# Training Language Models via Neural Cellular Automata
Dan Lee 1,∗ Seungwook Han 2,3,∗ Akarsh Kumar 2 Pulkit Agrawal 2,3 1Independent Contributor 2MIT 3Improbable AI Lab
arXiv:2603.10055v1 [cs.LG] 9 Mar 2026
Abstract
Pre-training is crucial for large language models (LLMs), as it is when most representations and capabilities are acquired. However, natural language pre-training has problems: high-quality text is finite, it contains human biases, and it entangles knowledge with reasoning. This raises a fundamental question: is natural language the only path to intelligence? We propose using neural cellular automata (NCA) to generate synthetic, non-linguistic data for pre-pre-training LLMs—training on synthetic-then-natural language. NCA data exhibits rich spatiotemporal structure and statistics resembling natural language while being controllable and cheap to generate at scale. We find that pre-pre-training on only 164M NCA tokens improves downstream language modeling by up to 6% and accelerates convergence by up to 1.6×one point six times. Surprisingly, this even outperforms pre-pre-training on 1.6B tokens of natural language from Common Crawl with more compute. These gains also transfer to reasoning benchmarks, including GSM8K, HumanEval, and BigBench-Lite. Investigating what drives transfer, we find that attention layers are the most transferable, and that optimal NCA complexity varies by domain: code benefits from simpler dynamics, while math and web text favor more complex ones. These results enable systematic tuning of the synthetic distribution to target domains. More broadly, our work opens a path toward more efficient models with fully synthetic pre-training.
*Equal contribution. Correspondence to: Dan Lee , Seungwook Han .
1. Introduction
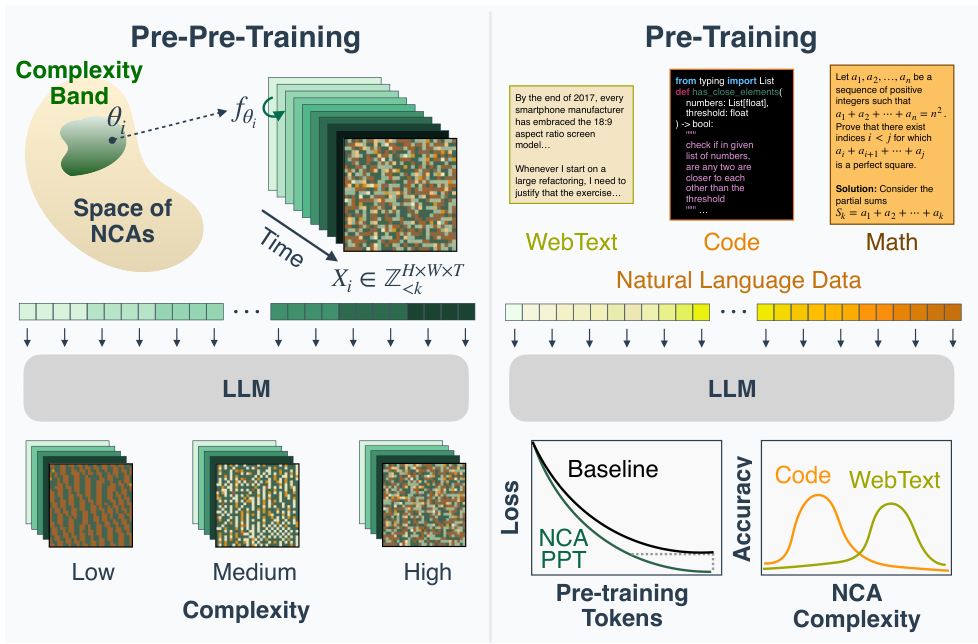
Figure 1. Overview of NCA Pre-pre-training to Language Pre-training. We pre-pre-train a transformer with next-token prediction on the dynamics of neural cellular automata (NCA) sampled from selected complexity regions. We then conduct standard pre-training on natural language corpora. NCA pre-pre-training improves both validation perplexity and convergence speed on language pre-training. Interestingly, the optimal NCA distribution varies by downstream domain.
Scale has transformed neural networks, enabling emergent abilities like reasoning (Jaech et al., 2024; Jiang, 2023; Austin et al., 2021)as shown in prior work and in-context learning (Brown et al., 2020; Wei et al., 2022; Zhao et al., 2024)by Brown and others in large language models (LLMs). However, neural scaling laws predict that continued improvements require exponentially more data (Kaplan et al., 2020), which is nearing exhaustion by 2028 (Villalobos et al., 2022). Furthermore, natural language inherits many undesirable human biases and needs tedious data curation and cleaning before it is used for training foundation models (Han et al., 2025a; An et al., 2024). This raises a fundamental question: Is natural language the only path to learning useful representations? In this paper, we explore an alternative path to using synthetic data from cellular automata.
Our core hypothesis is that the emergence of reasoning and other abilities in LLMs relies on the underlying structure
of natural language, rather than its semantics. Text is a lossy record of human cognition and the world it describes, containing diverse kinds of structure, from reasoning traces to procedural instructions (Ribeiro et al., 2023; Ruis et al., 2024; Cheng et al., 2025; Delétang et al., 2024). Next-token prediction on such data pressures models to internalize the latent computational processes that support coherent continuations, fostering key capabilities of intelligence (Delétang et al., 2023; Jiang, 2023).
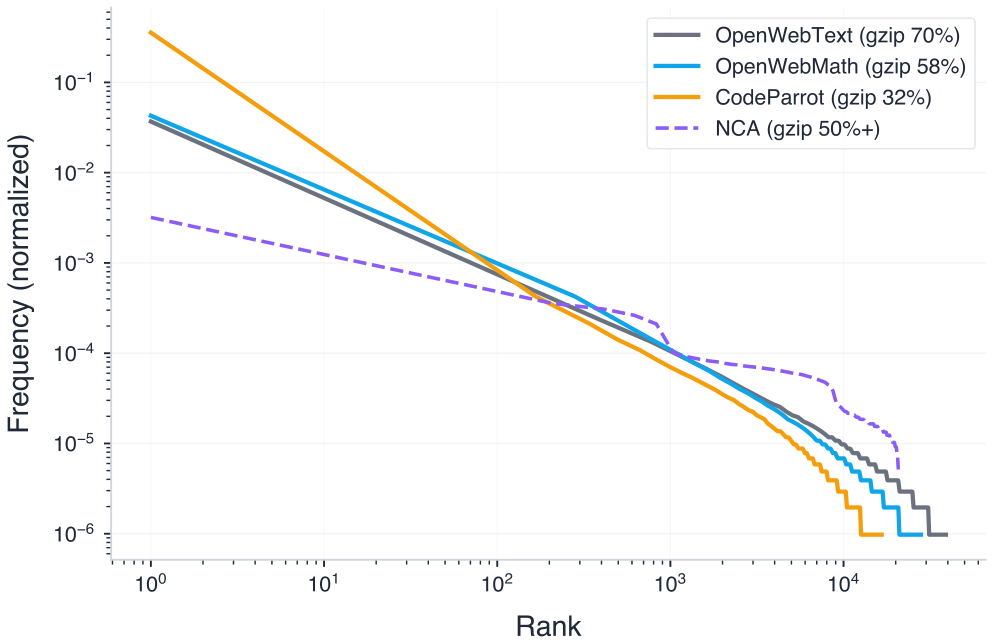
If the key ingredient is exposure to various structures rather than language semantics, then richly structured non-linguistic data could also be effective for teaching models to reason. To investigate this hypothesis, we employ algorithmically generated synthetic data from neural cellular automata (NCA) (Mordvintsev et al., 2020) as a synthetic training substrate. NCA generalize systems like Conway’s Game of Life (Gardner, 1970) by replacing fixed dynamics rules with neural networks and can be used to generate diverse data distributions with spatially local rules. This produces long-range spatio-temporal patterns (see Figure 1) of arbitrary sizes that exhibit heavy-tailed, Zipfian token distributions (see Figure 8 in Appendix A) reminiscent of natural data. Crucially, we propose a method to explicitly control the complexity of NCA, enabling systematic tuning of the synthetic data distribution for optimal transfer to downstream domains.
