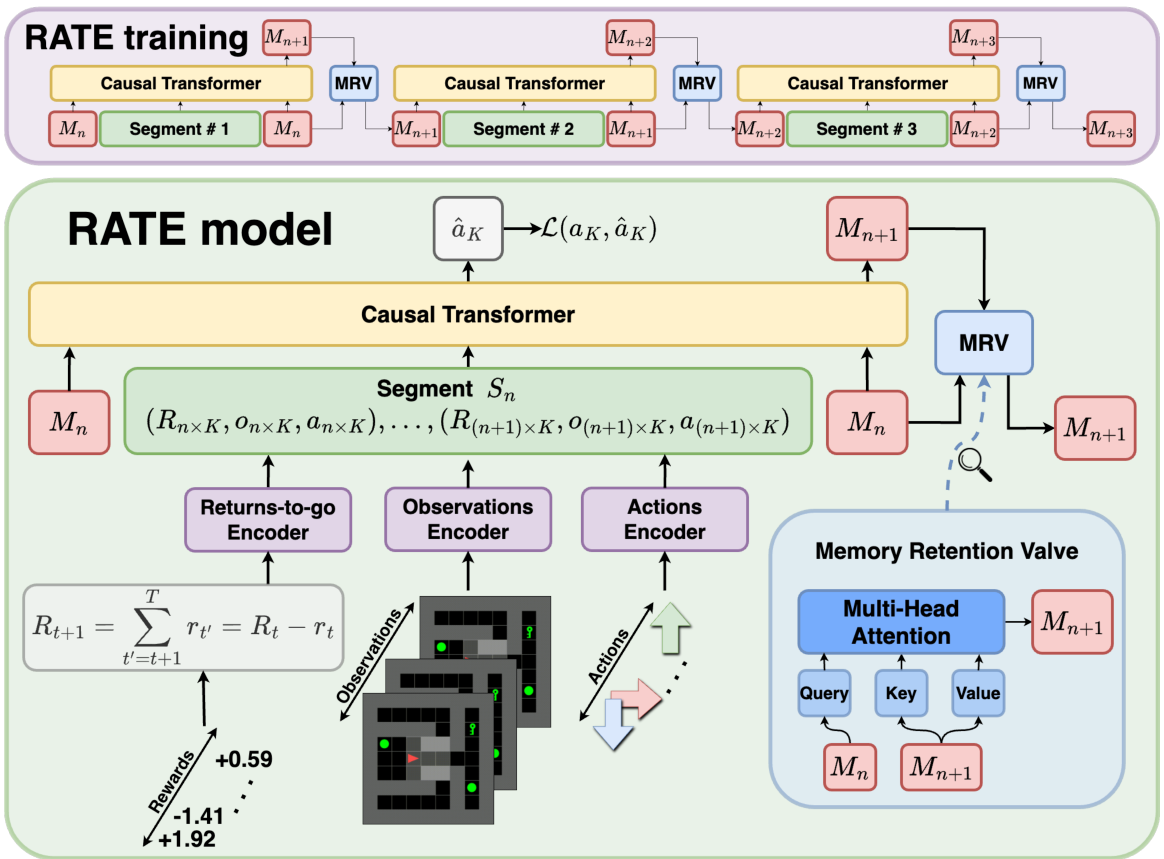
We introduce the Recurrent Action Transformer with Memory (RATE; see Figure 1), a memory-augmented transformer that incorporates three complementary mechanisms: learned memory embeddings, recurrent caching of past hidden states, and a novel Memory Retention Valve (MRV) for selective information flow. We empirically show that memory mechanisms effectively preserve information from previous steps, allowing the model to use past information when making decisions in the present. MRV is designed to control the process of updating memory embeddings and prevent the loss of important information when processing long sequences, thus enabling the processing of highly sparse tasks. To assess the effectiveness of our memory mechanisms, we conduct extensive experiments across a diverse set of memory-intensive environments, including ViZDoom-Two-Colors
Our main contributions are as follows:
- We propose Recurrent Action Transformer with Memory (RATE), a new transformer for offline RL that combines three complementary memory mechanisms: (i) memory embeddings, (ii) caching of hidden states, and (iii) a Memory Retention Valve (MRV), which uses cross-attention to retain key information over long horizons (Section 3).
- We conduct extensive evaluations on memory-intensive tasks — including ViZDoom Two-Colors, Memory Maze, Minigrid-Memory, POPGym, and Passive T-Maze — showing that RATE consistently outperforms strong baselines (Section 4.1).
- We further show that RATE matches or surpasses standard baselines on the Atari and MuJoCo benchmarks, demonstrating strong generalization across task types and highlighting the model’s versatility (Section 4.1).
2 BACKGROUND
Offline RL. In RL
the sum of future rewards from
POMDP. In real-world, agents often receive partial observations rather than full states, breaking the Markov property. For instance, a robot using only camera input or an agent relying on past context. Such cases are modeled as Partially Observable MDPs (POMDPs):
3 RECURRENT ACTION TRANSFORMER WITH MEMORY
Transformers excel at sequence modeling, including offline RL
RATE combines memory embeddings
| Algorithm 1 RATE |
|---|
| Require: |
| 1: |
| 2: |
| 3: |
| 4: for in do |
| 5: |
| 6: |
| 7: |
| 8: |
| 9: end for |
| Algorithm 2 Memory Retention Valve |
|---|
| Require: |
| 1: |
| 2: |
| 3: |
| 4: |
| 5: |
| 6: |
| Output: |
Each segment is then processed by the transformer,
and the resulting memory is refined via the MRV before being passed to the next segment.
Naively forwarding memory embeddings leads to error accumulation or overwriting of relevant information. To address this, we introduce the Memory Retention Valve (MRV), a cross-attention module that filters new memory tokens through the lens of the previous ones
This mechanism allows to control what to retain or overwrite when updating to . Unlike static recurrence2, it preserves sparse, long-range information. RATE overcomes DT’s limits by extending context with recurrence, preserving early cues via MRV, and retaining key events in sparse settings. As a result, RATE solves tasks where DT fails, generalizes beyond training, and remains competitive on standard MDPs.
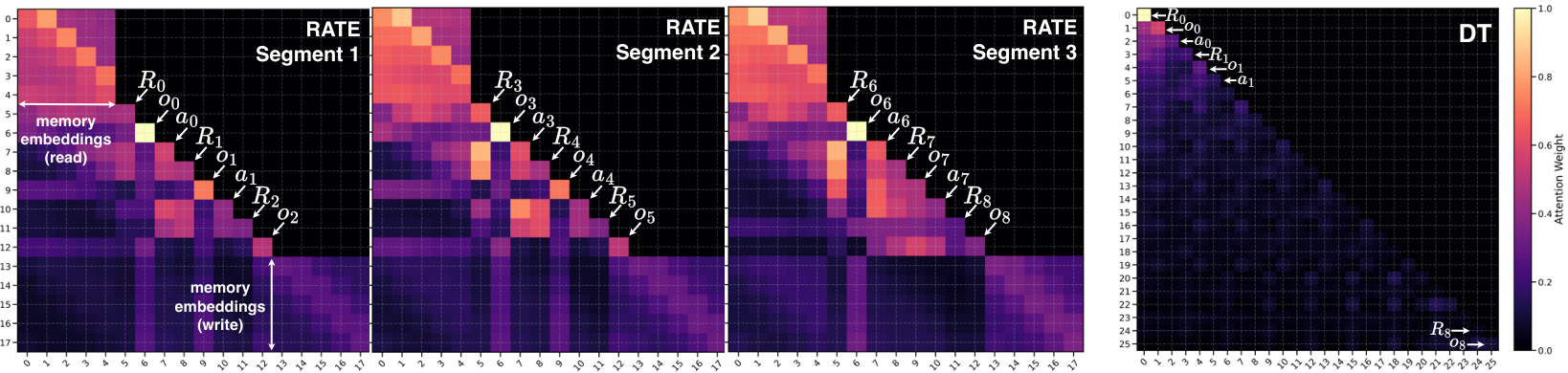
Attention pattern analysis. Figure 2 compares attention maps of RATE and DT on a T-Maze sequence. DT (right) attends only within a fixed window, focusing on recent tokens while losing early cues like
3.1 Preservation Properties of MRV
We formalize the intuition that the cross-attention-based MRV prevents catastrophic overwriting of memory by preserving alignment between consecutive memory states. All vectors are row-vectors. We use for the Frobenius norm and for the norm.
Let and denote the incoming and updated memory embeddings at segment , where is the number of memory tokens and is the model dimension. We assume that each row of is -normalized: . The MRV computes the next memory state as:
.
-alignment condition. The memory embeddings are said to satisfy -alignment3 if there exists a constant such that for every row , there exists a row for which:

Theorem 1 (On memory loss bounds). Let each memory row be -normalized, the -alignment condition hold, and be the MRV attention matrix. Then:
In words: at least a
Proof. Since each row of the attention matrix is a probability distribution, we have for every . By the pigeonhole principle, there exists an index such that .
By assumption, for each there exists a such that . In particular, this holds for : . Using the MRV definition , we write:
Let be the angle between and . Since both vectors are -normalized, we have: . Using the identity for unit vectors:
Summing over all memory tokens and applying the previous bound: , which simplifies to: . Consequently, since due to row normalization, we conclude: .
We now derive the lower bound
, which completes the proof of Equation 4. ■
4 EXPERIMENTAL EVALUATION
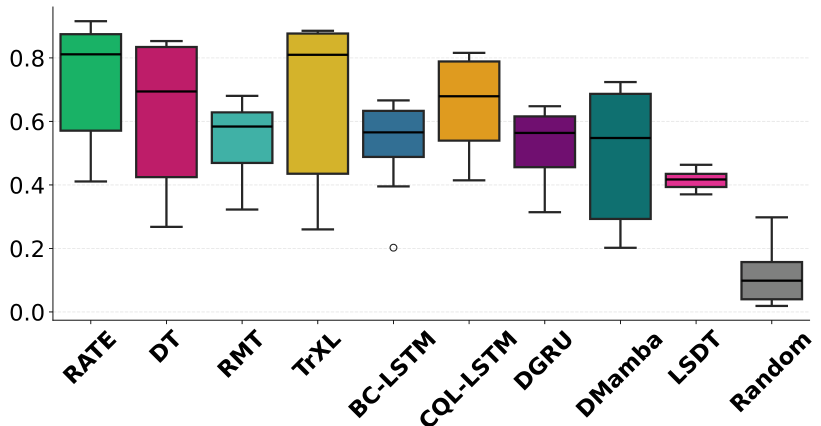
We designed our experiments to achieve two main goals: (a) to showcase the strengths of the RATE model in memory-intensive environments (T-Maze, ViZDoom-Two-Colors, Memory Maze, Minigrid-Memory, POPGym), and (b) to assess its effectiveness in standard MDPs, demonstrating its versatility across domains.
