Recurrent Memory Transformer
Neural Networks and Deep Learning Lab, Moscow Institute of Physics and Technology, Dolgoprudny, Russia
AIRI, Moscow, Russia
Abstract
Transformer-based models show their effectiveness across multiple domains and tasks. The self-attention allows to combine information from all sequence elements into context-aware representations. However, global and local information has to be stored mostly in the same element-wise representations. Moreover, the length of an input sequence is limited by quadratic computational complexity of self-attention. In this work, we propose and study a memory-augmented segment-level recurrent Transformer (RMT). Memory allows to store and process local and global information as well as to pass information between segments of the long sequence with the help of recurrence. We implement a memory mechanism with no changes to Transformer model by adding special memory tokens to the input or output sequence. Then the model is trained to control both memory operations and sequence representations processing. Results of experiments show that RMT performs on par with the Transformer-XL on language modeling for smaller memory sizes and outperforms it for tasks that require longer sequence processing. We show that adding memory tokens to Tr-XL is able to improve its performance. This makes Recurrent Memory Transformer a promising architecture for applications that require learning of long-term dependencies and general purpose in memory processing, such as algorithmic tasks and reasoning.
1 Introduction
Transformers
input sequence length that hurts its applications to long inputs
Our work introduces a memory-augmented segment-level recurrent Transformer named Recurrent Memory Transformer (RMT). RMT uses a memory mechanism based on special memory tokens
We tested RMT on the tasks that require global information about the whole input sequence to be solved. We use copy, reverse, and associative retrieval tasks in the setting where the input sequence is split into segments. RMT and Transformer-XL perfectly solve these tasks, but exceeding some value of sequence length, RMT starts to outperform Transformer-XL. Also, we experimentally show that the proposed Recurrent Memory Transformer requires less memory size to perform closely to Transformer-XL on language modeling tasks. RMT code and experiments are available1.
Contributions
- In this study we augment Transformer with token based memory storage and segment-level recurrence.
- We experimentally evaluate proposed architecture as well as vanilla Transformer and Transformer-XL on memory-intensive tasks such as copy, reverse, associative retrieval, and language modeling. We show that RMT outperforms Transformer-XL for sequence processing tasks and on par with Transformer-XL on language modeling but requires less memory.
- We show that Tr-XL cache could be combined with RMT leading to better performance on language modeling.
- We analysed how the Transformer model learns to use memory. Specific interpretable memory read-write patterns of attention are shown.
2 Related work
In our study we add a memory to general purpose attention based neural architecture. Memory is a recurrent topic in neural networks research. It had started from the early works
The recent rise of Transformer models also resulted in introduction of a number of new memory architectures. Transformer-XL
In many variations of Transformer different sorts of global representations are added. Among them are Star-Transformer
Segment-level recurrence in Transformers is actively explored in a number of studies. Transformer-XL, Compressive Transformer keep previous states and re-use them in subsequent segments. Ernie-Doc
3 Recurrent Memory Transformer
Transformer-XL
here, SG stands for stop-gradient,
Then,
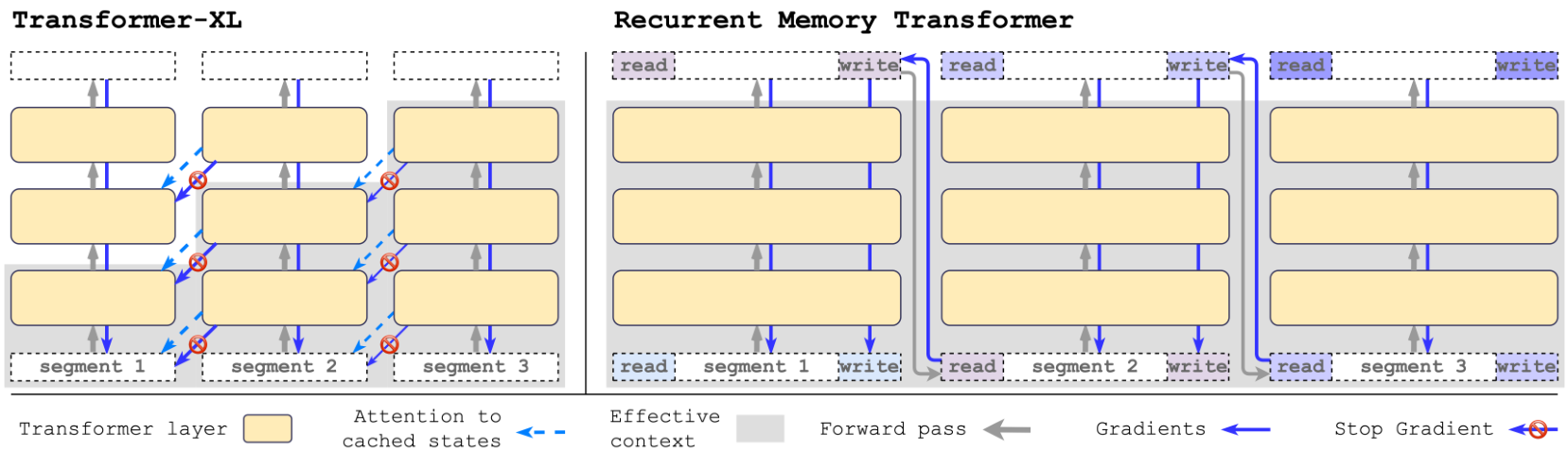
In Transformer-XL, self-attention layers are modified to use relative position encodings to improve generalization to longer attention lengths. The overall architecture is shown in the Figure 2.
Memory augmented Transformers such as GMAT, ETC, Memory Transformer
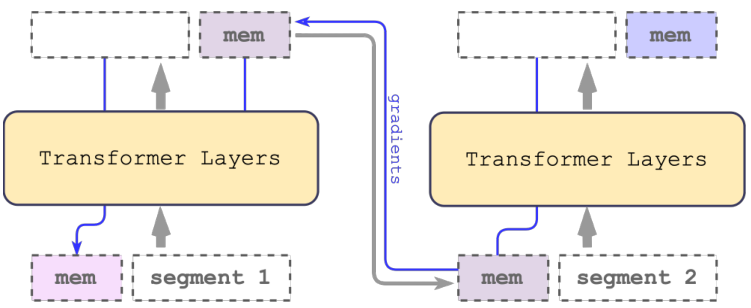
for representations. Usually, memory tokens are added to the beginning of the input sequence. However, in decoder-only architectures the causal attention mask makes impossible for memory tokens at the start of the sequence to collect information from the subsequent tokens. On the other hand, if memory tokens are placed at the end of the sequence then preceding tokens unable to access their representations. To solve this problem we add a recurrence to the sequence processing. Representations of memory tokens placed at the end of the segment are used as an input memory representations at the start as well as at the end of the next segment.
