RECURRENT INDEPENDENT MECHANISMS
Anirudh Goyal, Alex Lamb, Jordan Hoffmann, Shagun Sodhani, Sergey Levine
Yoshua Bengio, Bernhard Schölkopf
ABSTRACT
We explore the hypothesis that learning modular structures which reflect the dynamics of the environment can lead to better generalization and robustness to changes that only affect a few of the underlying causes. We propose Recurrent Independent Mechanisms (RIMs), a new recurrent architecture in which multiple groups of recurrent cells operate with nearly independent transition dynamics, communicate only sparingly through the bottleneck of attention, and compete with each other so they are updated only at time steps where they are most relevant. We show that this leads to specialization amongst the RIMs, which in turn allows for remarkably improved generalization on tasks where some factors of variation differ systematically between training and evaluation.
1 INDEPENDENT MECHANISMS
Physical processes in the world often have a modular structure which human cognition appears to exploit, with complexity emerging through combinations of simpler subsystems. Machine learning seeks to uncover and use regularities in the physical world. Although these regularities manifest themselves as statistical dependencies, they are ultimately due to dynamic processes governed by causal physical phenomena. These processes are mostly evolving independently and only interact sparsely. For instance, we can model the motion of two balls as separate independent mechanisms even though they are both gravitationally coupled to Earth as well as (weakly) to each other. Only occasionally will they strongly interact via collisions.
The notion of independent or autonomous mechanisms has been influential in the field of causal inference. A complex generative model, temporal or not, can be thought of as the composition of independent mechanisms or “causal” modules. In the causality community, this is often considered a prerequisite for being able to perform localized interventions upon variables determined by such models
In the dynamic setting, we think of an overall system being assayed as composed of a number of fairly independent subsystems that evolve over time, responding to forces and interventions. An agent needs not devote equal attention to all subsystems at all times: only those aspects that significantly interact need to be considered jointly when deciding or planning
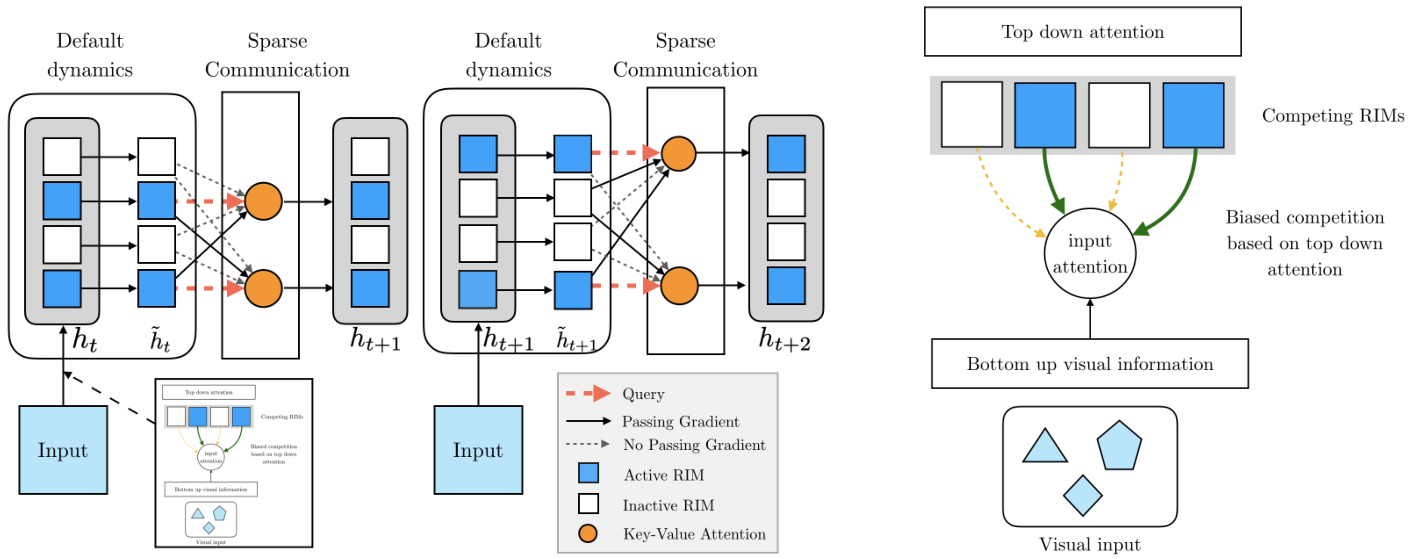
sparsely interacting recurrent mechanisms in order to benefit from the modularity and independent mechanisms assumption.
Why do Models Succeed or Fail in Capturing Independent Mechanisms? While universal approximation theorems apply in the limit of large i.i.d. data sets, we are interested in the question of whether models can learn independent mechanisms from finite data in possibly changing environments, and how to implement suitable inductive biases. As the simplest case, we can consider training an RNN consisting of
Assumptions on the joint distribution of high level variables. The central question motivating our work is how a gradient-based deep learning approach can learn a representation of high level variables which favour learning independent but sparsely interacting recurrent mechanisms in order to benefit from such modularity assumption. The assumption about the joint distribution between the high-level variables is different from the assumption commonly found in many papers on disentangling factors of variation
2 RIMs with Sparse Interactions
Our approach to modelling a dynamical system of interest divides the overall model into
At a high level (see Fig. 1), we want each RIM to have its own independent dynamics operating by default, and occasionally to interact with other relevant RIMs and selected elements of the encoded input. The total number of parameters can be kept small since RIMs can specialize on simple sub-1
problems, and operate on few key/value variables at a time selected using an attention mechanism, as suggested by the inductive bias from
2.1 Key-Value Attention to Process Sets of Named Interchangeable Variables
Each RIM should be activated and updated when the input is relevant to it. We thus utilize competition to allocate representational and computational resources, using an attention mechanism which selects and then activates only a subset of the RIMs for each time step. As argued by
where the softmax is applied to each row of its argument matrix, yielding a set of convex weights. As a result, one obtains a convex combination of the values in the rows of
When the inputs and outputs of each RIM are a set of objects or entities (each associated with a key and value vector), the RIM processing becomes a generic object-processing machine which can operate on subsymbolic “variables” in a sense analogous to variables in a programming language: as interchangeable arguments of functions, albeit with a distributed representation both for they name or type and for their value. Because each object has a key embedding (which one can understand both as a name and as a type), the same RIM processing can be applied to any variable which fits an expected “distributed type” (specified by a query vector). Each attention head then corresponds to a typed argument of the function computed by the RIM. When the key of an object matches the query of head
2.2 Selective Activation of RIMs as a Form of Top-Down Modulation
The proposed model learns to dynamically select those RIMs for which the current input is relevant. RIMs are triggered as a result of interaction between the current state of the RIM and input information coming from the environment. At each step, we select the top-
attention score for the real input. Intuitively, the RIMs must compete on each step to read from the input, and only the RIMs that win this competition will be able to read from the input and have their state updated. In our use of key-value attention, the queries come from the RIMs, while the keys and values come from the current input. This differs from the mechanics of
The input
As before, linear transformations are used to construct keys (
Based on the softmax values in (2), we select the top RIMs (out of the total RIMs) to be activated for each step, which have the least attention on the null input (and thus put the highest attention on the input), and we call this set . Since the queries depend on the state of the RIMs, this enables individual RIMs to attend only to the part of the input that is relevant for that particular RIM, thus enabling selective attention based on a top-down attention process
For spatially structure input: All datasets we considered are temporal, yet there is a distinction between whether the input on each time step is highly structured (such as a video) or not (such as language modeling, where each step has a word or character). In the former case, we can get further improvements by making the activation of RIMs not just sparse across time but also sparse across the (spatial) structure. The input at time can be seen as an output of the encoder parameterized by a neural network (for ex. CNN in case of visual observations) i.e., . As before, linear transformations are used to construct position-specific input keys (), position-specific values (), and RIM specific queries (, one per RIM attention head). The attention thus is
In order for different RIMs to specialize on different spatial regions, we can use position-specific competition among the different RIMs. The contents of the attended positions are combined yielding a RIM-specific input. As before based on the softmax values in (3), we can select the top RIMs (out of the total RIMs) to be activated for each spatial position, which have the highest attention on that spatial position.
2.3 Independent RIM Dynamics
Now, consider the default transition dynamics which we apply for each RIM independently and during which no information passes between RIMs. We use
somewhat flexible, but we opted to use either a GRU
as a function of the attention mechanism
2.4 COMMUNICATION BETWEEN RIMS
Although the RIMs operate independently by default, the attention mechanism allows sharing of information among the RIMs. Specifically, we allow the activated RIMs to read from all other RIMs (activated or not). The intuition behind this is that non-activated RIMs are not related to the current input, so their value needs not change. However they may still store contextual information relevant for activated RIMs later on. For this communication between RIMs, we use a residual connection as in
We note that we can also consider sparsity in the communication attention such that a particular RIM only attends to sparse sub-set of other RIMs, and this sparsity is orthogonal to the kind used in input attention. In order to make the communication attention sparse, we can still use the same top- attention.
Number of Parameters. RIMs can be used as a drop-in replacement for an LSTM/GRU layer. There is a subtlety that must be considered for successful integration. If the total size of the hidden state is kept the same, integrating RIMs drastically reduces the total number of recurrent parameters in the model (because of having a block-sparse structure). RIMs also adds new parameters to the model through the addition of the attention mechanisms although these are rather in small number.
Multiple Heads: Analogously to
3 RELATED WORK
Neural Turing Machine (NTM) and Relational Memory Core (RMC): the NTM
Separate Recurrent Models: EntNet
Modularity and Neural Networks: A network can be composed of several modules, each meant to perform a distinct function, and hence can be seen as a combination of experts
Computation on demand: There are various architectures
4 Experiments
The main goal of our experiments is to show that the use of RIMs improves generalization across changing environments and/or in modular tasks, and to explore how it does so. Our goal is not to outperform highly optimized baselines; rather, we want to show the versatility of our approach by applying it to a range of diverse tasks, focusing on tasks that involve a changing environment. We organize our results by the capabilities they illustrate: we address generalization based on temporal patterns, based on objects, and finally consider settings where both of these occur together.