Baselines. To evaluate the performance of RATE, we compare it against a diverse set of baselines spanning several categories: transformer-based models including Decision Transformer (DT)
(BC-MLP) and Conservative Q-Learning
Memory-intensive tasks. We evaluate RATE in tasks that require agents to retain information over time
4.1 EXPERIMENTAL RESULTS
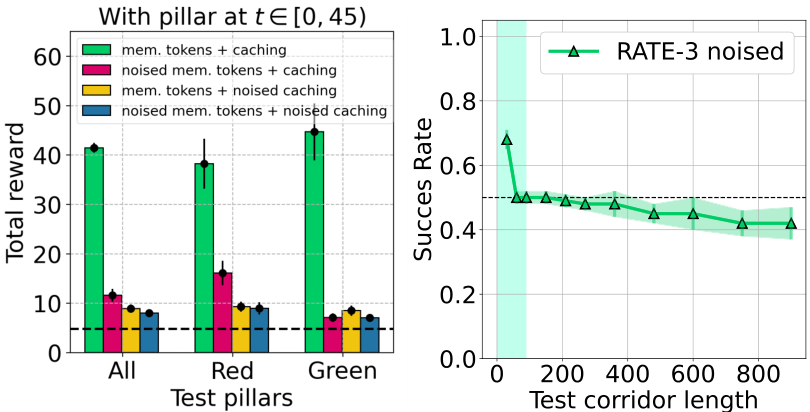
ViZDoom-Two-Colors. Figure 4 shows training with
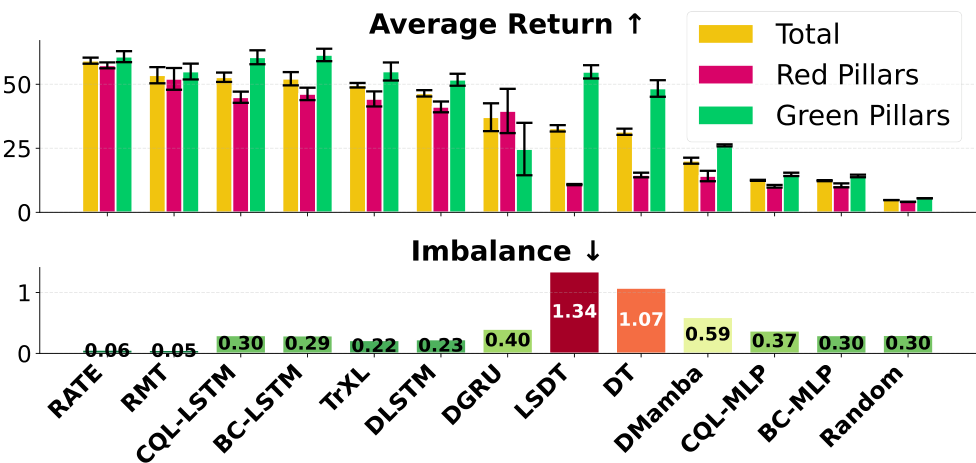
This limitation is clearer in Figure 3 (c, d), which separates performance within and beyond the 90-step context. DT’s return drops by nearly 50% in red-pillar episodes once the cue leaves the window, while memory models (RATE, RMT, TrXL) remain stable, demonstrating their ability to retain and use information over long horizons.
Figure 3 (e, f, g) shows model performance across target reward levels. RATE consistently outperforms all baselines overall (e), and this advantage is even clearer when separating red (f) and green (g) pillar episodes. While other models show large disparities, RATE maintains stable performance across both conditions, demonstrating effective use of initial cues and validating the strength of its memory architecture.
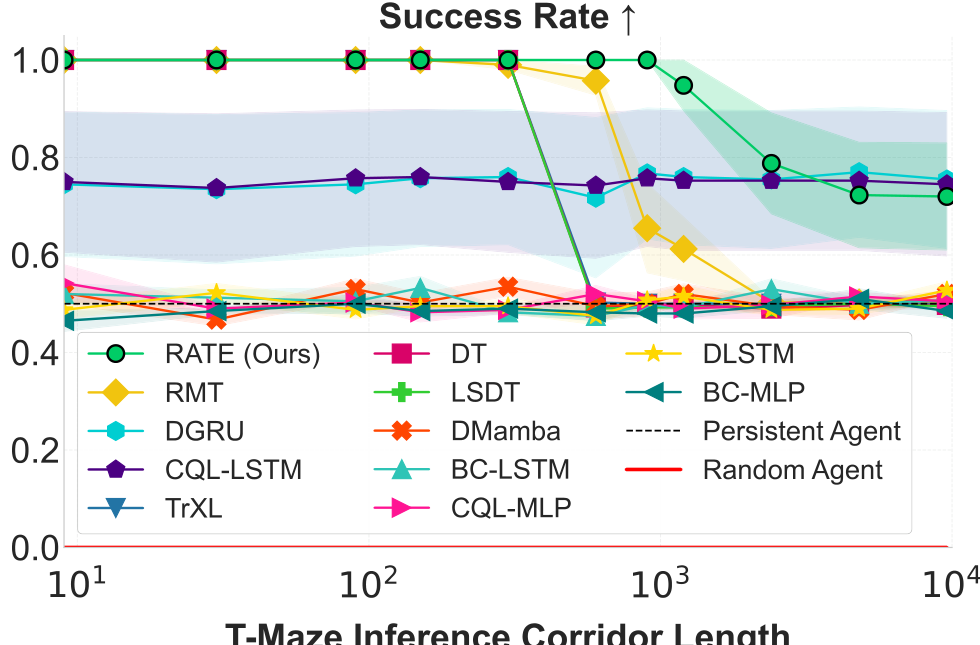
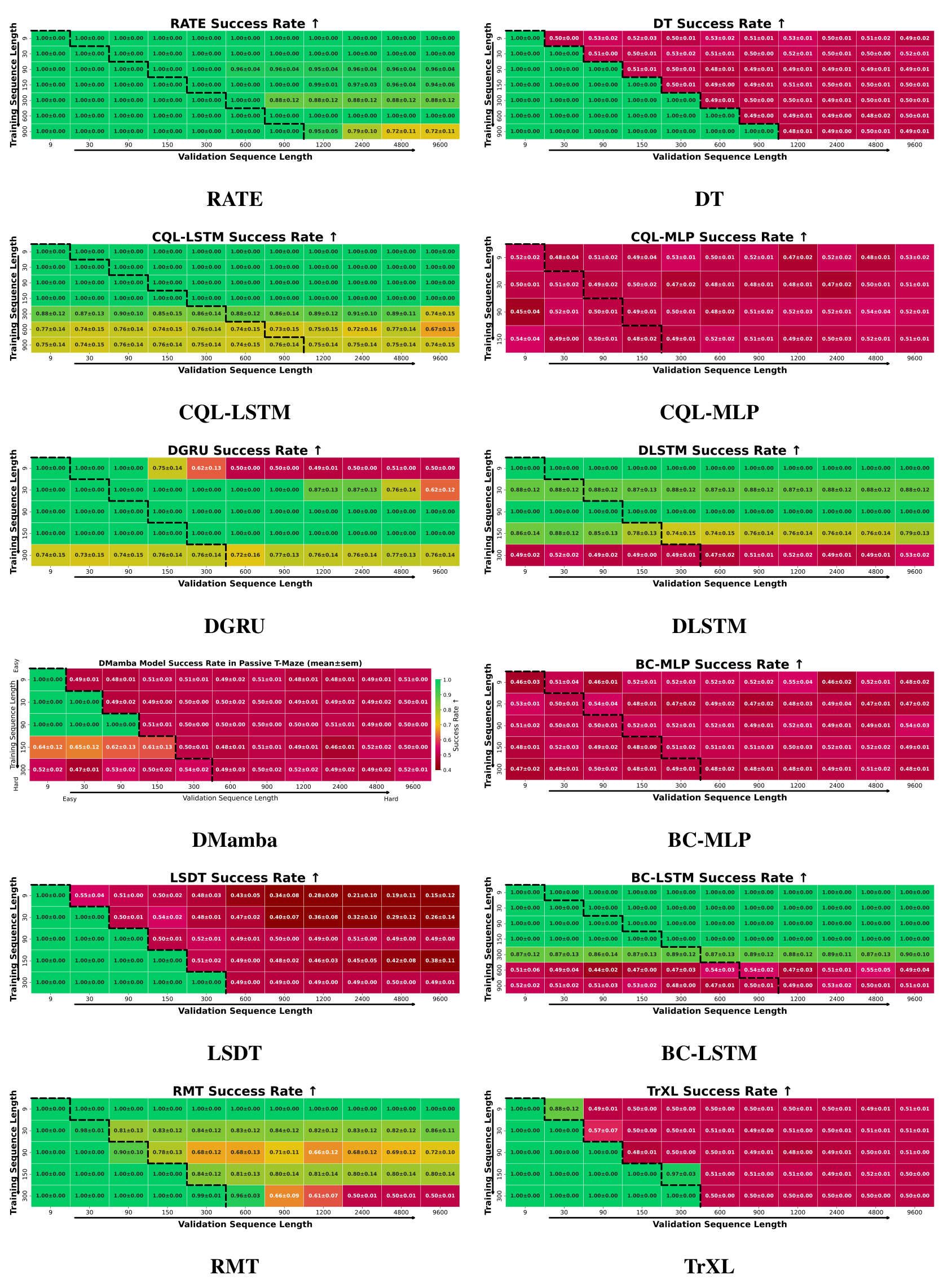
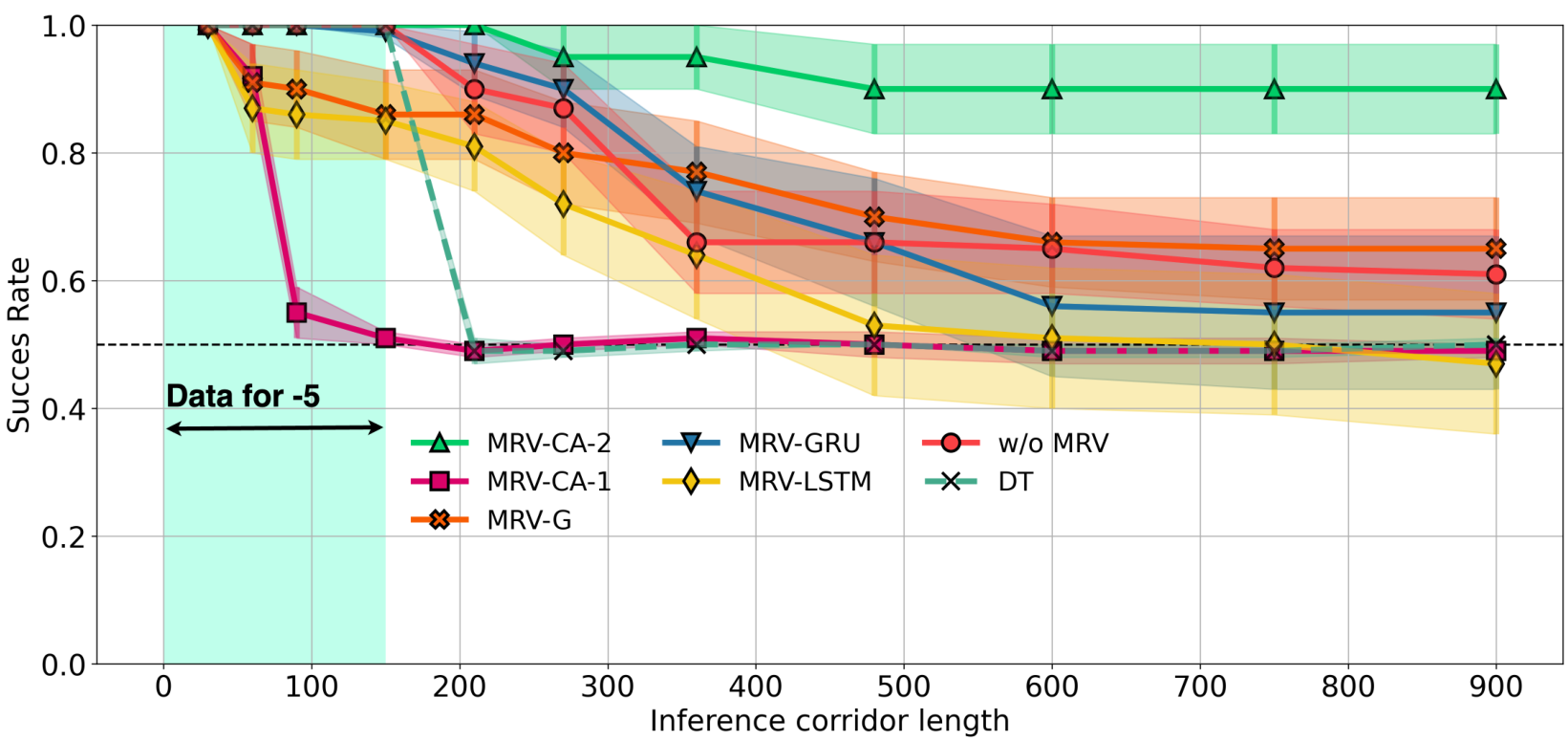
T-Maze. Figure 5 shows the model generalization in Passive T-Maze as inference length grows from 9 to 9600 steps. All models were trained on episodes up to 900 steps; extrapolation beyond this requires long-horizon generalization. RATE achieves 100% success across all in-distribution lengths and performs well even at 9600-step inference, corresponding to trajectories of
over extremely long horizons. Other transformers
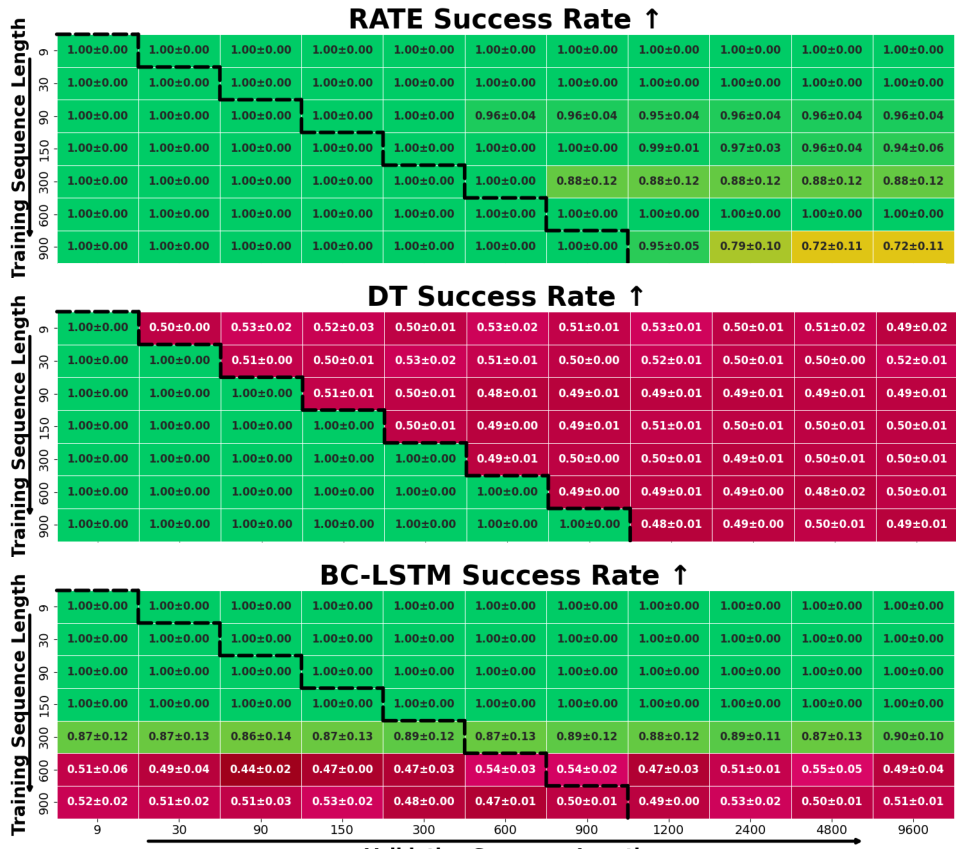
RATE both interpolates within training and extrapolates well beyond, a key strength for solving sparse POMDPs. Notably, poor performance of some memory baselines in Figure 5 is due to difficulty modeling long sequences during training, not just generalization failure: even for
Minigrid-Memory. Figure 7 presents average returns on Minigrid-Memory, where all models were trained on grids of fixed size
Memory Maze. Table 1 presents results on the Memory Maze task. RATE achieves higher average episode returns by effectively capturing implicit structure, such as maze layout. For reference, the dataset’s average return is 4.69. All models were trained on 90-step trajectory subsequences, while full episodes span 1000 steps.
POPGym. To further assess generalization and memory capabilities, we evaluated models on all 46 tasks from the POPGym benchmark suite, which covers a wide range of partially observable RL scenarios. The benchmark is split into 33 memory puzzle tasks and 15 reactive POMDP tasks.
Table 1: Average return SEM in the Memory Maze () environment (ep. length: 1000 steps).
| Method | Random | BC-LSTM | CQL-LSTM | DT | RMT | TrXL | RATE |