In the Recurrent Memory Transformer input is augmented with special [mem] tokens, processed in a standard way along with the sequence of tokens. Each memory token is a real-valued vector.
here
The starting group of memory tokens functions as a read memory that allows sequence tokens to attend to memory states produced at the previous segment. The ending group works as a write memory that can attend to all current segment tokens and update representation stored in the memory. As a result,
Segments of the input sequence are processed sequentially. To enable recurrent connection between segments, we pass outputs of the memory tokens from the current segment to the input of the next segment:
Both memory and recurrence in the RMT are based only on global memory tokens. It allows to keep the backbone Transformer unchanged and make RMT memory augmentation compatible with any model from the Transformer family. Memory tokens operate only on the input and output of the model. In this study we implement RMT on top of the original Transformer-XL code. Both architectures are shown in Figure 2.
Recurrence in the RMT is different compared to the Transformer-XL because the former stores only
We train the RMT with Backpropagation Through Time (BPTT). During backward pass, unlike in Transformer-XL, memory gradients are not stopped between segments. The number of previous segments to backpropagate is a hyperparameter of a training procedure. We vary BPTT unroll in our experiments from 0 to 4 previous segments. Increasing this parameter is computationally expensive
and requires a lot of GPU RAM. However, techniques such as gradient checkpointing could be used to alleviate this problem.
4 Experiments
We designed our experiments to evaluate the ability of Recurrent Memory Transformers to preserve long-term dependencies across multiple input segments. The first set of experiments includes copy, reverse, associative retrieval, and quadratic equations tasks. The second one addresses language modeling task for word-level on WikiText-103
Our RMT implementation is based on Transformer-XL repository2. The full set of hyperparameters is available in our repository as well as in supplementary materials. Language modeling experiments follow the same model and training hyperparameters as Transformer-XL. WikiText-103 experiments use 16-layer Transformers (10 heads, 410 hidden size, 2100 intermediate FF), enwik8 – 12 layer Transformers (8 heads, 512 hidden size, 2048 intermediate FF). We used Adam optimizer
Algorithmic Tasks. We evaluate RMT on algorithmic tasks that require information about the whole input sequence to be solved successfully. In a recurrent setting, the model has to keep information about all previous segments to make predictions.
In the Copy task, an input sequence should be replicated twice after a special start-to-generate token. In the Reverse task, an input sequence should be generated in a reverse order. Input for the Associative Retrieval task consists of
For all tasks, input and output sequences are split into segments and processed by models sequentially. Datasets for algorithmic tasks were randomly pre-generated, the same data was used in all experiments, and character-level tokenization was used. Because Transformer-XL and RMT are decoder-only Transformer models, we don’t compute loss over the input sequence before the start-to-generate token. The loss is computed over target sequence segments only (see Appendix A.1 for details).
Language Modeling and NLP. We use two standard benchmarks for language modeling: WikiText-103 and enwik8. WikiText-103
We compare Recurrent Memory Transformer with decoder-only Transformer and Transformer-XL as baselines. Model size and training parameters are selected to match Transformer-XL paper. For Wikitext-103 an input context length was set to 150 tokens, and for enwik8 it was set to 512 characters. Another set of experiments inspected how RMT handles long-term dependencies and recurrence. We increased the number of segments and recurrent steps by making segments smaller (50 tokens for WikiText-103, 128 characters for enwik8). The increased number of recurrent steps makes language modeling tasks harder for RMT because information has to be stored in the same amount of memory for more steps.
As a testbed for the real-life application scenario we select popular long-text classification benchmark Hyperpartisan news
5 Results
Baseline, Transformer-XL
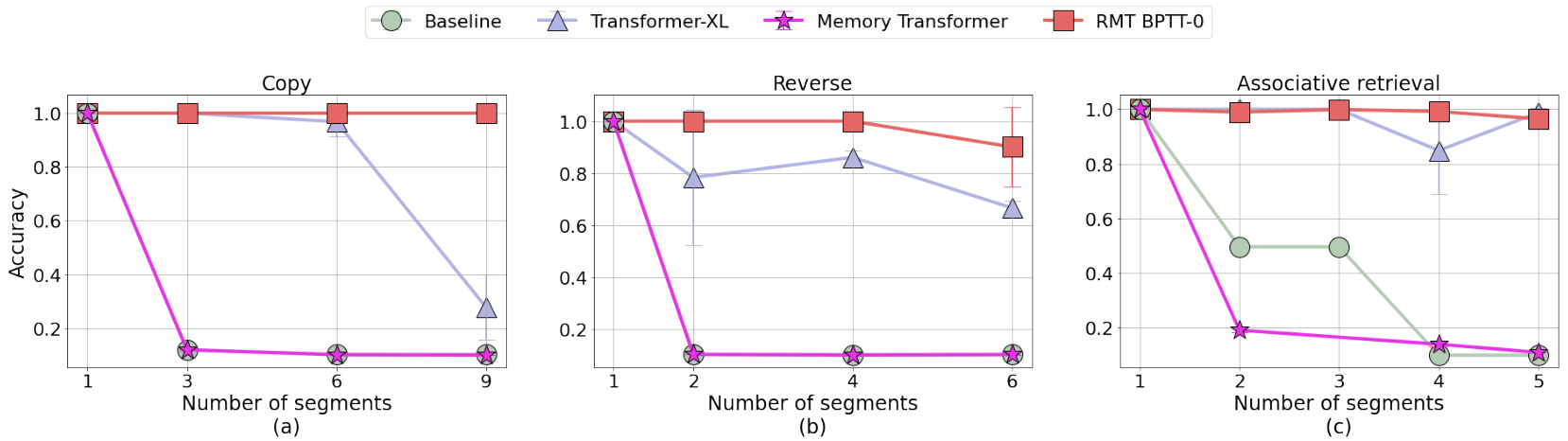
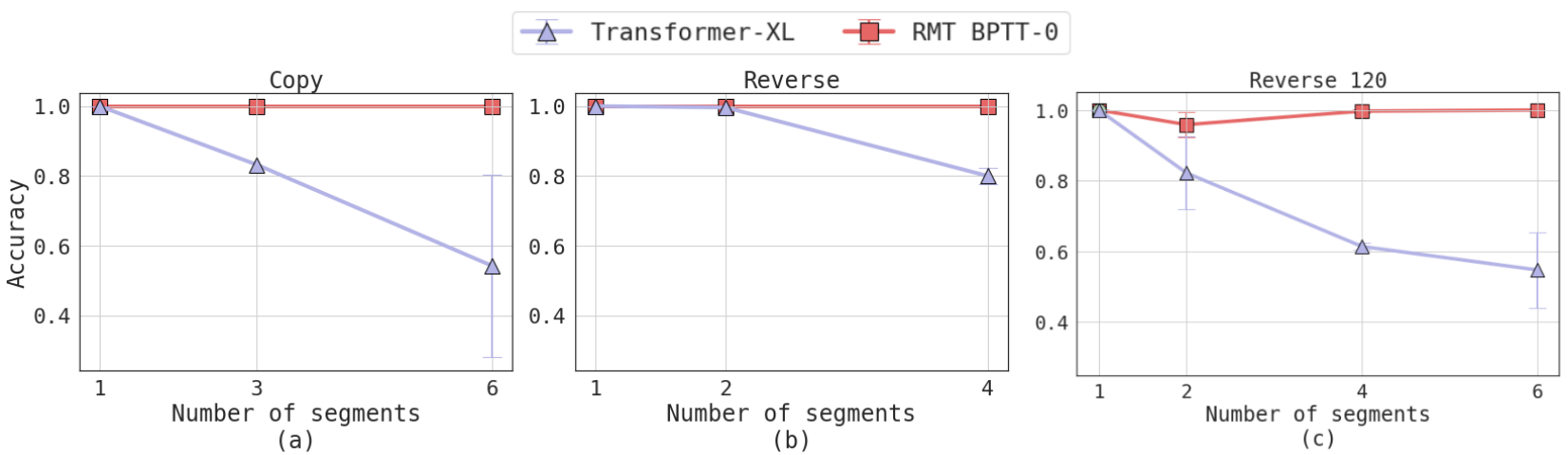
On Copy and Reverse tasks as a number of segments increases, RMT starts to outperform Transformer-XL with memory sizes less than the number of all previous tokens. With the number of segments up to 6 mean accuracy of Transformer-XL drops by up to 0.2 points, and with 9 segments plunges close to the baseline without memory. Associative Retrieval results are similar with the number of segments up to 4. RMT manages to solve the task with Transformer-XL closely behind. However, in the setting with 5 segments, RMT performance slightly decreases and Transformer-XL average accuracy rises higher.