4.1 RIMs improve generalization by specializing over temporal patterns
We first show that when RIMs are presented with sequences containing distinct and generally independent temporal patterns, they are able to specialize so that different RIMs are activated on different patterns. RIMs generalize well when we modify a subset of the patterns (especially those unrelated to the class label) while most recurrent models fail to generalize well to these variations.

Copying Task: First we turn our attention to the task of receiving a short sequence of characters, then receiving blank inputs for a large number of steps, and then being asked to reproduce the original sequence. We can think of this as consisting of two temporal patterns which are independent: one where the sequence is received and another “dormant” pattern where no input is provided. As an example of out-of-distribution generalization, we find that using RIMs, we can extend the length of this dormant phase from 50 during training to 200 during testing and retain perfect performance (Table 1), whereas baseline methods including LSTM, NTM, and RMC substantially degrade. In addition, we find that this result is robust to the number of RIMs used as well as to the number of RIMs activated per-step. Our ablation results
Sequential MNIST Resolution Task: RIMs are motivated by the hypothesis that generalization performance can benefit from modules which only activate on relevant parts of the sequence. For further evidence that RIMs can achieve this out-of-distribution, we consider the task of classifying MNIST digits as sequences of pixels
| Copying | Train(50) CE | Test(200) CE | |||
|---|---|---|---|---|---|
| RIMs | 6 | 4 | 600 | 0.00 | 0.00 |
| 6 | 3 | 600 | 0.00 | 0.00 | |
| 6 | 2 | 600 | 0.00 | 0.00 | |
| 5 | 2 | 500 | 0.00 | 0.00 | |
| LSTM | - | - | 300 | 0.00 | 4.32 |
| - | - | 600 | 0.00 | 3.56 | |
| NTM | - | - | - | 0.00 | 2.54 |
| RMC | - | - | - | 0.00 | 0.13 |
| Transformers | - | - | - | 0.00 | 0.54 |
| Sequential MNIST | 16 x 16 Accuracy | 19 x 19 Accuracy | 24 x 24 Accuracy | |||
|---|---|---|---|---|---|---|
| RIMs | 6 | 6 | 600 | 85.5 | 56.2 | 30.9 |
| 6 | 5 | 600 | 88.3 | 43.1 | 22.1 | |
| 6 | 4 | 600 | 90.0 | 73.4 | 38.1 | |
| LSTM | - | - | 300 | 86.8 | 42.3 | 25.2 |
| - | - | 600 | 84.5 | 52.2 | 21.9 | |
| EntNet | - | - | - | 89.2 | 52.4 | 23.5 |
| RMC | - | - | - | 89.58 | 54.23 | 27.75 |
| DNC | - | - | - | 87.2 | 44.1 | 19.8 |
| Transformers | - | - | - | 91.2 | 51.6 | 22.9 |
Results: Table 1 shows the result of the proposed model on the Sequential MNIST Resolution Task. If the train and test sequence lengths agree, both models achieve comparable test set performance. However, RIMs model is relatively robust to changing the sequence length (by changing the image resolution), whereas the LSTM performance degraded more severely. This can be seen as a more involved analogue of the copying task, as MNIST digits contain large empty regions. It is essential that the model be able to store information and pass gradients through these regions. The RIMs outperform strong baselines such as Transformers, EntNet, RMC, and
4.2 RIMS LEARN TO SPECIALIZE OVER OBJECTS AND GENERALIZE BETWEEN THEM
We have shown that RIMs can specialize over temporal patterns. We now turn our attention to assaying whether RIMs can specialize to objects, and show improved generalization to cases where we add or remove objects at test time.
Bouncing Balls Environment: We consider a synthetic “bouncing balls” task in which multiple balls (of different masses and sizes) move using basic Newtonian physics

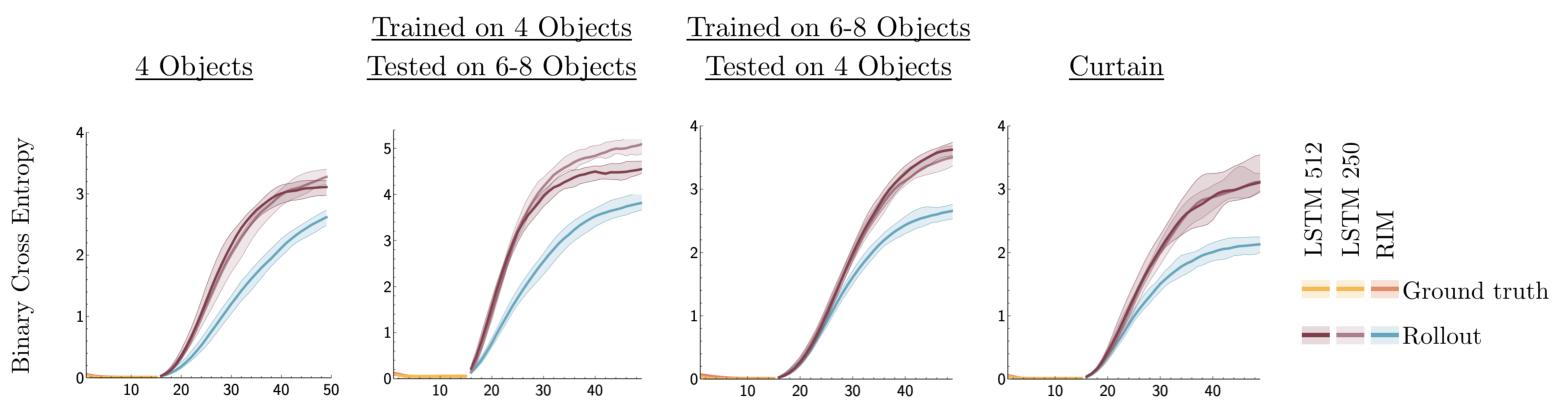
We take this further by evaluating RIMs on environments where the test setup is different from the training setup. First we consider training with 4 balls and evaluating on an environment with 6-8
balls. Second, we consider training with 6-8 balls and evaluating with just 4 balls. Robustness in these settings requires a degree of invariance w.r.t. the number of balls.
In addition, we consider a task where we train on 4 balls and then evaluate on sequences where part the visual space is occluded by a “curtain.” This allows us to assess the ability of balls to be tracked (or remembered) through the occluding region. Our experimental results on these generalization tasks
Environment with Novel Distractors: We next consider an object-picking reinforcement learning task from BabyAI
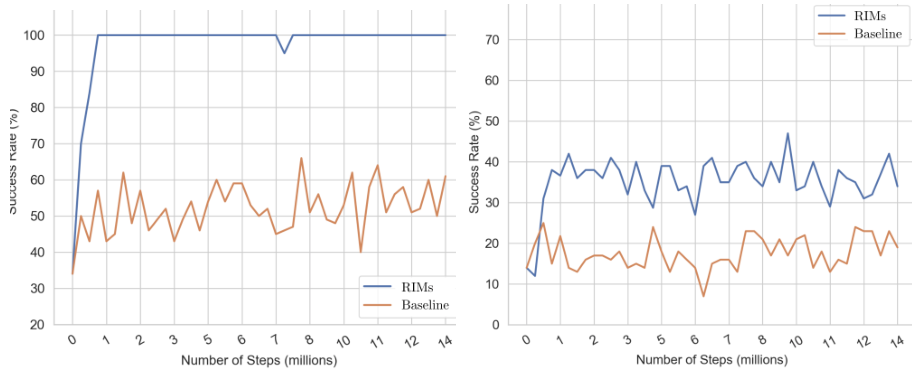
Figure 4 shows that RIMs outperform LSTMs on this task (details in appendix). When evaluating with known distractors, the RIM model achieves perfect performance while the LSTM struggles. When evaluating in an environment with novel unseen distractors the RIM doesn’t achieve perfect performance but strongly outperforms the LSTM. An LSTM with a single memory flow may struggle to keep the distracting elements separate from elements which are necessary for the task, while the RIMs model uses attention to control which RIMs receive information at each step as well as what information they receive (as a function of their hidden state). This “top-down” attention results in a diminished representation of the distractor, not only enhancing the target visual information, but also suppressing irrelevant information.
