Scaling Transformer to 1M tokens and beyond with RMT
Aydar Bulatov, Yuri Kuratov, Yermek Kapushev, Mikhail Burtsev
Neural Networks and Deep Learning Lab, MIPT, Dolgoprudny, Russia
AIRI, Moscow, Russia
London Institute for Mathematical Sciences, London, UK
{bulatov.as,yurii.kuratov}@phystech.edu, mb@lims.ac.uk
Abstract
A major limitation for the broader scope of problems solvable by transformers is the quadratic scaling of computational complexity with input size. In this study, we investigate the recurrent memory augmentation of pre-trained transformer models to extend input context length while linearly scaling compute. Our approach demonstrates the capability to store information in memory for sequences of up to an unprecedented two million tokens while maintaining high retrieval accuracy. Experiments with language modeling tasks show perplexity improvement as the number of processed input segments increases. These results underscore the effectiveness of our method, which has significant potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Introduction
Transformer-based models show their effectiveness across multiple domains and tasks. The self-attention allows to combine information from all sequence elements into context-aware representations. However, global and local information has to be stored mostly in the same element-wise representations. Moreover, the length of an input sequence is limited by quadratic computational complexity of self-attention.
In this work, we propose and study a memory-augmented segment-level recurrent Transformer (Recurrent Memory Transformer or RMT). Memory allows to store and process local and global information as well as to pass information between segments of the long sequence with the help of recurrence. We implement a memory mechanism with no changes to Transformer model by adding special memory tokens to the input or output sequence. Then Transformer is trained to control both memory operations and sequence representations processing.
In this study we show that by using simple token-based memory mechanism introduced in
Contributions 1. We expand application of RMT to encoder-only and decoder-only pre-trained language models. Proposed segment wise curriculum learning allows to fine-tune majority of pre-trained transformer based models for processing potentially unlimited sequences.
2. To benchmark generalization capabilities of RMT we propose a set of novel memory acquisition and retention tasks scalable to extremely long sequences of million tokens.
3. We demonstrate the unparalleled ability of RMT to generalize memory operations, successfully detecting and storing information about facts for up to two million tokens. To the best of our knowledge, this establishes a record for the longest sequence task processed by any existing deep neural network. Furthermore, we identify no technical limitations that prevent further scaling.
4. We compare computational complexity of RMT vs. other transformer models and demonstrate the significant advantage of RMT due to its linear scaling of inference operations and constant memory.
The code is available on GitHub. The paper version with supplementary materials is available on arXiv.
Related Work
Our work revolves around the concept of memory in neural architectures. Memory has been a recurrent theme in neural network research, dating back to early works
NTMs, followed by Differentiable Neural Computer
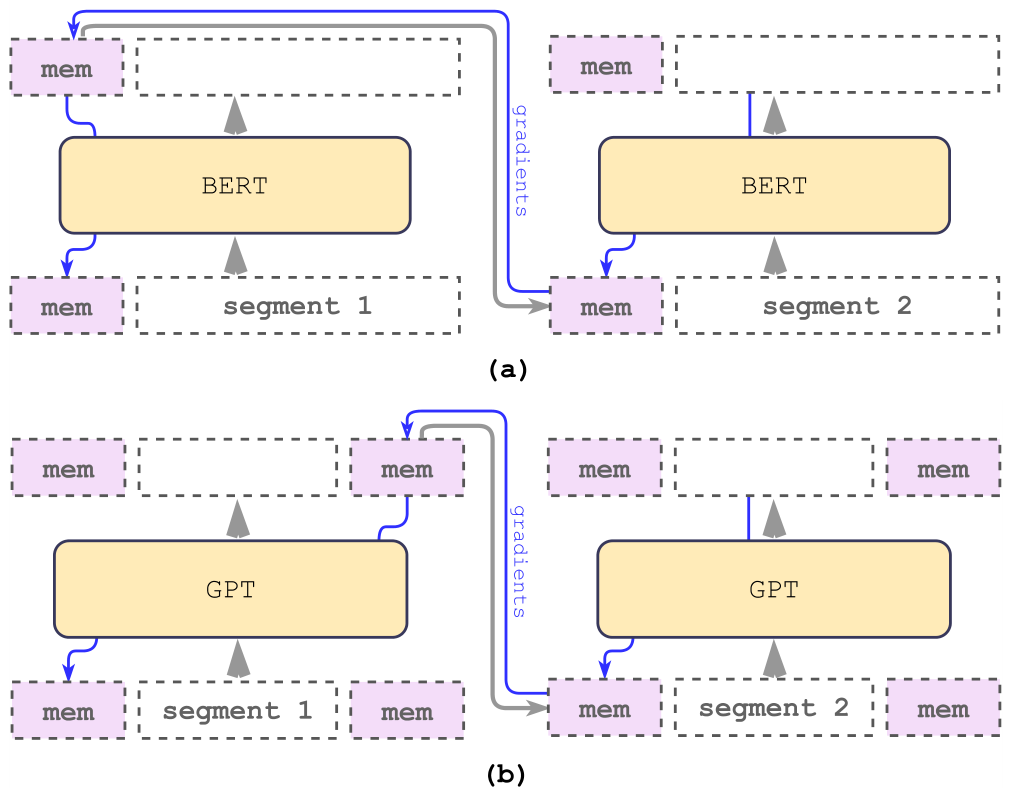
Memory is often combined with Transformers in a recurrent approach. Long inputs are divided into smaller segments, processed sequentially with memory to access information from past segments. Transformer-XL
A drawback of most existing recurrent methods is the need for architectural modifications that complicate their application to various pre-trained models. In contrast, the Recurrent Memory Transformer can be built upon any model that uses a common supported interface.
Some approaches redesign the self-attention mechanism to reduce computational complexity while minimizing input coverage loss. Star-Transformer
A common constraint of these methods is that memory requirements grow with input size during both training and inference, inevitably limiting input scaling due to hardware constraints. In contrast, recurrent approaches have constant memory complexity during inference. The longest Longformer, Big Bird, and Long T5
Another line of recent related work focuses on models with an alternative to traditional attention mechanism: S4
Recurrent Memory Transformer
Starting from the initial Recurrent Memory Transformer
This adaptation augments its backbone with memory, composed of
write sections. For the time step
here
After the forward pass,
Segments of the input sequence are processed sequentially. To enable the recurrent connection, we pass the outputs of the memory tokens from the current segment to the input of the next one:
Both memory and recurrence in the RMT are based only on global memory tokens. This allows the backbone Transformer to remain unchanged, making the RMT memory augmentation compatible with any Transformer-based model.