We analyze how a number of segments, sequence length, a length of training context, and memory size affect models’ performance on Copy task
On the Quadratic Equations task
| MODEL | MEMORY | SEGMENTS | ACCSTD |
|---|---|---|---|
| BASELINE | 0 | 1 | |
| TRANSFORMER-XL | 30 | 6 | |
| RMT | 30 | 6 | |
The results of experiments on word-level language modeling on WikiText-103 are shown in Table 2. In the first section with a segment length of 150, Tr-XL and RMT outperform the baseline and Memory Transformer (MemTr) by a large margin. It shows the significance of increased effective context length by Tr-XL cache or RMT memory for language modeling. RMT improves over MemTr memory mechanism with read/write blocks. The best RMT models with memory size 10 and 25 show similar performance as Transformer-XL with a memory size equal to 75. RMT learns to use smaller memory more effectively than Transformer-XL. Additionally, the smaller memory size of RMT leads to reducing required GPU memory for running the model.
To force models to process longer recurrent dependencies the size of a segment is set to 50, so the number of recurrent steps increases. RMT with memory size 1 shows similar results to Transformer
XL with memory size 10. It is worth noting that Transformer-XL memory consists of hidden representations from all layers memory_size vectors. Transformer-XL with memory size 50 and RMT with memory size 5 show similar perplexity values
RMT could be combined with Tr-XL cache. In this case Tr-XL cache could be seen as short-term memory keeping the nearest context and RMT memory as long-term memory. Such combination leads to the best results on WikiText-103 improving over Tr-XL.
| MODEL | MEMORY | SEGMENT LEN | PPLSTD |
|---|---|---|---|
| TR-XL (PAPER) | 150 | 150 | 24.0 |
| BASELINE | 0 | 150 | 29.95 ± 0.15 |
| MEMTR | 10 | 150 | 29.63 ± 0.06 |
| TR-XL (OURS) | 150 | 150 | 24.12 ± 0.05 |
| TR-XL | 25 | 150 | 25.57 ± 0.02 |
| TR-XL | 75 | 150 | 24.68 ± 0.01 |
| RMT BPTT-3 | 10 | 150 | 25.04 ± 0.07 |
| RMT BPTT-2 | 25 | 150 | 24.85 ± 0.31 |
| TR-XL + RMT | 75+5 | 150 | 24.47 ± 0.05 |
| TR-XL + RMT | 150+10 | 150 | 23.99 ± 0.09 |
| BASELINE | 0 | 50 | 39.05 ± 0.01 |
| TR-XL | 100 | 50 | 25.66 ± 0.01 |
| TR-XL | 50 | 50 | 26.54 ± 0.01 |
| TR-XL | 25 | 50 | 27.57 ± 0.09 |
| TR-XL | 10 | 50 | 28.98 ± 0.11 |
| RMT BPTT-1 | 1 | 50 | 28.71 ± 0.03 |
| RMT BPTT-3 | 10 | 50 | 26.37 ± 0.01 |
On enwik8 RMT models with memory size 5 and Transformer-XL with memory size 40 show similar results. Confirming that RMT learns to use smaller amounts of memory representation more effectively. All results for enwik8 dataset are shown in Appendix A.4.
