The Causally Emergent Alignment Hypothesis: Causal Emergence Aligns with and Predicts Final Reward in Reinforcement Learning Agents
Federico Pigozzi and Michael Levin
Allen Discovery Center, Tufts University, USA
Wyss Institute for Biologically Inspired Engineering, Harvard University, USA
Author for correspondence: michael.levin@allencenter.tufts.edu
Abstract
A hallmark of life on Earth is the ability of agents to exert causal power and be drivers of subsequent events. This is key to cognition at all scales. Causal emergence, measuring the degree to which an agent exerts unique predictive power on its future, is one consequence of causal power. Indeed, recent discoveries have shown that biological agents, even minimal ones, increase their causal emergence after learning new memories. However, there is a major knowledge gap regarding how causally emergent artificial agents are. We focused on Reinforcement Learning (RL) of neural-network agents across an array of environmental conditions, encompassing different algorithms, agent architectures, and six environments arranged on a complexity spectrum. For consistency, we computed the causal emergence of their latent-space representations over their lifetimes. We used the recently proposed
Submission type: Full Paper
Data/Code available at: GitHub
Introduction and Related Work
A key component of living beings is their ability to act as causal agents: they exert causal power, the ability of a composite system (like a living organism made of cells and organs) to be a driver of subsequent events
Causal emergence of an agent is one symptom of causal power. The causal emergence of a system measures the degree to which the whole is greater than the sum of the parts
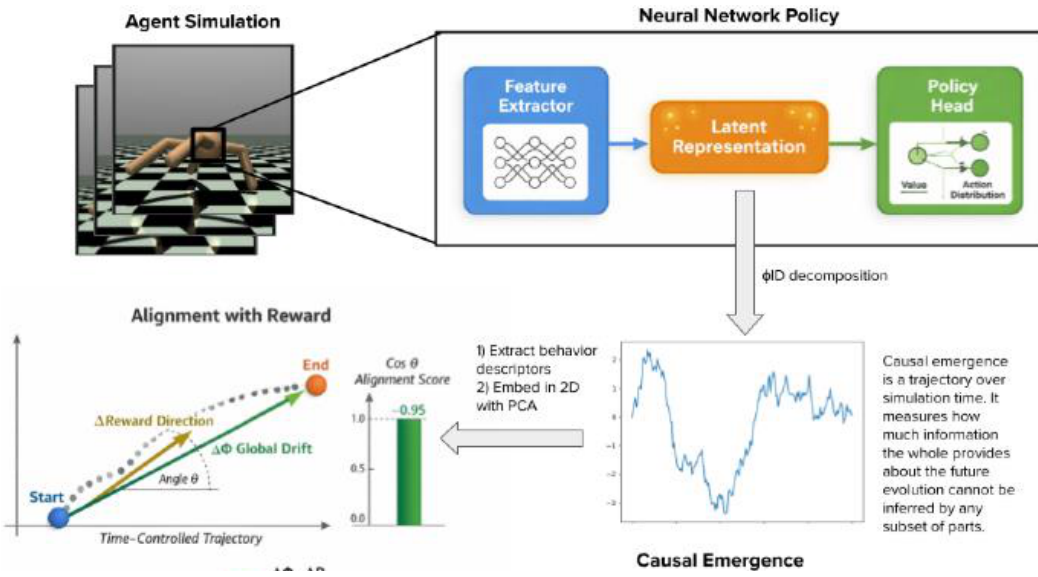
Among the different embodiments of causal emergence, we adopted the
Our recent study
were found to increase their causal emergence after Pavlovian conditioning had induced associative memories
This raises the question: can the same phenomenon occur in artificial agents? The field of diverse intelligence seeks to adopt tools from neuroscience and the behavioral sciences (conventionally used for brainy animals) in unconventional contexts, envisioning a continuum of cognitive abilities from active matter to conventionally intelligent agents
Previous research at the intersection of RL and causal emergence found that integrated information (measured with Tononi’s
We trained RL agents across a wide range of conditions, encompassing two RL algorithms, two agent architectures, and six environments distributed across a complexity spectrum (from Pendulum to Crafter). In this way, we ensured that the observed phenomena were robust to the experimental setup and reflected general properties of learning. The latent space of the neural network policy was used as a substrate because it is consistent across all environments and provides a sufficiently rich representation. If we go back to the ant colony analogy, the “parts” are the dimensions of the latent space (hidden layer neurons), while the “whole” is the latent space representation itself. We present a schematic of our pipeline in Figure 1.