|---|---|---|---|---|---|---|---|
| Return | 7.64 |
Table 2: Aggregated average returns on 48 POP-Gym tasks, split into memory and reactive subsets.
| Tasks | Rand. | BC-MLP | DT | BC-LSTM | RATE |
|---|---|---|---|---|---|
| All (48) | -12.2 | -6.8 | 5.8 | 9.0 | 9.5 |
| Memory (33) | -14.6 | -11.9 | -3.5 | -0.2 | 0.5 |
| Reactive (15) | 2.3 | 5.1 | 9.3 | 9.1 | 9.1 |
Table 2 reports average normalized scores across all tasks and subsets. RATE achieves the highest overall score (9.54), outperforming all baselines. On the challenging memory tasks, RATE maintains a positive average score (0.45), while all other models fall below zero — indicating a consistent failure to exploit long-term dependencies. Notably, DT scores
On reactive tasks, all models perform better, but the gap between memory-based and non-memory models narrows. RATE, DT, and BC-LSTM show almost the same results, suggesting that the greatest performance gains from RATE’s memory mechanisms occur on memory puzzle tasks. For simpler reactive POMDPs, lightweight memory mechanisms appear sufficient. These results also underscore RATE’s ability to generalize across both puzzle and reactive settings, confirming that its memory architecture does not hinder performance in simpler tasks while offering clear benefits in those with temporal dependencies. More details are provided in Appendix, Table 9.
Table 3: Normalized scores on MuJoCo tasks from the D4RL benchmark
| Dataset | Environment | CQL | DT | TAP | TT | DMamba | DMamba | MambaDM | RATE (ours) |
|---|---|---|---|---|---|---|---|---|---|
| ME | HalfCheetah | 91.6 | 86.81.3 | 91.80.8 | 91.90.6 | 86.51.2 | 87.40.1 | ||
| ME | Hopper | 105.4 | 105.51.7 | ||||||
| ME | Walker2d | 107.40.9 | |||||||
| M | HalfCheetah | 44.4 | 42.60.1 | 42.80.1 | 43.80.2 | 42.80.1 | 43.50.3 | ||
| M | Hopper | 58.0 | 63.41.4 | 61.13.6 | |||||
| M | Walker2d | 72.5 | 74.01.4 | 64.92.1 | |||||
| MR | HalfCheetah | 36.60.8 | 39.60.1 | 39.10.1 | 39.00.6 | ||||
| MR | Hopper | 87.32.3 | 82.64.6 | 86.12.5 | 83.78.2 | ||||
| MR | Walker2d | 66.63.0 | 66.83.1 | 70.94.3 | |||||
| Average | 74.7 | 74.8 |
Atari and MuJoCo. We evaluate RATE on standard RL benchmarks: Atari games and MuJoCo control tasks (Table 3, Table 4). For comparison, we include results from recent state-of-the-art methods:
5 Ablation Study
We conduct a comprehensive ablation study to assess the contributions of individual components and architectural choices in RATE, structured around three key research questions.
- How do different components of RATE influence performance on memory tasks? (RQ1)
- What is the upper-bound results RATE can achieve with access to perfect memory? (RQ2)
- What role does the MRV play, and which configuration is most effective? (RQ3)
Further ablations exploring key transformer parameters, memory tokens number, and sequence segmentation strategies are provided in Appendix F and Appendix G.