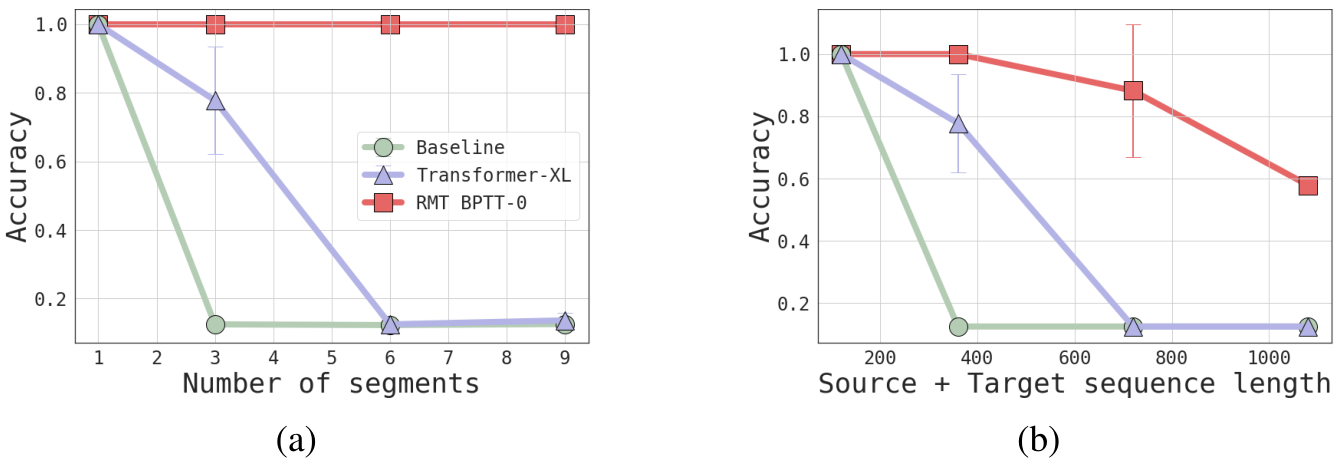
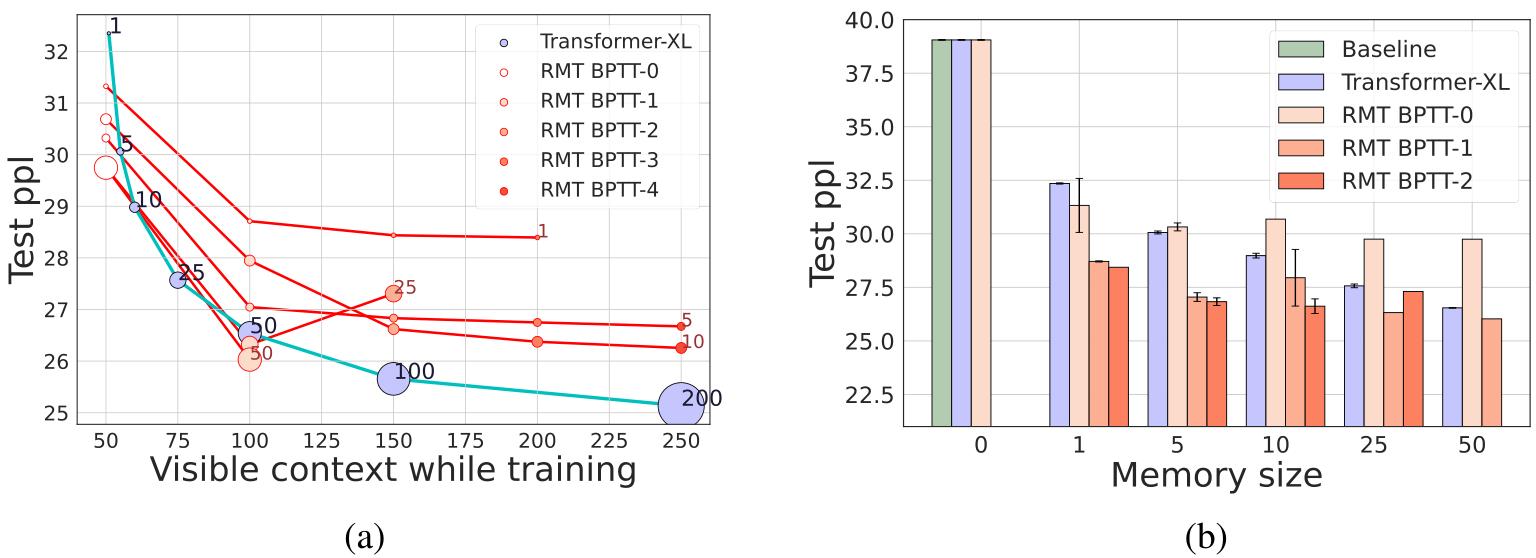
Recurrent Memory Transformer learns to make predictions depending on #BPTT_unrolls over previous segments +1 current segment. Transformer-XL does not use BPTT and relies only on memory_size cached states and current segment making in total: memory_size + segment_length tokens. In Figure 5a, we compare RMT and Tr-XL according to the described value of visible context at training time.
RMT with a single memory vector could be trained to achieve lower perplexity as Transformer-XL with memory size 10. This means that RMT can learn to compress information from the previous observations better. Another observation is that RMT with memory sizes 10 and 25 performs only a bit weaker compared to Transformer-XL even when Transformer-XL has access to more non-compressed states (50, 100, 200) from previous segments. In general, training RMT with unrolling gradients in earlier segments drastically improves scores thus showing the importance of BPTT training but, we observe instabilities and out-of-memory issues during RMT training for a larger memory sizes with deeper BPTT unrolls.
RMT wins a lot when only one memory token is added but then the effect from increasing memory size from 5 to 50 fades (Figure 5b). Still, RMT with memory size 5 have performance on par with Transformer-XL with cache 50, confirming that RMT learns to store more compact representations. The results suggest that there is some optimal memory size for RMT to solve the task, and further increase does not add much.
Proposed recurrent memory mechanism affects only input and gradient flows of the augmented core model. This might be an important advantage because the memory can be added to already pretrained
model. Evaluation results for four memory augmented language models fine tuned for long text classification are presented in the Table 3. Incorporation of 10 memory tokens in the input sequence of 512 allows to encode longer stretches of a text up to 2000 tokens and significantly improve metrics for the majority of models. Moreover, a combination of recurrent memory with RoBERTa-base results in state of the art performance for the Hyperpartisan news classification task