Our analyses showed that causal emergence strongly aligned with the long-term (though not short-term) reward, suggesting that it provided a slow directional signal to behavior improvement. Chiefly, causal emergence from early on in training predicted final reward better than a set of standard representational metrics, meaning that it was also an early indicator of performance. Taken together, we frame these phenomena as the Causal Emergence Alignment Hypothesis: successful agents are those with causally emergent representations that reorganize in directions that, in most tasks, align with reward and are always predictive of final learning outcomes.
In the future, we envision these findings as a basis for revealing causal emergence as a new interventional approach for RL agents. Our results also suggest parallels between biological and artificial systems, thus highlighting how in silico experimentation complements the study of in vivo systems.
Materials and Methods
We present the methods relevant to this study.
Causal Emergence
Information Decomposition
Information theory, originally introduced to study the transmission capacity of communication channels, has emerged as a principled language for evaluating dependencies in complex systems, including artificial and biological systems. The basic object of study is Shannon’s entropy:
Where the summation is over the support of
But what if there is more than one source variable, as in complex systems like RL neural network policies? We must then consider all the different directions in which information can flow in a system. Intuitively, let us consider the case of stereoscopic vision in humans: with one eye open, we perceive a unique set of visual features for each eye, as well as redundant features captured by both eyes. Depth perception, which can only be captured if both eyes are open simultaneously, corresponds instead to synergistic information. The seminal work on Partial Information Decomposition 1 (PID) provides a framework for partitioning mutual information into these three information atoms (redundant, unique, and synergistic).
Causal Emergence
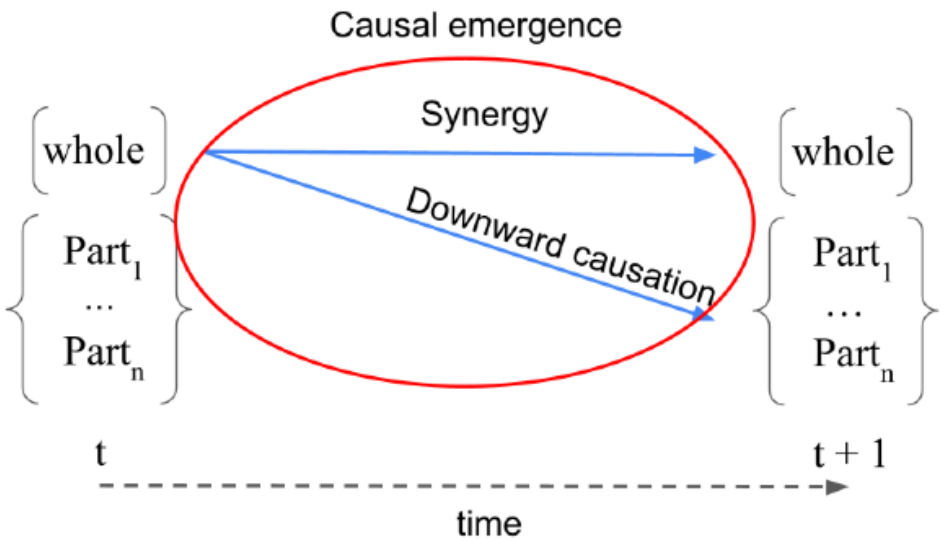
Our latent space trajectories are multivariate, consisting of the activations of several neurons. We relied on the recent framework of Integrated Information Decomposition
- Downward causation: the amount of information that the whole predicts about the future of the single components.
- Synergy: the amount of information that the whole predicts about the future of the whole.