RQ1: Impact of RATE components. To assess the contribution of individual memory mechanisms in RATE, we performed inference-time ablations by replacing memory components with random noise. In T-Maze ( segments)
Table 4: Raw scores on Atari games. RATE outperforms DT in 3 out of 4 environments.
| Environment | CQL | BC | DT | DMamba Ota (2024) | MambaDM | RATE (Ours) |
|---|---|---|---|---|---|---|
| Breakout | 62.5 | 42.8 | ||||
| Qbert | 2862.0 | |||||
| SeaQuest | 782.2 | |||||
| Pong | 6.4 |
to turn correctly – showing it retained navigation skills but lost the initial cue. Thus, memory embeddings act as dedicated storage for task-relevant information, while transformer layers encode general behavior. In ViZDoom-Two-Colors
RQ2: Performance upper-bound estimate. To estimate the upper-bound performance achievable by RATE, we introduce OracleDT – a variant of Decision Transformer augmented with perfect prior knowledge about the environment. Specifically, OracleDT receives an additional input vector
Table 5: Performance comparison between DT, RATE, and OracleDT. OracleDT is an oracle-informed variant used solely to approximate the upper bound and is not a feasible baseline.
| T-Maze | |||
|---|---|---|---|
| Success Rate | OracleDT | DT | RATE |
| ViZDoom-Two-Colors | |||
| Total Reward | |||
| Red Pillars | |||
| Green Pillars |
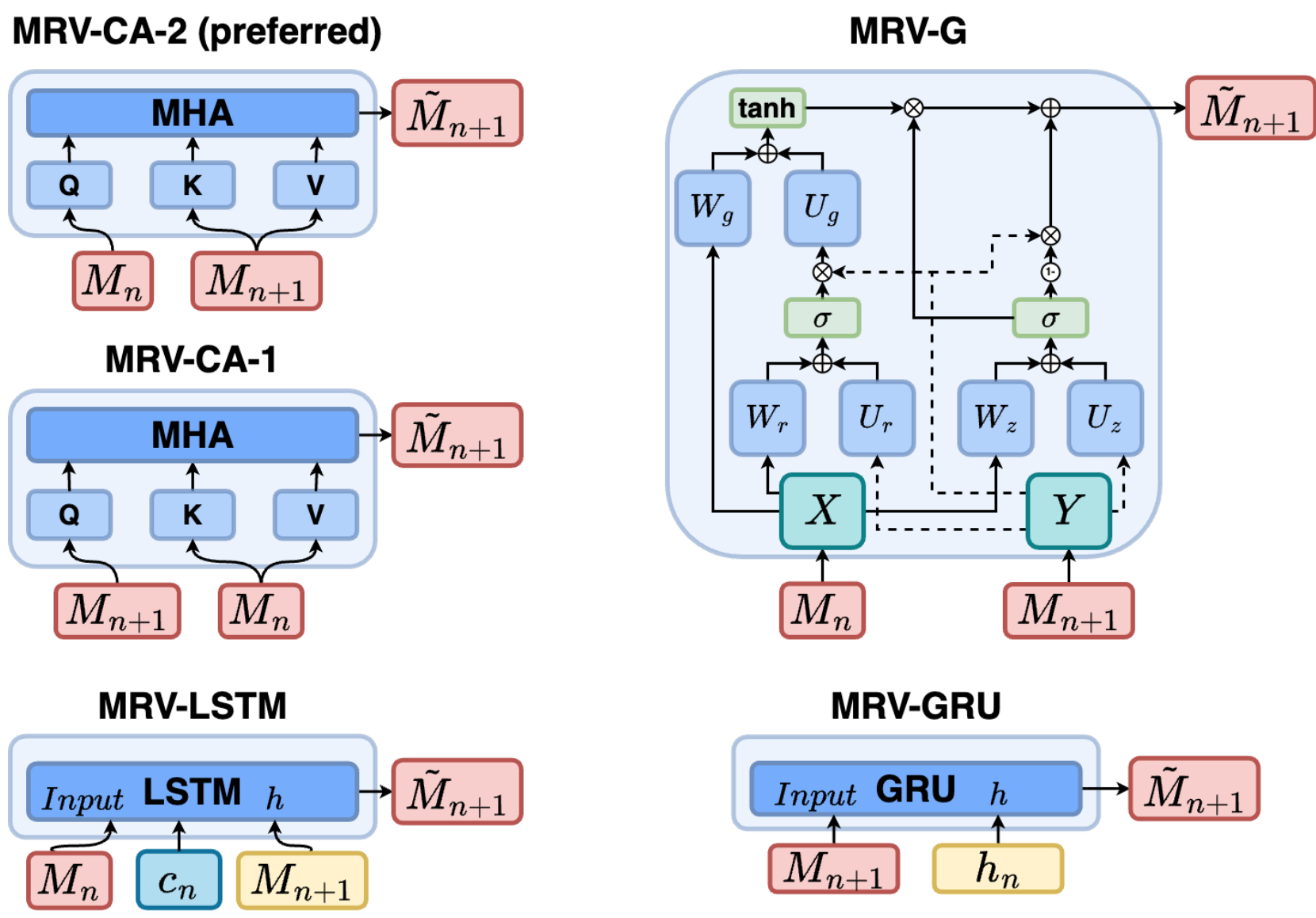
RQ 3. Memory Retention Valve scheme ablation. In the T-Maze environment, we observed that without MRV, RATE’s performance deteriorates on long corridors (
hidden states; MRV-LSTM: LSTM-based
Among all tested configurations, MRV-CA-2 demonstrated best performance (see Table 6). This cross-attention scheme uses incoming memory tokens
| Model | 150 | 360 | 600 | 900 |
|---|---|---|---|---|
| w/o MRV | ||||
| MRV-CA-2 | ||||
| MRV-G | ||||
| MRV-GRU | ||||
| MRV-LSTM | ||||
| MRV-CA-1 |
Table 6: Ablation of MRV configurations in T-Maze (). Baseline without MRV is marked . Default: MRV-CA-2.
6 RELATED WORK
Transformers in RL: Transformers have been applied to online
7 LIMITATIONS
While RATE is tailored for long-horizon, memory-intensive tasks, its complexity may be unnecessary in fully observable or short-term settings where simpler recurrent models suffice. Nonetheless, RATE matches or exceeds their performance across all tasks. Future work may explore adaptive variants that scale memory based on task complexity.
8 CONCLUSION
We propose the Recurrent Action Transformer with Memory (RATE), a transformer-based architecture for offline RL that combines attention with recurrence for long-horizon decision-making. RATE integrates memory embeddings, hidden state caching, and a Memory Retention Valve (MRV) to selectively retain critical information across segments. RATE achieves state-of-the-art results on memory-intensive tasks such as T-Maze, Minigrid-Memory, ViZDoom-Two-Colors, Memory Maze, and 48 POPGym tasks, generalizing up to 9600-step sequences and outperforming both recurrent and transformer baselines. Theoretical analysis shows that MRV guarantees lower-bounded memory preservation across updates, and ablation studies confirm its importance for long-horizon stability. Despite its memory focus, RATE also performs competitively on standard benchmarks like Atari and MuJoCo, demonstrating broad versatility. These results establish RATE as a unified, general-purpose offline RL model that excels across both short and long temporal contexts.
ACKNOWLEDGMENTS
The study was supported by the Ministry of Economic Development of the Russian Federation
REPRODUCIBILITY STATEMENT
We have taken several measures to ensure the reproducibility of our results. Model details: A full description of the RATE architecture, including pseudocode for both the model and the Memory Retention Valve (MRV), is provided in Section 3 and Algorithms 1 – 2. Theoretical results: Formal assumptions and complete proofs for our preservation theorem are given in Section 3. Experimental setup: Details of environments, training procedures, and evaluation protocols are reported in Section 4, with additional specifications (hyperparameters, dataset preprocessing, random seeds, and hardware setup) in Appendix E and Appendix C. Baselines: All baseline implementations are either drawn from widely used open-source libraries or re-implemented with hyperparameters matched to their original publications, as described in Section 4 and Appendix G. Code and data: An anonymous repository with the implementation of RATE, training scripts, and configuration files submitted as supplementary material. Together, these resources allow for full replication of our theoretical analyses and empirical results.
REFERENCES
Pranav Agarwal, Aamer Abdul Rahman, Pierre-Luc St-Charles, Simon JD Prince, and Samira Ebrahimi Kahou. Transformers in reinforcement learning: a survey. arXiv, 2023.
Rishabh Agarwal, Dale Schuurmans, and Mohammad Norouzi. An optimistic perspective on offline reinforcement learning. In International Conference on Machine Learning, pp. 104–114. PMLR, 2020.
Shmuel Bar-David, Itamar Zimerman, Eliya Nachmani, and Lior Wolf. Decision s4: Efficient sequence-based rl via state spaces layers. arXiv, 2023.
Edward Beeching, Christian Wolf, Jilles Dibangoye, and Olivier Simonin. Deep reinforcement learning on a budget: 3d control and reasoning without a supercomputer. CoRR, abs/1904.01806, 2019. URL http://arxiv.org/abs/1904.01806.
Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47: 253–279, 2013.
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv, 2020.
Aydar Bulatov, Yury Kuratov, and Mikhail Burtsev. Recurrent memory transformer. Advances in Neural Information Processing Systems, 35:11079–11091, 2022.
Jiahang Cao, Qiang Zhang, Ziqing Wang, Jiaxu Wang, Hao Cheng, Yecheng Shao, Wen Zhao, Gang Han, Yijie Guo, and Renjing Xu. Mamba as decision maker: Exploring multi-scale sequence modeling in offline reinforcement learning. arXiv, 2024.
Chang Chen, Yi-Fu Wu, Jaesik Yoon, and Sungjin Ahn. Transdreamer: Reinforcement learning with transformer world models. arXiv, 2022.
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34:15084–15097, 2021.
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo de Lazcano, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan Terry. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. CoRR, abs/2306.13831, 2023.
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv, 2014.
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv, 2019.
Yan Duan, John Schulman, Xi Chen, Peter L Bartlett, Ilya Sutskever, and Pieter Abbeel. Rl2: Fast reinforcement learning via slow reinforcement learning. arXiv, 2016.
Kevin Esslinger, Robert Platt, and Christopher Amato. Deep transformer q-networks for partially observable reinforcement learning. arXiv, 2022.
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning, 2021.
Jake Grigsby, Linxi Fan, and Yuke Zhu. AMAGO: Scalable in-context reinforcement learning for adaptive agents. In The Twelfth International Conference on Learning Representations, 2024. URL OpenReview.
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv, 2023.
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. arXiv, 2021.
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. arXiv, 2019.
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8): 1735–1780, 1997.
Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem. Advances in neural information processing systems, 34:1273–1286, 2021.
Zhengyao Jiang, Tianjun Zhang, Michael Janner, Yueying Li, Tim Rocktäschel, Edward Grefenstette, and Yuandong Tian. Efficient planning in a compact latent action space. In The Eleventh International Conference on Learning Representations, 2023. URL OpenReview.
Jikun Kang, Romain Laroche, Xindi Yuan, Adam Trischler, Xue Liu, and Jie Fu. Think before you act: Decision transformers with internal working memory. arXiv, 2023.
Feyza Duman Keles, Pruthuvi Mahesakya Wijewardena, and Chinmay Hegde. On the computational complexity of self-attention. In International conference on algorithmic learning theory, pp. 597–619. PMLR, 2023.