Prior work on synthetic pre-training has explored approaches like generating random strings with a recurrent network (Bloem, 2025) and simple algorithmic tasks (Wu et al., 2022; Shinnick et al., 2025a), but they have yet to match or outperform language training under matched token budgets. We hypothesize this is because such synthetic distributions are narrow and homogeneous, lacking certain key properties that characterize natural language. NCAs address this gap. The parametric structure of NCA yields diverse dynamics and allows systematic control over complexity. This enables us to ask not only whether synthetic data can transfer, but what structural properties make it effective.
We adopt a pre-pre-training framework: an initial phase of training on NCA dynamics that precedes standard pre-training on natural language (Hu et al., 2025b). Our ultimate vision is to pre-train entirely on clean synthetic data, followed by fine-tuning on a limited and curated corpora of natural language to acquire semantics (Han et al., 2025a). The pre-pre-training framework serves as an early prototype of this paradigm, allowing us to measure how computational primitives learned from synthetic NCA transfer to language tasks. Our contributions are as follows:
A synthetic pre-pre-training substrate that transfers to language and reasoning. We propose neural cellular automata (NCA) as a fully algorithmic, non-linguistic data source for pre-pre-training. NCA pre-pre-training improves downstream language modeling by up to 6% and converges up to 1.6×one point six times faster across web text, math, and code. These perplexity gains transfer to reasoning across benchmarks including GSM8K, HumanEval, and BigBench-Lite. Surprisingly, it outperforms pre-pre-training on natural language (C4), even with more data and compute.
Synthetic pre-training enables domain-targeted data design. We find that the optimal NCA complexity regime varies by downstream task: code benefits from lower-complexity rules while math and web text benefit from higher-complexity ones. NCAs’ parametric structure offers a new lever for efficient training: tuning the complexity of training distributions to match the computational character of target domains.
Attention captures the most transferable priors. The attention layers capture the most useful computational primitives, accounting for the majority of the transfer gains. Attention appears to be a universal carrier of transferable capabilities such as long-range dependency tracking and in-context learning, whereas MLPs encode more domain-specific knowledge—making MLP transfer conditional on alignment between the synthetic and target domains.
2. Related Works
Synthetic data is a broad umbrella term encompassing a wide spectrum of artificially generated data, ranging from using LLMs (Nadáš et al., 2025; Wang et al., 2023; Xu et al., 2025; Mukherjee et al., 2023; Li et al., 2023; Lu et al., 2024; Wei & Zou, 2019) to simple algorithms to generate data. In this work, we pursue the latter, a non-linguistic approach.
Algorithm-Based Synthetic Data Some works have gone beyond natural data altogether, using simple algorithmic procedures (e.g., OpenGL shader images) to generate synthetic training data (Baradad et al., 2022). Past works have trained vision models on data generated by simple processes like fractals, dead leaves, and wavelet models (Kataoka et al., 2020; Baradad Jurjo et al., 2021; Baradad et al., 2022). Despite lacking semantic content, these models learn representations that transfer well to real images. Baradad Jurjo et al. (2021)Baradad Jurjo and colleagues argue that what matters is not natural data per se, but naturalistic data, i.e. data that reproduces the statistical structure of the natural world, such as the approximate scale-invariance (Field, 1987) or the Zipfian distribution (Zipf, 1949; Chan et al., 2022).
In the language domain, using algorithmically generated data is less common, as language is thought to be uniquely complex. Nevertheless, some works have explored this
approach (Saxton et al., 2019; Desai et al., 2015; Papadimitriou & Jurafsky, 2023). Chiang & yi Lee (2020); Hu et al. (2025a)Chiang and Lee, as well as Hu and colleagues, showed that pre-training LLMs on synthetic data generated by context-free grammars can be useful for natural language modeling. Berkovich & Buehler (2025)Berkovich and Buehler and Berkovich et al. (2025)Berkovich and colleagues trained LLMs on cellular automata, but did not study the usefulness of the learned representations for language.
Shared Underlying Computation A growing body of work suggests that neural networks learn general computations that transfer across domains, raising the possibility that synthetic algorithmic data could instill such primitives directly. Lu et al. (2022)Lu and colleagues show that LLMs trained on natural language can transfer to seemingly unrelated domains like vision and protein folding, and Huh et al. (2024)Huh and colleagues illustrate that foundation models across different modalities are converging in representation, hinting that they are learning a common structure. Going further, Mirchandani et al. (2023)Mirchandani and colleagues show that, even without fine-tuning, LLMs already have in-context learning capabilities for symbolic reasoning, numeric pattern continuation, and robotic control. These works cast LLMs as universal computation engines (Lu et al., 2022). Other works have shown transfer from natural language to robotic RL environments (Reid et al., 2022). Zhang et al. (2024)Zhang and colleagues showed that training LLMs on elementary cellular automata allows them to better transfer to chess.
Emergent Complexity A central puzzle for algorithmic synthetic data is how simple procedures can give rise to data with rich structure, resembling the complexity of the real world. This echoes a deeper observation about nature itself: despite its diversity, the universe appears governed by simple underlying laws (Wigner et al., 1990; Tegmark, 2008), and may even be fundamentally computational (Wolfram, 2020). Researchers have developed various measures to quantify such complexity (Lloyd, 2001; Mitchell, 2009), including Kolmogorov complexity (Kolmogorov, 1963), sophistication (Mota et al., 2013), and assembly index (Sharma et al., 2023). More recently, epiplexity was introduced as a complexity metric for computationally bounded observers (Finzi et al., 2026), demonstrating that simple deterministic rules can produce data useful for learning useful representations. These works suggest that NCAs, despite having simple local rules, can generate arbitrarily complex structures when rolled out over long time horizons, making them a promising source of synthetic training data.
3. Method
We study whether neural cellular automata (NCA) can create training data that teaches transferable computational priors useful for language modeling.
3.1. Neural Cellular Automata (NCA)
NCA is a generalization of classical cellular automata (Wolfram, 1984), where the update rule is parametrized as a neural network, allowing the dynamics to be diversely sampled rather than hand-designed.
Random Discrete NCA. We use 2D discrete neural cellular automata on a 12×12twelve by twelve grid with periodic boundaries and an n=10n equals ten state alphabet, where each cell is represented as a 10-dimensional one-hot vector. The transition dynamics are governed by a neural network fθf theta that maps each cell’s 3×3three by three neighborhood to logits over next-cell states:
ci(t+1)∼softmax(fθ(cN(i)(t))/τ),(1)
the state of cell i at time t plus one is sampled from the softmax of f theta applied to the neighborhood of cell i at time t, scaled by tau
where ci(t)c i t is the state of cell ii at time tt, N(i)N of i denotes its neighborhood, and τ=10−3tau equals ten to the minus three introduces mild stochasticity. We parameterize fθf theta as a 3×3three by three convolution (4 channels) followed by a cell-wise MLP with hidden size 16 and ReLU activation, producing 10 logits per cell.
