Transformer Feed-Forward Layers Are Key-Value Memories
Abstract
Feed-forward layers constitute two-thirds of a transformer model’s parameters, yet their role in the network remains under-explored. We show that feed-forward layers in transformer-based language models operate as key-value memories, where each key correlates with textual patterns in the training examples, and each value induces a distribution over the output vocabulary. Our experiments show that the learned patterns are human-interpretable, and that lower layers tend to capture shallow patterns, while upper layers learn more semantic ones. The values complement the keys’ input patterns by inducing output distributions that concentrate probability mass on tokens likely to appear immediately after each pattern, particularly in the upper layers. Finally, we demonstrate that the output of a feed-forward layer is a composition of its memories, which is subsequently refined throughout the model’s layers via residual connections to produce the final output distribution.
1 Introduction
Transformer-based language models
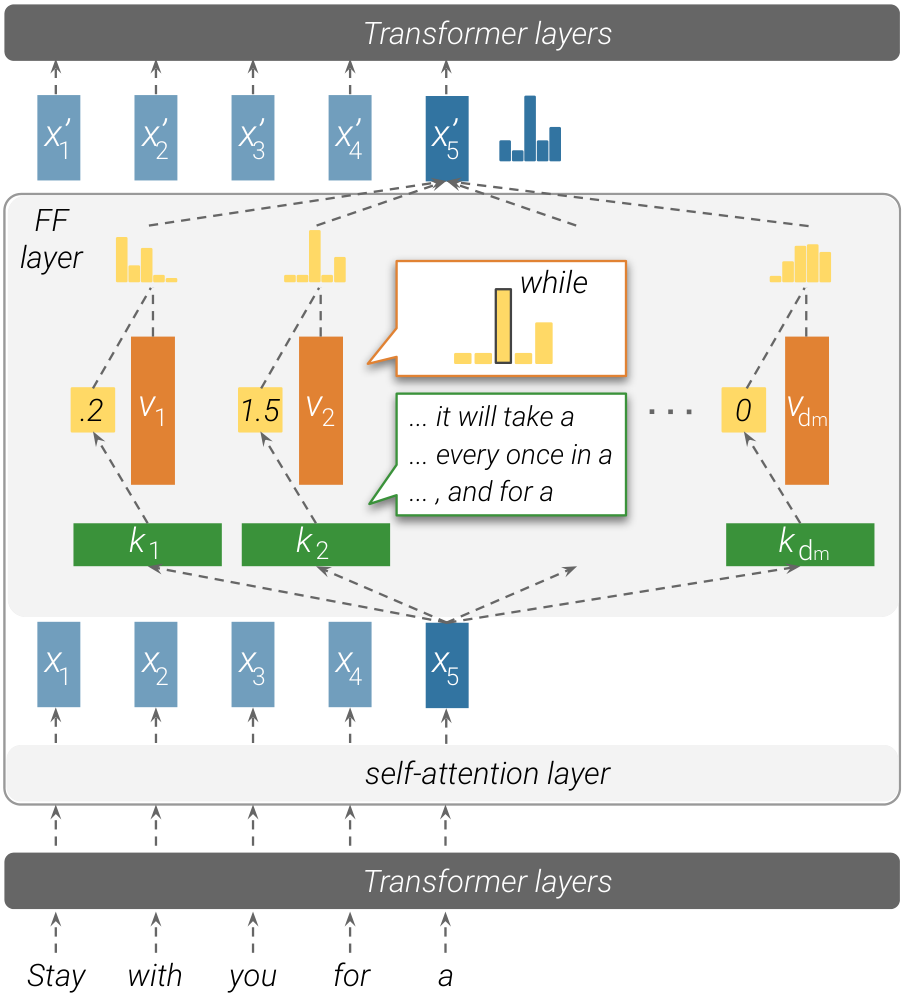
We show that feed-forward layers emulate neural memories
We find that each key correlates with a specific set of human-interpretable input patterns, such as -grams
riod of time and end with “a”. Simultaneously, we observe that each value can induce a distribution over the output vocabulary, and that this distribution correlates with the next-token distribution of the corresponding keys in the upper layers of the model. In the above example, the corresponding value
Lastly, we analyze how the language model, as a whole, composes its final prediction from individual memories. We observe that each layer combines hundreds of active memories, creating a distribution that is qualitatively different from each of its component memories’ values. Meanwhile, the residual connection between layers acts as a refinement mechanism, gently tuning the prediction at each layer while retaining most of the residual’s information.