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. Advances in Neural Information Processing Systems, 33:1179–1191, 2020.
Andrew Lampinen, Stephanie Chan, Andrea Banino, and Felix Hill. Towards mental time travel: a hierarchical memory for reinforcement learning agents. Advances in Neural Information Processing Systems, 34:28182–28195, 2021.
Hung Le, Kien Do, Dung Nguyen, Sunil Gupta, and Svetha Venkatesh. Stable hadamard memory: Revitalizing memory-augmented agents for reinforcement learning. arXiv, 2024.
Kuang-Huei Lee, Ofir Nachum, Mengjiao Sherry Yang, Lisa Lee, Daniel Freeman, Sergio Guadarrama, Ian Fischer, Winnie Xu, Eric Jang, Henryk Michalewski, et al. Multi-game decision transformers. Advances in Neural Information Processing Systems, 35:27921–27936, 2022.
Wenzhe Li, Hao Luo, Zichuan Lin, Chongjie Zhang, Zongqing Lu, and Deheng Ye. A survey on transformers in reinforcement learning. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL OpenReview. Survey Certification.
Qi Lv, Xiang Deng, Gongwei Chen, Michael Y Wang, and Liqiang Nie. Decision mamba: A multi-grained state space model with self-evolution regularization for offline RL. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL OpenReview.
Volodymyr Mnih. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
Steven Morad, Ryan Kortvelesy, Matteo Bettini, Stephan Liwicki, and Amanda Prorok. Popgym: Benchmarking partially observable reinforcement learning. arXiv preprint arXiv:2303.01859, 2023a.
Steven Morad, Ryan Kortvelesy, Stephan Liwicki, and Amanda Prorok. Reinforcement learning with fast and forgetful memory. Advances in Neural Information Processing Systems, 36:72008–72029, 2023b.
Tianwei Ni, Michel Ma, Benjamin Eysenbach, and Pierre-Luc Bacon. When do transformers shine in RL? decoupling memory from credit assignment. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL OpenReview.
Toshihiro Ota. Decision mamba: Reinforcement learning via sequence modeling with selective state spaces. arXiv preprint arXiv:2403.19925, 2024.
Emilio Parisotto, Francis Song, Jack Rae, Razvan Pascanu, Caglar Gulcehre, Siddhant Jayakumar, Max Jaderberg, Raphael Lopez Kaufman, Aidan Clark, Seb Noury, et al. Stabilizing transformers for reinforcement learning. In International conference on machine learning, pp. 7487–7498. PMLR, 2020.
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. In International conference on machine learning, pp. 1310–1318. Pmlr, 2013.
Jurgis Pasukonis, Timothy Lillicrap, and Danijar Hafner. Evaluating long-term memory in 3d mazes. arXiv preprint arXiv:2210.13383, 2022.
Marco Pleines, Matthias Pallasch, Frank Zimmer, and Mike Preuss. Transformerxl as episodic memory in proximal policy optimization. Github Repository, 2023. URL GitHub.
Andrey Polubarov, Nikita Lyubaykin, Alexander Derevyagin, Ilya Zisman, Denis Tarasov, Alexander Nikulin, and Vladislav Kurenkov. Vintix: Action model via in-context reinforcement learning. arXiv preprint arXiv:2501.19400, 2025.
Subhojeet Pramanik, Esraa Elelimy, Marlos C Machado, and Adam White. Agalite: Approximate gated linear transformers for online reinforcement learning. arXiv preprint arXiv:2310.15719, 2023.
Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive transformers for long-range sequence modelling. arXiv preprint arXiv:1911.05507, 2019.
Jan Robine, Marc Höftmann, Tobias Uelwer, and Stefan Harmeling. Transformer-based world models are happy with 100k interactions. In The Eleventh International Conference on Learning Representations, 2023. URL OpenReview.
Thomas Schmied, Fabian Paischer, Vihang Patil, Markus Hofmarcher, Razvan Pascanu, and Sepp Hochreiter. Retrieval-augmented decision transformer: External memory for in-context rl. arXiv preprint arXiv:2410.07071, 2024.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv, 2017.
Max Siebenborn, Boris Belousov, Junning Huang, and Jan Peters. How crucial is transformer in decision transformer? arXiv, 2022.
Artyom Sorokin, Nazar Buzun, Leonid Pugachev, and Mikhail Burtsev. Explain my surprise: Learning efficient long-term memory by predicting uncertain outcomes. 07 2022. doi: 10.48550/arXiv.2207.13649.
R.S. Sutton and A.G. Barto. Reinforcement Learning, second edition: An Introduction. Adaptive Computation and Machine Learning series. MIT Press, 2018. ISBN 9780262039246.
Adaptive Agent Team, Jakob Bauer, Kate Baumli, Satinder Baveja, Feryal Behbahani, Avishkar Bhoopchand, Nathalie Bradley-Schmieg, Michael Chang, Natalie Clay, Adrian Collister, et al. Human-timescale adaptation in an open-ended task space. arXiv, 2023.
Trieu Trinh, Andrew Dai, Thang Luong, and Quoc Le. Learning longer-term dependencies in rnns with auxiliary losses. In International Conference on Machine Learning, pp. 4965–4974. PMLR, 2018.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
Jane X Wang, Zeb Kurth-Nelson, Dhruva Tirumala, Hubert Soyer, Joel Z Leibo, Remi Munos, Charles Blundell, Dharshan Kumaran, and Matt Botvinick. Learning to reinforcement learn. arXiv, 2016.
Jincheng Wang, Penny Karanasou, Pengyuan Wei, Elia Gatti, Diego Martinez Plasencia, and Dimitrios Kanoulas. Long-short decision transformer: Bridging global and local dependencies for generalized decision-making. In The Thirteenth International Conference on Learning Representations, 2025. URL.
Yueh-Hua Wu, Xiaolong Wang, and Masashi Hamaya. Elastic decision transformer. Advances in neural information processing systems, 36:18532–18550, 2023.
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33:17283–17297, 2020.
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv, 2022.
Zifeng Zhuang, Dengyun Peng, Jinxin Liu, Ziqi Zhang, and Donglin Wang. Reinformer: Max-return sequence modeling for offline rl. arXiv, 2024.
Table of Contents
- A Discussion: Are RNNs Still Better for Memory?
- B Decision Transformer
- C Environments
- C.1 Memory-intensive environments
- C.2 Standard benchmarks
- D Action Associative Retrieval
- E Training
- E.1 ViZDoom-Two-Colors
- E.2 Passive T-Maze
- E.3 Memory Maze
- E.4 Minigrid-Memory
- E.5 POPGym Suite
- E.6 Atari and MuJoCo
- F Additional ablation studies
- F.1 Additional ViZDoom-Two-Colors ablation
- F.2 Curriculum Learning
- F.3 Supplemental MRV ablation
- F.4 Ablation on number of segments and segment length
- G Transformer Ablation Studies
- H Recommendations for Hyperparameter Settings
- I Technical details
A DISCUSSION: ARE RNNS STILL BETTER FOR MEMORY?
Our experiments provide a systematic comparison between recurrent and transformer-based architectures in memory-intensive tasks. When trained on short sequences, recurrent models such as BC-LSTM perform competitively. For example, in the T-Maze environment, BC-LSTM achieves perfect success rates when trained on sequences up to 150 steps, effectively capturing short-term dependencies via its internal state dynamics.
However, this advantage quickly fades as training sequences grow longer. Increasing the training horizon from 150 to 600 steps causes BC-LSTM’s performance to collapse to a 50% success rate across all inference lengths – even those shorter than the training context – indicating difficulty with gradient stability and information retention over long spans
These findings extend to more complex environments. In ViZDoom-Two-Colors and Memory Maze
In conclusion, while RNNs remain effective for short-range temporal dependencies, their performance degrades in long-horizon, sparse-reward, and generalization-critical settings. RATE bridges this gap

by integrating attention with recurrence, offering a scalable and robust memory solution. These results underscore the architectural promise of combining transformer attention with recurrent dynamics for long-term tasks in RL.
B DECISION TRANSFORMER
Decision Transformer
| Algorithm 3 Decision Transformer |
|---|
| Require: |
| 1: |
| 2: |
| 3: |
| 4: |
| Output: |
C ENVIRONMENTS
C.1 MEMORY-INTENSIVE ENVIRONMENTS
In this section, we provide an extended description of the environments used in this paper, as well as the methodology used to collect the trajectories. Table 7 summarizes the observations type, rewards type, and actions type for each of the environments considered in this paper.
C.1.1 VIZDOOM-TWO-COLORS
We used a modified ViZDoom-Two-Colors environment from
We collected a dataset of 5000 trajectories of 90 steps in length using a trained A2C
Table 7: Description of observations and reward functions for the considered environments.
| Environment | Obs. Type | Rew. Type | Act. Space | Obs. Details |
|---|---|---|---|---|
| ViZDoom-Two-Colors | Image | Continuous | Discrete | First-person view |
| T-Maze | Vector | Sparse & Discrete | Discrete | Low-dimensional vector |
| Memory Maze | Image | Sparse & Discrete | Discrete | First-person view |
| Minigrid-Memory | Image | Sparse | Discrete | grid centered on agent |
| POPGym | Vector/Image | Discrete/Continuous | Discrete/Continuous | Vector or 2D grid |
| Action Assoc. Retrieval | Vector | Sparse & Discrete | Discrete | Symbolic vector input |
| Atari | Image | Sparse & Discrete | Discrete | Full game screen |
| MuJoCo | Vector | Continuous | Continuous | Low-dimensional state vector |
retain information about the pillar for a time much longer than the pillar has been in the environment. Using only short-term memory and, for example, collecting the next item of the same color as the previous collected item, it will not be possible for the agent to survive for a long time, as this policy is extremely unstable. This is due to the fact that in the training dataset the agent occasionally makes a mistake and picks up an object of the opposite color. Thus, irrelevant information about the desired color may enter the transformer context and the agent will start collecting items of an opposite color, which will quickly lead to a failure.
C.1.2 T-MAZE
To investigate agent’s long-term memory on very long environments (the inference trajectory length is much longer than the effective context length
The dataset consists of 2000 of trajectories for each segment of length 30 (i.e. 6000 trajectories for the
C.1.3 MEMORY MAZE
In this first-person view 3D environment
C.1.4 MINIGRID-MEMORY
Minigrid-Memory
C.1.5 POPGYM
POPGym
C.2 STANDARD BENCHMARKS
C.2.1 ATARI GAMES
For the Atari game environments
C.2.2 MUJOCO.