Complexity-based sampling. To generate diverse training data, we sample both the transition rules and initial conditions. For each sequence, we randomly initialize the parameters θtheta of the transition network and sample the initial grid c(0)c zero i.i.d. uniform over {0,…,9}the integers zero through nine. This procedure yields a distribution over NCA dynamics ranging from trivially predictable (fixed points or short cylce) to highly chaotic and unpredictable.
To sample NCA dynamics with controlled structural complexity, we sample rules based on the gzip compression ratios of generated sequences. For rollouts, we serialize all timesteps into a byte stream and compute r=compressed bytes/raw bytes∗100r equals compressed bytes divided by raw bytes times one hundred. We retain NCAs with trajectories of r>50%r greater than fifty percent.
gzip under the hood combines Lempel-Ziv compression (Ziv & Lempel, 1977) with Huffman coding. Since Lempel-Ziv compression provides a computable upper bound on Kolmogorov complexity (Li & Vitányi, 2019), gzip compression ratio serves as a practical measure of intrinsic sequence complexity. Compressible sequences exhibit simpler and more predictable structure, whereas incompressible sequences are more chaotic, as seen in Figure 1.
3.2. Tokenization
Patch vocabulary. We tokenize each grid using non-overlapping 2×2two by two patches, following the patch-based tokenization for vision transformers (Dosovitskiy et al., 2021). Each patch contains four cells in {0,…,9} and is mapped bijectively to an integer token, yielding a fixed vocabulary of 104ten to the fourth patch tokens. We serialize each timestep in row-major
order with <grid> and </grid> delimiters, and concatenate timesteps to form sequences of up to 1024 tokens.
3.3. Training Objective and Interpretation
We train a transformer autoregressively on the tokenized trajectory x=(x1,…,xN)x equals x 1 through x N using cross-entropy loss:
L=−i=1∑Nlogpϕ(xi∣x<i)(2)
Since each sampled θtheta defines a distinct dynamics rule, next-token prediction requires inferring the latent rule in context and applying it within the same sequence. This aligns NCA training with the Bayesian view of in-context learning (Han et al., 2025b; Xie et al., 2022).
4. Experimental Setup
4.1. Training Paradigm
We adopt a three-stage training paradigm (Shinnick et al., 2025a; Hu et al., 2025b; Bloem, 2025):
Pre-pre-training: An initial training phase designed to instill transferable computational priors before the main pre-training stage. In this work, we propose using synthetic, non-linguistic data (NCA trajectories) for pre-pre-training.
Pre-training: Standard large-scale training on natural language corpora (web text, code, or math) to acquire linguistic knowledge.
This work studies the transfer from stage 1 to stage 2 and 3: whether computational structure learned from synthetic data can accelerate and improve language model pre-training, and how it manifests in downstream reasoning benchmarks.
4.2. Setup
We generate NCA data by randomly sampling neural network weights that define the transition rule. Each trajectory is thus produced by a unique rule, ensuring diversity across the training distribution. We pre-pre-train a Llama-based transformer (Touvron et al., 2023) (1.6B parameters, 24 layers, 32 heads, 2048 hidden dimension, weight-tying) on 164M NCA tokens sampled at the 50%+ gzip compressibility band, unless otherwise noted. We measure transfer by conducting pre-training on three downstream corpora: OpenWebText(Gokaslan et al., 2019), OpenWebMath(Paster et al., 2023), and CodeParrot(Tunstall et al., 2022). We transfer all model weights except the embedding layers, which are re-initialized for the natural language vocabulary. All parameters are updated during pre-training.
For downstream reasoning benchmarks, we evaluate on GSM8K(Cobbe et al., 2021), HumanEval(Chen et al., 2021), and BigBench-Lite(Srivastava et al., 2023). We fine-tune the models on the train set for instruction following for GSM8K and BigBench-Lite. We provide the details on our stage 3 pipeline in Appendix C.
4.3. Baselines
We compare against two baselines: (i) No pre-pre-training (scratch): the model is randomly initialized and trained directly on the pre-training corpora, establishing whether pre-pre-training provides any benefit; (ii) Dyck pre-pre-training: pre-pre-training on K-Dyck, a synthetic formal language studied in Hu et al. (2025b)Hu and colleagues, testing how NCA pre-pre-training compares against an alternative synthetic data approach. We generate our pre-pre-training data using k=128k equals 128 and infinite potential depth; (iii) C4 pre-pre-training: pre-pre-training on natural language data (C4; Raffel et al. (2020)Raffel and colleagues) with matched token budgets, testing how NCA pre-pre-training compares against natural language pre-pre-training.
4.4. Hyperparameters
For both our pre-pre-training and baseline runs, we perform a grid search over learning rate and weight decay and use the best hyperparameters for each method. For pre-training, we train three separate models for a single epoch on each dataset: OpenWebText (9B tokens), OpenWebMath (4B tokens), and CodeParrot (13B tokens). We report the detailed hyperparameters in Table 2 in Appendix B.
For downstream reasoning benchmarks, we use models pre-trained on OpenWebText, OpenWebMath, and CodeParrot for Big-Bench-Lite, GSM8K, and HumanEval, respectively: matching the benchmark domain approximately to the pre-training domain. We report details on fine-tuning in Appendix C.
4.5. Evaluation Metrics for Transfer
We measure the transfer between our pre-pre-training and pre-training by mainly studying validation perplexity on a held-out set and convergence speed (Bloem, 2025; Hu et al., 2025b; Kaplan et al., 2020). We quantify convergence speed by comparing the number of tokens to reach the final perplexity of the scratch model. On downstream reasoning tasks, our primary evaluation metric is pass accuracy with multiple decodings or pass@kpass at k(Chen et al., 2021). For BigBench tasks, we compute accuracy on a normalized basis to adjust for random guessing associated with multiple-choice questions (Srivastava et al., 2023).
5. Results
We present results on the impact of NCA pre-pre-training on downstream language modeling, and analyze how transfer varies across scale and data complexity.
5.1. NCA Pre-Pre-Training Improves Language Modeling
We compare the language modeling performance against three baselines: (i) no pre-pre-training (“scratch”), (ii) pre-pre-training on another natural language dataset C4, and (iii) pre-pre-training on another synthetic language Dyck.