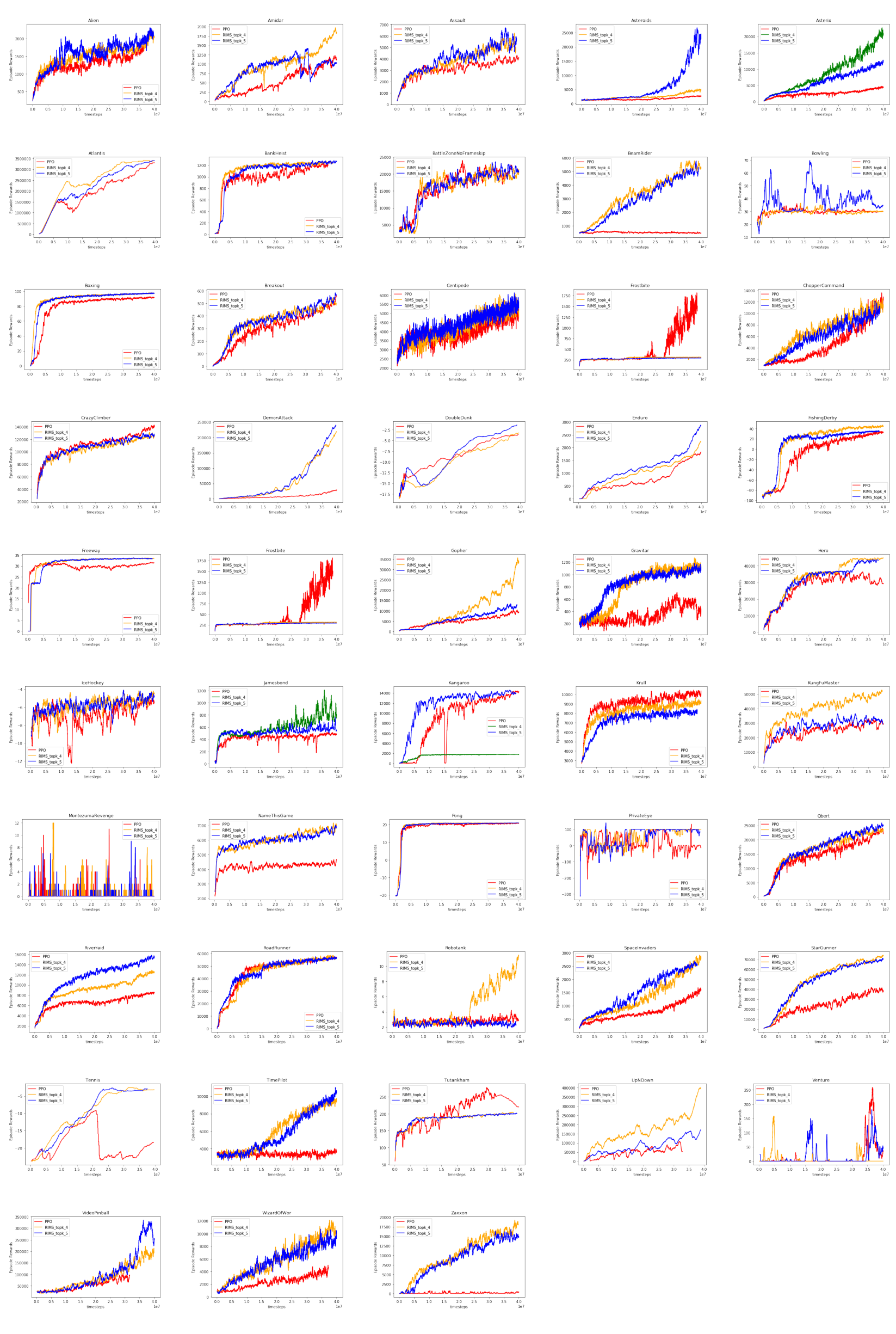
4.3 RIMS IMPROVE GENERALIZATION IN COMPLEX ENVIRONMENTS
We have investigated how RIMs use specialization to improve generalization to changing important factors of variation in the data. While these improvements have often been striking, it raises a question: what factors of variation should be changed between training and evaluation? One setting where factors of variation change naturally is in reinforcement learning, as the data received from an environment changes as the agent learns and improves. We conjecture that when applied to reinforcement learning, an agent using RIMs may be able to learn faster as its specialization leads to improved generalization to previously unseen aspects of the environment. To investigate this we use an RL agent trained using Proximal Policy Optimization (PPO)
There is also an intriguing connection between the selective activation in RIMs and the concept of affordances from cognitive psychology
hypothesize that in cases like this, selective activation of RIMs allows the agent to rapidly adapt its information processing to the types of actions relevant to the current context.
4.4 Discussion and Ablations
Sparse Activation is necessary, but works for a wide range of hyperparameters: On the copying task, we tried a wide variety of sparsity levels for different numbers of RIMs, and found that using a sparsity level between 30% to 70% performed optimally, suggesting that the sparsity hyperparameter is fairly flexible (refer to Table 4, 5 in appendix). On Atari we found that using
Input-attention is necessary: We study the scenario where we remove the input attention process (i.e the top-down competition between different RIMs) but still allow the RIMs ot communicate with attention. We found that this degraded results substantially on Atari but still outperformed the LSTM baseline. See
Communication between RIMs improves performance: For copying and sequential MNIST, we performed an ablation where we remove the communication between RIMs and varied the number of RIMs and the number of activated RIMs (Refer to Table 4 in appendix.). We found that the communication between RIMs is essential for good performance.
5 Conclusion
Many systems of interest comprise multiple dynamical processes that operate relatively independently and only occasionally have meaningful interactions. Despite this, most machine learning models employ the opposite inductive bias, i.e., that all processes interact. This can lead to poor generalization and lack of robustness to changing task distributions. We have proposed a new architecture, Recurrent Independent Mechanisms (RIMs), in which we learn multiple recurrent modules that are independent by default, but interact sparingly. For the purposes of this paper, we note that the notion of RIMs is not limited to the particular architecture employed here. The latter is used as a vehicle to assay and validate our overall hypothesis (cf. Appendix A), but better architectures for the RIMs model can likely be found.
Acknowledgements
Research Chairs, Canada Graduate Scholarship Program, Nvidia for funding, and Compute Canada for computing resources. We are very grateful to Google for giving Google Cloud credits used in this project. This project was also known by the name “Blocks” internally at Mila.
REFERENCES
Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. Neural module networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 39–48, 2016.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv, 2014.
Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks. arXiv, 2018.
Eric B Baum and David Haussler. What size net gives valid generalization? In Advances in neural information processing systems, pp. 81–90, 1989.
Yoshua Bengio. The consciousness prior. arXiv, 2017.
Yoshua Bengio, Tristan Deleu, Nasim Rahaman, Rosemary Ke, Sébastien Lachapelle, Olexa Bilaniuk, Anirudh Goyal, and Christopher Pal. A meta-transfer objective for learning to disentangle causal mechanisms. arXiv, 2019.
Léon Bottou and Patrick Gallinari. A framework for the cooperation of learning algorithms. In Advances in neural information processing systems, pp. 781–788, 1991.
Matthew Botvinick and Todd Braver. Motivation and cognitive control: from behavior to neural mechanism. Annual review of psychology, 66, 2015.
Michael M Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst. Geometric deep learning: going beyond euclidean data. IEEE Signal Processing Magazine, 34(4):18–42, 2017.
Christopher P Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guillaume Desjardins, and Alexander Lerchner. Understanding disentangling in -vae
Ricky TQ Chen, Xuechen Li, Roger B Grosse, and David K Duvenaud. Isolating sources of disentanglement in variational autoencoders. In Advances in Neural Information Processing Systems, pp. 2610–2620, 2018.
Maxime Chevalier-Boisvert and Lucas Willems. Minimalistic gridworld environment for openai gym. GitHub, 2018.
Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, and Yoshua Bengio. Babyai: First steps towards grounded language learning with a human in the loop. arXiv, 2018.
Junyoung Chung, Kyle Kastner, Laurent Dinh, Kratarth Goel, Aaron C Courville, and Yoshua Bengio. A recurrent latent variable model for sequential data. In Advances in neural information processing systems, pp. 2980–2988, 2015.
Junyoung Chung, Sungjin Ahn, and Yoshua Bengio. Hierarchical multiscale recurrent neural networks. arXiv, 2016.
Paul Cisek and John F Kalaska. Neural mechanisms for interacting with a world full of action choices. Annual review of neuroscience, 33:269–298, 2010.
Emily Denton and Rob Fergus. Stochastic video generation with a learned prior. arXiv, 2018.
Robert Desimone and Jody Duncan. Neural mechanisms of selective visual attention. Annual Review of Neuroscience, 18:193–222, 1995.
A. Dickinson. Actions and habits: the development of behavioural autonomy. Philosophical Transactions of the Royal Society B: Biological Sciences, 308(1135):67–78, 1985. ISSN 0080-4622. doi: 10.1098/rstb.1985.0010.
Salah El Hihi and Yoshua Bengio. Hierarchical recurrent neural networks for long-term dependencies. In Advances in neural information processing systems, pp. 493–499, 1996.
Chrisantha Fernando, Dylan Banarse, Charles Blundell, Yori Zwols, David Ha, Andrei A Rusu, Alexander Pritzel, and Daan Wierstra. Pathnet: Evolution channels gradient descent in super neural networks. arXiv preprint arXiv:1701.08734, 2017.
James J Gibson. The theory of affordances. Hilldale, USA, 1(2), 1977.
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 1263–1272. JMLR. org, 2017.
Anirudh Goyal, Riashat Islam, Daniel Strouse, Zafarali Ahmed, Matthew Botvinick, Hugo Larochelle, Sergey Levine, and Yoshua Bengio. Infobot: Transfer and exploration via the information bottleneck. arXiv preprint arXiv:1901.10902, 2019a.
Anirudh Goyal, Shagun Sodhani, Jonathan Binas, Xue Bin Peng, Sergey Levine, and Yoshua Bengio. Reinforcement learning with competitive ensembles of information-constrained primitives. arXiv preprint arXiv:1906.10667, 2019b.
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. arXiv preprint arXiv:1410.5401, 2014a.
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. CoRR, abs/1410.5401, 2014b. URL http://arxiv.org/abs/1410.5401.
Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka Grabska-Barwińska, Sergio Gómez Colmenarejo, Edward Grefenstette, Tiago Ramalho, John Agapiou, et al. Hybrid computing using a neural network with dynamic external memory. Nature, 538(7626):471, 2016.
David Ha and Jürgen Schmidhuber. World models. arXiv preprint arXiv:1803.10122, 2018.
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. arXiv preprint arXiv:1811.04551, 2018.
Mikael Henaff, Jason Weston, Arthur Szlam, Antoine Bordes, and Yann LeCun. Tracking the world state with recurrent entity networks. arXiv preprint arXiv:1612.03969, 2016.
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. 2016.
Geoffrey E Hinton, Sara Sabour, and Nicholas Frosst. Matrix capsules with em routing. 2018.
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8): 1735–1780, 1997.
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, Geoffrey E Hinton, et al. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991.
Yacine Jernite, Edouard Grave, Armand Joulin, and Tomas Mikolov. Variable computation in recurrent neural networks. arXiv preprint arXiv:1611.06188, 2016.
Nan Rosemary Ke, Anirudh Goyal, Olexa Bilaniuk, Jonathan Binas, Michael C Mozer, Chris Pal, and Yoshua Bengio. Sparse attentive backtracking: Temporal credit assignment through reminding. In Advances in Neural Information Processing Systems, pp. 7640–7651, 2018.
Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
Thomas Kipf, Ethan Fetaya, Kuan-Chieh Wang, Max Welling, and Richard Zemel. Neural relational inference for interacting systems. arXiv preprint arXiv:1802.04687, 2018.
Louis Kirsch, Julius Kunze, and David Barber. Modular networks: Learning to decompose neural computation. In Advances in Neural Information Processing Systems, pp. 2408–2418, 2018.
Wouter Kool and Matthew Botvinick. Mental labour. Nature human behaviour, 2(12):899–908, 2018.
Ilya Kostrikov. Pytorch implementations of reinforcement learning algorithms. GitHub, 2018.