In conclusion, our work sheds light on the function of feed-forward layers in transformer-based language models. We show that feed-forward layers act as pattern detectors over the input across all layers, and that the final output distribution is gradually constructed in a bottom-up fashion.1
2 Feed-Forward Layers as Unnormalized Key-Value Memories
Feed-forward layers A transformer language model
Here,
Neural memory A neural memory
With matrix notation, we arrive at a more compact formulation:
Feed-forward layers emulate neural memory Comparing equations 1 and 2 shows that feed-forward layers are almost identical to key-value neural memories; the only difference is that neural memory uses softmax as the non-linearity
We conjecture that each key vector
3 Keys Capture Input Patterns
We posit that the key vectors
| Key | Pattern | Example trigger prefixes |
|---|---|---|
| Ends with “substitutes” (shallow) | At the meeting, Elton said that “for artistic reasons there could be no substitutes In German service, they were used as substitutes Two weeks later, he came off the substitutes | |
| Military, ends with “base”/“bases” (shallow + semantic) | On 1 April the SRSG authorised the SADF to leave their bases Aircraft from all four carriers attacked the Australian base Bombers flying missions to Rabaul and other Japanese bases | |
| a “part of” relation (semantic) | In June 2012 she was named as one of the team that competed He was also a part of the Indian delegation Toy Story is also among the top ten in the BFI list of the 50 films you should | |
| Ends with a time range (semantic) | Worldwide, most tornadoes occur in the late afternoon, between 3 pm and 7 Weekend tolls are in effect from 7:00 pm Friday until The building is open to the public seven days a week, from 11:00 am to | |
| TV shows (semantic) | Time shifting viewing added 57 percent to the episode’s The first season set that the episode was included in was as part of the From the original NBC daytime version , archived |
then ask humans to identify patterns within the retrieved examples. For almost every key
3.1 Experiment
We conduct our experiment over the language model of
Retrieving trigger examples We assume that patterns stored in memory cells originate from examples the model was trained on. Therefore, given a key
Pattern analysis We let human experts (NLP graduate students) annotate the top-25 prefixes retrieved for each key, and asked them to (a) identify repetitive patterns that occur in at least 3 prefixes (which would strongly indicate a connection to the key, as this would unlikely happen if sentences were drawn at random) (b) describe each recognized pattern, and (c) classify each recognized pattern as “shallow” (e.g. recurring n-grams) or “semantic” (recurring topic). Each key and its corresponding top-25 prefixes were annotated by one expert. To assure that every pattern is grounded in at least 3 prefixes, we instruct the experts to specify, for each of the top-25 prefixes, which pattern(s) it contains. A prefix may be associated with multiple (shallow or semantic) patterns.
Table 1 shows example patterns. A fully-annotated example of the top-25 prefixes from a single memory key is shown in Appendix A.