We illustrate the definition in Figure 2 for a generic system made of
Other measures of agent integration exist, such as total correlation and co-information. But, they are instantaneous measures; they fail to capture the temporal and causal aspects of information dependencies up to and including all future time steps, a crucial aspect for dynamical systems that evolve over time
Gaussian Information Theory
Information theory was originally defined for discrete random variables, but our representations, being neural network activations, are continuous-valued. Hence, we used the continuous generalization of Shannon’s entropy, the differential entropy:
This integral is generally hard to compute because it requires estimating
Where
Most practical computations of causal emergence converge on the same simple form for Gaussian continuous variables that we adopted here. We first computed the lag-1 mutual information matrix for all node pairs in the system using the equation above
Reinforcement Learning and substrate
RL
We adopted the standard agent architecture from the literature. At each time step
Causal emergence computes the agent integration within a system, but what counts as the system in our case? We wanted a system representation that is:
- Low-dimensional enough to make the
phi I D computation tractable and not noisy; - Dynamically rich enough to show meaningful variation;
- Consistent across environments and architectures.
With these desiderata in mind, we found the latent
In the following, we computed causal emergence on the latent representation trajectories
Data Preprocessing
Gaussian Information Theory assumes that the variables are jointly Gaussian. Since this is hardly ever true for neural activations, we applied a copula-based Gaussianization (rank-normal transform) to ensure approximate marginal normality. After this transformation, only a minority of all units (28.53%) rejected the normality hypothesis
Environments
We ran all the experimental combinations across six OpenAI Gymnasium2 environments (except CrafterReward, which comes in its own library3), as shown in Figure 3. Our environments spanned a complexity spectrum, from least to most complex:
- Pendulum-v1: The agent applies the torque to keep the pole in an upright position. It is a classic task with minimal state and action dimensions.
- Lunar-Lander-v2: The agent turns the engines on or off to land as close as possible to a landing pad. It is a more complex control task, with more actions and states.
- BipedalWalker-v4: The agent controls a bipedal 2D robot to walk upright as far as possible. It has a high-dimensional state space.
- Walker2D-v4: The agent controls a bipedal robot 3D consisting of seven body parts. It is embodied, with continuous states, actions, and non-trivial body dynamics.
- Ant-v4: The agent controls a four-legged 3D ant consisting of nine body parts. It is embodied, with continuous states, actions, and non-trivial body dynamics.
- CrafterReward-v1: In the 2D version of Minecraft, the agent must survive as long as possible while gathering resources and fending off enemies. It requires long-term planning and exploration skills.

Architectures and Algorithms
To experiment with a broad range of conditions, we tested two architectures and two RL algorithms across all environments. As architectures, we used a feed-forward (MLP) and a recurrent neural network (GRU) because they impose different inductive biases on representations (static vs. temporally dependent), allowing us to isolate the effect of architectural inductive biases (memory vs. non-memory).
We implemented the MLP using the default stable-baselines3 policy architecture. For the sake of fairness, we implemented the GRU variant using the same architecture as the MLP, but with a GRU block added on top of the feature extractor. This resulted in slightly different parameter counts for the two variants, but our focus was how causal emergence behaved across different
architectural classes (memory vs. memoryless) rather than performance or capacity equivalence. We also remark that for CrafterReward, whose state space consists of images, we replaced the feed-forward feature extractor with the same convolutional backbone used in
As algorithms, we employed Proximal Policy Optimization
Experimental Parameters
For each environment algorithm architecture combination, we performed 10 runs with different random seeds for reproducibility. Every
For each episode, we computed the causal emergence trajectory over the simulation’s history of latent-space activations and aggregated it with the median to have a robust summary, as previously done in
Each run lasted stable-baselines3 values to isolate the representation effect from tuning and report the results for off-the-shelf, widely used settings.
We coded all experiments and analyses in Python and made them publicly available at GitHub.
Results
To understand how causal emergence reacted to learning, we answered the following Research Questions (RQ):
- RQ0: Does causal emergence capture novel information? In other words, does it overlap with known representation metrics?
- RQ1: Does causal mergence align and move with the reward?
- RQ2: Does causal emergence predict learning outcomes?
This transition gradually deepened our task from descriptive to functional, and then to predictive.
RQ0: Did causal emergence correlate with known representation metrics?
To ensure our causal emergence approach captured a novel axis of representation shift, we tested whether it was uncorrelated with other established neural representation metrics. Our metrics were standard measures from information theory and dynamical systems: entropy, Shannon mutual information, autocorrelation, effective dimension, and magnitude of the latent representations.