Jan Koutnik, Klaus Greff, Faustino Gomez, and Juergen Schmidhuber. A clockwork rnn. arXiv preprint arXiv:1402.3511, 2014.
David Krueger, Tegan Maharaj, János Kramár, Mohammad Pezeshki, Nicolas Ballas, Nan Rosemary Ke, Anirudh Goyal, Yoshua Bengio, Aaron Courville, and Chris Pal. Zoneout: Regularizing rnns by randomly preserving hidden activations. arXiv preprint arXiv:1606.01305, 2016.
Shuai Li, Wanqing Li, Chris Cook, Ce Zhu, and Yanbo Gao. Independently recurrent neural network (indrnn): Building a longer and deeper rnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5457–5466, 2018.
Daniel Neil, Michael Pfeiffer, and Shih-Chii Liu. Phased lstm: Accelerating recurrent network training for long or event-based sequences. In Advances in neural information processing systems, pp. 3882–3890, 2016.
Giambattista Parascandolo, Niki Kilbertus, Mateo Rojas-Carulla, and Bernhard Schölkopf. Learning independent causal mechanisms. In Proceedings of the 35th International Conference on Machine Learning (ICML), pp. 4033–4041, 2018. URL http://proceedings.mlr.press/v80/parascandolo18a.html.
Judea Pearl. Causality: Models, Reasoning, and Inference. Cambridge University Press, New York, NY, 2nd edition, 2009.
Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. Elements of Causal Inference - Foundations and Learning Algorithms. MIT Press, Cambridge, MA, USA, 2017. ISBN 978-0-262-03731-0.
David Raposo, Adam Santoro, David Barrett, Razvan Pascanu, Timothy Lillicrap, and Peter Battaglia. Discovering objects and their relations from entangled scene representations. arXiv preprint arXiv:1702.05068, 2017.
Scott Reed and Nando De Freitas. Neural programmer-interpreters. arXiv preprint arXiv:1511.06279, 2015.
Eric Ronco, Henrik Gollee, and Peter J Gawthrop. Modular neural networks and self-decomposition. Technical Report CSC-96012, 1997.
Clemens Rosenbaum, Tim Klinger, and Matthew Riemer. Routing networks: Adaptive selection of non-linear functions for multi-task learning. arXiv preprint arXiv:1711.01239, 2017.
Clemens Rosenbaum, Ignacio Cases, Matthew Riemer, and Tim Klinger. Routing networks and the challenges of modular and compositional computation. arXiv preprint arXiv:1904.12774, 2019.
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks. arXiv preprint arXiv:1606.04671, 2016.
Adam Santoro, David Raposo, David G Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. A simple neural network module for relational reasoning. In Advances in neural information processing systems, pp. 4967–4976, 2017.
Adam Santoro, Ryan Faulkner, David Raposo, Jack W. Rae, Mike Chrzanowski, Theophane Weber, Daan Wierstra, Oriol Vinyals, Razvan Pascanu, and Timothy P. Lillicrap. Relational recurrent neural networks. CoRR, abs/1806.01822, 2018. URL arXiv.
Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model. IEEE Transactions on Neural Networks, 20(1):61–80, 2008.
Jürgen Schmidhuber. One big net for everything. arXiv preprint arXiv:1802.08864, 2018.
Bernhard Schölkopf, Dominik Janzing, Jonas Peters, Eleni Sgouritsa, Kun Zhang, and Joris Mooij. On causal and anticausal learning. In J. Langford and J. Pineau (eds.), Proceedings of the 29th International Conference on Machine Learning (ICML), pp. 1255–1262, New York, NY, USA, 2012. Omnipress.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
Herbert A Simon. The architecture of complexity. In Facets of systems science, pp. 457–476. Springer, 1991.
Shagun Sodhani, Anirudh Goyal, Tristan Deleu, Yoshua Bengio, Sergey Levine, and Jian Tang. Learning powerful policies by using consistent dynamics model. arXiv preprint arXiv:1906.04355, 2019.
Andrea Tacchetti, H Francis Song, Pedro AM Mediano, Vinicius Zambaldi, Neil C Rabinowitz, Thore Graepel, Matthew Botvinick, and Peter W Battaglia. Relational forward models for multi-agent learning. arXiv preprint arXiv:1809.11044, 2018.
Yee Teh, Victor Bapst, Wojciech M Czarnecki, John Quan, James Kirkpatrick, Raia Hadsell, Nicolas Heess, and Razvan Pascanu. Distral: Robust multitask reinforcement learning. In Advances in Neural Information Processing Systems, pp. 4496–4506, 2017.
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 5026–5033. IEEE, 2012.
Sjoerd Van Steenkiste, Michael Chang, Klaus Greff, and Jürgen Schmidhuber. Relational neural expectation maximization: Unsupervised discovery of objects and their interactions. arXiv preprint arXiv:1802.10353, 2018.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pp. 5998–6008, 2017.
H. L. F. von Helmholtz. Handbuch der physiologischen Optik, volume III. Voss, 1867.
Erich von Holst and Horst Mittelstaedt. Das reafferenzprinzip. Naturwissenschaften, 37(20):464–476, Jan 1950. doi: 10.1007/BF00622503.
Nicholas Watters, Daniel Zoran, Theophane Weber, Peter Battaglia, Razvan Pascanu, and Andrea Tacchetti. Visual interaction networks: Learning a physics simulator from video. In Advances in neural information processing systems, pp. 4539–4547, 2017.
Ronald J Williams and David Zipser. A learning algorithm for continually running fully recurrent neural networks. Neural computation, 1(2):270–280, 1989.
Appendix
Table of Contents
- A Desiderata for Recurrent Independent Mechanisms
- B Extended Related Work
- C Model Setup Details and Hyperparameters
- C.1 RIMs Implementation
- C.2 Detailed Model Hyperparameters
- C.3 Other Architectural Changes that we Explored
- D Experiment Details
- D.1 Effect of Varying Number and Active RIMs on Copying Task
- D.2 Effect of Varying Number and Active RIMs on Adding Task
- D.3 Sequential MNIST Resolution Task
- D.4 Bouncing Ball Environment
- D.5 Video Prediction from Crops
- D.6 Environment with Novel Distractors
- D.7 MiniGrid Environments for OpenAI Gym
- D.8 Atari
- E Additional Experiments
- E.1 Imitation Learning: Robustness to Noise in State Distribution
- E.2 Transfer on Atari
- E.3 Bouncing MNIST: Dropping individual RIMs
- F Natural Language Processing: Language Modeling, Machine Translation, and Transfer Learning
A Desiderata for Recurrent Independent Mechanisms
We have laid out a case for building models composed of modules which by default operate independently and can interact in a limited manner. Accordingly, our approach to modelling the dynamics of the world starts by dividing the overall model into small subsystems (or modules), referred to as Recurrent Independent Mechanisms (RIMs), with distinct functions learned automatically from data. Our model encourages sparse interaction, i.e., we want most RIMs to operate independently and follow their default dynamics most of the time, only rarely sharing information. Below, we lay out desiderata for modules to capture modular dynamics with sparse interactions.
Competitive Mechanisms: Inspired by the observations in the main paper, we propose that RIMs utilize competition to allocate representational and computational resources. As argued by
Top Down Attention: The points mentioned in Section 2 in principle pertain to synthetic and natural intelligent systems alike. Hence, it is not surprising that they also appear in neuroscience. For instance, suppose we are looking for a particular object in a large scene, using limited processing capacity. The biased competition theory of selective attention conceptualizes basic findings of experimental psychology and neuroscience
enables us to selectively devote resources to input information that may be of particular interest or relevance. This may be accomplished by units matching the internal model of an object or process of interest being pre-activated and thus gaining an advantage during the competition of brain mechanisms.
Sparse Information Flow: Each RIM’s dynamics should only be affected by RIMs which are deemed relevant. The fundamental challenge is centered around establishing sensible communication between modules. In the presence of noisy or distracting information, a large subset of RIMs should stay dormant, and not be affected by the noise. This way, training an ensemble of these RIMs can be more robust to out-of-distribution or distractor observations than training one big homogeneous neural network
Modular Computation Flow and Modular Parameterization: Each RIM should have its own dynamics operating by default, in the absence of interaction with other RIMs. The total number of parameters (i.e. weights) can be reduced since the RIMs can specialize on simple sub-problems, similar to
B EXTENDED RELATED WORK
Table 2: A concise comparison of recurrent models with modular memory.
| Method / Property | Modular Memory | Sparse Information Flow | Modular Computation Flow | Modular Parameterization |
|---|---|---|---|---|
| LSTM / RNN | ✗ | ✗ | ✗ | ✗ |
| Relational RNN (Santoro et al., 2018) | ✓ | ✗ | ✓ | ✗ |
| NTM (Graves et al., 2014b) | ✓ | ✓ | ✗ | ✗ |
| SAB (Ke et al., 2018) | ✗ | ✓ | ✗ | ✗ |
| IndRNN (Li et al., 2018) | ✓ | ✗ | ✗ | ✓ |
| RIMs | ✓ | ✓ | ✓ | ✓ |
The present section provides further details on related work, thus extending Section 3.
Neural Turing Machine (NTM). The NTM
Relational RNN. The Relational Models paper
Sparse Attentive Backtracking (SAB). The SAB architecture
Independently Recurrent Neural Network (IndRNN). The IndRNN
Consciousness Prior
Recurrent Entity Networks: EnTNet
Capsules and Dynamic Routing: EM Capsules
Relational Graph Based Methods: Recent graph-based architectures have studied combinatorial generalization in the context of modeling dynamical systems like physics simulation, multi-object scenes, and motion-capture data, and multiagent systems
Default Behaviour: Our work is also related to work in behavioural research that deals with two modes of decision making
C Model Setup Details and Hyperparameters
C.1 RIMs Implementation
The RIMs model consists of three main components: the input attention, the process for selecting activated RIMs, and the communication between RIMs. The input attention closely follows the attention mechanism of
For selecting activated RIMs, we compute the top-k attention weight over the RIMs (based on the query). We then select the activated RIMs, using a mask which zeroes out the outputs from inactive RIMs. We compute the independent dynamics over all RIMs by using a separate LSTM for each RIM. Following this, we compute the communication between RIMs as a multihead attention
The use of RIMs introduces two additional hyperparameters over an LSTM/GRU: the number of RIMs and the number of activated RIMs per step. We also observed that having too few activated RIMs tends to hurt
optimization and having too many activated RIMs attenuates the improvements to generalization. For the future it would be interesting to explore dynamic ways of controlling how many RIMs to activate.