3.2 Results
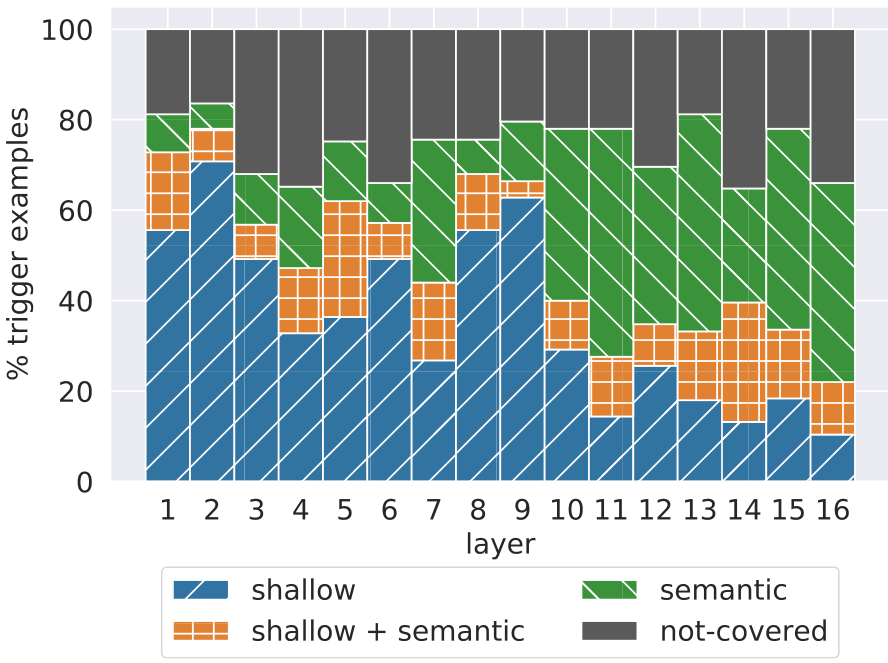
Memories are associated with human-recognizable patterns Experts were able to identify at least one pattern for every key, with an average of 3.6 identified patterns per
key. Furthermore, the vast majority of retrieved prefixes (65%-80%) were associated with at least one identified pattern
Shallow layers detect shallow patterns Comparing the amount of prefixes associated with shallow patterns and semantic patterns
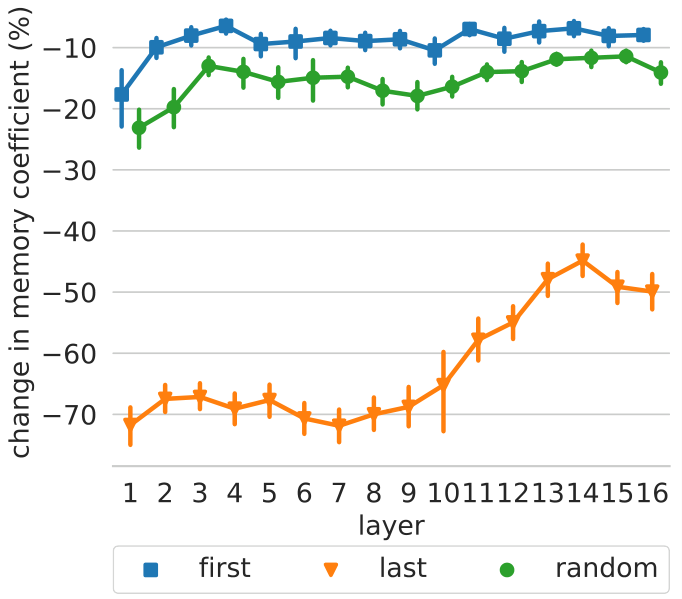
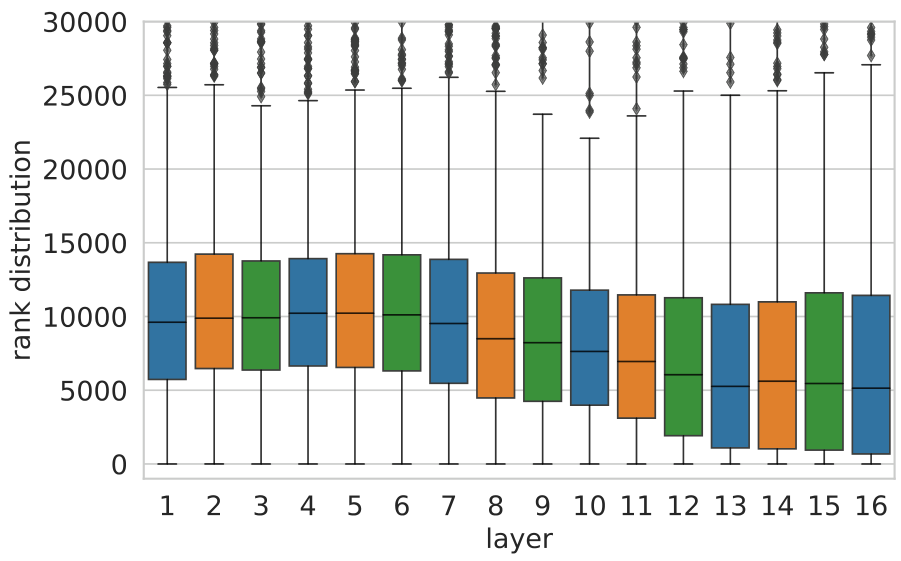
To further test this hypothesis, we sample 1600 random keys (100 keys per layer) and apply local modifications to the top-50 trigger examples of every key. Specifically, we remove either the first, last, or a random token from the input, and measure how this mutation affects the memory coefficient. Figure 3 shows that the model considers the end of an example as more salient than the beginning for predicting the next token. In upper layers, removing the last token has less impact, supporting our conclusion that upper-layer keys are less correlated with shallow patterns.