For each run of every experimental combination, we computed Spearman’s
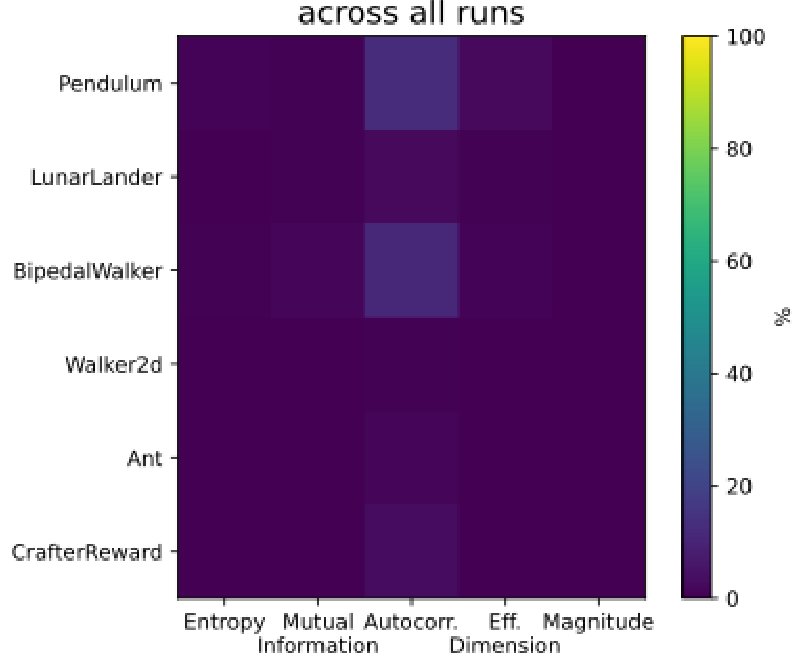
environment (y-axis). Deep purple dominates the array, with a maximum value of only 6% for Autocorrelation+Pendulum, meaning that causal emergence did not generally correlate with established representation metrics of neural latents.
RQ1: Did causal emergence align with the reward?
Having established that causal emergence did not overlap with existing representation metrics, we investigated whether its changes were oriented toward improving performance. Concretely, we computed the reward alignment of a trajectory
- Embed the trajectory using PCA to have a low-dimensional embedding
e in R to the m ; - Fit a linear model with coefficients
w in R to the m to predictr frome ; - Interpret the coefficients
w as a reward gradient in the embedding space; - Compute the cosine similarity between
w and the global direction (i.e., end minus start, for global reward alignment) or the mean of the instantaneous directions (for local reward alignment):
Global Reward Alignment
Local Reward Alignment
Both scores took values in . A high alignment meant that the representation metric under consideration proceeded in the direction of increasing reward, linking representational dynamics to functional improvement.
Reward alignment measured directional consistency between representational change and performance improvement. Other measures, such as statistical correlations and regression coefficients, capture association but not the trajectory over time. Similarly, distance metrics ignore whether the change is useful for reward. In other words, reward alignment evaluated if the metric’s path was effectively goal-directed and linked to behavior.
To embed a causal emergence trajectory, we described it with seven “behavior” descriptors that were found to be the most expressive and compact at the same time
- Standard deviation: a measure of dispersion.
- Trend: the slope of the least squares fit of the trajectory. A positive slope indicated an increasing trend, while a negative slope indicated a decreasing trend.
- Monotonicity: the Kendall’s tau coefficient between the trajectory and the sequence of its time stamps. Kendall’s tau is a standard statistic to measure ordinal association between two quantities, and in our case, it was the highest for a perfectly monotonically increasing trajectory, and the lowest for a perfectly monotonically decreasing one, with values around zero corresponding to the trajectory fluctuating independently of the time axis.
- Flatness: how flat the trajectory was and did not locally deviate from the mean. We divided the trajectory into consecutive intervals and approximated it with the mean of each interval. We computed flatness as the R-squared coefficient of this approximation: the higher the coefficient, the better the fit of the local means, indicating that the trajectory was locally flat (though jumps may have occurred at the interval boundaries). After preliminary experiments, we found an interval size of 100 to be sufficient to capture the intuition behind a trajectory’s flatness.
- Number of peaks: the number of local minima and maxima of the trajectory.
- Average distance among peaks: the average distance among all the peaks from 4) (or 0 if there were none).