Multiple Heads: Analogously to
Selective Activation. In order to selectively decide which set of RIMs to activate, we also tried appending a vector of zeros to the input representation, and the RIMs, which pay least attention to the null input (in the input attention) are activated.
C.2 Detailed Model Hyperparameters
Table 3 lists the different hyperparameters.
| Parameter | Value |
|---|---|
| Optimizer | Adam(Kingma & Ba, 2014) |
| learning rate | |
| batch size | 64 |
| Input keys | 64 |
| Input Values | Size of individual RIM * 4 |
| Input Heads | 4 |
| Input Dropout | 0.1 |
| Communication keys | 32 |
| Communication Values | 32 |
| Communication heads | 4 |
| Communication Dropout | 0.1 |
C.3 Other Architectural Changes That We Explored
We have not conducted systematic optimizations of the proposed architecture. We believe that even principled hyperparameter tuning may significantly improve performance for many of the tasks we have considered in the paper. We briefly mention a few architectural changes which we have studied:
- On the output side, we concatenate the representations of the different RIMs, and use the concatenated representation for learning a policy (in RL experiments) or for predicting the input at the next time step (for bouncing balls as well as all other experiments). We empirically found that adding another layer of (multi-headed) key-value attention on the output seems to improve the results. We have not included this change in the RIMs implementation of this paper.
- In our experiments, we shared the same decoder for all the RIMs, i.e., we concatenate the representations of different RIMS, and feed the concatenated representations to the decoder. In the future it would be interesting to think of ways to allow a more “structured” decoder. The reason for this is that even if the RIMs generalize to new environments, the shared decoder can fail to do so. So changing the structure of decoder could be helpful.
- For the RL experiments, we also tried providing the previous actions, rewards, language instruction as input to decide the activation of RIMs. This is consistent with the idea of efference copies as proposed by
von Helmholtz (1867); von Holst & Mittelstaedt (1950) von Helmholtz, and von Holst and Mittelstaedt , i.e., using copies of motor signals as inputs. Preliminary experiments shows that this improves the performance in Atari games.
D Experiment Details
D.1 Effect of Varying Number and Active RIMs on Copying Task
We used a learning rate of 0.001 with the Adam Optimizer and trained each model for 150 epochs (unless the model was stuck, we found that this was enough to bring the training error close to zero). For the RIMs model
we used 600 units split across 6 RIMs (100 units per block). For the LSTM we used a total of 600 units. We did not explore this extensively but we qualitatively found that the results on copying were not very sensitive to the exact number of units.
The sequences to be copied first have 10 random digits (from 0-8), then a span of zeros of some length, followed by a special indicator “9” in the input which instructs the model to begin outputting the copied sequence.
In our experiments, we trained the models with “zero spans” of length 50 and evaluated on the model with “zero spans” of length 200. We note that all the ablations were run with the default parameters (i.e number of keys, values as for RIMs model) for 100 epochs. Table 4 shows the effect of two baselines as compared to the RIMs model (a) When we allow the input attention for activation of different RIMs but we dont allow different RIMs to communicate. (b) No Input attention, but we allow different RIMs to communicate with each other. Table 4 shows that the proposed method is better than both of these baselines. For copy task, we used 1 head in input attention, and 4 heads for RIMs communication. We note that even with 1 RIM, its not exactly same as a LSTM, because each RIM can still reference itself.
Table 4: Error (CE for last 10 time steps) on the copying task. Note that while all of the methods are able to learn to copy on the length seen during training, the RIMs model generalizes to sequences longer than those seen during training whereas the LSTM fails catastrophically.
| Approach | Train Length 50 | Test Length 200 |
|---|---|---|
| RIMs | 0.00 | 0.00 |
| With input Attention and No Communication | ||
| RIMs () | 2.3 | 1.6 |
| RIMs () | 1.7 | 4.3 |
| RIMs () | 2.5 | 4,7 |
| RIMs () | 0.4 | 4.0 |
| RIMs () | 0.2 | 0.7 |
| RIMs () | 3.3 | 2.4 |
| RIMs () | 1.2 | 1.0 |
| RIMs () | 0.7 | 5.0 |
| RIMs () | 0.22 | 0.56 |
| With No input Attention and Full Communication | ||
| RIMs () | 0.0 | 0.7 |
| RIMs () | 0.0 | 1.7 |
| RIMs () | 0.0 | 2.9 |
| RIMs () | 0.0 | 1.8 |
| RIMs () | 0.0 | 0.2 |
| With input Attention and Full Communication | ||
| RIMs () | 0.24 | 0.15 |
| RIMs () | 0.01 | 0.00 |
| RIMs () | 0.01 | 0.00 |
| RIMs () | 0.01 | 0.00 |
| RIMs () | 0.01 | 0.01 |
| RIMs () | 0.04 | 0.07 |
| RIMs () | 0.00 | 0.10 |
| RIMs () | 0.03 | 0.24 |
| RIMs () | 0.05 | 0.02 |
| RIMs () | 0.00 | 0.00 |
| RIMs () | 0.00 | 0.00 |
| RIMs () | 0.00 | 0.00 |
| RIMs () | 0.00 | 0.00 |
| RIMs () | 0.01 | 0.26 |
| RIMs () | 0.01 | 0.00 |
| RIMs () | 0.00 | 0.00 |
| RIMs () | 0.00 | 0.00 |
| RIMs () | 0.00 | 0.00 |
| RIMs () | 0.00 | 0.42 |
D.2 EFFECT OF VARYING NUMBER AND ACTIVE RIMS ON ADDING TASK
In the adding task we consider a stream of numbers as inputs (given as real-values) and then indicate which two numbers should be added together as a set of two input streams which varies randomly between examples. The length of the input sequence during testing is longer than during training. This is a simple test of the model’s ability to ignore the numbers which it is not tasked with adding together. We provide the results in Table 5 which demonstrates that proposed model generalize better for longer testing sequences as well as adding multiple numbers. We ran the proposed model with different configurations like changing number of RIMs as well as number of active RIMs.
Table 5: Error CE on the adding task.
| Approach | Train Length 50 | Test Length 200 |
|---|---|---|
| With input Attention and Full Communication | ||
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| Approach | Train Length 500 | Test Length 1000 |
| With input Attention and Full Communication | ||
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
| RIMs () | 0.0 | 0.0 |
D.3 SEQUENTIAL MNIST RESOLUTION TASK
In this task we considered classifying binary MNIST digits by feeding the pixels to an RNN (in a fixed order scanning over the image). As the focus of this work is on generalization, we introduced a variant on this task where the training digits are at a resolution of
D.4 BOUNCING BALL ENVIRONMENT
We use the bouncing-ball dataset from

D.4.1 DIFFERENT RIMS ATTEND TO DIFFERENT BALLS
In order to visualize what each RIM is doing, we associate each RIM with a different encoder. By performing spatial masking on the input, we can control the possible spatial input to each RIM. We use six non-overlapping horizontal strips and allow only 4 RIMs to be active at a time
D.4.2 COMPARISON WITH LSTM BASELINES
In Figures 7, 8, 9, and 10 we highlight different baselines and how these compare to the proposed RIMs model.
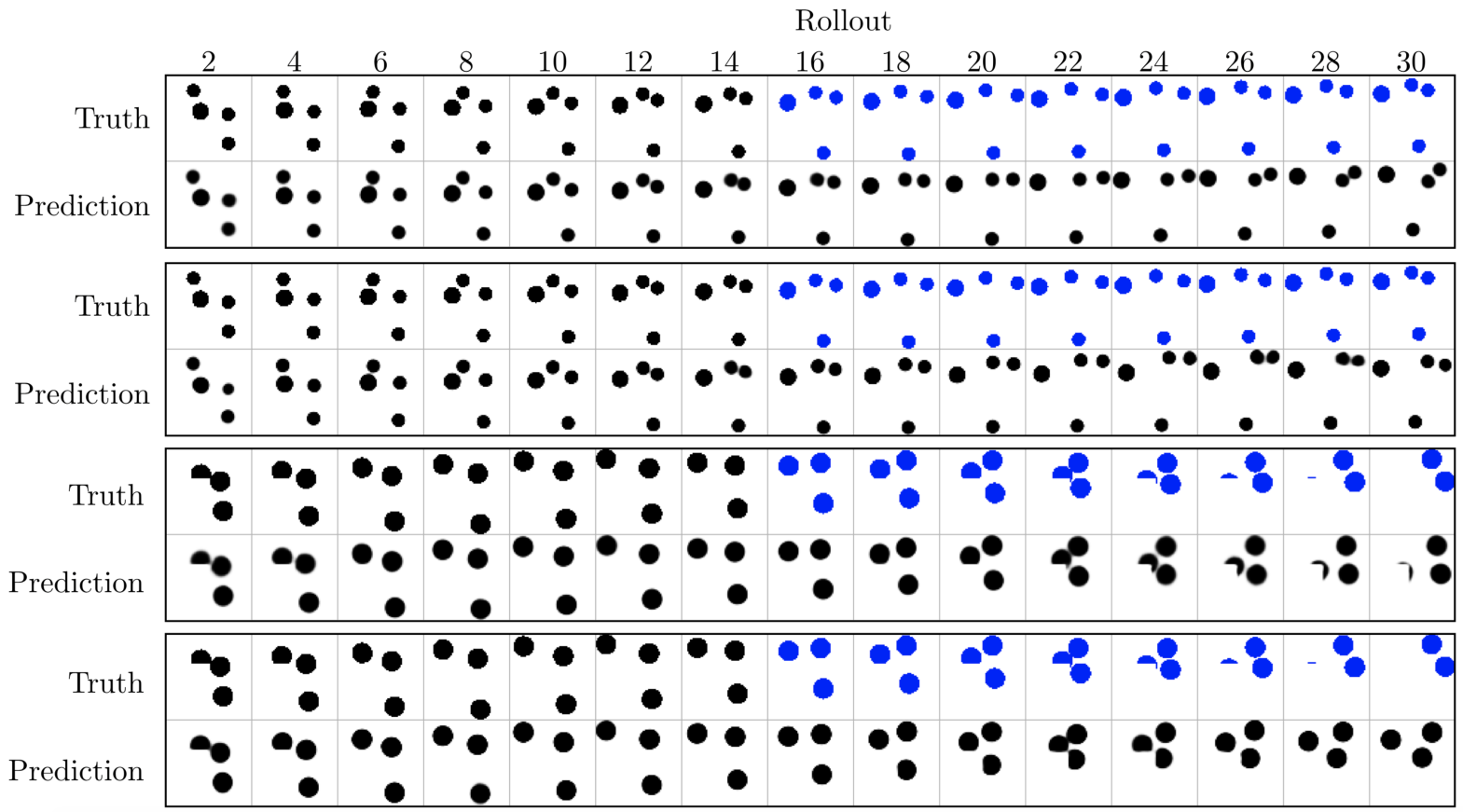
D.4.3 OCCLUSION
In Fig. 11, we show the performance of RIMs on the curtain dataset. We find RIMs are able to track balls through the occlusion without difficulty. Note that the LSTM baseline, is also able to track the ball through the “invisible” curtain.