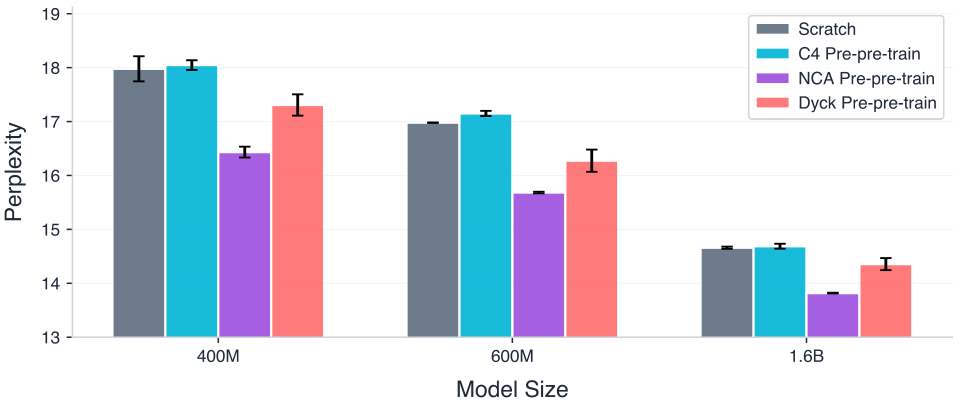
As seen in Figure 3, across model scales (400M, 600M, 1.6B)four hundred million, six hundred million, and one point six billion parameters and multiple random seeds, NCA pre-pre-trained models consistently outperform all three baselines (scratch, Dyck, and natural language). On OpenWebText, the best-performing NCA pre-pre-trained 400M model improves downstream perplexity upon the scratch baseline by 8.6%, and the 1.6B model improves by 5.7%. The relative gain decreases with scale, which is expected as larger models provide a stronger baseline and incremental perplexity improvements become progressively harder to obtain. The improvements nonetheless remain consistent across seeds, indicating that the effect is robust rather than a fragile artifact of initialization.
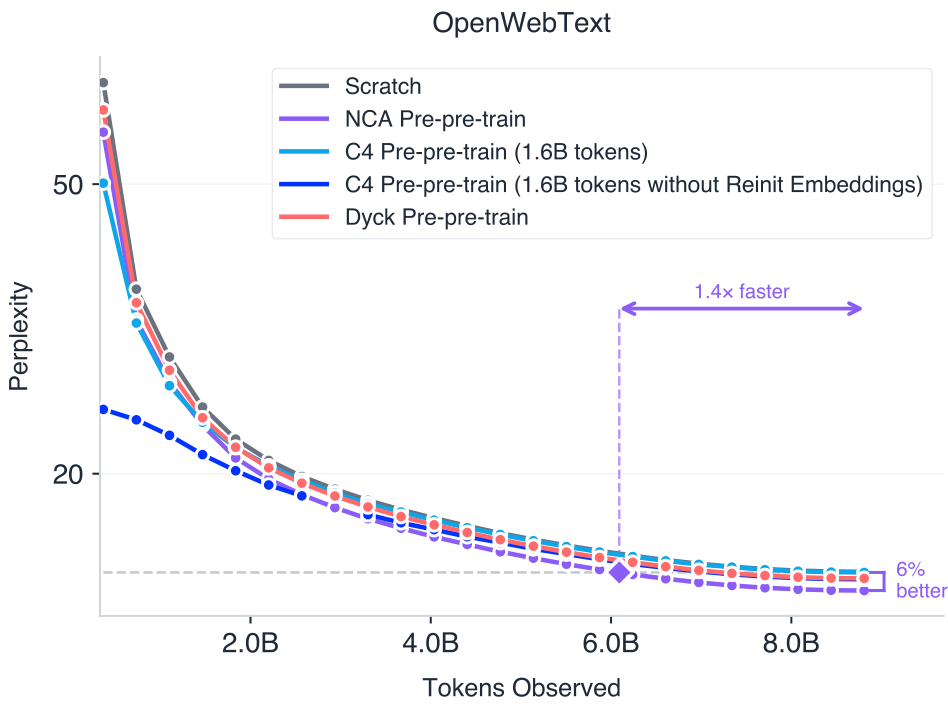
The most surprising observation is that pre-pre-training on NCA outperforms pre-pre-training on natural language (C4) under matched token and compute budgets. To further study this, we compared NCA pre-pre-training (160M tokens) against C4 with significantly more data (1.6B tokens), with and without transferring the pre-trained embedding layers in Figure 4. NCA pre-pre-training improves upon this baseline by 5% on perplexity and converges 1.4×one point four times faster. We hypothesize this reflects what each data source teaches at each scale: C4 may emphasize shallow syntactic patterns, while NCA directly trains long-range dependency tracking and latent rule inference. We return to this discussion in Section 6.
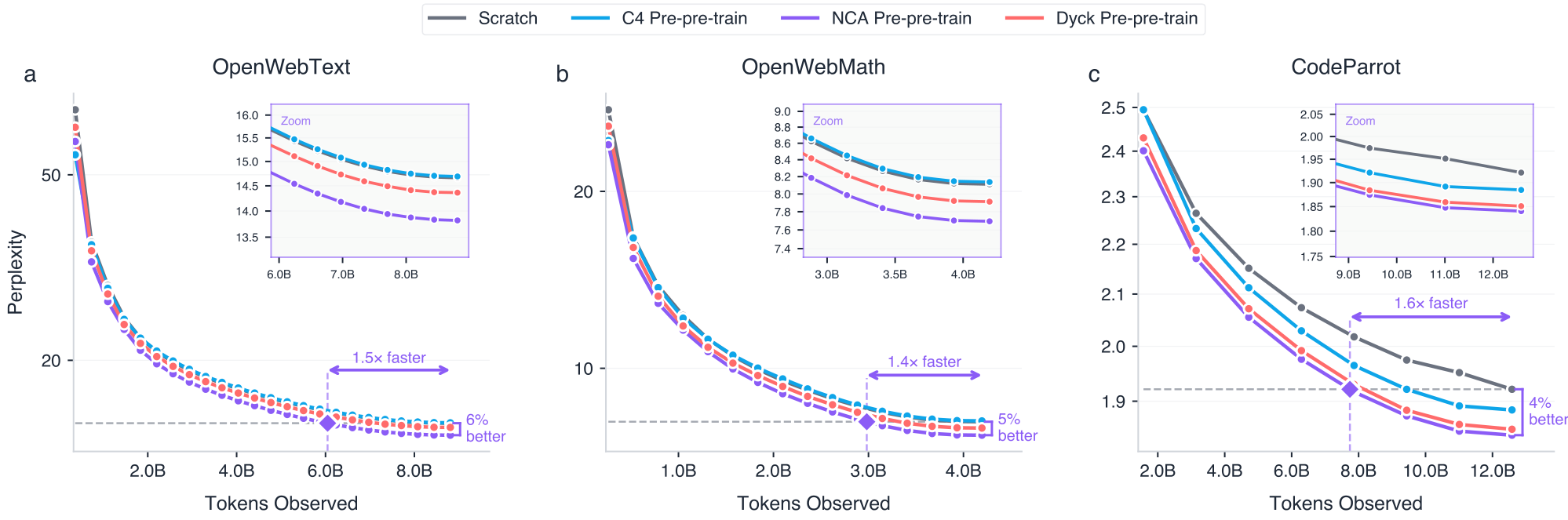
This transfer to natural language holds across the training and generalizes across different domains of math and code, as shown in Figure 2. These training curves show that NCA pre-pre-training lowers validation perplexity on OpenWeb-Math and CodeParrot by 4−5% by the end of convergence and with the NCA pre-pre-training we can achieve up to 1.6×one point six times faster convergence. These results demonstrate that the transfer is not specific to a single downstream domain but generalizes across different natural language distributions. This is also not a short-lived initialization effect. The perplexity advantage persists and often grows throughout training, indicating that NCA pre-pre-training genuinely increases token efficiency.