Despite the fact that memory is not required in decision making in control environments like MuJoCo
Published as a conference paper at ICLR 2026
D Action Associative Retrieval
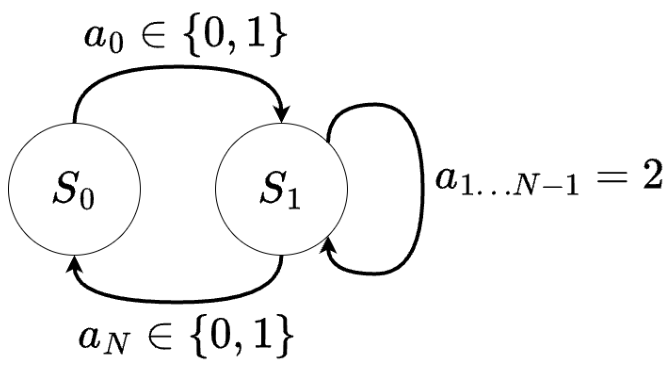
As shown in Figure 6, DT has a SR = 50%
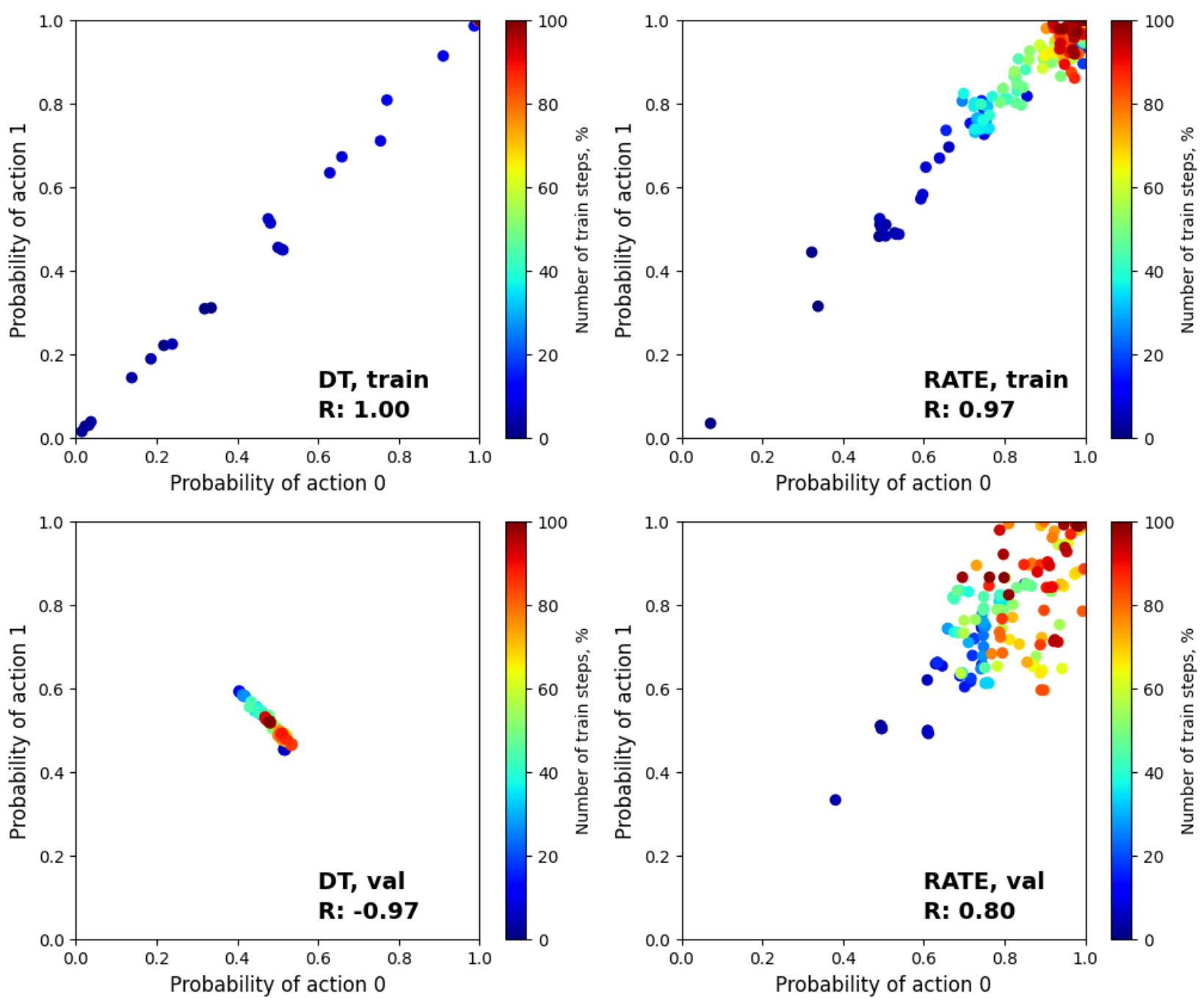
To check how the agent’s performance changes during training, we design an Action Associative Retrieval (AAR)
There are two states in this environment: and
More formally, we can talk about the presence of memory in an agent when solving AAR (T-Maze-like) tasks under the condition that:
This condition means that if the agent has memory, the sum of the average conditional probabilities over all experiments will be greater than one, i.e., these probabilities are independent of each other.
Provided that the sum of these probabilities is less than or equal to one, the agent will choose at best the same target action in most experiments, even if another action is required.
where
In the results Figure 12, the first 1% of training steps was removed because it corresponds to the beginning of the training and is unrepresentative. Blue dots correspond to the beginning of training, red dots to the end of training. As can be seen from Figure 12, during training, the probabilities and
At the same time, during validation, for the RATE model this pattern is preserved – the red points corresponding to the probabilities of choosing actions and are in the upper right part of the graph, positive correlation persists (
E Training
This section provides additional details on the training process of the baselines considered in the paper. We treated the inclusion of the feed-forward network (FFN) block in RATE’s transformer decoder as a hyperparameter, as RATE performed slightly better without FFN in some environments. In contrast, other transformer-based baselines were trained with the standard transformer decoder including FFN.
E.1 ViZDoom-Two-Colors
Since the pillar disappears at time
E.2 Passive T-Maze
We trained models on sequences of length and evaluated them on . For RATE, each sequence was split into segments, yielding a context length of . All training trajectories started from , ensuring the cue was always included. In what follows, we adopt the notation MODEL-N, where indicates segmentation into three recurrent blocks (e.g., RATE-3 is trained on full sequences of length with ). This convention is used throughout the ablation studies.
E.3 Memory Maze
To train RATE, DT, RMT, and TrXL on Memory Maze, we used the same approach as for ViZDoom-Two-Colors environment, but instead of using fixed trajectories starting at , we sampled consecutive 90-step subsequences from the original 1000-step trajectories. Each subsequence was sampled with a stride of 90 steps, resulting in approximately 11 training sequences per original trajectory. As in the ViZDoom-Two-Colors case, training for DT was performed with a context length of and for RATE, RMT, and TrXL with a context length of and number of segments , i.e., effective context length .
E.4 MINIGRID-MEMORY
To train baselines in this environment, we used only mazes of fixed size
E.5 POPGYM SUITE
POPGym
E.6 ATARI AND MUJOCO
When training RATE on Atari games and MuJoCo control tasks, sequences of length (Atari) and (MuJoCo)
For Atari, we used the identical experimental design described in the DT paper
For MuJoCo, our findings suggest that the conventional strategy of utilizing return is not suitable for our segment-based scheme. The issue arises during the trajectory, where the agent’s return persistently diminishes. However, the true value of the agent’s state at the onset and conclusion of the episode could remain unchanged, provided the agent’s policy performs consistently well. To rectify this discrepancy, we propose a novel evaluation strategy for MuJoCo tasks. In this approach, each segment commences with the maximum return, simulating the scenario where the agent initiates the trajectory anew. This method effectively mitigates the aforementioned issue, enhancing the accuracy of our evaluation process. Our MuJoCo experiments in Table 3 show that this benefits performance significantly for some environments. Thus, using RATE allowed us to obtain the best metrics for MuJoCo in 3/9 cases compared to the other baselines. RATE also outperforms DT in 9/9 tasks.