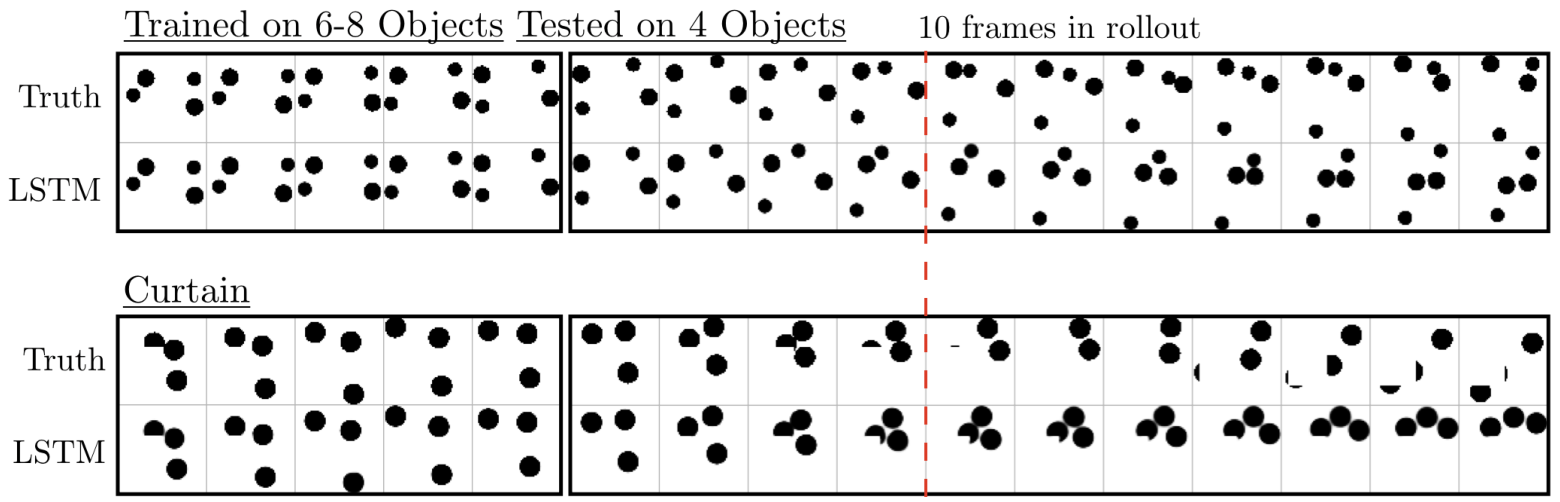
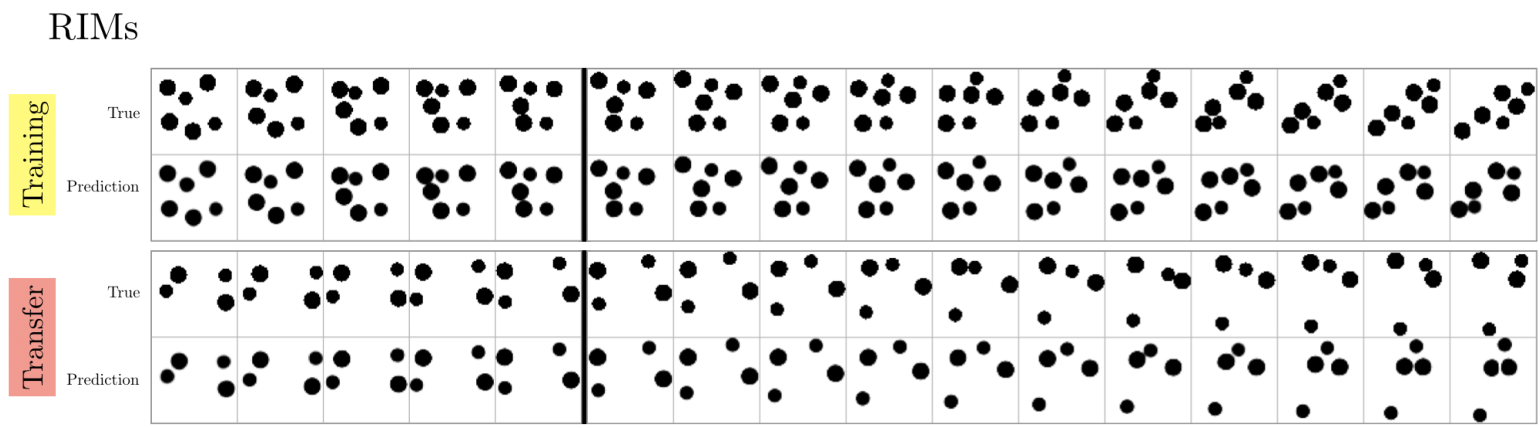
D.4.4 STUDY OF TRANSFER
It is interesting to ask how models trained on a dataset with 6-8 balls perform on a dataset with 4 balls. In Fig. 12 we show predictions during feed-in and rollout phases.
Preprint


D.5 VIDEO PREDICTION FROM CROPS
Dataset. We train all models on a training dataset of 20K video sequences with 100 frames of 3 balls bouncing in an arena of size
Preprint

Training. We train all models until the validation loss is saturated, and select the best of three runs. During training, we automatically decay the learning rate by a factor of 2 if the validation loss does not significantly decrease by at least 0.01% for five consecutive epochs.
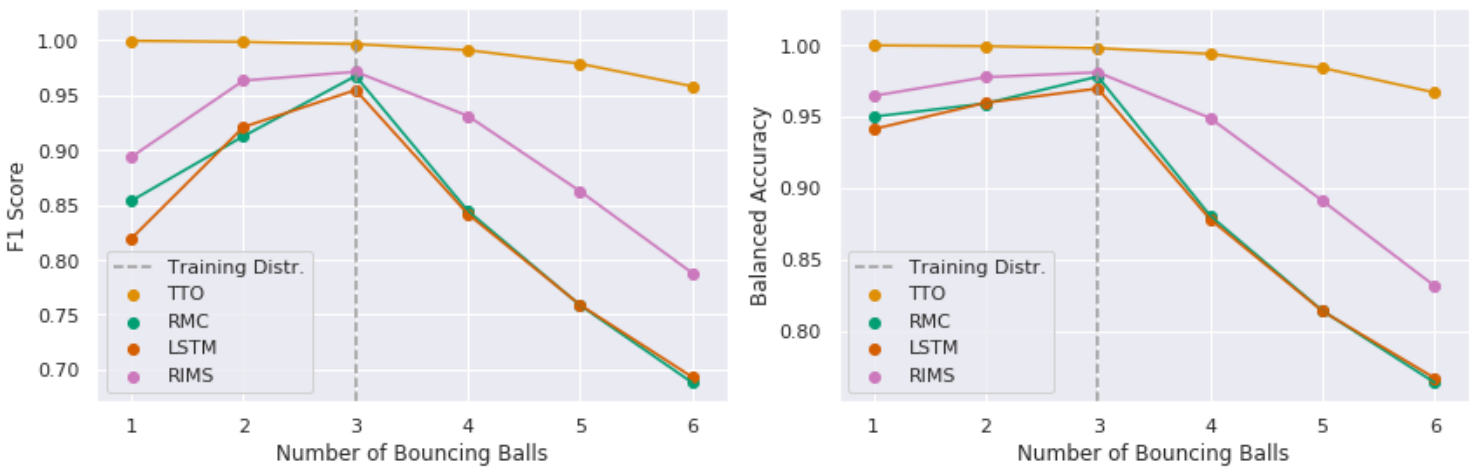
Evaluation Criteria. After having trained on the training dataset with 3 bouncing balls, we evaluate the performance on all test datasets with 1 to 6 bouncing balls. In Figure 13, we report the balanced accuracy (i.e. arithmetic mean of recall and specificity) and F1-scores (i.e. harmonic mean of precision and recall) to account for class-imbalance
Results. In Figure 13, we see that proposed method out-perform all non-oracle baselines OOD on the one-step forward prediction task and strike a good balance in regard to in-distribution and OOD performance.
Baselines: We compared the performance of the proposed method with a baseline LSTM model, as well as state of the art memory model,
D.6 ENVIRONMENT WITH NOVEL DISTRACTORS
We evaluate the proposed framework using Adavantage Actor-Critic (A2C) to learn a policy
For the maze environments, we use A2C with 48 parallel workers. Our actor network and critic networks consist of two and three fully connected layers respectively, each of which have 128 hidden units. The encoder network is also parameterized as a neural network, which consists of 1 fully connected layer. We use RMSProp with an initial learning rate of 0.0007 to train the models. Due to the partially observable nature of the environment, we further use a LSTM to encode the state and summarize the past observations.