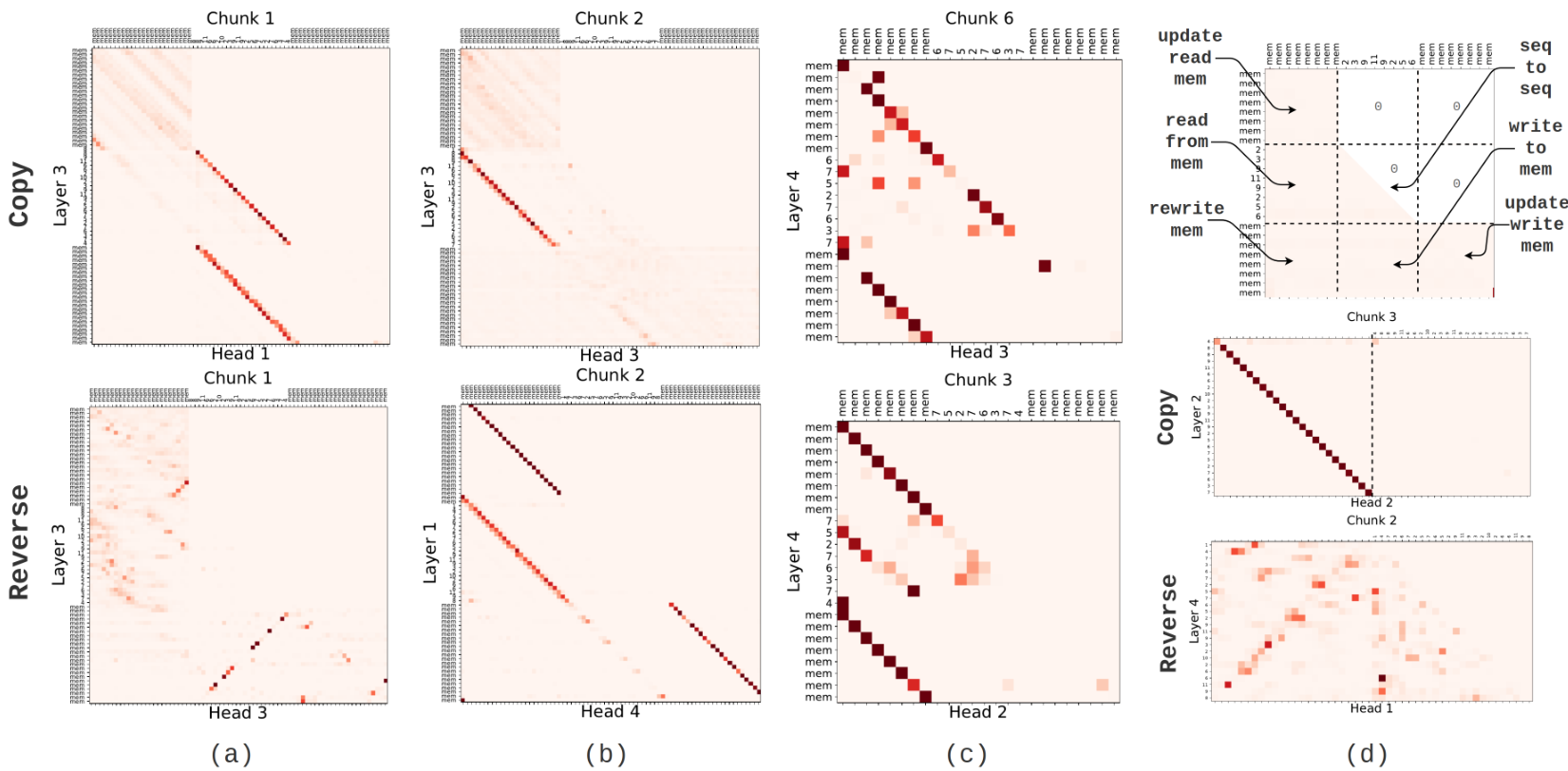
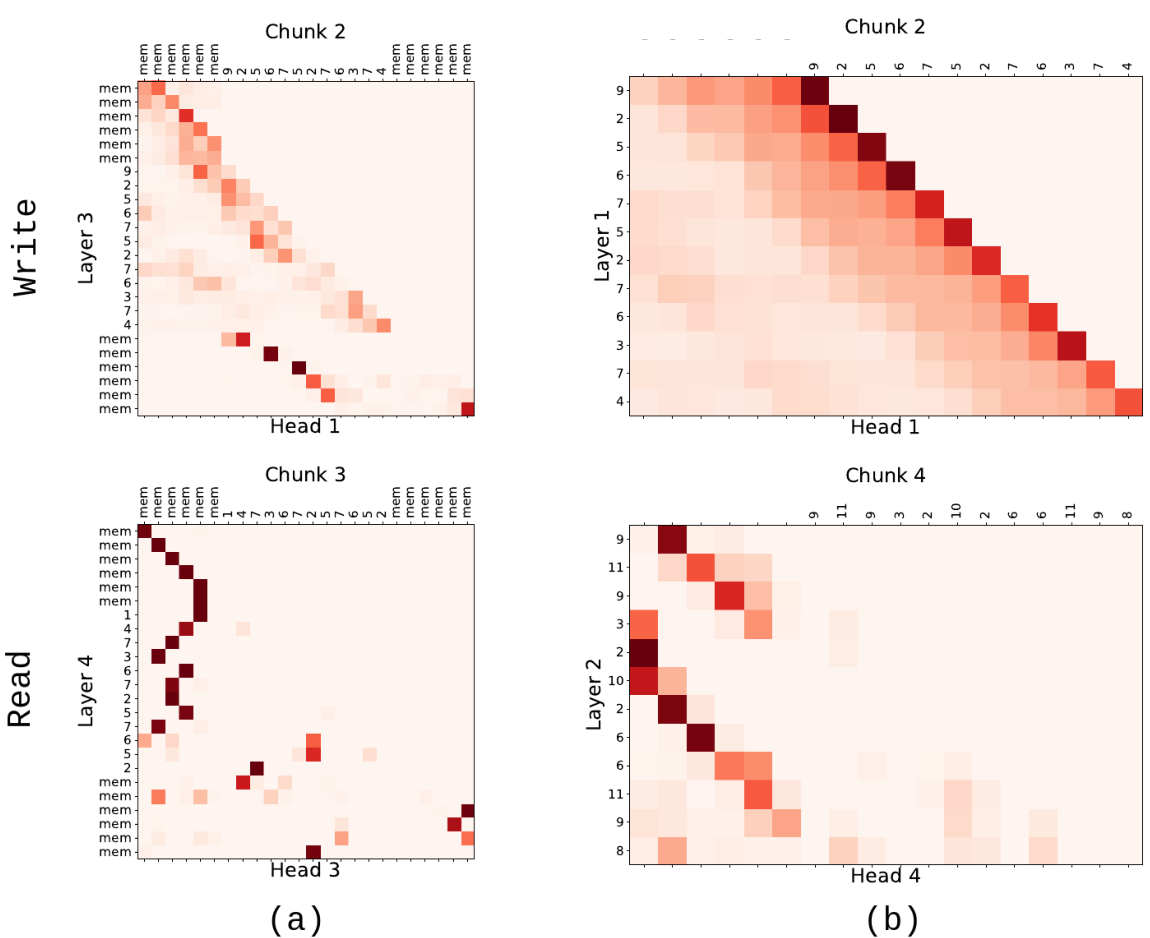
To get an understanding of memory operations, learned by RMT for algorithmic tasks we visualise attention maps for copy and reverse tasks (Figure 6). In each RMT attention map sequence tokens are preceded by read memory, located at the top left corner, and followed by write memory at the bottom right. Diagonal at the central part of the fig.6(a) (top) shows classic attention of token sequence to itself, but the bottom diagonal represents the operation of writing of sequence tokens to memory in straight order. When completing reverse (fig.6(a) bottom) the model learns to write the sequence to the memory in the reversed order, which is in line with common sense.
Table 3: Hyperpartisan news detection. Models starting with RMT are taken from HuggingFace Transformers and augmented with 10 memory tokens and recurrence before fine-tuning. Train/valid/test split as in (Beltagy et al., 2020) and metric is F1.
| MODEL [INPUT SIZE] | NUMBER OF SEGMENTS 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| BIG BIRD [4096] (ZAHEER ET AL., 2020) | 92.20 | |||
| LONGFORMER [4096] (BELTAGY ET AL., 2020) | 94.80 | |||
| GRAPH-ROBERTA [512X100] (XU ET AL., 2021) | 96.15 | |||
| ERNIE-DOC-LARGE [640] (DING ET AL., 2021) | 96.60 | |||
| ERNIE-SPARSE [4096] (LIU ET AL., 2022) | 92.81 | |||
| RMT BERT-BASE-CASE [512] | 91.60 | 94.12 | 93.06 | 94.34 |
| RMT ROBERTA-BASE [512] | 94.87 | 97.20 | 96.72 | 98.11 |
| RMT DEBERTA-V3-BASE [512] | 94.17 | 96.78 | 94.80 | 94.80 |
| RMT T5-BASE [512] | 94.99 | 95.32 | 96.12 | 97.20 |
When it comes to reproducing the target sequence, the model accesses memory (fig.6(b)) and writes to the output sequence. Another operation (fig.6(c)) is rewriting from read memory to write memory. It is commonly used by RMT in settings with larger number of segments to keep information about recent segments longer.