4 Values Represent Distributions
After establishing that keys capture patterns in training examples, we turn to analyze the information stored in their corresponding values. We show that each value
Casting values as distributions over the vocabulary. We begin by converting each value vector
The probability distribution
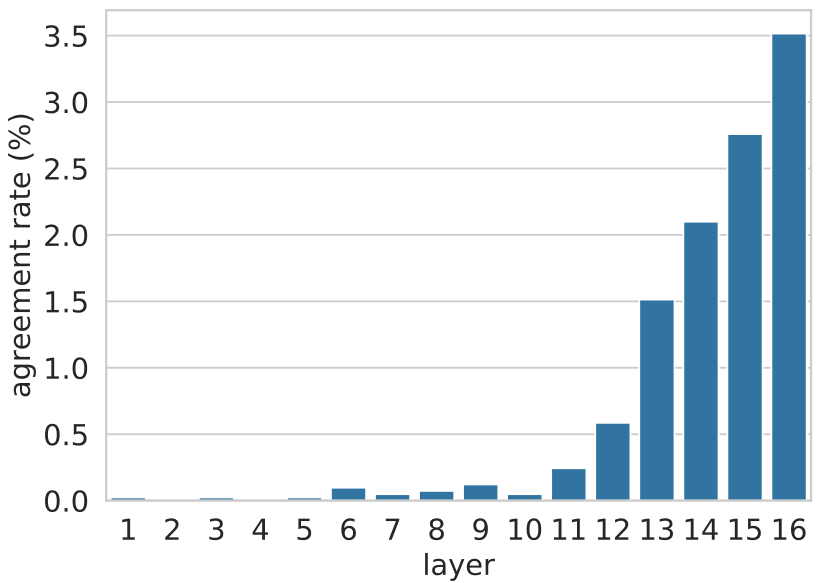
Value predictions follow key patterns in upper layers. For every layer
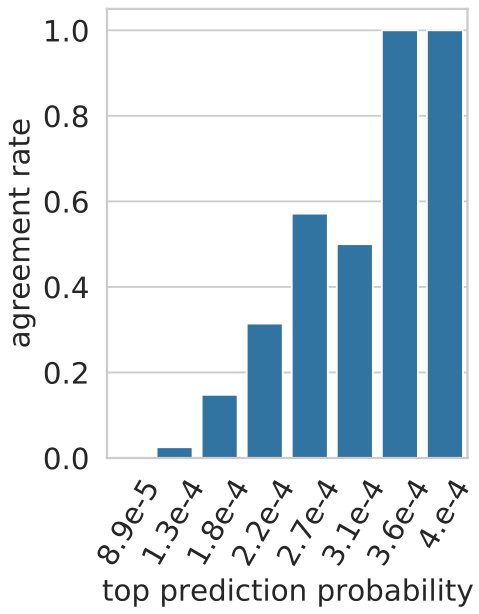
agreement rate is close to zero in the lower layers (1-10), but starting from layer 11, the agreement rate quickly rises until 3.5%, showing higher agreement between keys and values on the identity of the top-ranked token. Importantly, this value is orders of magnitude higher than a random token prediction from the vocabulary, which would produce a far lower agreement rate (0.0004%), showing that upper-layer memories manifest non-trivial predictive power.