D.7 MINIGRID ENVIRONMENTS FOR OPENAI GYM
The MultiRoom environments used for this research are part of MiniGrid, which is an open source gridworld package. This package includes a family of reinforcement learning environments compatible with the OpenAI Gym framework. Many of these environments are parameterizable so that the difficulty of tasks can be adjusted (e.g., the size of rooms is often adjustable).
D.7.1 THE WORLD
In MiniGrid, the world is a grid of size NxN. Each tile in the grid contains exactly zero or one object. The possible object types are wall, door, key, ball, box and goal. Each object has an associated discrete color, which can be one of red, green, blue, purple, yellow and grey. By default, walls are always grey and goal squares are always green.
D.7.2 REWARD FUNCTION
Rewards are sparse for all MiniGrid environments. In the MultiRoom environment, episodes are terminated with a positive reward when the agent reaches the green goal square. Otherwise, episodes are terminated with zero reward when a time step limit is reached. In the FindObj environment, the agent receives a positive reward if it reaches the object to be found, otherwise zero reward if the time step limit is reached.
The formula for calculating positive sparse rewards is
D.7.3 ACTION SPACE
There are seven actions in MiniGrid: turn left, turn right, move forward, pick up an object, drop an object, toggle and done. For the purpose of this paper, the pick up, drop and done actions are irrelevant. The agent can use the turn left and turn right action to rotate and face one of 4 possible directions (north, south, east, west). The move forward action makes the agent move from its current tile onto the tile in the direction it is currently facing, provided there is nothing on that tile, or that the tile contains an open door. The agent can open doors if they are right in front of it by using the toggle action.

D.7.4 Observation Space
Observations in MiniGrid are partial and egocentric. By default, the agent sees a square of
D.7.5 Level Generation
The level generation in this task works as follows: (1) Generate the layout of the map
We follow the same architecture as
D.7.6 Additional Ablation
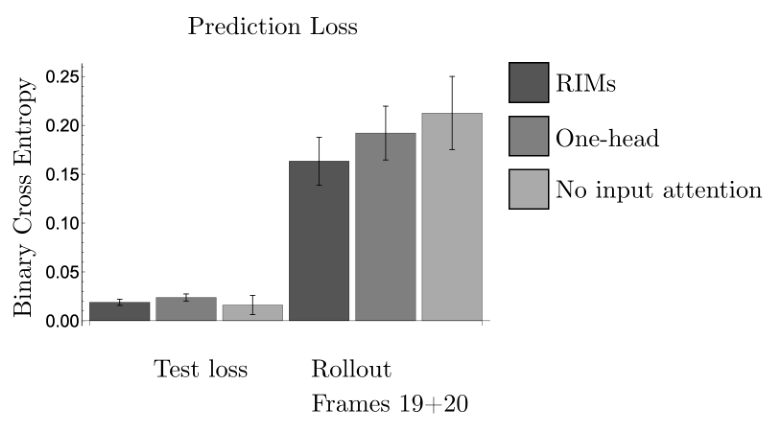
We present one ablation in addition to the ones in Section 4.4. In this experiment, we study the effect on input attention
In Fig. 16, we show the predictions that result from the model with only one active head.
D.8 Atari
We used open-source implementation of PPO from
E ADDITIONAL EXPERIMENTS
E.1 IMITATION LEARNING: ROBUSTNESS TO NOISE IN STATE DISTRIBUTION
Here, we consider imitation learning where we have training trajectories generated from an expert
Table 6: Imitation Learning: Results on the half-cheetah imitation learning task. RIMs outperforms a baseline LSTM when we evaluate with perturbations not observed during training (left). An example of an input image fed to the model (right).
| Method / Setting | Training Observed Reward | Perturbed States Observed Reward |
|---|---|---|
| LSTM (Recurrent Policy) | ||
| RIMs () | ||
| RIMs () | ||
| RIMs (without Input attention) |

We use the convolutional network from
E.2 TRANSFER ON ATARI
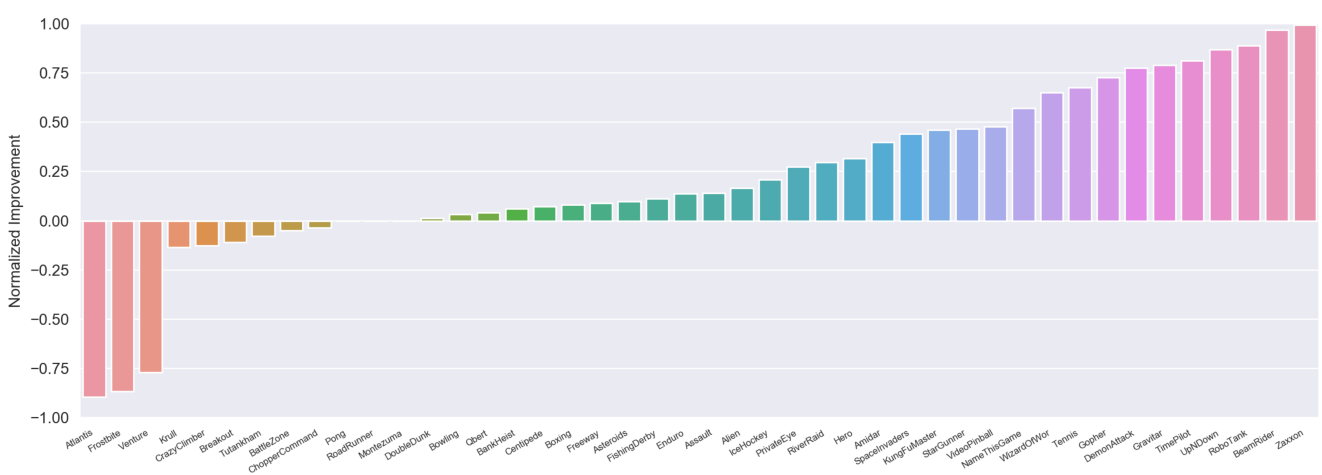
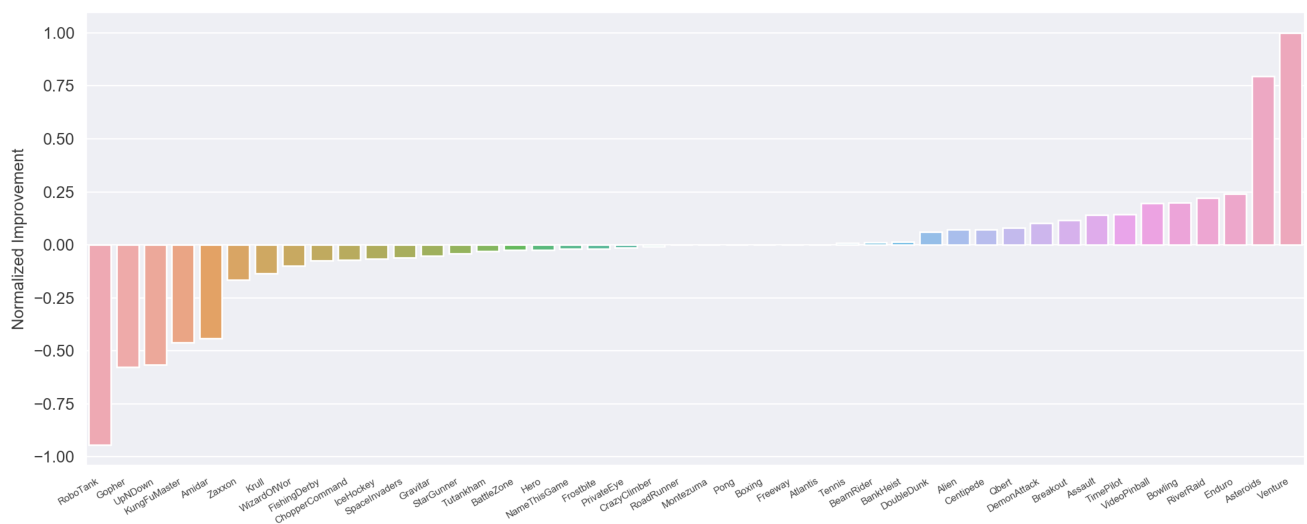
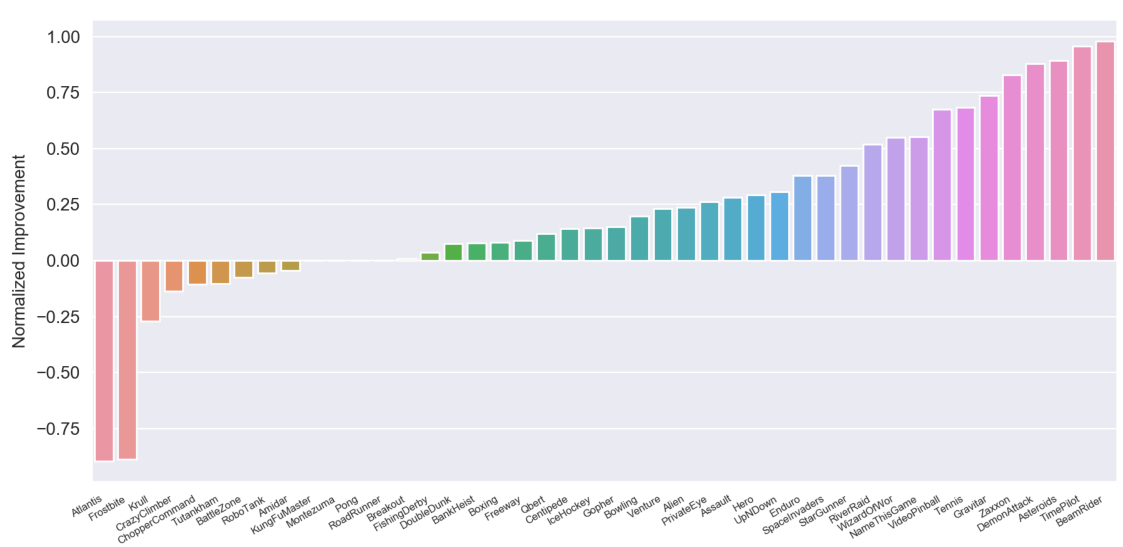
As a very preliminary result, we investigate feature transfer between randomly selected Atari games. In order to study this question, we follow the experimental protocol of
We start by training RIMs on three source games (Pong, River Raid, and Seaquest) and test if the learned features transfer to a different subset of randomly selected target games (Alien, Asterix, Boxing, Centipede, Gopher, Hero, James Bond, Krull, Robotank, Road Runner, Star Gunner, and Wizard of Wor). We observe, that RIMs result in positive transfer in 9 out of 12 target games, with three cases of negative transfer. On the other hand
| Environment | LSTM-PPO | RIMs-PPO |
|---|---|---|
| Alien | ||
| Amidar | ||
| Assault | ||
| Asterix | ||
| Asteroids | ||
| Atlantis | ||
| BankHeist | ||
| BattleZone | ||
| BeamRider | ||
| Bowling | ||
| Boxing | ||
| Breakout | ||
| Centipede | ||
| ChopperCommand | ||
| CrazyClimber | ||
| DemonAttack | ||
| DoubleDunk | ||
| Enduro | ||
| FishingDerby | ||
| Freeway | ||
| Gopher | ||
| Gravitar | ||
| IceHockey | ||
| Jamesbond | ||
| Kangaroo | ||
| Krull | ||
| KungFuMaster | ||
| NameThisGame | ||
| Pong | ||
| PrivateEye | ||
| Qbert | ||
| Riverraid | ||
| RoadRunner | ||
| Robotank | ||
| SpaceInvaders | ||
| StarGunner | ||
| TimePilot | ||
| UpNDown | ||
| VideoPinball | ||
| WizardOfWor | ||
| Zaxxon |
progressive networks
E.2.1 ATARI RESULTS: COMPARISON WITH LSTM-PPO
E.2.2 ATARI RESULTS: NO INPUT ATTENTION
Here we compare the proposed method to the baseline, where we dont use input attention, and we force different RIMs to communicate with each at all the time steps.