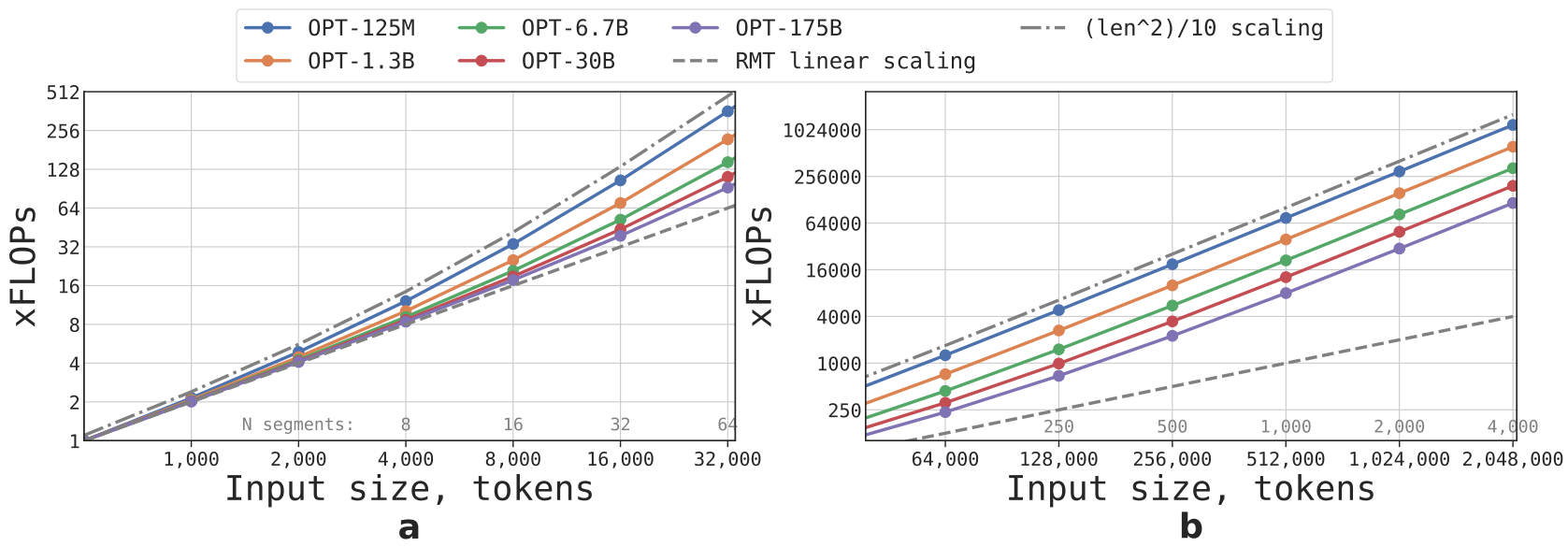
We can estimate the required FLOPs for RMT and Transformer models of different sizes and sequence lengths. We took configurations (vocabulary size, number of layers, hidden size, intermediate hidden size, and number of attention heads) for the OPT model family
Figure 2 shows that RMT scales linearly for any model size if the segment length is fixed. We achieve linear scaling by dividing an input sequence into segments and computing the full attention matrix only within segment boundaries. Larger Transformer models tend to exhibit slower quadratic scaling with respect to sequence length because of compute-heavy FFN layers (which scale quadratically with respect to hidden size). However, on extremely long sequences
Memorization Tasks
To test memorization abilities, we constructed synthetic datasets that require memorization of simple facts and basic reasoning. The task input consists of one or several facts and a question that can be answered only by using all of these facts. To increase the task difficulty, we added natural language text unrelated to the questions or answers. This text acts as noise, so the model’s task is to separate facts from irrelevant text and use them to answer the questions. The task is formulated as a multi-class classification, with each class representing a separate answer option.
Facts are generated using the bAbI dataset
Background text example: ”… He was a big man, broad-shouldered and still thin-waisted. Eddie found it easy to believe the stories he had heard about his father …”
The first task tests the ability of RMT to write and store information in memory for an extended time (Figure 3, top). In the simplest case, the fact is always located at the beginning of the input, and the question is always at the end. The amount of irrelevant text between the question and answer is gradually increased, so that the entire input does not fit into a single model input. Example: “Fact: Daniel went back to the hallway. Question: Where is Daniel? Answer: hallway”
Fact detection increases the task difficulty by moving the fact to a random position in the input (Figure 3, middle).
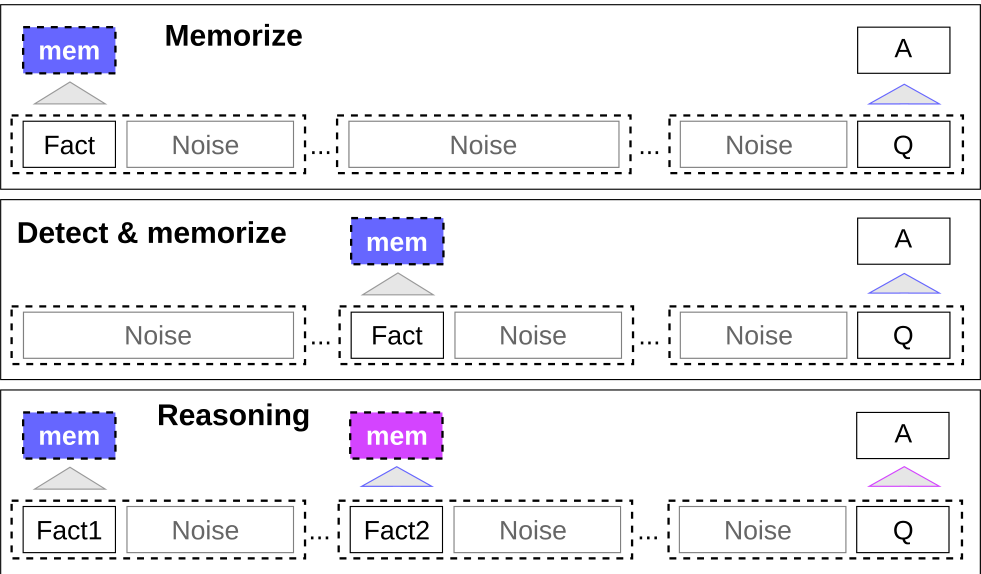
This requires the model to first distinguish the fact from irrelevant text, write it to memory, and later use it to answer the question located at the end.
Another important operation with memory is being able to operate with several facts and current context. To evaluate this function, we use a more complicated task called “reasoning”, where two facts are generated and positioned randomly within the input sequence
Learning Memory Operations
We use the pretrained models from
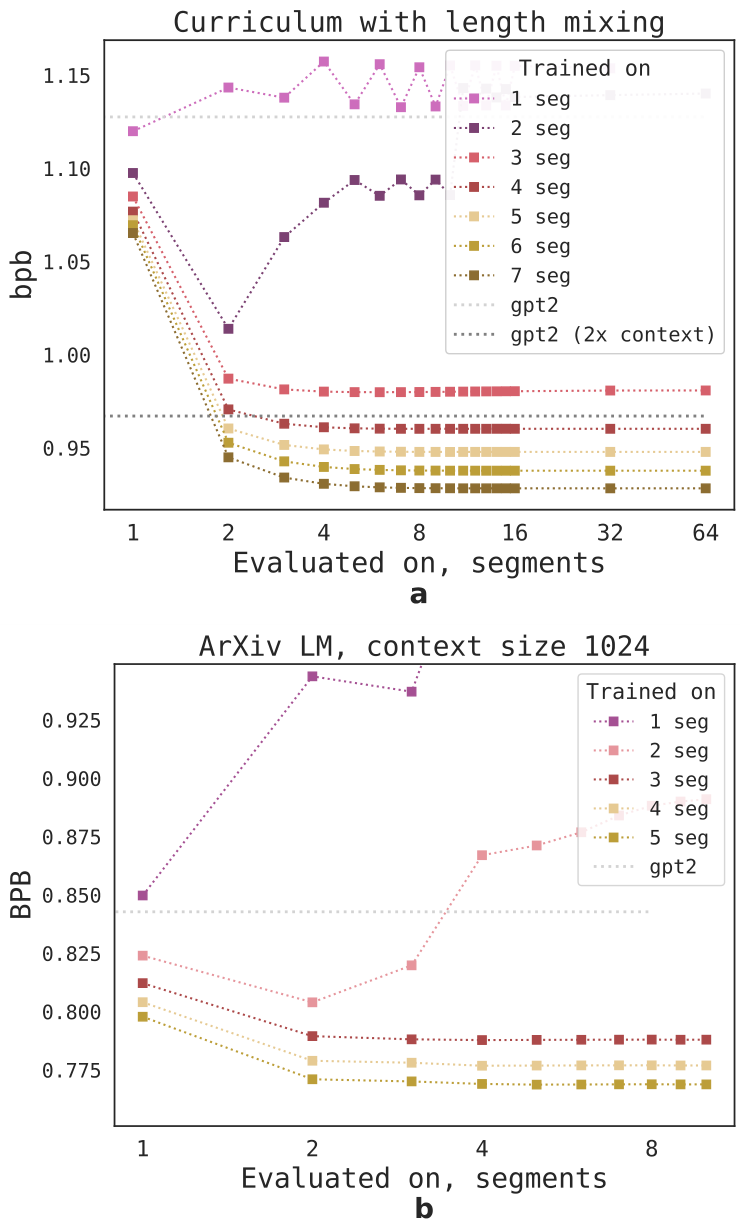
To improve training stability of the original RMT we introduce curriculum learning. At the beginning of training, RMT is fine-tuned on shortest one segment version of the task, and upon convergence, the task length is increased by adding one more segment. The curriculum learning continues until the desired input length is reached.