Next, we take the next token of
Detecting predictive values. To examine if we can automatically detect values with high agreement rate, we analyze the probability of the values’ top prediction, i.e.,
Discussion. When viewed as distributions over the output vocabulary, values in the upper layers tend to assign higher probability to the next-token of examples triggering the corresponding keys. This suggests that memory cells often store information on how to directly predict the output (the distribution of the next word) from the input (patterns in the prefix). Conversely, the lower layers do not exhibit such clear correlation between the keys’ patterns and the corresponding values’ distributions. A possible explanation is that the lower layers do not operate in the same embedding space, and therefore, projecting values onto the vocabulary using the output embeddings does not produce distributions that follow the trigger examples. However, our results imply that some intermediate layers do operate in the same or similar space to upper layers (exhibiting some agreement), which in itself is non-trivial. We leave further exploration of this phenomenon to future work.
5 Aggregating Memories
So far, our discussion has been about the function of a single memory cell in feed-forward layers. How does the information from multiple cells in multiple layers aggregate to form a model-wide prediction? We show that every feed-forward layer combines multiple memories to produce a distribution that is qualitatively different from each of its component memories’ value distributions (Section 5.1). These layer-wise distributions are then combined via residual connections in a refinement process, where each feed-forward layer updates the residual’s distribution to finally form the model’s output (Section 5.2).
| Value | Prediction | Precision@50 | Trigger example |
|---|---|---|---|
| each | 68% | But when bees and wasps resemble | |
| played | 16% | Her first role was in Vijay Lalwani’s psychological thriller Karthik Calling Karthik, where Padukone was cast as the supportive girlfriend of a depressed man ( | |
| extratropical | 4% | Most of the winter precipitation is the result of synoptic scale, low pressure weather systems (large scale storms such as | |
| part | 92% | Comet served only briefly with the fleet, owing in large | |
| line | 84% | Sailing from Lorient in October 1805 with one ship of the | |