F Additional Ablation Studies
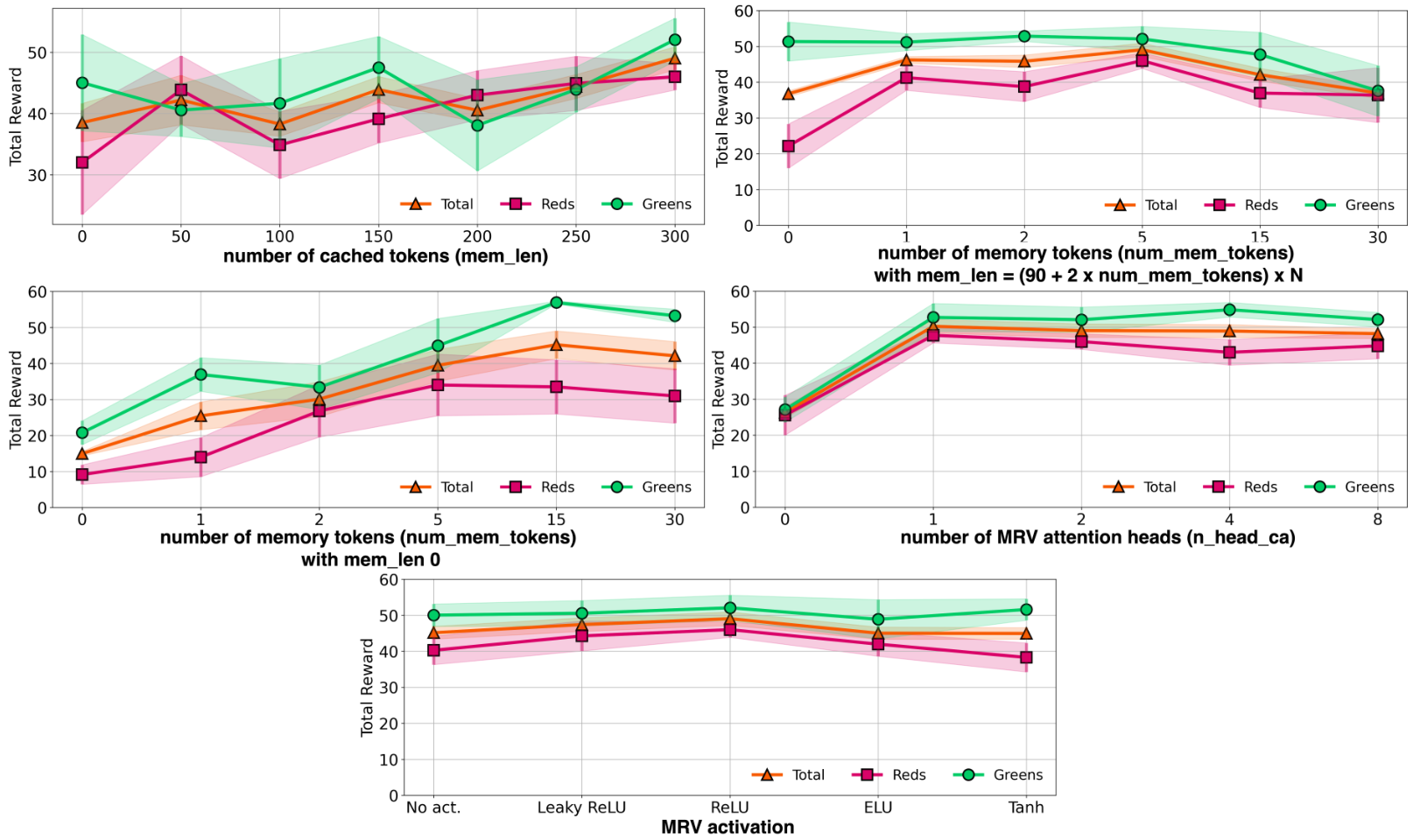
To determine the optimal hyperparameters associated with memory mechanisms, additional ablation studies were performed in ViZDoom-Two-Colors and T-Maze environments, and the results are presented in Figure 14 and Figure 13 (right). From the ablation studies results, it was found that for environments like ViZDoom-Two-Colors with continuous reward signal and image observations, the best results can be obtained using number of cached memory tokens mem_len = (K * 3 + 2 * num_mem_tokens) * N
Table 8: RATE hyperparameters for different experiments. ‡ – Leaky ReLU used in Atari.Pong. The listed hyperparameters for ViZDoom-Two-Colors and T-Maze correspond to the experiments with
| Hyperparameter | ViZDoom2C | Memory Maze | T-Maze | Minigrid-Memory | POPGym | Atari | MuJoCo |
|---|---|---|---|---|---|---|---|
| Memory-specific parameters | |||||||
| Number of memory tokens | 15 | 15 | 10 | 10 | 30 | 15 | 5 |
| Number of cached tokens | 100 | 360 | 0 | 180 | 100 | 360 | 60 |
| Number of MRV heads | 2 | 0 | 2 | 4 | 2 | 1 | 1 |
| MRV activation | ReLU | ReLU | ReLU | ReLU | ReLU | ReLU | ReLU |
| Transformer architecture | |||||||
| Number of layers | 6 | 6 | 8 | 4 | 10 | 6 | 3 |
| Number of attention heads | 8 | 8 | 8 | 4 | 2 | 8 | 1 |
| Embedding dimension | 64 | 64 | 64 | 128 | 32 | 128 | 128 |
| Context length | 50 | 30 | 50 | 30 | 18 | 30 | 20 |
| Number of segments | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| Skip dec FFN | False | True | True | False | True | True | True |
| Regularization | |||||||
| Hidden dropout | 0.2 | 0.5 | 0.2 | 0.3 | 0.1 | 0.2 | 0.2 |
| Attention dropout | 0.05 | 0.2 | 0.1 | 0.1 | 0.05 | 0.05 | 0.05 |
| Weight decay | 0.001 | 0.1 | 0.001 | 0.001 | 0.001 | 0.1 | 0.1 |
| Training configuration | |||||||
| Max epochs | 150 | 80 | 200 | 500 | 200 | 10 | 10 |
| Batch size | 128 | 64 | 64 | 64 | 32 | 128 | 4096 |
| Loss function | CE | CE | CE | CE | CE | CE | MSE |
| Optimizer | AdamW | AdamW | AdamW | AdamW | AdamW | AdamW | AdamW |
| Learning rate | 3e-4 | 3e-4 | 1e-4 | 1e-4 | 3e-4 | 3e-4 | 6e-5 |
| Grad norm clip | 5.0 | 1.0 | 1.0 | 5.0 | 5.0 | 1.0 | 1.0 |
| Cosine decay | False | True | False | False | False | True | False |
| Linear warmup | True | True | True | True | True | True | True |
| (0.9, 0.999) | (0.9, 0.95) | (0.9, 0.999) | (0.9, 0.999) | (0.9, 0.999) | (0.9, 0.95) | (0.9, 0.95) |
On the other hand, for environments with sparse events like T-Maze, it has been found that using caching of hidden states of previous tokens (mem_len > 0) prevents remembering important information.
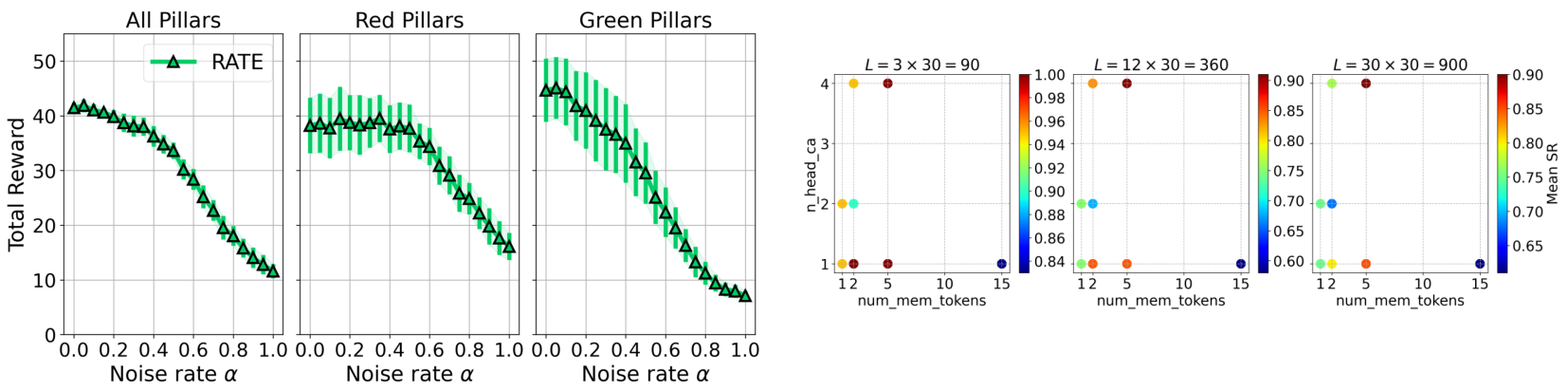
F.1 ADDITIONAL VIZDOOM-TWO-COLORS ABLATION
The effect of combining of memory tokens with noise is shown in Figure 13 (left). The noise was applied as a convex combination: memory_tokens = (1-α) * memory_tokens + α * noise. With unchanged caching of hidden states from previous steps at growth of the noise parameter
Table 9: Performance on POPGym tasks (mean±sem over three runs, 100 seeds each).
| Environment | RATE | DT | Random | BC-MLP | BC-LSTM | Dataset Average Return |
|---|---|---|---|---|---|---|
| AutoencodeEasy-v0 | ||||||
| AutoencodeMedium-v0 | ||||||
| AutoencodeHard-v0 | ||||||
| BattleshipEasy-v0 | ||||||
| BattleshipMedium-v0 | ||||||
| BattleshipHard-v0 | ||||||
| ConcentrationEasy-v0 | ||||||
| ConcentrationMedium-v0 | ||||||
| ConcentrationHard-v0 | ||||||
| CountRecallEasy-v0 | ||||||
| CountRecallMedium-v0 | ||||||
| CountRecallHard-v0 | ||||||
| HigherLowerEasy-v0 | ||||||
| HigherLowerMedium-v0 | ||||||
| HigherLowerHard-v0 | ||||||
| LabyrinthEscapeEasy-v0 | ||||||
| LabyrinthEscapeMedium-v0 | ||||||
| LabyrinthEscapeHard-v0 | ||||||
| LabyrinthExploreEasy-v0 | ||||||
| LabyrinthExploreMedium-v0 | ||||||
| LabyrinthExploreHard-v0 | ||||||
| MineSweeperEasy-v0 | ||||||
| MineSweeperMedium-v0 | ||||||
| MineSweeperHard-v0 | ||||||
| MultiarmedBanditEasy-v0 | ||||||
| MultiarmedBanditMedium-v0 | ||||||
| MultiarmedBanditHard-v0 | ||||||
| NoisyPositionOnlyCartPoleEasy-v0 | ||||||
| NoisyPositionOnlyCartPoleMedium-v0 | ||||||
| NoisyPositionOnlyCartPoleHard-v0 | ||||||
| NoisyPositionOnlyPendulumEasy-v0 | ||||||
| NoisyPositionOnlyPendulumMedium-v0 | ||||||
| NoisyPositionOnlyPendulumHard-v0 | ||||||
| PositionOnlyCartPoleEasy-v0 | ||||||
| PositionOnlyCartPoleMedium-v0 | ||||||
| PositionOnlyCartPoleHard-v0 | ||||||
| PositionOnlyPendulumEasy-v0 | ||||||
| PositionOnlyPendulumMedium-v0 | ||||||
| PositionOnlyPendulumHard-v0 | ||||||
| RepeatFirstEasy-v0 | ||||||
| RepeatFirstMedium-v0 | ||||||
| RepeatFirstHard-v0 | ||||||
| RepeatPreviousEasy-v0 | ||||||
| RepeatPreviousMedium-v0 | ||||||
| RepeatPreviousHard-v0 | ||||||
| VelocityOnlyCartPoleEasy-v0 | ||||||
| VelocityOnlyCartPoleMedium-v0 | ||||||
| VelocityOnlyCartPoleHard-v0 |
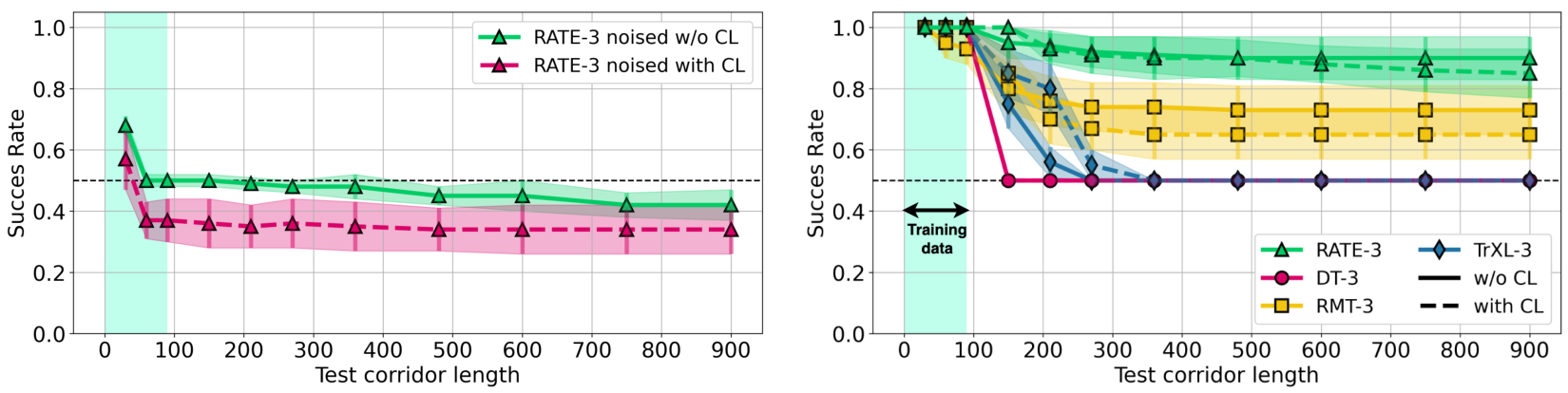
F.2 CURRICULUM LEARNING
Since in the T-Maze environment, the number of actions at the junction relates to the number of actions when moving straight along the corridor as
Curriculum learning (CL) is a technique in which a model is trained on examples of increasing difficulty. In this approach, the model is first trained on the set of trajectories
In the T-Maze environment, DT, RATE, RMT, and TrXL were trained with and without curriculum learning because this approach theoretically produces better results. However, it is important to note
Table 10: Experimental setup and evaluation metrics across different environments. denotes the number of model runs; denotes the number of inference episodes with different seeds; sem denotes standard error of the mean, and std denotes standard deviation.