In our experiments, we begin with sequences that fit in a single segment. The practical segment size is 499, as 3 special tokens of BERT and 10 placeholders for memory are reserved from the model input, sized 512. We notice that after training on shorter tasks, it is easier for RMT to solve
longer versions as it converges faster to the perfect solution.
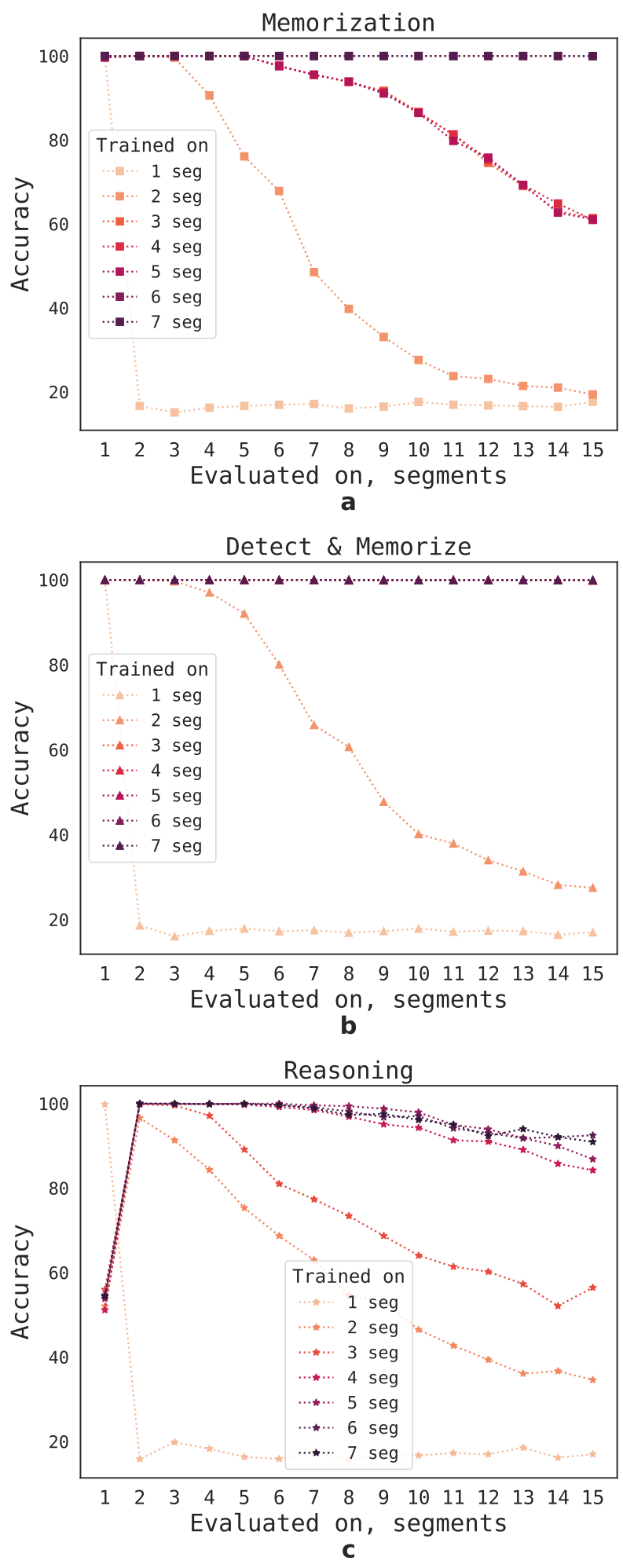
How well does RMT generalize to different sequence lengths? To answer this question, we evaluate models trained on a varying number of segments to solve tasks of larger lengths (Figure 4). We observe that most models tend to perform well on shorter tasks. The only exception is the single-segment reasoning task, which becomes hard to solve once the model is trained on longer sequences. One possible ex-
planation is that since the task size exceeds one segment, the model stops expecting the question in the first segment, leading to quality degradation.
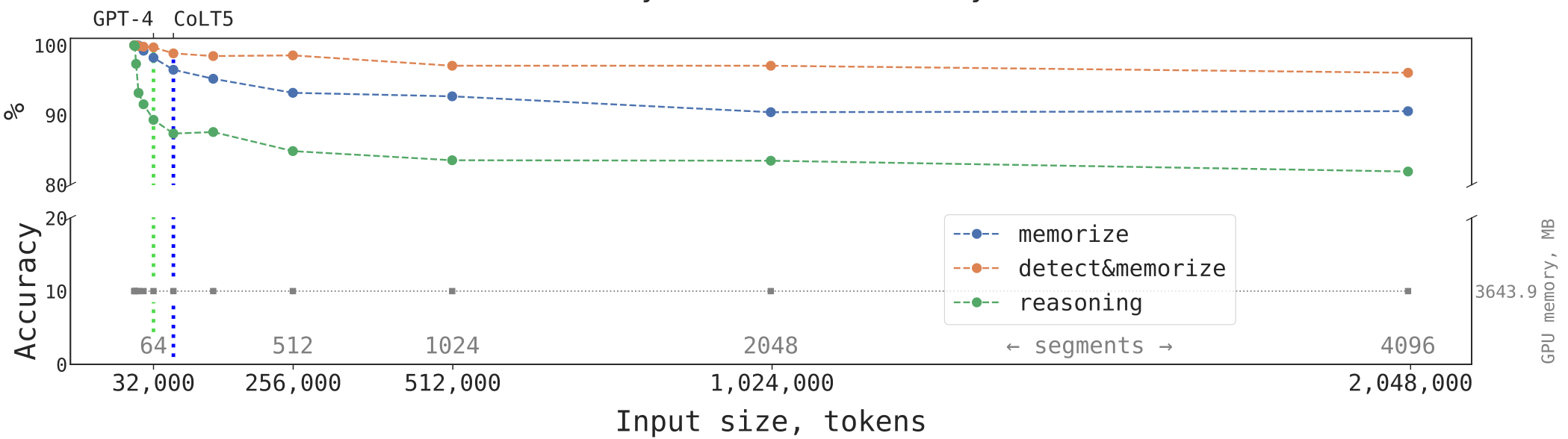
Interestingly, the ability of RMT to generalize to longer sequences also emerges with a growing number of training segments. After being trained on 5 or more segments, RMT can generalize nearly perfectly for tasks twice as long. To test the limits of generalization, we increase the validation task size up to 4096 segments or 2,043,904 tokens (Figure 5). RMT holds up surprisingly well on such long sequences, with Detect & Memorize being the easiest and Reasoning task the most complex.