- Average difference among peaks: the average difference in causal emergence value of the peaks from 4) (or 0 if there were none).
- Range: the difference in causal emergence value between the maximum and the minimum peaks.
For step 1), we tested
Table 1 shows the global and local alignment scores for causal emergence. The global alignment scores were of large magnitude, indicating that causal emergence aligned strongly with the same (or opposite) direction as reward improvement. Also, the sign was positive in a majority
(5/6) of environments, meaning the same direction, whereas negative in CrafterReward, which may be linked to more time spent on early exploration for that task. Contrarily, the local alignment scores were approximately zero. This meant that causal emergence captured the agent’s long-term “representation shift” or behavioral adaptation, but not the step-by-step improvements in reward, which were noisy or canceled each other out.
| Global Reward Alignment | Local Reward Alignment | |
|---|---|---|
| Pendulum | 0.99 | 0.00 |
| LunarLander | 1.00 | 0.00 |
| BipedalWalker | 0.86 | 0.00 |
| Walker2D | 0.35 | 0.03 |
| Ant | 0.49 | 0.02 |
| CrafterReward | -0.95 | 0.00 |
We found the global alignment scores of causal emergence to be significantly greater than those obtained with random projections
RQ2: Did causal emergence predict the final reward performance, and how did it compare to the baselines?
Correlation alone does not prove if a measure is relevant for learning. Hence, we moved to a predictive setting, asking whether early measurements of these predictors foreshadowed final performance. This reframed the question to understand if it captured information that mattered for learning outcomes.
To answer this question, we trained a machine learning model to predict the reward at the last time step (taken as the median over the last 10 test episodes), using as input the representation metrics from the first
Figure 5 shows the results, one plot per environment, with Spearman’s
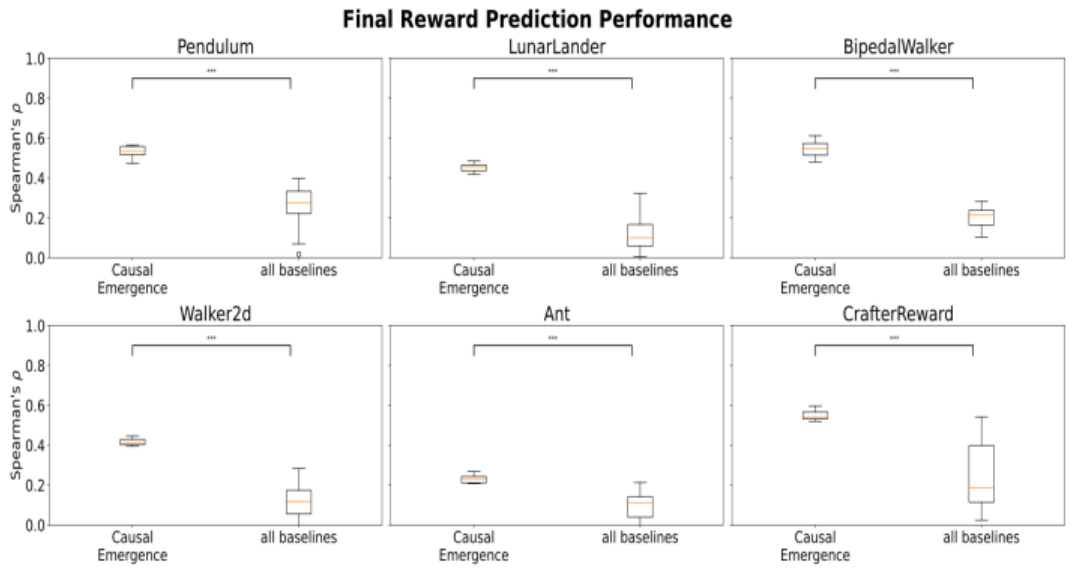
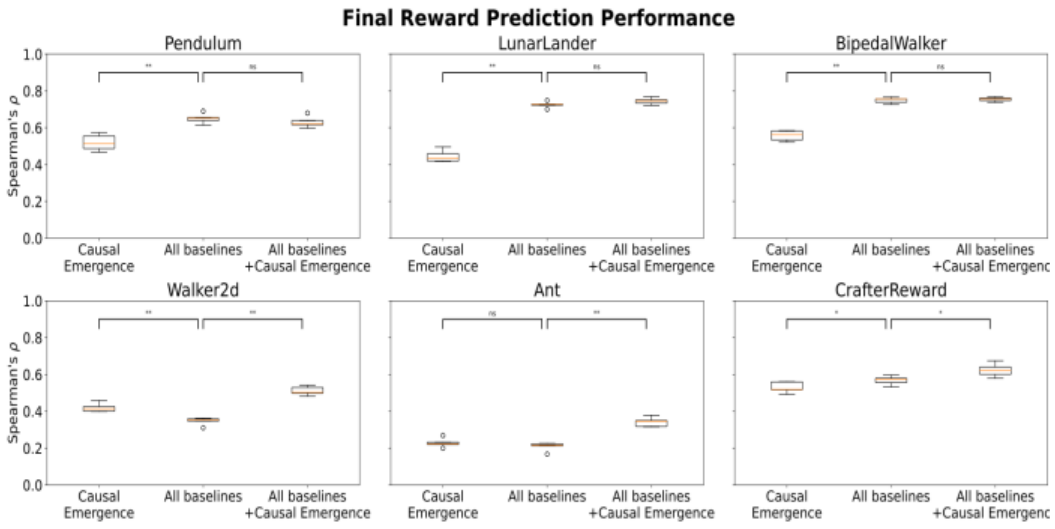
To push our analysis one step further, we repeated the experiment, using all baselines together as predictors for the same model (rather than one at a time and reporting the best), and then repeated the experiment with the addition of causal emergence descriptors. We reported the results in Figure 6, using the same syntax as Figure 5.
The plots and the significance tests (with Mann-Whitney) revealed that this time, causal emergence was worse in 4/6 environments, the same in 1/6, and better in 1/6. Conversely, adding causal emergence to the baselines
did not worsen performance in 3/6 environments and improved it in the other 3.
Discussion