5.2. Language Modeling Gains Translate to Downstream Reasoning
Perplexity measures language modeling quality, but it is a proxy for the capabilities we ultimately care about. To assess whether these gains translate into task-level improvements, we evaluate on downstream reasoning benchmarks in Table 1. On GSM8K, NCA pre-pre-training improves accuracy from 3.8% to 4.4% at pass@1 and from 36.6% to 37.9% at pass@32, with gains growing slightly at higher pass@kk. On HumanEval, NCA pre-pre-training improves pass@1 but the advantage diminishes at higher kk. Interestingly, Dyck pre-pre-training is competitive with NCA on HumanEval at higher pass@kk, and slightly outperforms it at pass@16 and pass@32. This likely reflects the structural overlap between Dyck languages and code, both of which require tracking nesting logic and delimiter patterns. On BigBench-Lite, pass@1 is comparable across all methods, but NCA pre-pre-training outperforms markedly at higher kk, reaching 36.5% at pass@4 compared to 29.7% for C4 and 25.9% for the scratch baseline. Overall, these results demonstrate that NCA pre-pre-training transfers to downstream reasoning across math, logic, and code.
Math (GSM8K)
pass@k
Scratch
C4
NCA
Dyck
1
3.8%±0.1%
3.8%±0.2%
4.4%±0.3%
4.1%±0.4%
8
17.9%±0.3%
17.8%±0.5%
19.2%±0.3%
18.6%±0.9%
16
26.5%±0.5%
26.3%±0.6%
27.8%±0.3%
27.3%±0.9%
32
36.6%±0.6%
36.2%±0.9%
37.9%±0.3%
37.4%±0.7%
Coding (HumanEval)
pass@k
Scratch
C4
NCA
Dyck
1
6.8%±0.6%
6.3%±0.3%
7.5%±0.4%
6.9%±0.1%
8
11.2%±0.6%
10.5%±0.5%
11.4%±0.8%
11.3%±0.2%
16
12.6%±0.6%
11.6%±0.6%
12.6%±0.9%
12.8%±0.2%
32
13.9%±0.5%
12.6%±0.7%
13.8%±1.0%
14.3%±0.4%
Reasoning (BigBench-Lite)
pass@k
Scratch
C4
NCA
Dyck
1
15.4%±1.1%
15.9%±0.9%
15.0%±1.2%
13.4%±2.8%
2
20.9%±2.5%
22.8%±1.2%
26.5%±1.0%
18.1%±2.3%
4
25.9%±3.9%
29.7%±1.3%
36.5%±2.1%
22.7%±2.1%
Table 1. NCA pre-pre-training improves performance on downstream reasoning benchmarks. We report the mean pass@k± std over 4 training seeds.
5.3. What Drives Transfer?
The preceding results establish that NCA pre-pre-training improves both language modeling and reasoning. We now investigate the mechanism: which model components capture the transferable structure, and what properties of the synthetic data control transfer effectiveness?
Figure 2. NCA pre-pre-training improves and accelerates language model pre-training across diverse domains. We show the validation perplexity during pre-training on (a) OpenWebText, (b) OpenWebMath, and (c) CodeParrot for 1.6B parameter models. Models pre-pre-trained on NCA trajectories consistently outperform the scratch, Dyck pre-pre-training, and surprisingly even C4 pre-pre-training baselines. NCA pre-pre-training achieves 1.4–1.6× faster convergence to the scratch baseline’s final perplexity while also reaching up to 6% lower final perplexity. We provide a zoomed-in training curve of the last third of training for clarity.
Figure 3. NCA pre-pre-training improves language model training performance across model sizes (Section 5.1). We report the final validation perplexity after pre-training on OpenWebText across (400M, 600M, and 1.6B parameter models). At 164M tokens, C4 pre-pre-training likely acquires shallow syntactic patterns that interfere with downstream learning rather than transferable structure. We investigate this further in Figure 4.
tics that interfere with language learning. On CodeParrot, these components have negligible effect. This asymmetry suggests that attention is more transferable across domains, whereas MLP layers are contingent on whether the domain-specific priors align with the target task.
These findings align with concurrent work identifying attention as the primary locus of transferable structure in synthetic pre-training (Shinnick et al., 2025a;b)Shinnick and colleagues. They also resonate with recent analyses of Mixture-of-Expert architectures, which demonstrate that scaling MLP parameters primarily enhance memorization rather than reasoning (Jelassi et al., 2025)Jelassi and colleagues. Together, these results suggest a functional division: attention layers learn general-purpose mechanisms for tracking dependencies and inferring latent rules, while MLP layers specialize in storing domain-specific patterns and statistics. This division may explain why attention transfers universally from NCA to language, whereas MLP weights can introduce interference when the source and target domains differ substantially.
5.3.1. Attention captures the most transferable primitives.
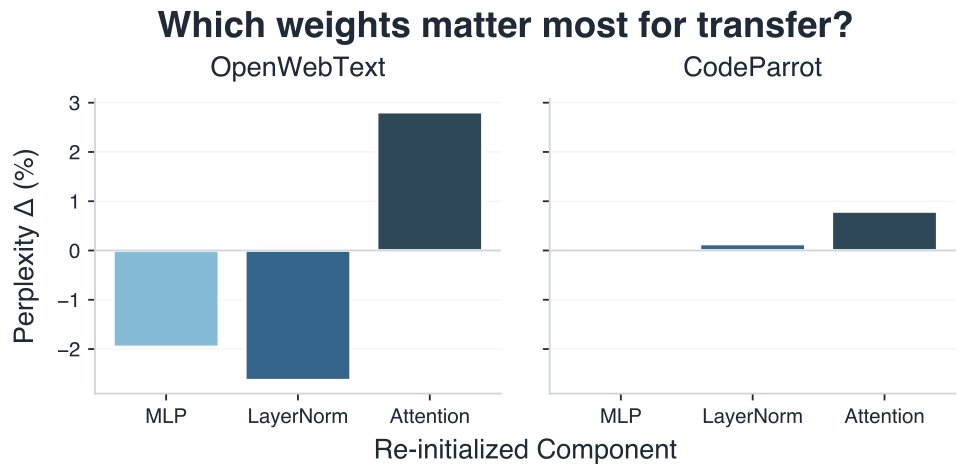
To isolate which model components carry the transfer signal, we selectively re-initialize subsets of weights after NCA pre-pre-training and measure the impact on language modeling. As shown in Figure 5, re-initializing attention weights causes the largest degradation in transfer across all configurations, indicating that attention captures the most transferable computational primitives.
The role of other components is more nuanced. On OpenWebText, retaining MLP and LayerNorm weights degrades transfer, suggesting these layers encode NCA-specific statistics that interfere with language learning.
5.3.2. Data complexity modulates transfer and the optimum is domain-dependent.
Having established that attention carries the most transferable signal, we next ask: what properties of NCA data affect the transfer? We analyze complexity along two complementary axes: gzip compressibility (as an upper bound to Kolmogorov complexity) and alphabet size nn (size of the state space).
Complexity via gzip. We generate NCA trajectories of varying gzip compressibility bands (20–30%, 30–40%, 40–50%, 50%+). Smaller compression ratios imply regular,
Figure 4. Pre-pre-training on 160M tokens of NCA is better than pre-pre-training on 1.6B tokens of natural language (C4). We report the validation perplexity during pre-training on OpenWebText. Perplexity improvement is calculated relative to the C4 pre-pre-trained model. We add a version where we also preserve the embedding layers from pre-pre-training to pre-training (1.6B tokens w/o embedding reinit). Surprisingly even with the embedding layers, NCA pre-pre-training is better.