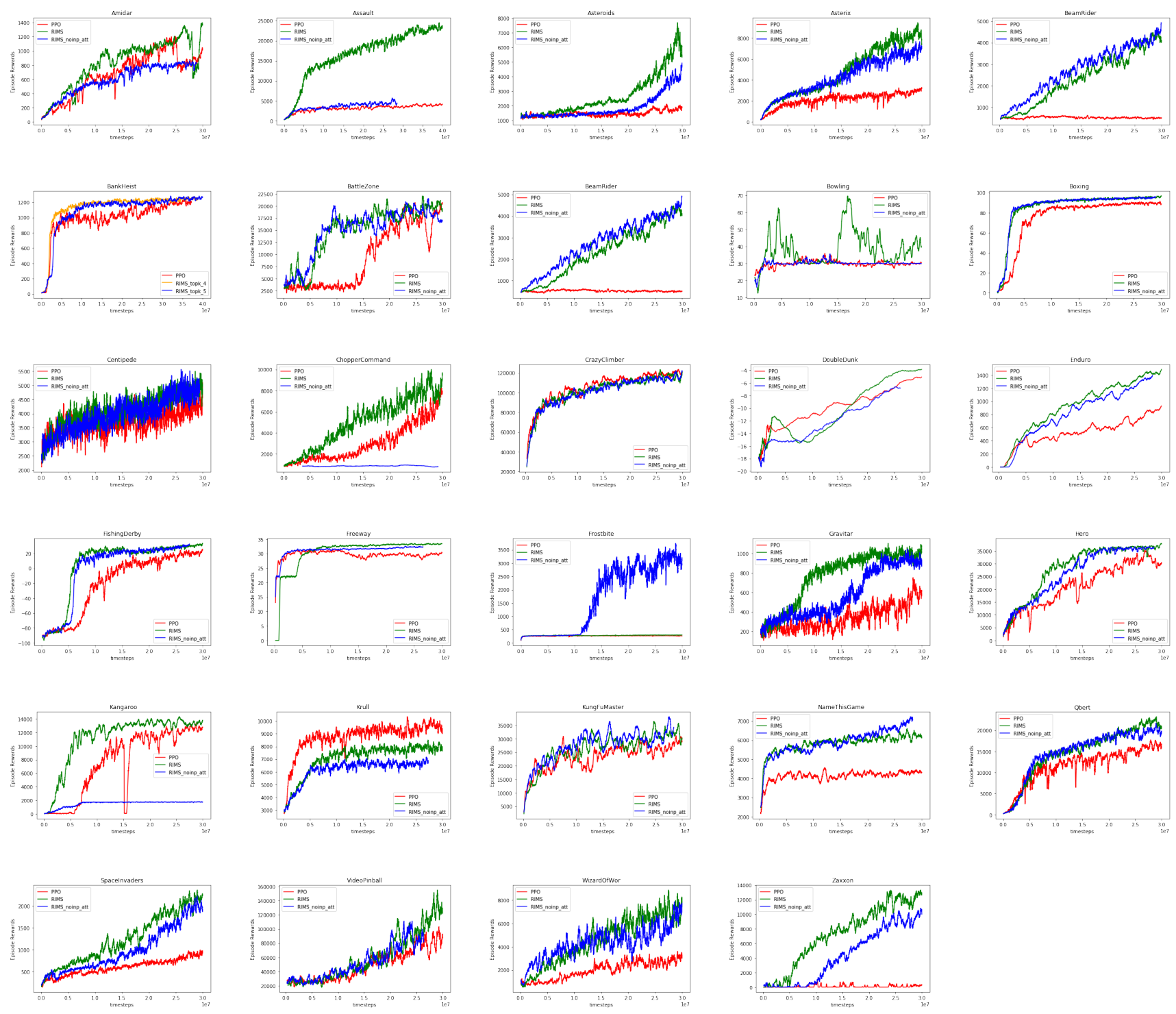
Table 8: Transfer from WMT to IWSLT (en
| Training Data | (Vanilla) Transformer | LSTM | RIMs |
|---|---|---|---|
| en de | 22.89 | 21.32 | 23.71 |
| en de, en fr | 22.92 | 20.37 | 24.23 |
E.3 Bouncing MNIST: Dropping Individual RIMs
We use the Stochastic Moving MNIST
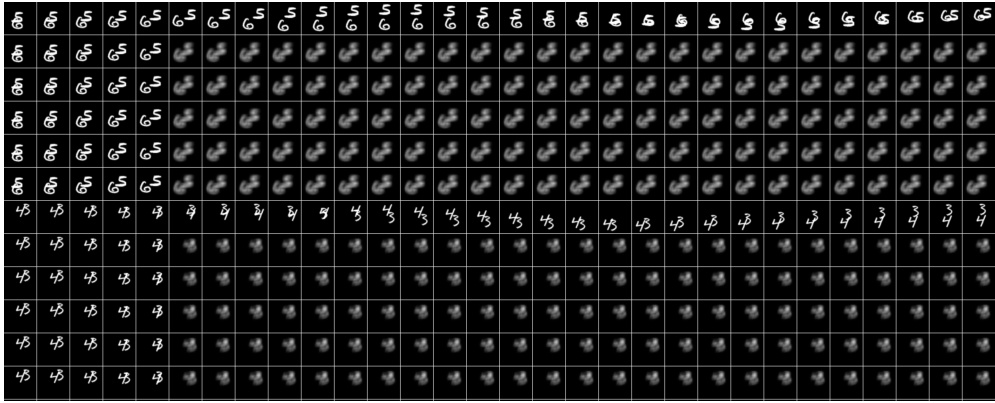
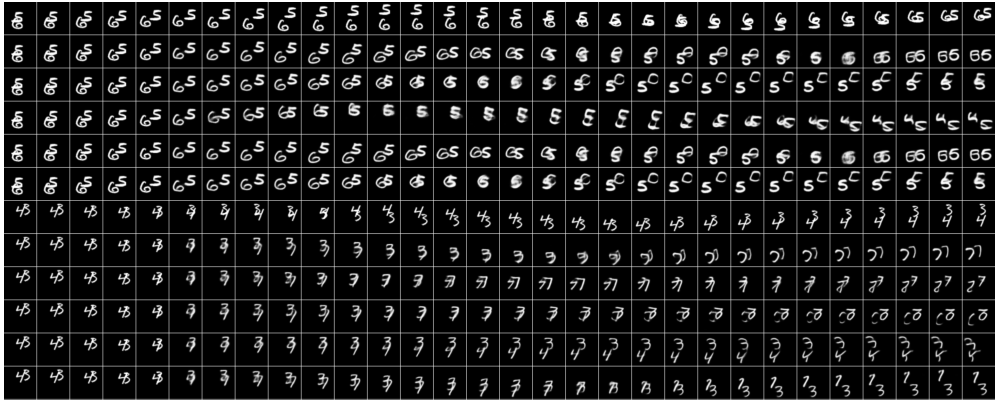
Here, we show the effect of masking out a particular RIM and study the effect of the masking on the ensemble of RIMs. Ideally, we would want different RIMs not to co-adapt with each other. So, masking out a particular RIM should not really effect the dynamics of the entire model. We show qualitative comparisons in Fig. 21, 22, 23, 24, 25. In each of these figures, the model gets the ground truth image as input for first 5 time steps, and then asked to simulate the dynamics for next 25 time-steps. We find that sparsity is needed otherwise different RIMs co-adapt with each other
F Natural Language Processing: Language Modeling, Machine Translation, and Transfer Learning
We performed some additional experiments to evaluate how well RIMs improve transfer learning on some widely studied NLP datasets.
We performed an additional experiment where we trained a seq2seq model on the WMT machine translation dataset and evaluated on the IWSLT14 dataset (English to German). WMT consists of European Parliament text and news articles, whereas IWSLT14 consists of transcribed spoken text (for example, TED talks). Thus the two datasets are in the same general domain but have fairly distinct content distributions. Additionally, we considered either training the WMT model on both English to German and English to French (with shared encoders but separate decoders) or only on English to German. The results are in Table 8. The LSTM and RIMs models used have a comparable number of parameters in this experiment. We note that the multi-task training setup substantially hurts the performance of the LSTM baseline, but helps performance when using RIMs (the performance of the transformer is about the same in both settings).










Footnotes
-
Note that we are overloading the term mechanism, using it both for the mechanisms that make up the world’s dynamics as well as for the computational modules that we learn to model those mechanisms. The distinction should be clear from context. ↩