Causal emergence trajectories had very strong global but near-zero local reward alignment across all environments. Reward alignment captured the degree to which the changes in the representation metric aligned with the direction that improved learning. This suggested that learning induced a slow, long-term representational reorganization that was captured by causal emergence, whereas local changes were noisy or canceled out. Complementing this result, we found that causal emergence was a better predictor of final learning performance than standard representational metrics like entropy, Shannon mutual information, autocorrelation, effective dimension, and magnitude. This meant that the captured aspects of representation reorganization were functionally relevant for downstream learning, beyond standard metrics. Together, these results suggested that causal emergence provided a directional signal and an early indicator of final performance.
Notably, causal emergence was a better predictor when the baselines were considered separately. This suggested that causal emergence was not “the best predictor of all,” but rather a low-dimensional summary of several representational metrics; in other words, it did not redundantly overlap with them but instead compressed distributed, weaker signals into a single geometric object, in line with recent discoveries for manifold learning
We concluded that successful RL agents have causally emergent representations that reorganize in directions that align with reward and are always predictive of final learning outcomes. This is consistent with a prior proposal in which an agent’s border is determined by the size of its goals; like cells adapting to reach homeostasis, RL agents reach a preferred state and establish selves, which is what causal emergence may be capturing
In the future, we will investigate whether predicting learning also implies causality; in other words, if intervention in the causal emergence space affects learning in a directed manner. If this held true, causal emergence would potentially spur advances in RL algorithms. We also look forward to testing not only the causal emergence of an agent, but also the interactions between the agent and its environment, possibly drawing on the active inference
In addition to these experiments, we will address the main limitation of this work: that any conclusions we draw are limited by the array of experimental conditions we considered. We will extend our analyses to more complex architectures, like world models
When considered in the context of the biological literature, our results demonstrate a new parallel between biological and artificial creatures. Indeed, biological substrates such as gene regulatory networks have been found to exhibit similar causal emergence in response to learning
Acknowledgements
We thank Patrick McMillen for the ant colony analogy to explain causal emergence, and Astonishing Labs for their
support via a sponsored research agreement.
References
Biswas, S., W. Clawson, and M. Levin. 2023. ‘Learning in Transcriptional Network Models: Computational Discovery of Pathway-Level Memory and Effective Interventions’, International Journal of Molecular Sciences, 24.