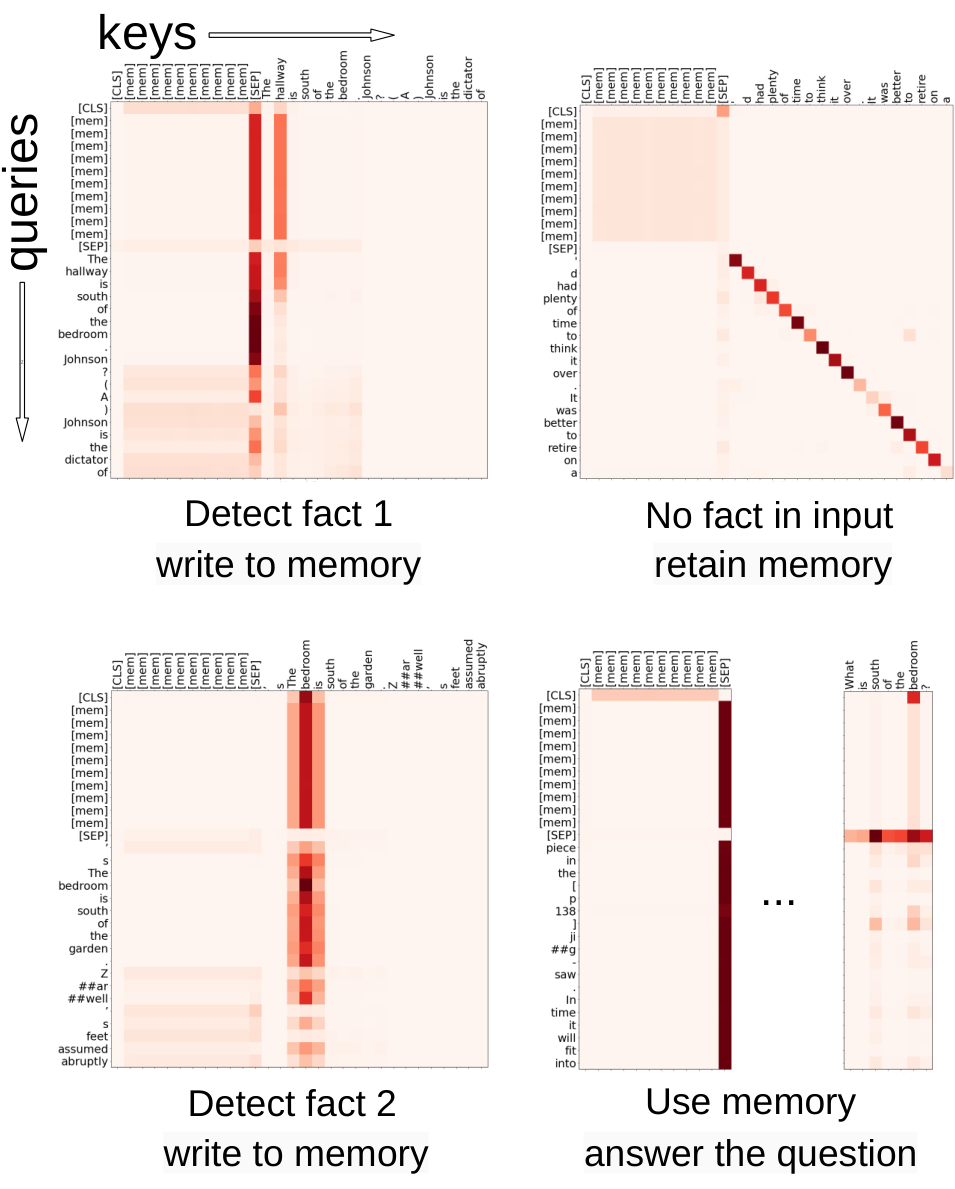
By examining the RMT attention on specific segments, as shown in Figure 6, we observe that memory operations correspond to particular patterns in attention. Furthermore, the high extrapolation performance on extremely long sequences, as presented on the Fig. 5, demonstrates the effectiveness of learned memory operations, even when used thousands of times. The RMT does not have any specific memory read/write modules and Transformer learns how to operate with memory recurrently. This is particularly impressive, considering that these operations were not explicitly motivated by the task loss.
Natural and Formal Language Modeling
To study the contribution of recurrent memory for long text understanding, we focus on the long range language modeling task. To capture long-term dependencies in text, memory is required to find and store various type of information between segments. We train the GPT-2 Hugging Face checkpoint with 2 memory tokens using the recurrent memory approach on the ArXiv documents from The Pile
loss and perplexity only for the last target segment. Similarly to memorization tasks, we employ curriculum learning for training, starting without history and then gradually increasing context size. We also find that mixing the number of segments on each curriculum step leads to much better generalization on other sequence lengths. We discuss curriculum procedures and usage of parameter-efficient methods in the Appendix.
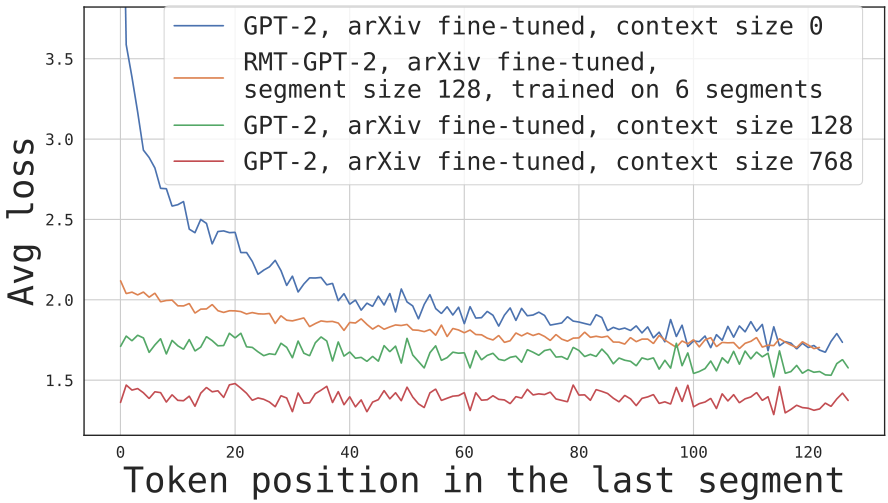
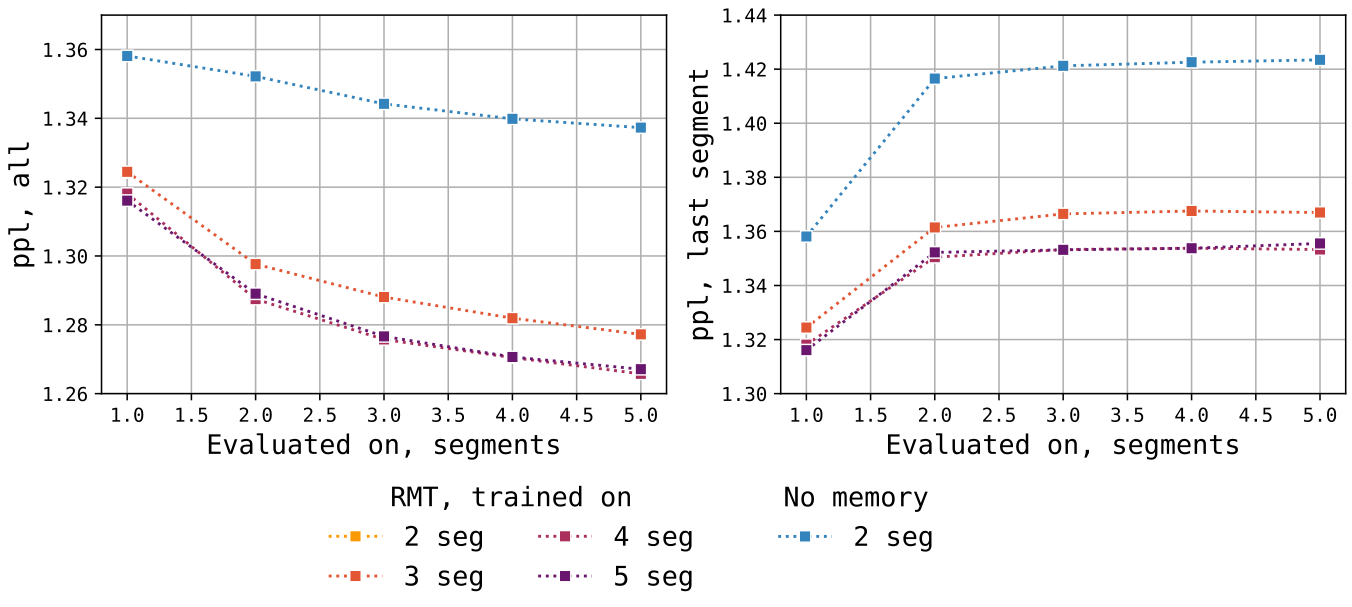
As expected, increasing the effective context size leads to an improvement in perplexity (Figure 7). RMT trained for an equal number of steps as the baseline GPT-2 displays substantially lower perplexity values. With increasing number of segments in training RMT starts exhibiting better tolerance to longer history sizes. Performance of memory models trained without history suffers when applied to long contexts, but improves after multi-segment training.