Transformer-XL mechanism of accessing memory (fig.6(d)) does not allow straightforward writing to memory without changing sequence token representations. Sequential reading from cache is represented by diagonals on Transformer-XL attention maps. Using token representations as storage harms model performance in tasks with larger number of segments. For reverse task with 4 segments Transformer-XL with limited memory size 6
Visualizations from Figure 6 and Appendix B Figure 9 provide evidence to support our hypotheses that Tr-XL has to mix representations from previous and current segments in the same hidden states to pass information between segments. Also, visualizations show how memory tokens in RMT help
mitigate such kind of mixing. RMT ability of sequence compression to memory is illustrated in Appendix A.1 Figure 8. For copy with 6 segments RMT compresses and then reads the sequence of 12 tokens with just 6 memory tokens. For Transformer-XL decreasing memory size harms the accuracy score significantly with number of segments larger than 2.
6 Conclusions
In this paper we introduced Recurrent Memory Transformer a simple recurrent memory augmentation of Transformer model. RMT is implemented by extension of an input sequence with special global memory tokens and segment-level recurrence. Importantly, our method allows to learn more compact sequence representations and improve existing pretrained models without extensive additional compute, thus making practical machine learning applications more energy efficient and environmentally friendly.
In our experiments we compared RMT with Transformer baseline and Transformer-XL which is a well-known modification of Transformer for long sequences. RMT almost perfectly solves Copy, Reverse as well as quadratic equations tasks for sequences consisting of multiple segments outperforming Transformer-XL. It also demonstrates quality for associative retrieval task on par with Transformer-XL. As expected, baseline Transformer fails to solve these tasks for multi-segment settings.
RMT trained as a language model performs significantly ahead of Transformer baseline and shows quality metrics similar to Transformer-XL but for up to 10 times smaller memory size. Experimental results demonstrate that for fixed memory size backpropagating gradients for more segments improves performance of RMT. Proposed approach to memory augmentation is quite universal and might be easily applied to any pretrained transformer based model as demonstrated by achievement of state of the art results for long text classification task by fine tuning a combination of RoBERTa and RMT.
Analysis of attention maps suggests that better RMT performance can be related to more effective storage of input representations in dedicated memory tokens compared to mixing representations storage in Transformer-XL. RMT could be combined with Transformer-XL cache and improve the performance of both models.
Overall, results of the study show that dedicated memory storage and recurrence provided by Recurrent Memory Transformer make it a promising architecture for applications that require learning of long-term dependencies and general purpose in-memory processing, such as algorithmic tasks and reasoning. Furthermore, we believe that RMT could open the way for adding memory and recurrence to other models in the Transformer family.
Acknowledgments and Disclosure of Funding
This work was supported by a grant for research centers in the field of artificial intelligence, provided by the Analytical Center for the Government of the Russian Federation in accordance with the subsidy agreement (agreement identifier 000000D730321P5Q0002) and the agreement with the Moscow Institute of Physics and Technology dated November 1, 2021 No. 70-2021-00138.
References
Jimmy Ba, Geoffrey E Hinton, Volodymyr Mnih, Joel Z Leibo, and Catalin Ionescu. Using fast weights to attend to the recent past. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016. URL NeurIPS.
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
Mikhail S Burtsev, Yuri Kuratov, Anton Peganov, and Grigory V Sapunov. Memory transformer. arXiv preprint arXiv:2006.11527, 2020.
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers, 2019.
Kyunghyun Cho, Bart van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neural machine translation: Encoder–decoder approaches. In Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, pages 103–111, Doha, Qatar, October 2014. Association for Computational Linguistics. doi: 10.3115/v1/W14-4012. URL ACL Anthology.
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. arXiv preprint arXiv:2009.14794, 2020.
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context, 2019.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, 2019. URL ACL Anthology.
SiYu Ding, Junyuan Shang, Shuohuan Wang, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. ERNIE-Doc: A retrospective long-document modeling transformer. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 2914–2927, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.227. URL ACL Anthology.
Linhao Dong, Shuang Xu, and Bo Xu. Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5884–5888, 2018. doi: 10.1109/ICASSP.2018.8462506.
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021. URL OpenReview.
Angela Fan, Thibaut Lavril, Edouard Grave, Armand Joulin, and Sainbayar Sukhbaatar. Addressing some limitations of transformers with feedback memory. arXiv preprint arXiv:2002.09402, 2020.
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines, 2014.
Edward Grefenstette, Karl Moritz Hermann, Mustafa Suleyman, and Phil Blunsom. Learning to transduce with unbounded memory, 2015.
Caglar Gulcehre, Sarath Chandar, Kyunghyun Cho, and Yoshua Bengio. Dynamic neural turing machine with soft and hard addressing schemes. arXiv, 2016.
Caglar Gulcehre, Sarath Chandar, and Yoshua Bengio. Memory augmented neural networks with wormhole connections. arXiv, 2017.
Qipeng Guo, Xipeng Qiu, Pengfei Liu, Yunfan Shao, Xiangyang Xue, and Zheng Zhang. Star-transformer, 2019.
Ankit Gupta and Jonathan Berant. Gmat: Global memory augmentation for transformers. arXiv, 2020.
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural Comput., 9(8):1735–1780, November 1997. ISSN 0899-7667. doi: 10.1162/neco.1997.9.8.1735. URL MIT Press.
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver io: A general architecture for structured inputs & outputs. arXiv, 2021.
Armand Joulin and Tomas Mikolov. Inferring algorithmic patterns with stack-augmented recurrent nets, 2015.
Da Ju, Stephen Roller, Sainbayar Sukhbaatar, and Jason Weston. Staircase attention for recurrent processing of sequences. arXiv, 2021.
Johannes Kiesel, Maria Mestre, Rishabh Shukla, Emmanuel Vincent, Payam Adineh, David Corney, Benno Stein, and Martin Potthast. Semeval-2019 task 4: Hyperpartisan news detection. In Proceedings of the 13th International Workshop on Semantic Evaluation, pages 829–839, 2019.
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR (Poster), 2015. URL arXiv.
Guillaume Lample, Alexandre Sablayrolles, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. Large memory layers with product keys, 2019.
Jie Lei, Liwei Wang, Yelong Shen, Dong Yu, Tamara L. Berg, and Mohit Bansal. Mart: Memory-augmented recurrent transformer for coherent video paragraph captioning, 2020.