| Environment | Experiment Setup | Results | ||
|---|---|---|---|---|
| Metric | Notation | |||
| Memory-intensive environments | ||||
| ViZDoom-Two-Colors | 6 | 100 | Return | meansem |
| T-Maze | 4 | 100 | Success Rate | meansem |
| Memory Maze | 3 | 100 | Return | meansem |
| Minigrid-Memory | 3 | 100 | Return | meansem |
| POPGym | 3 | 100 | Return | meansem |
| Diagnostic environment | ||||
| Action Associative Retrieval | 10 | — | Success Rate | meansem |
that the T-Maze task is successfully solved by the RATE model without using curriculum learning, and even vice versa – its use slightly degraded performance on long corridors. However, with respect to TrXL, the use of CL yielded slightly better results. The work showed that using CL does not achieve significantly better performance on the T-Maze task. The results of using the CL on the T-Maze environment are presented in Figure 16 (left), and the results of applying noise to memory embeddings to assess its importance are presented in Figure 16 (right).
F.3 SUPPLEMENTAL MRV ABLATION
One of the options for implementing the memory tokenization gating mechanism was an approach similar to the one proposed in Gated Transforer-XL
Table 11: RATE encoders for each part of
| Environment | Encoder Configuration | |||
|---|---|---|---|---|
| Return | Observation | Conv. params | Action | |
| Image-based environments | ||||
| ViZDoom-Two-Colors | Linear | Conv2D 3 | (32, 64, 64) / (8, 4, 3) / 0 | Embedding |
| Memory Maze | Linear | Conv2D 3 | (32, 64, 64) / (8, 4, 3) / 2 | Embedding |
| Minigrid-Memory | Linear | Conv2D 3 | (32, 64, 64) / (8, 4, 3) / 0 | Embedding |
| Atari | Linear | Conv2D 3 | (32, 64, 64) / (8, 4, 3) / 0 | Embedding |
| Vector-based environments | ||||
| T-Maze | Linear | Linear | — | Embedding |
| MuJoCo | Linear | Linear | — | Linear |
| Action Associative Retrieval | Linear | Linear | — | Embedding |
| POPGym | Linear | Linear | — | Embedding / Linear |
The results of the RATE (trained on corridor lengths of
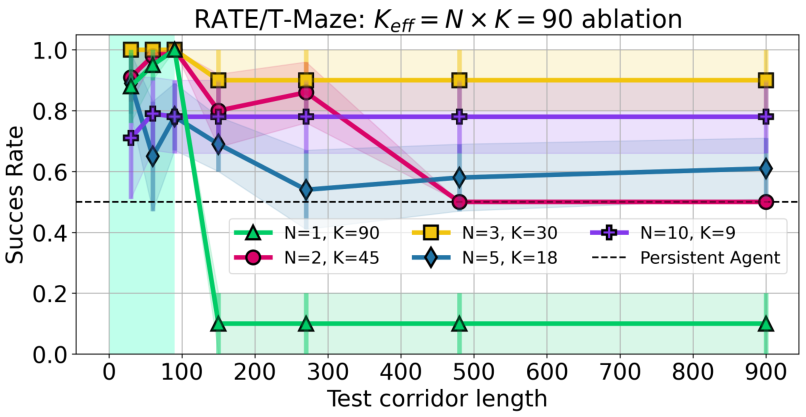
F.4 ABLATION ON NUMBER OF SEGMENTS AND SEGMENT LENGTH
Partitioning the trajectories into fixed-length segments allows the RATE model to train on long trajectories without increasing the context size, which makes the parameters
G TRANSFORMER ABLATION STUDIES
Transformer core hyperparameters. This section presents the results of ablation studies on the main hyperparameters of the RATE transformer. The RATE configuration for the T-Maze environment specified in Table 8 was chosen for the ablation studies. The ablation studies focus on understanding the impact of key hyperparameters by systematically varying one parameter while keeping others constant. The results are shown in Figure 20, Figure 21, and Figure 22.
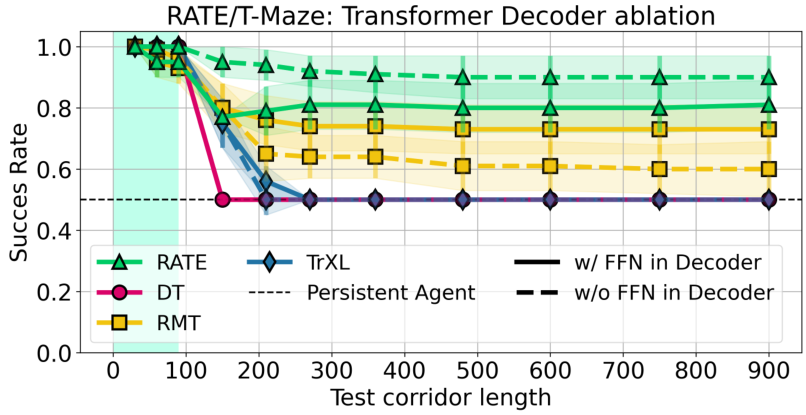
Feed-Forward Network. For RATE, the inclusion of the decoder feed-forward block is treated as a tunable hyperparameter. In most environments, we disable it, as doing so often leads to better performance Figure 19. However, for ViZDoom-Two-Colors and Minigrid-Memory, we found that retaining the feed-forward block yields slightly improved results, and thus it is enabled in those settings.
H RECOMMENDATIONS FOR HYPERPARAMETER SETTINGS
Transformer-based models require careful hyperparameter tuning, and the addition of memory mechanisms in RATE introduces a few more components. However, configuring RATE remains
largely similar to tuning a standard transformer. Based on extensive empirical evaluation, we provide the following practical guidelines to simplify the setup process.
Step-by-step configuration:
- Segment setup. Divide each trajectory into
N equals three segments. For a trajectory of lengthT , set the context length toK equals T floor divided by 3 .
-
Memory configuration. Use the following default parameters for RATE’s memory mechanisms:
num_mem_tokens = 5n_head_ca = 1mrv_act = ReLUmem_len =three times K plus two times number of memory tokens, all times N for dense reward environments(e.g., ViZDoom-Two-Colors, Minigrid-Memory) zero for sparse reward environments(e.g., T-Maze)
-
Transformer core. Set the standard architecture parameters (number of layers, attention heads, embedding dimension, etc.) based on the task complexity and computational constraints.
-
Memory tuning. After adjust, fine-tune memory-related parameters if needed (e.g.,
num_mem_tokens,mem_len, dropout rates).
This configuration provides a strong default setup and has consistently performed well across all evaluated tasks.

Table 12: Comparison of RATE and DT Model Parameters. RATE has 1.0-7.7% less parameters compared to DT due to the fact that RATE does not use feed-forward network in the transformer decoder by default.
| Environment | RATE | DT | diff, % |
|---|---|---|---|
| T-Maze | 1,723,840 | 1,775,488 | -2.91 |
| ViZDoom-Two-Colors | 4,537,504 | 4,672,032 | -2.88 |
| Minigrid-Memory | 2,000,864 | 2,051,872 | -2.49 |
| Memory Maze | 1,639,840 | 1,673,696 | -2.02 |
| POPGym | 6,760,192 | 6,827,008 | -0.98 |
I Technical Details
Table 12 and Table 13 shows the technical parameters of the training models. Note that the difference between the number of DT and RATE parameters is small. Training RATE with trajectory splitting into
Table 13: Computational efficiency comparison between RATE and DT models across different memory-intensive environments. We report three key metrics: (1) training time per epoch (meanstd, in seconds), (2) inference latency per step (meansem, in milliseconds), and (3) GPU memory footprint (in MiB). Lower values indicate better efficiency.
| RATE | DT | |||||
|---|---|---|---|---|---|---|
| Environment | Train (s) | Test (ms) | Size (MiB) | Train (s) | Test (ms) | Size (MiB) |
| T-Maze | 16.172.75 | 7.200.31 | 3,148 | 95.750.49 | 10.690.14 | 8,608 |
| ViZDoom-Two-Colors | 77.443.56 | 10.350.52 | 7,750 | 68.181.56 | 10.450.41 | 14,046 |
| Minigrid-Memory | 33.742.65 | 9.942.24 | 4,102 | 16.771.37 | 10.432.84 | 4,298 |
| Memory Maze | 110.262.97 | 38.980.62 | 6,638 | 82.691.56 | 40.360.46 | 10,386 |
| POPGym | 3.370.25 | 8.910.37 | 5,948 | 3.640.53 | 8.980.32 | 10,696 |
Footnotes
-
In our setting, cached hidden states refers to the mechanism introduced in Transformer-XL
(Dai et al., 2019) , in which the hidden activations computed for preceding segments are stored and reused as an extended key-value context when processing the next segment. Concretely, instead of recomputing all past representations from scratch, the model concatenates the fixed, non-trainable hidden states from earlier segments with the current segment’s inputs, thereby enabling segment-level recurrence and information flow across boundaries without backpropagating gradients through the cached states. ↩ -
Static recurrence denotes the practice of forwarding cached hidden states from one segment to the next without any gating or content-based filtering. For instance, Transformer-XL uses this mechanism by directly reusing past hidden states as extended key-value context, which increases the effective horizon but provides no control over what information is retained or overwritten ↩
-
Throughout the paper, alignment refers only to a geometric notion: two vectors are “-aligned” when the angle between them does not exceed a specified threshold. This has no relation to alignment or preference tuning in large language models. ↩