To understand how memory is utilized during generation of the sequence we measured perplexity for every position in it (see Figure 8). Baseline shows low prediction quality at the beginning of the sequence due to short context available to condition generation. On the other hand, RMT ensures equally good prediction for all tokens due to carryover of information from the previous segment.
To test our approach in a different domain we fine-tune RMT on a complex mathematical task: generating a proof for a given mathematical theorem in formal language. For our experiments, we utilized Lean 3
Each proof relies on known results, referred to as lemmas. To ensure an effective model, it must accurately assess the relevance of a lemma to the given proof. Subsequently, it should memorize the lemma’s name and incorporate it within the proof. To construct our dataset, we organized each sample into a sequence format. The sequence comprises the theorem statement at the beginning, followed by a randomly ordered list of relevant and irrelevant lemmas, and concludes with the human-written proof. By adjusting the presence of irrelevant lemmas, we control the sequence length. We further divide the sequence into non-overlapping segments of fixed size.
For training and evaluation, we calculate the loss and perplexity of the entire sequence. Similar to memorization tasks, we train the RMT model and gradually increase size of the sequences. As our backbone, we employ GPT-Neo
To assess the performance of the RMT model, we compare it with GPTNeo without memory trained on a sequences of 2 segments (first segment always contains the theorem statement and the second contains the proof). GPT-Neo undergoes fine-tuning using the same number of tokens as RMT with 2 segments. Figure 9 shows the results of the RMT model. The RMT model improves perplexity compared to the memory-less model.
However, training with 4 or more segments does not enhance predictions for longer sequences. According to how the sequence is constructed and split into segments, we hypothesize that the model is more concentrated on learning to remember the beginning of the last lemma in the previous
segment to predict its end in the subsequent segment. The effect of detecting and memorizing relevant lemmas and utilizing them in proof generation is less notable. We believe that the results can be improved by more careful loss construction and data preparation.
Conclusion
The problem of long input scaling in Transformers has been extensively studied since the introduction of this architecture. Our research has presented a series of significant advancements in augmenting and training of Transformer language models. The work expands the conventional capabilities of pre-trained encoder-only and decoder-only transformers to an unprecedented level of scalability through the integration of token-based memory storage and segment-level recurrence using recurrent memory (RMT).
We have shown that by employing the RMT combined with curriculum learning, even models pre-trained on shorter sequences can be effectively adapted to manage tasks involving significantly longer sequences. This demonstrates that the input length originally designed for the model does not necessarily restrict its potential capabilities, thus offering a new perspective on the adaptability of Transformers.
Our work further uncovered the remarkable adaptability of the trained RMT models in extrapolating to tasks of varying lengths. The results obtained showcased the RMT’s ability to handle sequences exceeding 1 million tokens. Importantly, the computational requirements scaled linearly, thereby maintaining computational efficiency even as task length drastically increased. This is a substantial contribution that could lead to broader applications and improved performance in handling large-scale data. Through an analysis of attention patterns, we provided insight into the operations RMT engages to manipulate memory.
Overall, our research contributes significantly to the understanding and enhancement of pre-trained Transformer language models. It offers a promising direction for future work, particularly in terms of handling longer sequences and improving the adaptability of these models.
Limitations and Discussion
The curriculum procedure has a substantial impact on the generalization abilities of RMT. Consequently, careful consideration and implementation of curriculum is needed, in contrast to straightforward training of regular Transformers.
We demonstrate scaling to extremely long sequences such as 2M tokens only on specialized tasks. Unfortunately, there are currently no established benchmarks for NLP tasks with such lengths. However, there are no technical limitations to use the proposed methods on tasks with 2M+ tokens lengths.
Training with BPTT is less computationally expensive than full attention, but still requires a significant amount of computation. In our experiments, BPTT with a maximum unroll of 7 segments was sufficient to show generalization on much longer sequences. However, larger models would be more expensive to train with BPTT and some tasks may require more segments to generalize. Techniques such as gradient checkpointing, truncated BPTT or parameter efficient training can reduce the amount of required resources.
Another point is that with unlimited resources and general-purpose information to remember, full attention models might still have an edge in performance. We can think of full-attention models as an upper bound for RMT, since RMT has to operate only on memory states that represent compressed information, not on actual exact hidden states of the past. Recurrent-based approaches, on the other, hand may be useful in complex step-by-step reasoning tasks, with specialized memory-intensive tasks or in cases where current models are limited
Acknowledgements
References
Ainslie, J.; Lei, T.; de Jong, M.; Ontañón, S.; Brahma, S.; Zemlyanskiy, Y.; Uthus, D.; Guo, M.; Lee-Thorp, J.; Tay, Y.; Sung, Y.-H.; and Sanghai, S. 2023. CoLT5: Faster Long-Range Transformers with Conditional Computation. arXiv.
Ainslie, J.; Ontanon, S.; Alberti, C.; Pham, P.; Ravula, A.; and Sanghai, S. 2020. ETC: Encoding Long and Structured Data in Transformers. arXiv.
Beltagy, I.; Peters, M. E.; and Cohan, A. 2020. Longformer: The long-document transformer. arXiv.
Bertsch, A.; Alon, U.; Neubig, G.; and Gormley, M. R. 2023. Unlimiformer: Long-Range Transformers with Unlimited Length Input. arXiv.
Biderman, S.; Schoelkopf, H.; Anthony, Q.; Bradley, H.; O’Brien, K.; Hallahan, E.; Khan, M. A.; Purohit, S.; Prashanth, U. S.; Raff, E.; Skowron, A.; Sutawika, L.; and van der Wal, O. 2023. Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. arXiv.
Black, S.; Gao, L.; Wang, P.; Leahy, C.; and Biderman, S. 2021. GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow.
Bulatov, A.; Kuratov, Y.; and Burtsev, M. 2022. Recurrent Memory Transformer. In Koyejo, S.; Mohamed, S.; Agarwal, A.; Belgrave, D.; Cho, K.; and Oh, A., eds., Advances in Neural Information Processing Systems, volume 35, 11079–11091. Curran Associates, Inc.
Burtsev, M. S.; Kuratov, Y.; Peganov, A.; and Sapunov, G. V. 2020. Memory transformer. arXiv.
Cho, K.; van Merriënboer, B.; Bahdanau, D.; and Bengio, Y. 2014. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, 103–111. Doha, Qatar: Association for Computational Linguistics.
Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.; and Salakhutdinov, R. 2019. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2978–2988. Florence, Italy: Association for Computational Linguistics.
de Moura, L.; Kong, S.; Avigad, J.; Van Doorn, F.; and von Raumer, J. 2015. The Lean theorem prover (system description). In Automated Deduction-CADE-25: 25th International Conference on Automated Deduction, Berlin, Germany, August 1-7, 2015, Proceedings 25, 378–388. Springer.
Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2019. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186.
Ding, J.; Ma, S.; Dong, L.; Zhang, X.; Huang, S.; Wang, W.; and Wei, F. 2023. Longnet: Scaling transformers to 1,000,000,000 tokens. arXiv.
Ding, S.; Shang, J.; Wang, S.; Sun, Y.; Tian, H.; Wu, H.; and Wang, H. 2021. ERNIE-Doc: A Retrospective Long-Document Modeling Transformer. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2914–2927. Online: Association for Computational Linguistics.
Fan, A.; Lavril, T.; Grave, E.; Joulin, A.; and Sukhbaatar, S. 2020. Addressing some limitations of transformers with feedback memory. arXiv.
Gao, L.; Biderman, S.; Black, S.; Golding, L.; Hoppe, T.; Foster, C.; Phang, J.; He, H.; Thite, A.; Nabeshima, N.; Presser, S.; and Leahy, C. 2020. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv.
Graves, A.; Wayne, G.; and Danihelka, I. 2014. Neural turing machines. arXiv.
Graves, A.; Wayne, G.; Reynolds, M.; Harley, T.; Danihelka, I.; Grabska-Barwińska, A.; Colmenarejo, S. G.; Grefenstette, E.; Ramalho, T.; Agapiou, J.; Badia, A. P.; Hermann, K. M.; Zwols, Y.; Ostrovski, G.; Cain, A.; King, H.; Summerfield, C.; Blunsom, P.; Kavukcuoglu, K.; and Hassabis, D. 2016. Hybrid computing using a neural network with dynamic external memory. Nature, 538(7626): 471–476.
Grefenstette, E.; Hermann, K. M.; Suleyman, M.; and Blunsom, P. 2015. Learning to Transduce with Unbounded Memory. arXiv.
Gu, A.; Goel, K.; and Re, C. 2021. Efficiently Modeling Long Sequences with Structured State Spaces. In International Conference on Learning Representations.
Gulcehre, C.; Chandar, S.; and Bengio, Y. 2017. Memory augmented neural networks with wormhole connections. arXiv.
Gulcehre, C.; Chandar, S.; Cho, K.; and Bengio, Y. 2016. Dynamic neural turing machine with soft and hard addressing schemes. arXiv.
Guo, M.; Ainslie, J.; Uthus, D.; Ontanon, S.; Ni, J.; Sung, Y.-H.; and Yang, Y. 2022. LongT5: Efficient Text-To-Text Transformer for Long Sequences. In Findings of the Association for Computational Linguistics: NAACL 2022, 724–736. Seattle, United States: Association for Computational Linguistics.
Guo, Q.; Qiu, X.; Liu, P.; Shao, Y.; Xue, X.; and Zhang, Z. 2019. Star-Transformer. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 1315–1325. Minneapolis, Minnesota: Association for Computational Linguistics.
Gupta, A.; and Berant, J. 2020. GMAT: Global memory augmentation for transformers. arXiv.
Hochreiter, S.; and Schmidhuber, J. 1997. Long Short-Term Memory. Neural Comput., 9(8): 1735–1780.
Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; de Las Casas, D.; Hendricks, L. A.; Welbl, J.; Clark, A.; Hennigan, T.; Noland, E.; Millican, K.; van den Driessche, G.; Damoc, B.; Guy, A.; Osindero, S.; Simonyan, K.; Elsen, E.; Vinyals, O.; Rae, J.; and Sifre, L. 2022. An empirical analysis of compute-optimal large language model training. In Koyejo, S.; Mohamed, S.; Agarwal, A.; Belgrave, D.; Cho, K.; and Oh, A., eds., Advances in Neural Information Processing Systems, volume 35, 30016–30030. Curran Associates, Inc.
Hu, E. J.; yelong shen; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; and Chen, W. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In International Conference on Learning Representations.
Hutchins, D.; Schlag, I.; Wu, Y.; Dyer, E.; and Neyshabur, B. 2022. Block-Recurrent Transformers. In Oh, A. H.; Agarwal, A.; Belgrave, D.; and Cho, K., eds., Advances in Neural Information Processing Systems.
Joulin, A.; and Mikolov, T. 2015. Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets. arXiv.
Lei, J.; Wang, L.; Shen, Y.; Yu, D.; Berg, T. L.; and Bansal, M. 2020. MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning. arXiv.
Liu, N. F.; Lin, K.; Hewitt, J.; Paranjape, A.; Bevilacqua, M.; Petroni, F.; and Liang, P. 2023. Lost in the middle: How language models use long contexts. arXiv.
Loshchilov, I.; and Hutter, F. 2019. Decoupled Weight Decay Regularization. In International Conference on Learning Representations.
mathlib Community, T. 2020. The lean mathematical library. In Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs. ACM.
McCulloch, W. S.; and Pitts, W. 1943. A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics, 5(4): 115–133.
Meng, Y.; and Rumshisky, A. 2018. Context-aware neural model for temporal information extraction. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 527–536.
OpenAI. 2023. GPT-4 Technical Report. arXiv.
Pang, R. Y.; Parrish, A.; Joshi, N.; Nangia, N.; Phang, J.; Chen, A.; Padmakumar, V.; Ma, J.; Thompson, J.; He, H.; and Bowman, S. 2022. QuALITY: Question Answering with Long Input Texts, Yes! In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 5336–5358. Seattle, United States: Association for Computational Linguistics.
Peng, B.; Alcaide, E.; Anthony, Q.; Albalak, A.; Arcadinho, S.; Cao, H.; Cheng, X.; Chung, M.; Grella, M.; GV, K. K.; et al. 2023. RWKV: Reinventing RNNs for the Transformer Era. arXiv.
Poli, M.; Massaroli, S.; Nguyen, E.; Fu, D. Y.; Dao, T.; Baccus, S.; Bengio, Y.; Ermon, S.; and Re, C. 2023. Hyena Hierarchy: Towards Larger Convolutional Language Models. In Krause, A.; Brunskill, E.; Cho, K.; Engelhardt, B.; Sabato, S.; and Scarlett, J., eds., Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, 28043–28078. PMLR.
Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; and Sutskever, I. 2019. Language Models are Unsupervised Multitask Learners.
Rae, J. W.; Hunt, J. J.; Harley, T.; Danihelka, I.; Senior, A.; Wayne, G.; Graves, A.; and Lillicrap, T. P. 2016. Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes. arXiv.
Rae, J. W.; Potapenko, A.; Jayakumar, S. M.; Hillier, C.; and Lillicrap, T. P. 2020. Compressive Transformers for Long-Range Sequence Modelling. In International Conference on Learning Representations.
Stephen, C. 1956. Kleene. Representation of events in nerve nets and finite automata. Automata studies.
Sukhbaatar, S.; Szlam, A.; Weston, J.; and Fergus, R. 2015. End-To-End Memory Networks. arXiv.
Sun, Y.; Dong, L.; Huang, S.; Ma, S.; Xia, Y.; Xue, J.; Wang, J.; and Wei, F. 2023. Retentive network: A successor to transformer for large language models. arXiv.
Werbos, P. J. 1990. Backpropagation through time: what it does and how to do it. Proceedings of the IEEE, 78(10): 1550–1560.
Weston, J.; Bordes, A.; Chopra, S.; and Mikolov, T. 2016. Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks. In Bengio, Y.; and LeCun, Y., eds., 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings.
Weston, J.; Chopra, S.; and Bordes, A. 2015. Memory Networks. In Bengio, Y.; and LeCun, Y., eds., 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings.
Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, 38–45.