Figure 5. Attention weights are most crucial for positive transfer. We report the change in validation perplexity when selectively re-initializing model components after NCA pre-pre-training, relative to full transfer. Higher means the component is more important for transfer. Re-initializing attention causes the largest degradation across both OpenWebText and CodeParrot, while MLP and LayerNorm effects are domain-dependent.
low-entropy dynamics that are more predictable, whereas larger compression ratios generate more diverse and unpredictable trajectories with richer spatiotemporal structure, as illustrated in Figure 1.
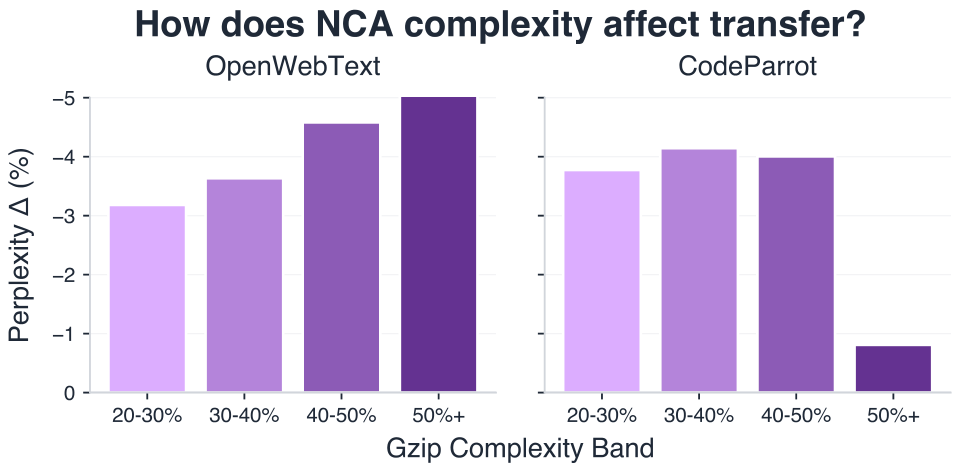
As shown in Figure 6, the optimal complexity band varies by downstream domain. OpenWebText benefits from less compressible (more complex) NCA rules in the 50%+ band, while CodeParrot shows a sweet spot at intermediate complexity (30–40% gzip). Strikingly, this aligns with the intrinsic complexity of the target corpora themselves in Figure 8 of Appendix A: OpenWebText and OpenWebMath have gzip ratios of 60–70%, whereas CodeParrot is substantially more compressible at 32%. The correlation is somewhat direct. Domains with higher intrinsic complexity benefit from higher-complexity synthetic data, and vice versa. This suggests a plausible and practical principle: matching the complexity of synthetic pre-training data to the target domain maximizes transfer.
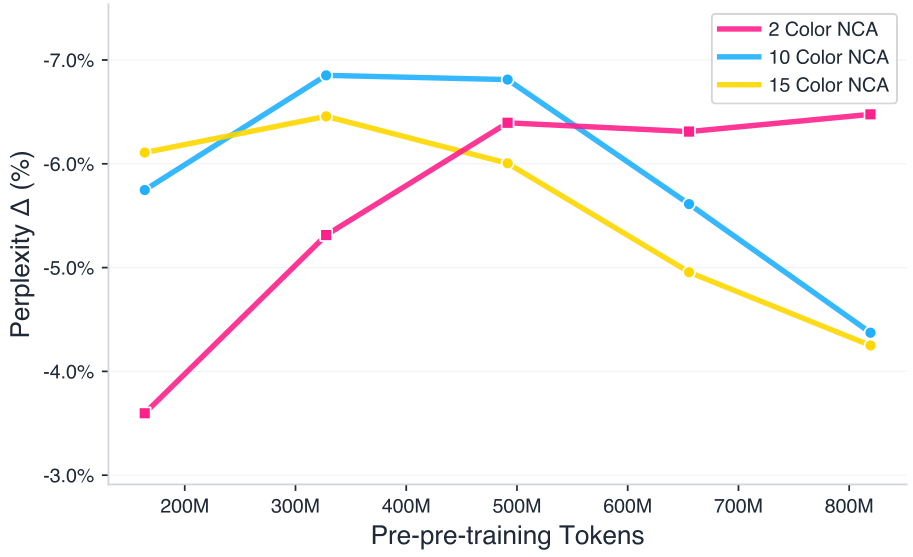
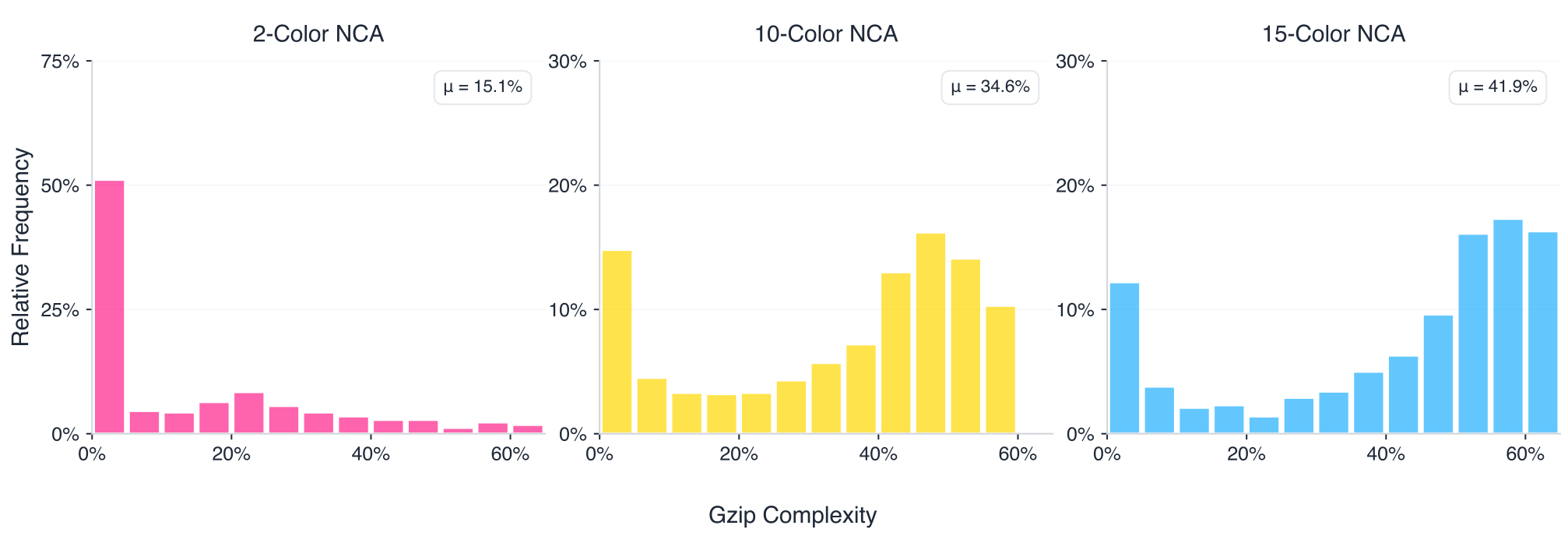
Rule space expressiveness via alphabet size. We vary the NCA state alphabet n∈{2,10,15}n in the set 2, 10, and 15, which controls the diversity of possible local interactions. As shown in Figure 7, larger alphabets (n=10,15n equals 10 or 15) exhibit diminishing returns: performance improves the most at an intermediate NCA token budget, then the improvement gap narrows. Surprisingly, the smallest alphabet (n=2n equals 2) scales most favorably, continuing to improve where larger alphabets plateau.