Blackiston, D., H. Dromiack, C. Grasso, T. F. Varley, D. G. Moore, K. K. Srinivasan, O. Sporns, J. Bongard, M. Levin, and S. Walker. 2025. ‘Revealing non-trivial information structures in aneural biological tissues via functional connectivity’, Plos Computational Biology, 21.
Clawson, W. P., and M. Levin. 2023. ‘Endless forms most beautiful 2.0: teleonomy and the bioengineering of chimaeric and synthetic organisms’, Biological Journal of the Linnean Society, 139: 457-86.
Edlund, J. A., N. Chaumont, A. Hintze, C. Koch, G. Tononi, and C. Adami. 2011. ‘Integrated Information Increases with Fitness in the Evolution of Animats’, Plos Computational Biology, 7.
Etcheverry, M., C. Moulin-Frier, P. Y. Oudeyer, and M. Levin. 2025. ‘AI-driven automated discovery tools reveal diverse behavioral competencies of biological networks’, Elife, 13.
Fields, C., A. Goldstein, and L. Sandved-Smith. 2024. ‘Making the Thermodynamic Cost of Active Inference Explicit’, Entropy, 26.
Gao, H. C., T. R. Xu, T. R. Zhang, Y. Q. Guo, C. J. Zhao, J. S. Ren, Y. Z. Jiang, S. Q. Guo, and F. Chen. 2025. ‘Causal dreamer for partially observable model-based reinforcement learning’, Neurocomputing, 652.
Ghosh, D., J. Rahme, A. Kumar, A. Zhang, R. P. Adams, and S. Levine. 2021. ‘Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability’, Advances in Neural Information Processing Systems 34 (Neurips 2021).
Gottlieb, J., P. Y. Oudeyer, M. Lopes, and A. Baranes. 2013. ‘Information-seeking, curiosity, and attention: computational and neural mechanisms’, Trends in Cognitive Sciences, 17: 585-93.
Grasso, C., and J. Bongard. 2023. ‘Selection for short-term empowerment accelerates the evolution of homeostatic neural cellular automata’, Proceedings of the 2023 Genetic and Evolutionary Computation Conference, Gecco 2023: 147-55.
Ha, D., and J. Schmidhuber. 2018. ‘Recurrent World Models Facilitate Policy Evolution’, Advances in Neural Information Processing Systems 31 (Nips 2018), 31.
Haarnoja, T., A. Zhou, P. Abbeel, and S. Levine. 2018. ‘Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor’, International Conference on Machine Learning, Vol 80, 80.
He, H. R., P. L. Wu, C. J. Bai, H. Lai, L. X. Wang, L. Pan, X. L. Hu, and W. N. Zhang. 2024. ‘Bridging the Sim-to-Real Gap from the Information Bottleneck Perspective’, Conference on Robot Learning, 270.
Hoel, E. P., L. Albantakis, and G. Tononi. 2013. ‘Quantifying causal emergence shows that macro can beat micro’, Proceedings of the National Academy of Sciences of the United States of America, 110: 19790-95.
Kitazono, J., R. Kanai, and M. Oizumi. 2018. ‘Efficient Algorithms for Searching the Minimum Information Partition in Integrated Information Theory’, Entropy, 20.
Klyubin, A. S., D. Polani, and C. L. Nehaniv. 2005. ‘Empowerment: A universal agent-centric measure of control’, 2005 Ieee Congress on Evolutionary Computation, Vols 1-3, Proceedings: 128-35.
Krakauer, D., N. Bertschinger, E. Olbrich, J. C. Flack, and N. Ay. 2020. ‘The information theory of individuality’, Theory in Biosciences, 139: 209-23.
Levin, M. 2019. ‘The Computational Boundary of a “Self”: Developmental Bioelectricity Drives Multicellularity and Scale-Free Cognition’, Frontiers in Psychology, 10.
Levin, M. 2022. ‘Technological Approach to Mind Everywhere: An Experimentally-Grounded Framework for Understanding Diverse Bodies and Minds’, Frontiers in Systems Neuroscience, 16.
Luppi, A. I., P. A. M. Mediano, F. E. Rosas, J. Allanson, J. D. Pickard, G. B. Williams, M. M. Craig, P. Finoia, A. R. D. Peattie, P. Coppola, D. K. Menon, D. Bor, and E. A. Stamatakis. 2023. ‘Reduced emergent character of neural dynamics in patients with a disrupted connectome’, Neuroimage, 269.