Wu, Q.; Lan, Z.; Qian, K.; Gu, J.; Geramifard, A.; and Yu, Z. 2022a. Memformer: A Memory-Augmented Transformer for Sequence Modeling. In Findings of the Association for Computational Linguistics: AACL-IJCNLP 2022, 308–318. Online only: Association for Computational Linguistics.
Wu, Y.; Rabe, M. N.; Hutchins, D.; and Szegedy, C. 2022b. Memorizing Transformers. In International Conference on Learning Representations.
Zaheer, M.; Guruganesh, G.; Dubey, K. A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; and Ahmed, A. 2020. Big Bird: Transformers for Longer Sequences. In Larochelle, H.; Ranzato, M.; Hadsell, R.; Balcan, M.; and Lin, H., eds., Advances in Neural Information Processing Systems, volume 33, 17283–17297. Curran Associates, Inc.
Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X. V.; Mihaylov, T.; Ott, M.; Shleifer, S.; Shuster, K.; Simig, D.; Koura, P. S.; Sridhar, A.; Wang, T.; and Zettlemoyer, L. 2022. OPT: Open Pre-trained Transformer Language Models. arXiv, abs/2205.01068.
A Appendix: Training details
Efficiency of recurrence
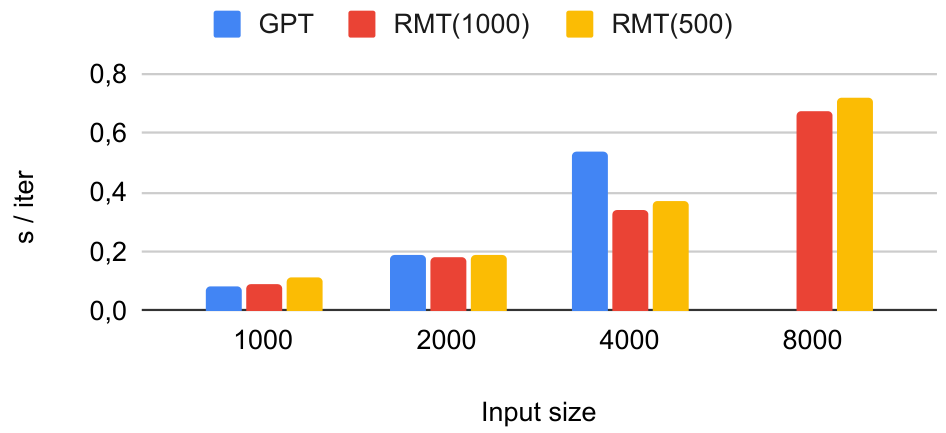
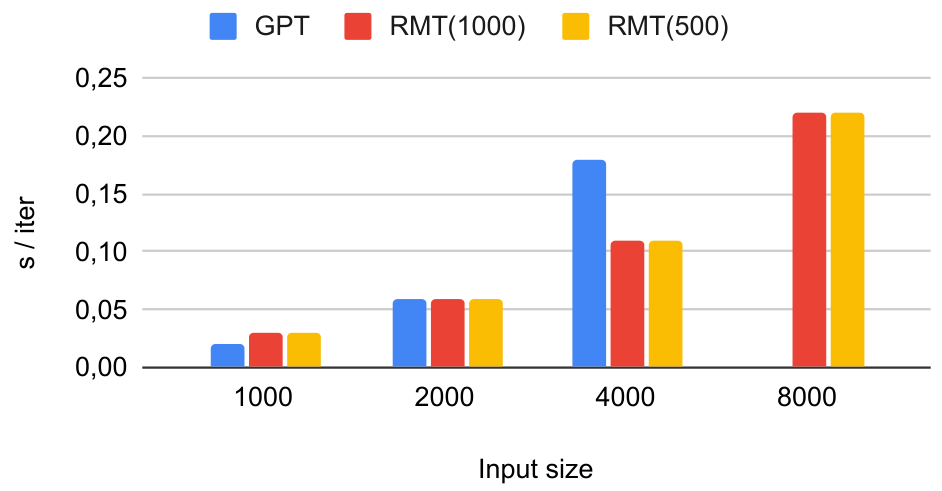
We compare the resource efficiency of RMT and full attention model by measuring GPU memory and iteration time on Figure 10. The tests were done on a single Nvidia A100 80GB GPU. We use reference GPT2 implementation from HuggingFace without FlashAttention and any other optimization techniques, and run models in FP32 mode.
RMT is not only more memory efficient but also faster than the standard transformer, even considering additional overhead from backpropagation through time, that can be turned off when the resources are limited. Baseline transformer fails to process sequences with length 8000 with out-of-memory error.
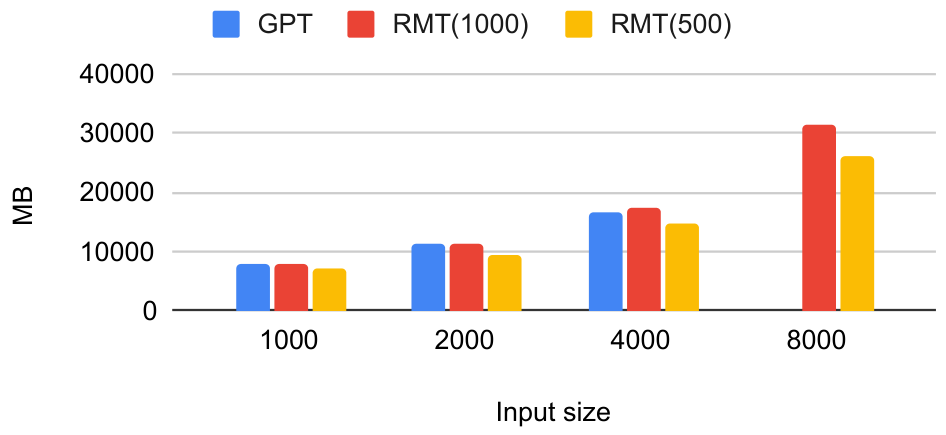
It is also worth noting that one of the key advantages of RMT is ability to train on shorter sequences, e.g. up to 8000 tokens and then leverage its generalization capabilities to process much larger sequences. During evaluation, computational requirements for RMT scale linearly, while memory requirements remain constant. This is due to the fact that only one segment is kept in GPU memory at a time during inference.
Synthetic task generation
Here we provide a concise description of memorization tasks. Code for dataset generation and reproducing all experiments can be found in the GitHub repository.
Memorization and Detect&Memorize datasets use questions and supporting facts from the qa1_single-supporting-fact subset of the bAbI dataset
Fact: [person] [action] [place]
Question: Where is [person]?
Answer: [place]
The [place] is selected from 6 options: ‘bathroom’, ‘hallway’, ‘garden’, ‘office’, ‘bedroom’, and ‘kitchen’. For the encoder-only BERT model the resulting task is formulated as a 6-class classification problem, each class being the separate answer option.
Following the bAbI pipeline, we create a fact and question pair by randomly choosing these options and construct a dataset sample as in Figure 3. In Memorize task, fact is always at the beginning of the input. Detect and Memorize places the fact in a random segment within a sequence. Reasoning task is created in a similar way using supporting facts and questions from the qa4_two-arg-relations bAbI subset; an example of such facts is presented at the end of the Memorization Tasks section.
A noteworthy limitation of the proposed tasks is the source of distractor text, that comes from a different distribution from questions and facts. This makes distinguishing questions trivial for the model. Nonetheless, this could be easily changed to any other texts even from closer distributions. We believe that extending the memorization dataset with complex questions and control over supporting fact position will help improve the way of processing long sequences. Combined with the proposed training schedule, fu
ture models can overcome the current limitations of Transformer
Impact of curriculum
In our experiments, we find that the curriculum learning plays an essential role in training RMT. To confirm the importance of the curriculum with a gradually increasing number of segments, we train RMT with and without the curriculum on the memorization task.