As seen in Figure 9 in Appendix A, when increasing nn, the resulting NCA data naturally becomes more complex. This result suggests that although larger rule spaces can express more complex dynamics, better guidance is necessary to sample a diverse set of NCAs that optimally transfer to language. Thus, constraining the space to k=2k equals 2 may paradoxically help by concentrating samples on dynamics with more consistent, transferable structure.
Together, these results indicate that transfer is not simply “more NCA data is better.” The complexity of synthetic data, both gzip and alphabet size, must be calibrated. This offers a lever unavailable in natural language pre-training: the ability to tune the training distribution to match the computational character of target domains. We further discuss the implications for domain-targeted pre-training in Section 6.
6. Discussion
Why should we expect transfer? NCA data are substantially different from natural language and generated by deterministic processes, prompting the question of why one should expect transfer at all? We argue that NCAs may provide a purer training signal for in-context rule inference. In natural language, models may rely on semantic “shortcuts” or co-occurrence priors (Abbas et al., 2023; Geirhos et al., 2020)Abbas and colleagues, 2023, and Geirhos and colleagues, 2020. In contrast, every NCA sequence is generated by a hidden transition rule – parameterized by a random neural network. With no semantic knowledge to fall back on, every NCA token guides the model to in-context rule inference (Kirsch et al., 2022)Kirsch and colleagues, 2022.
This mirrors a core capability required for language modeling (Brown et al., 2020; Wei et al., 2022; Dong et al., 2024)Brown and colleagues, 2020, Wei and colleagues, 2022, and Dong and colleagues, 2024. Xie et al. (2022)Xie and colleagues show that training on natural text
Figure 6. Optimal NCA complexity is domain-dependent. We report the validation perplexity change of models trained with different NCA complexities from the scratch model. OpenWebText benefits from higher-complexity data (50%+), while CodeParrot peaks at intermediate complexity (30–40%). This suggests that matching synthetic data complexity to the target domain is necessary to maximize transfer.
Figure 7. NCA alphabet size changes scaling behavior. We report the perplexity change relative to the scratch model (higher is better) on OpenWebText across different alphabet sizes nn and NCA pre-pre-training token budgets. NCA improves perplexity at all token budgets. The smaller alphabet scales better, and the improvements degrade with scale for larger alphabets.
teaches models to perform implicit Bayesian inference over latent concepts: each sequence draws from a latent concept, and predicting the next token means conditioning on the inferred concept. The same mechanism appears in math and code as well (Garg et al., 2023; Cook et al., 2025)Garg and colleagues, and Cook and colleagues. Prior work on formal languages and algorithmic tasks such as Dyck and string copying (Hu et al., 2025b; Wu et al., 2022; Shinnick et al., 2025b)as documented in recent literature also train for this kind of in-context inference. Unlike these tasks, NCAs encompass a broad, universal class of computable functions (Copeland, 2012), some of which realize Turing-complete systems (Rendell, 2002; Wolfram & Gad-el Hak, 2003). The breadth and scale of this distribution makes memorization infeasible, forcing models to learn a general mechanism for rule inference (Li et al., 2024)Li and colleagues that applies across the function class.
This framing is supported by our mechanistic finding from Section 5.3.1: attention layers, not the MLPs or LayerNorms carry the most transferable structure. (Olsson et al., 2022)Olsson and colleagues showed that ICL ability emerges with the formation of induction heads – attention circuits that help copy information from previous tokens to future ones. Because NCA pre-pre-training exclusively rewards this behavior, it may induce earlier and more robust formation than language-only pre-training. The transferred attention weights are, in effect, the in-context learning circuits, which are later adapted for downstream tasks and domains.
A secondary motivation for transfer is epiplexity(Finzi et al., 2026)as defined by Finzi and colleagues. Classical information theory suggests deterministic transformations cannot increase information content (Polyanskiy & Wu, 2025)Polyanskiy and Wu, thus questioning whether LLMs can learn meaningful structure from NCAs. However, this view assumes a computationally unbounded observer. For computationally bounded observers, Finzi et al. (2026)Finzi and colleagues show that deterministic processes can generate useful structural information—coined epiplexity—that models must internalize to learn useful representations of the data. Their key insight is that simple local rules, like CA, can produce emergent structures (e.g., gliders, collisions) that a finite-capacity model cannot brute-force simulate. Instead, the model must learn a representation that allows it to predict the simulation at a coarser-grained abstraction. Learning these representations over a diverse and universal class of functions like NCA may help with learning representations of natural language as well.
Why is 160M tokens of automata better than 1.6B tokens of text? Surprisingly, with a significantly lower token budget, pre-pre-training on NCA data improves language modeling more than pre-pre-training on natural language (C4), as shown in Figure 2. How can abstract dynamical systems’ data transfer better to language than language itself?
Even at 1.6B tokens, natural language pre-pre-training remains in an early training regime. Compute-optimal scaling laws suggest (Hoffmann et al., 2022)Hoffmann and colleagues that a 1.6B parameter model requires roughly 32B tokens. At this early stage, language models primarily acquire shallow, local patterns and only learn more complex structures later on (Evanson et al., 2023; Chen et al., 2023).
With limited tokens, C4 pre-pre-training likely spends most of its capacity on these surface-level regularities rather than the long-range dependencies and in-context learning that transfer broadly.
In contrast, we hypothesize that NCA sequences provide a purer training signal for in-context learning. Each sequence is generated by a single latent rule that the model must infer from context and then apply consistently. Once identified, next-token prediction becomes nearly deterministic.
Moreover, NCA pre-pre-training introduces a form of diversity orthogonal to what additional language tokens would provide. Despite their scale, many natural language datasets exhibit substantial redundancy (Abbas et al., 2023)as noted by Abbas and colleagues in 2023 in linguistic patterns and topic coverage. Since each of our NCA sequences represents a unique function to model, this diversity may be more efficient per token at building general-purpose representations.
Beyond one-size-fits-all pre-training Our complexity ablations reveal a nuanced picture that the optimal distribution for training varies by downstream domain. In Figure 6, we observed that code benefits from lower-complexity NCA rules, while web text and math benefit from higher-complexity ones, suggesting these domains encode computations of measurably different character. This opens a new axis of control. Rather than treating training data as fixed, we can tune the structures of synthetic data to match the target domain. Unlike grammar-based synthetic tasks, where each formal grammar defines a task with fixed structural complexity, NCAs provide a continuous and tunable spectrum of complexity within a single generator family. If researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code (Li et al., 2025)as discussed by Li and colleagues, richer long-range dependencies for genomic sequences (Wu et al., 2025)as discussed by Wu and colleagues), they can instill these capabilities directly, without scaling to trillions of general-purpose tokens. The result could aid the development of specialized, small language models (Belcak et al., 2025)as discussed by Belcak and colleagues that are more efficient to train and deploy—trained not on more data, but on better-matched data.