McMillen, P., and M. Levin. 2024. ‘Collective intelligence: A unifying concept for integrating biology across scales and substrates’, Communications Biology, 7.
Mediano, P. A. M., F. E. Rosas, A. I. Luppi, R. L. Carhart-Harris, D. Bor, A. K. Seth, and A. B. Barrett. 2025. ‘Toward a unified taxonomy of information dynamics via Integrated Information Decomposition’, Proceedings of the National Academy of Sciences of the United States of America, 122.
Mnih, V., K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis. 2015. ‘Human-level control through deep reinforcement learning’, Nature, 518: 529-33.
Mohanty, S., J. Poonganam, A. Gaidon, A. Kolobov, B. Wulfe, D. Chakraborty, G. Semetulskis, J. Schapke, J. Kubilius, J. Paükonis, L. Klimas, M. Hausknecht, P. MacAlpine, Q. N. Tran, T. Tumiel, X. C. Tang, X. W. Chen, C. Hesse, J. Hilton, W. H. Guss, S. Genc, J. Schulman, and K. Cobbe. 2020. ‘Measuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen
Benchmark’, Neurips 2020 Competition and Demonstration Track, Vol 133, 133: 361-95.
Neftci, E. O., and B. B. Averbeck. 2019. ‘Reinforcement learning in artificial and biological systems’, Nature Machine Intelligence, 1: 133-43.
Pigozzi, F., A. Goldstein, and M. Levin. 2026. ‘Associative conditioning in gene regulatory network models increases integrative causal emergence (vol 8, 1027, 2025)’, Communications Biology, 9.
Raffin, A., A. Hi, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann. 2021. ‘Stable-Baselines3: Reliable Reinforcement Learning Implementations’, Journal of Machine Learning Research, 22: 1-8.
Rosas, F. E., P. A. M. Mediano, M. Gastpar, and H. J. Jensen. 2019. ‘Quantifying high-order interdependencies via multivariate extensions of the mutual information’, Physical Review E, 100.
Rosas, F. E., P. A. M. Mediano, H. J. Jensen, A. K. Seth, A. B. Barrett, R. L. Carhart-Harris, and D. Bor. 2020. ‘Reconciling emergences: An information-theoretic approach to identify causal emergence in multivariate data’, Plos Computational Biology, 16.
Savva, M., A. Kadian, O. Maksymets, Y. L. Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V. Koltun, J. Malik, D. Parikh, and D. Batra. 2019. ‘Habitat: A Platform for Embodied AI Research’, 2019 Ieee/Cvf International Conference on Computer Vision (Iccv 2019): 9338-46.
Sutton, Richard S., and Andrew G. Barto. 2018. Reinforcement learning : an introduction (The MIT Press: Cambridge, Massachusetts).
Tishby, N., and N. Zaslavsky. 2015. ‘Deep Learning and the Information Bottleneck Principle’, 2015 Ieee Information Theory Workshop (Itw).
Tok, A. Y. F., N. L. Powell, and B. Guellaï. 2025. ‘A systematic review of moral agency in artificial agents’, Discover Psychology, 6.
Toker, D., and F. T. Sommer. 2019. ‘Information integration in large brain networks’, Plos Computational Biology, 15.
Tononi, G., M. Boly, M. Massimini, and C. Koch. 2016. ‘Integrated information theory: from consciousness to its physical substrate’, Nature Reviews Neuroscience, 17: 450-61.
Varley, T. F., P. A. M. Mediano, A. Patania, and J. Bongard. 2025. ‘The topology of synergy: Linking topological and information-theoretic approaches to higher-order interactions in complex systems’, Plos Computational Biology, 21.
Vernon, D., R. Lowe, S. Thill, and T. Ziemke. 2015. ‘Embodied cognition and circular causality: on the role of constitutive autonomy in the reciprocal coupling of perception and action’, Frontiers in Psychology, 6.
Watson, J. R., A. Maier, A. Novillo, I. Echegoyen, R. Resta, R. L. del Campo, and J. M. Buldú. 2026. ‘Information integration and the latent consciousness of human groups’, Chaos Solitons & Fractals, 203.