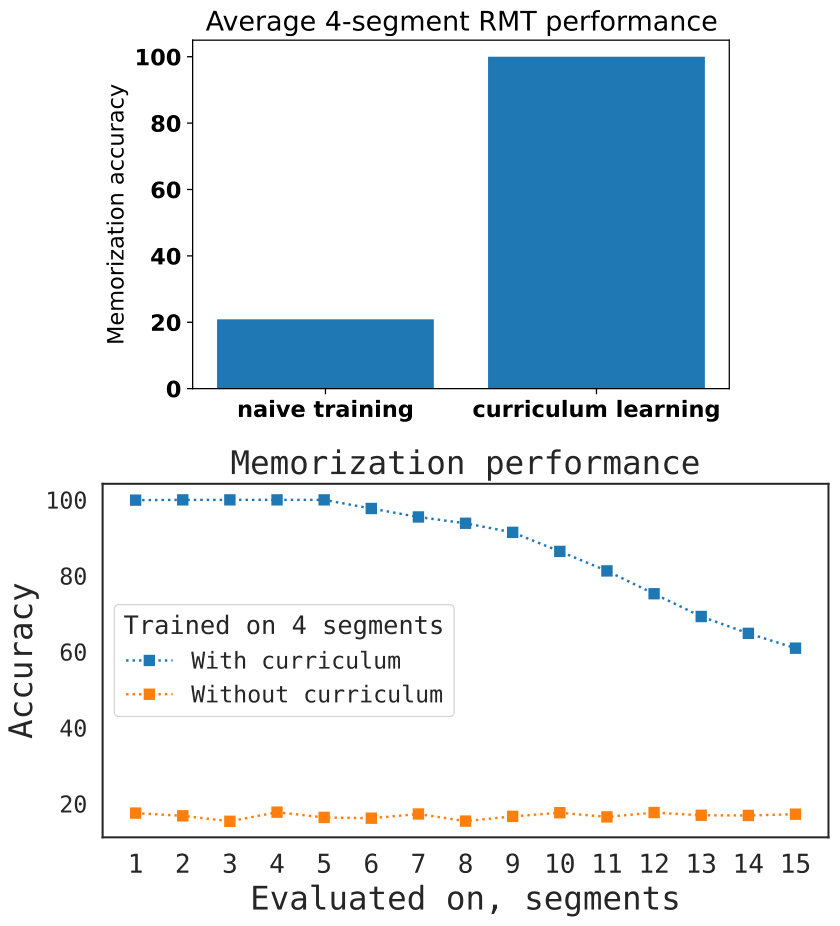
Figure 11 shows that in the absence of the curriculum, if the model is trained directly on the maximum number of segments, RMT does not learn neither to solve the task, nor to extrapolate on other sequence length. However, by using the curriculum, a much more capable model with strong generalization capabilities can be obtained.
On Figure 12 we also show that the curriculum learning procedure can be improved by adding samples from previous curriculum steps, i.e. at the step when we train on
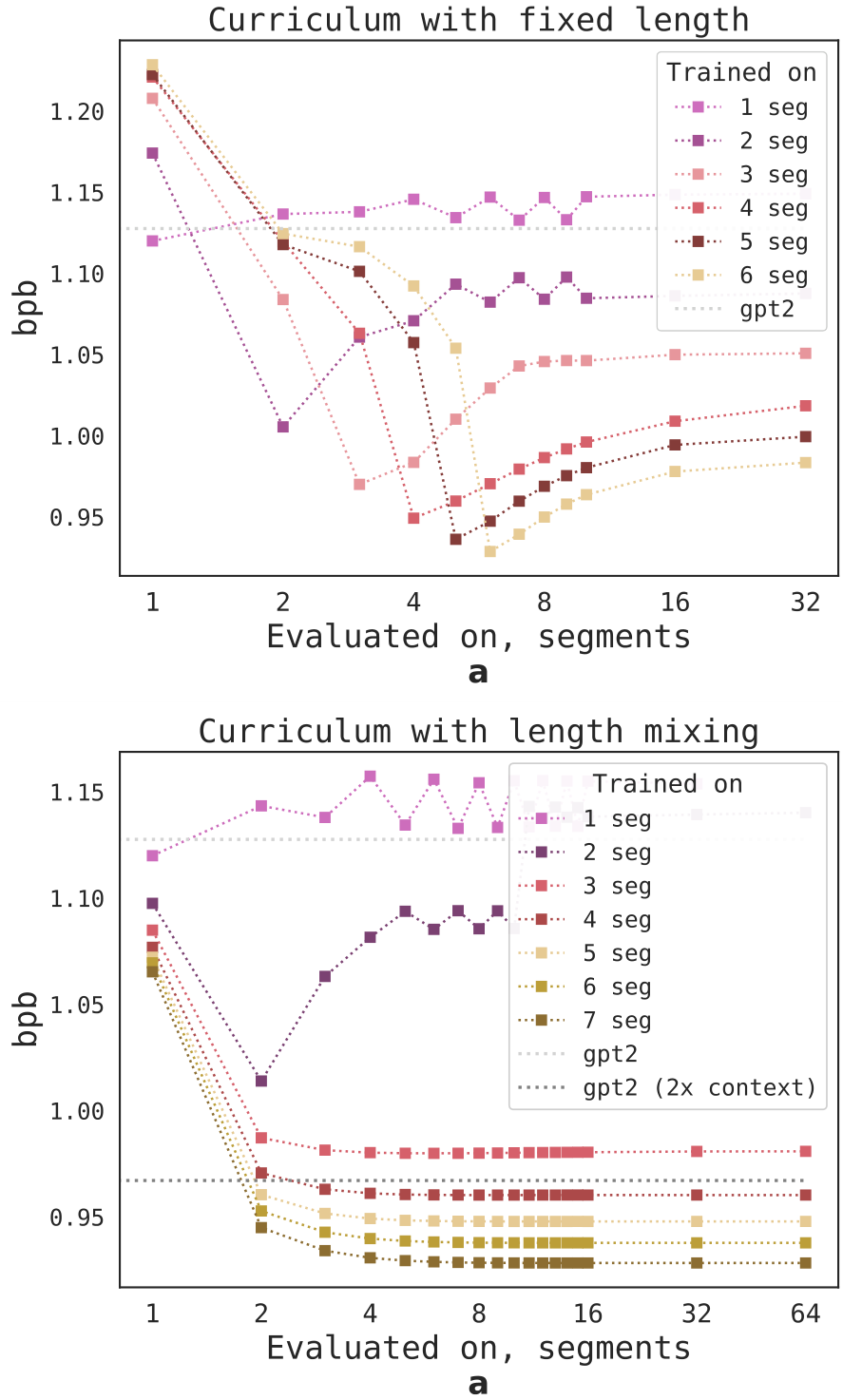
Usage of Parameter-Efficient Methods
One notable advantage of RMT is that the backbone architecture remains unchanged. This makes it possible to utilize existing parameter-efficient methods to modify only a small number of parameters to incorporate memory. The performance of RMT in combination with LoRA
Table 1: RMT can be successfully combined with parameter-efficient methods (parallel adapter, LoRA). Results for language modeling on the Arxiv dataset for Pythia-70m model.
| MODEL | LOSS |
|---|---|
| ADAPTER ONLY | 41.43 |
| ADAPTER + RMT-1SEG | 10.31 |
| ADAPTER + LORA + RMT-1SEG | 7.30 |
| ADAPTER + LORA + RMT-2SEG | 6.97 |
RMT offers the flexibility of incorporation various cost-efficient training methods, which greatly enhances its practical applicability, especially when computational resources are limited.