Yang Liu, Jiaxiang Liu, Li Chen, Yuxiang Lu, Shikun Feng, Zhida Feng, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. Ernie-sparse: Learning hierarchical efficient transformer through regularized self-attention. arXiv, 2022.
Matt Mahoney. Large text compression benchmark, 2006. URL Matt Mahoney.
Pedro Henrique Martins, Zita Marinho, and André FT Martins. -former: Infinite memory transformer. arXiv, 2021.
Warren S McCulloch and Walter Pitts. A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics, 5(4):115–133, 1943.
Yuanliang Meng and Anna Rumshisky. Context-aware neural model for temporal information extraction. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 527–536, 2018.
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. URL OpenReview.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018. URL papers/radford2018improving.pdf.
Jack W Rae, Jonathan J Hunt, Tim Harley, Ivo Danihelka, Andrew Senior, Greg Wayne, Alex Graves, and Timothy P Lillicrap. Scaling memory-augmented neural networks with sparse reads and writes, 2016.
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, and Timothy P. Lillicrap. Compressive transformers for long-range sequence modelling, 2019.
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8821–8831. PMLR, 18–24 Jul 2021. URL proceedings.mlr.press.
C Stephen. Kleene. representation of events in nerve nets and finite automata. Automata studies, 1956.
Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory networks, 2015.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is All you Need. In Advances in neural information processing systems, pages 5998–6008, 2017. URL nips.cc.
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity, 2020.
Paul J Werbos. Backpropagation through time: what it does and how to do it. Proceedings of the IEEE, 78(10): 1550–1560, 1990.
Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks, 2014.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38–45, 2020.
Qingyang Wu, Zhenzhong Lan, Jing Gu, and Zhou Yu. Memformer: The memory-augmented transformer. arXiv, 2020.
Peng Xu, Xinchi Chen, Xiaofei Ma, Zhiheng Huang, and Bing Xiang. Contrastive document representation learning with graph attention networks. arXiv, 2021.
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences. arXiv, 2020.
Checklist
- For all authors…
(a) Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? [Yes]
(b) Did you describe the limitations of your work? [Yes] We mention training instabilities and GPU RAM issues in Section 5.
(c) Did you discuss any potential negative societal impacts of your work? [No] The proposed model and method do not have any specific impacts. All general negative societal impacts applicable to the field could be potentially relative.
(d) Have you read the ethics review guidelines and ensured that your paper conforms to them? [Yes] - If you are including theoretical results…
(a) Did you state the full set of assumptions of all theoretical results? [N/A]
(b) Did you include complete proofs of all theoretical results? [N/A] - If you ran experiments…
(a) Did you include the code, data, and instructions needed to reproduce the main experimental results (either in the supplemental material or as a URL)? [Yes] We include code, training scripts, and raw experimental data in the supplementary material. The supplemental materials would be published on github with the final version of the paper. Instructions for language modeling data&experiments are taken from Tr-XL repo.
(b) Did you specify all the training details (e.g., data splits, hyperparameters, how they were chosen)? [Yes] See Section 4, Appendix A, and provided supplementary material.
(c) Did you report error bars (e.g., with respect to the random seed after running experiments multiple times)? [Yes] All the key experiments results are reported with std. Furthermore, we provide raw experimental data in the supplementary materials.
(d) Did you include the total amount of compute and the type of resources used (e.g., type of GPUs, internal cluster, or cloud provider)? [Yes] We used different GPUs depending on the task: 1080Ti, V100, A100. We provide this information in Appendix A for each task. - If you are using existing assets (e.g., code, data, models) or curating/releasing new assets…
(a) If your work uses existing assets, did you cite the creators? [Yes] We refer to the original Tr-XL code and Tr-XL paper. We use it for establishing baselines and setting our methods. See Section 4
(b) Did you mention the license of the assets? [No] Tr-XL license is Apache 2.0 and available at its github repo.
(c) Did you include any new assets either in the supplemental material or as a URL? [Yes] Our code is in the supplemental material and on GitHub: GitHub
(d) Did you discuss whether and how consent was obtained from people whose data you’re using/curating? [No] We used publicly available Tr-XL code (Apache 2.0) and datasets.
(e) Did you discuss whether the data you are using/curating contains personally identifiable information or offensive content? [No] We use either synthetic data or datasets collected from the Wikipedia (Wikitext-103, enwik8). - If you used crowdsourcing or conducted research with human subjects…
(a) Did you include the full text of instructions given to participants and screenshots, if applicable? [N/A]
(b) Did you describe any potential participant risks, with links to Institutional Review Board (IRB) approvals, if applicable? [N/A]
(c) Did you include the estimated hourly wage paid to participants and the total amount spent on participant compensation? [N/A]
A Training details and additional results
A.1 Algorithmic tasks
Datasets were randomly generated by uniformly sampling tokens from dictionary into task sequences and generating targets accordingly to the tasks. After generation, datasets are fixed for all experiments.
Copy and reverse use sequences of sizes 24, 40, 120, 240, and 360, making total copy/reverse input length 48/72, 80/120, 240/360, 480/720, 720/1080. The associative retrieval task consists of 4 key-value pairs and one randomly selected key; the answer consists of one value. Train, validation and test sizes of copy 24, reverse 24 and associative retrieval datasets are 100000, 5000 and 10000.
Transformer-XL had the same cache size on training and validation to match RMT.
For training all models on copy and reverse, we used constant learning rate
Experiments with sequence length 24 were conducted on a single Nvidia GTX 1080 Ti GPU from 1 hour to 2-3 days. Copy and reverse on longer sequence lengths were done on more powerful Tesla V100 using 1-3 devices with training time varying from 1 hour to 3-4 days.