Limitations and open problems A key question is whether NCA data can serve not only as a pre-pre-training signal, but as a scalable substitute for natural language pre-training. For larger alphabet sizes (n=10,15)n equals 10 or 15, we observe a reverse U-shaped trend: downstream improvement is optimal up to an intermediate token budget but plateaus beyond it. This behavior nonetheless reinforces our central thesis: effective synthetic pre-training depends critically on structural choices in the data generator, not merely on scale.
This points to a key open problem for future work: developing principled methods to guide synthetic generators to sample structures that match those of target domains. Our complexity results demonstrate that such matching matters, but gzip compressibility and alphabet size are only two lens on complexity. Complexity is multifaceted: a sequence can be compressible yet be rich in long-range dependencies, or vice versa. Characterizing which axes of complexity (e.g., size of NCA network, grid size, or epiplexity) matter for which domains and learning to sample synthetic data accordingly could unlock fully synthetic pre-training at scale.
NCA represents one point in the vast space of possible synthetic data generators. The key insight from our work is not that NCA specifically is optimal, but that structured synthetic data with appropriate complexity characteristics can provide meaningful pre-training signal even without any linguistic content. The question is no longer whether synthetic pre-training can work, but how to design synthetic data distributions that maximize what models learn.
Author Contributions
Dan Lee co-lead the project and contributed to all aspects of experiments and writing.
Seungwook Han co-lead the project and contributed to all aspects of experiments and writing.
Akarsh Kumar supported this project, contributed to the design of the experiments and significantly to the writing.
Pulkit Agrawal advised the development of the project idea from inception and contributed significantly to the writing.
Acknowledgment
We want to express our gratitude to Zachary Schinnick, Phillip Isola, Yoon Kim, Ryan Bahlous-Boldi, Idan Shenfeld, Nitish Dashora, and members of the Improbable AI lab for the helpful discussion on the paper. We are grateful to MIT Supercloud and the Lincoln Laboratory Supercomputing Center for providing HPC resources. The research was supported in part by NSF CSGrad4US Fellowship, Google, and Amazon. Also, the research was sponsored by the Army Research Office and was accomplished under Grant Number W911NF-23-1-0277. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Office, Naval Research Office, Air Force, or the U.S. Government
References
[references omitted]
[references omitted]
[references omitted]
[references omitted]
[references omitted]
A. Analysis on Natural and Synthetic Data Distributions
Figure 8. NCA data exhibits a similar Zipfian or power-law structure to natural language. We compare the relative token frequency distribution for each of the natural language corpora and NCA data. Natural language from different domains has different average complexity as measured by gzip compressibility (see legend).
In this section, we examine the distributions of natural-language and NCA-generated synthetic data with respect to two primary high-order heuristics: (1) token frequency distribution and (2) gzip compressibility.
A.1. NCA data exhibits similar token distributions to natural language
To compare the token frequency across different data distributions, we sample and tokenize random text sequences from the natural language datasets (OpenWebText, OpenWebMath, and CodeParrot) and NCA generated data n=15n equals fifteen. Figure 8 shows the distribution of relative token frequencies. Data generated from the NCAs follows a heavy-tailed, Zipfian token distribution that is structured similarly to natural language. Another interesting observation is that natural language depending on the domain varies quite drastically from 32% in code and 60-70% in math and web text.
A.2. Increasing the vocabulary size n leads to more complex generated trajectories
Figure 9 compares the distribution of gzip complexity across trajectories generated by randomly sampled NCAs across different alphabet sizes n=2,10,15n equals two, ten, and fifteen. As nn increases, the distribution skews towards less compressible, more complex data. This implies that with higher nn, the universe of rules expands and naturally the dynamics become more complex.
B. Detailed Pre-pre-training and Pre-training Setup
Table 2 summarizes the hyperparameters used for both pre-pre-training on NCA data and subsequent pretraining on natural language datasets. We sweep various batch sizes (32 to 512), learning rates (1×10−3 to 1×10−5)from one times ten to the minus three to one times ten to the minus five, and weight decays (1×10−4 to 1×10−6)from one times ten to the minus four to one times ten to the minus six. To ensure reproducibility, we train our pipeline on 4 randomness seeds for each main pipeline (NCA Pre-pre-training, Scratch, and C4 Pre-pre-training) and at least 2 seeds for each ablation run.
Hyperparameter
Pre-pre-training
Pre-training
Effective batch size
16
512
Sequence length
1024 tokens
1024 tokens
Learning rate
1×10−4
5×10−4 (Math/Text), 2×10−4 (Code)
LR schedule
Cosine w/ warmup
Cosine w/ warmup
Warmup steps (% total)
10%
10%
Weight decay
None
1×10−4
Gradient clipping
None
1.0
Table 2. Hyperparameters for pre-pre-training and pre-training experiments.
Figure 9. Different NCA alphabet sizes, n=2,10,15n equals two, ten, or fifteen naturally yield different complexity distributions of the data. Increasing nn inherently increases the complexity of the data.
C. Detailed Fine-Tuning Setup
For GSM8K and HumanEval, we evaluate on all tasks provided by the benchmarks. For BigBench-Lite, given the quantity and imbalance of samples and tasks, we randomly sample at most 300 tasks for each major category of english language problem where there are at least 100 examples available for training.
For GSM8K and BigBench-Lite, we fine-tune the OpenWebMath and OpenWebText pre-trained models on the respective training sets. For GSM8K, we train for 10 epochs using a learning rate of 1e-5 to enable the models to follow the question answering format for evaluation. For GSM8k, we also fine-tune on the Chain-of-Thought reasoning trace provided by the dataset. For BigBench-Lite, we train for a single epoch at a learning rate of 5e-6 to enable models to follow the answer format. Across both we sweep hyperparameters including learning and choose the best performing models for comparison for each baseline and NCA pre-trained model. For HumanEval, we do not fine-tune the models since it is a code completion task. For reproducibility, we train 4 seeds for each model and baseline and report the averages across runs.
We evaluate the models’ performances across different Pass@kk with kk varying from 1, 8, 16, and 32. For Big-Bench, because of the multiple-choice nature of some tasks, we opt to demonstrate up to 4 passes. We use the unbiased estimator from Chen (2021)Chen, computing the metric from 64 total decodings per run. For evaluation, we sampled with a temperature of 0.4 and top-p of 0.95 across GSM8k, HumanEval, and BigBench. We evaluated with higher temperatures and use 0.4 temperature as higher temperatures led to overall worse and highly variable performance. We use 4 training pipeline seeds per task for each baseline and NCA pre-pretrained models and 5 decoding seeds per pipeline seed.
D. NCA Pre-Pre-Training is more token efficient than natural language
In this section, we compare convergence speed across pipelines by computing a different the token efficiency metric used in Hu et al. (2025b)Hu and colleagues. Token efficiency gain is defined as:
Token Efficiency Gain equals one minus the sum of NCA pre-pre-training and pre-training tokens, divided by the sum of baseline pre-pre-training and pre-training tokens.
Where TPPTT sub P P T represents the number of pre-pre-training tokens and TPTT sub P T represents the number of pre-training tokens to achieve the scratch model’s final loss. Note that TPPTbase=0T base sub P P T equals zero for the no pre-pre-training baseline.
On average, NCA pre-pre-trained models exhibit token efficiency gains of 31% on OpenWebText, 27% on OpenWebMath, and 49% on CodeParrot to reach equivalent performance to the scratch baseline.