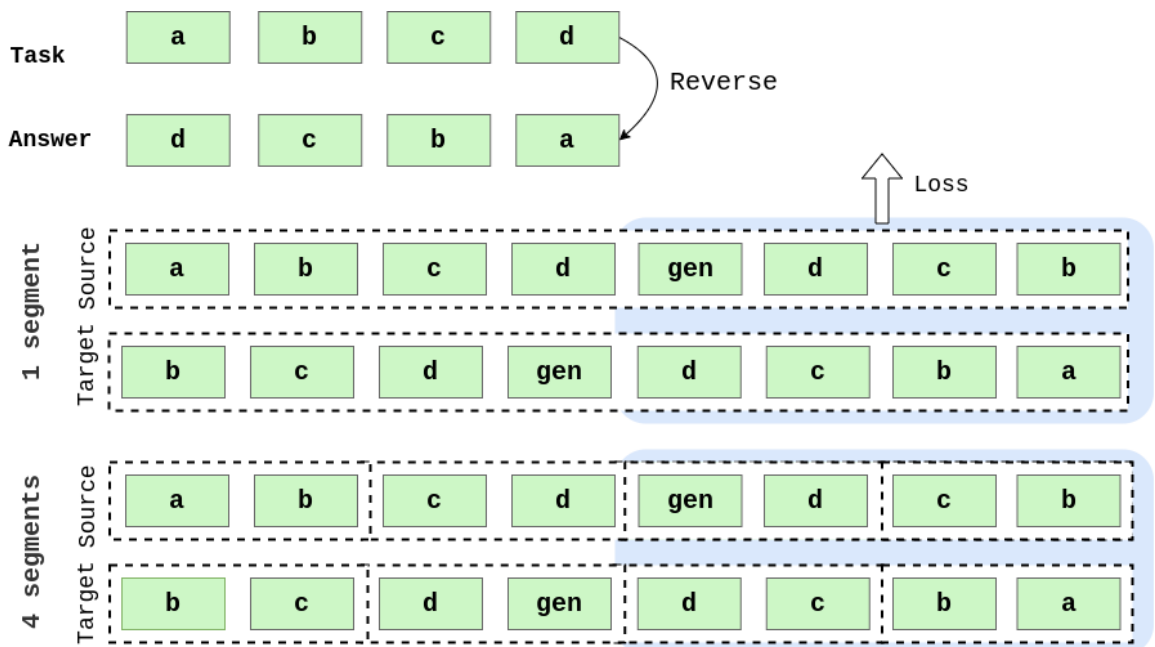
A.2 Associative retrieval
We used code for the task dataset generation from
A.3 Quadratic equations
This dataset consists of equations with integer coefficients and step-by-step solutions using the discriminant. Process of equation generation is started from uniformly sampling real roots
Example equation string:
-4*x^2+392*x-2208=0,
solution string:
x^2-98*x+552=0;D=98^2-4*1*552=7396=86^2;x=(98-86)/2=6;x=(98+86)/2=92 ,
and answer:
6,92
Each solution step is tokenized on char level and padded to the length of 30 tokens. The total length of each training sample is 180, the dataset has 100000 training, 10000 validation and 20000 test samples.
For this task we used models with 6 layers, 6 heads and segment sizes 180 and 30. The training was performed with the same schedule as copy and reverse on a single GTX 1080 ti for 1-2 days. Memory size for RMT and Transformer-XL was chosen equal to the segment length.
A.4 Enwik8
We verified our experimental setup by reproducing Transformer-XL results on enwik8 dataset (Table 4). We used 12-layer Baseline (Transformer), Transformer-XL, RMT in all enwik8 experiments. All results on enwik8 dataset are in Table 4. We used 2 NVIDIA A100 80Gb GPUs, training time varied from 10 to 30 hours depending on sequence length, memory size, and number of BPTT unrolls.
A.5 WikiText-103
We used 16-layer models in all experiments on WikiText-103 dataset. Training hyperparameters were used from
Table 4: Test set bits-per-character on enwik8. Our experimental setup shows similar scores to the original paper
| MODEL | MEMORY | SEGMENT LEN | |
|---|---|---|---|
| TR-XL (DAI ET AL., 2019) | 512 | 512 | 1.06 |
| TR-XL (OURS) | 512 | 512 | 1.071 |
| TR-XL | 200 | 128 | 1.140 |
| TR-XL | 100 | 128 | 1.178 |
| TR-XL | 75 | 128 | 1.196 |
| TR-XL | 40 | 128 | |
| TR-XL | 20 | 128 | 1.261 |
| TR-XL | 10 | 128 | |
| RMT BPTT-1 | 5 | 128 | |
| RMT BPTT-2 | 5 | 128 | |
| RMT BPTT-1 | 10 | 128 | |
| RMT BPTT-2 | 10 | 128 | |
| RMT BPTT-0 | 20 | 128 | 1.301 |
| RMT BPTT-1 | 20 | 128 | 1.229 |
| RMT BPTT-2 | 20 | 128 | 1.222 |
Table 5: Test set perplexity on WikiText-103. All experiments with RMT and Tr-XL models.
| MODEL | MEMORY | SEGMENT LEN | |
|---|---|---|---|
| BASELINE | 0 | 150 | |
| MT | 10 | 150 | |
| MT | 25 | 150 | |
| MT | 75 | 150 | |
| MT | 150 | 150 | |
| TR-XL (PAPER) | 150 | 150 | |
| TR-XL (OURS) | 150 | 150 | |
| TR-XL (OURS) 2X STEPS | 150 | 150 | |
| TR-XL | 75 | 150 | |
| TR-XL 2X STEPS | 75 | 150 | |
| TR-XL | 25 | 150 | |
| RMT BPTT-0 | 10 | 150 | |
| RMT BPTT-1 | 10 | 150 | |
| RMT BPTT-2 | 10 | 150 | |
| RMT BPTT-3 | 10 | 150 | |
| RMT BPTT-0 | 25 | 150 | |
| RMT BPTT-1 | 25 | 150 | |
| RMT BPTT-2 | 25 | 150 | |
| TR-XL + RMT BPTT-3 | 150 | ||
| TR-XL + RMT BPTT-3 | 150 | ||
| TR-XL + RMT BPTT-0 | 150 | ||
| TR-XL + RMT BPTT-1 | 150 | ||
| TR-XL + RMT BPTT-3 2X STEPS | 150 | ||
| BASELINE | 0 | 50 | |
| TR-XL | 200 | 50 | |
| TR-XL | 100 | 50 | |
| TR-XL | 50 | 50 | |
| TR-XL | 25 | 50 | |
| TR-XL | 10 | 50 | |
| TR-XL | 5 | 50 | |
| TR-XL | 1 | 50 | |
| RMT BPTT-0 | 1 | 50 | |
| RMT BPTT-1 | 1 | 50 | |
| RMT BPTT-2 | 1 | 50 | |
| RMT BPTT-3 | 1 | 50 | |
| RMT BPTT-0 | 5 | 50 | |
| RMT BPTT-1 | 5 | 50 | |
| RMT BPTT-2 | 5 | 50 | |
| RMT BPTT-3 | 5 | 50 | |
| RMT BPTT-4 | 5 | 50 | |
| RMT BPTT-0 | 10 | 50 | |
| RMT BPTT-1 | 10 | 50 | |
| RMT BPTT-2 | 10 | 50 | |
| RMT BPTT-3 | 10 | 50 | |
| RMT BPTT-4 | 10 | 50 | |
| RMT BPTT-0 | 25 | 50 | |
| RMT BPTT-1 | 25 | 50 | |
| RMT BPTT-2 | 25 | 50 | |
| RMT BPTT-0 | 50 | 50 | |
| RMT BPTT-1 | 50 | 50 |
B Operations with Memory
Footnotes
-
https://github.com/booydar/LM-RMT. The code, results of the raw experiments and hyperparameters are provided in the supplementary materials and on GitHub. ↩