| jail | 4% | On May 11, 2011, four days after scoring 6 touchdowns for the Slaughter, Grady was sentenced to twenty days in |
5.1 Intra-Layer Memory Composition
The feed-forward layer’s output can be defined as the sum of value vectors weighted by their memory coefficients, plus a bias term:
If each value vector
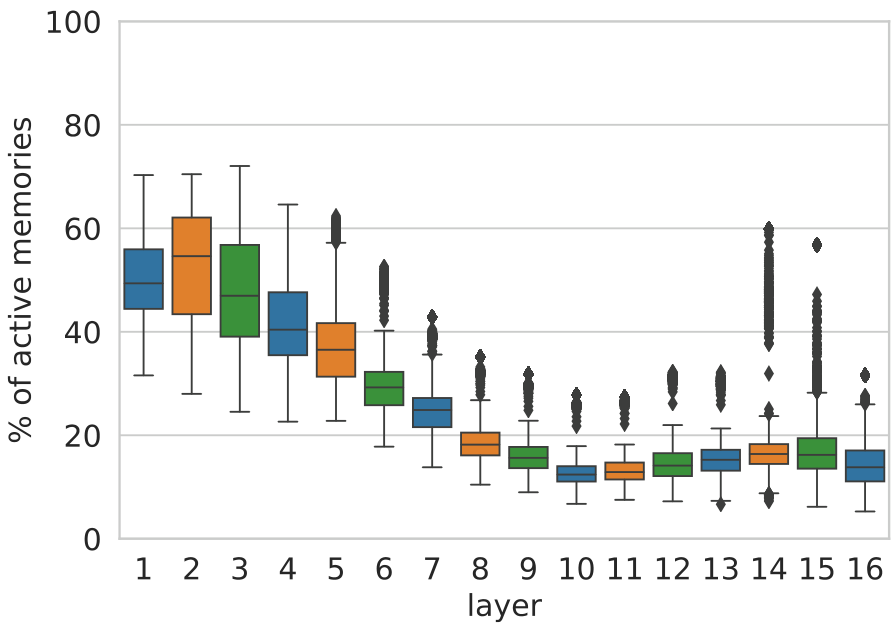
We first measure the fraction of “active” memories (cells with a non-zero coefficient). Figure 7 shows that a typical example triggers hundreds of memories per layer (10%-50% of 4096 dimensions), but the majority of cells remain inactive. Interestingly, the number of active memories drops towards layer 10, which is the same layer in which semantic patterns become more prevalent than shallow patterns, according to expert annotations
While there are cases where a single memory cell dominates the output of a layer, the majority of outputs are clearly compositional. We count the number of instances where the feed-forward layer’s top prediction is different from all of the memories’ top predictions. Formally, we denote:
as a generic shorthand for the top prediction from the vocabulary distribution induced by the vector
Figure 8 shows that, for any layer in the network, the layer’s final prediction is different than every one of the memories’ predictions in at least ~68% of the examples. Even in the upper layers, where the memories’ values are more correlated with the output space (Section 4), the layer-level prediction is typically not the result of a single dominant memory cell, but a composition of multiple memories.
We further analyze cases where at least one memory cell agrees with the layer’s prediction, and find that (a) in 60% of the examples the target token is a common stop word in the vocabulary (e.g. “the” or “of”), and (b) in 43% of the cases the input prefix has less than 5 tokens. This suggests that very common patterns in the training data might
be “cached” in individual memory cells, and do not require compositionality.
5.2 Inter-Layer Prediction Refinement
While a single feed-forward layer composes its memories in parallel, a multi-layer model uses the residual connection
We hypothesize that the model uses the sequential composition apparatus as a means to refine its prediction from layer to layer, often deciding what the prediction will be at one of the lower layers.
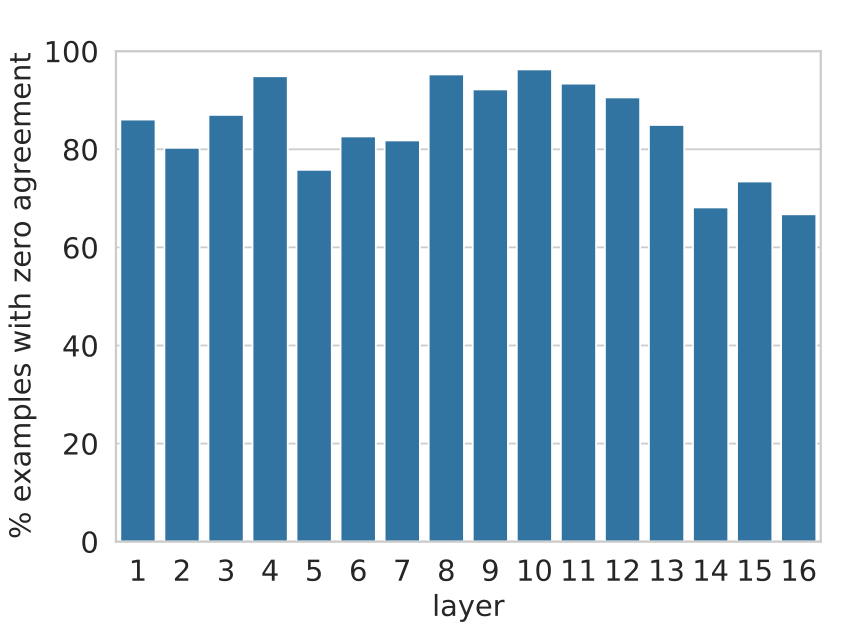
To test our hypothesis, we first measure how often the probability distribution induced by the residual vector
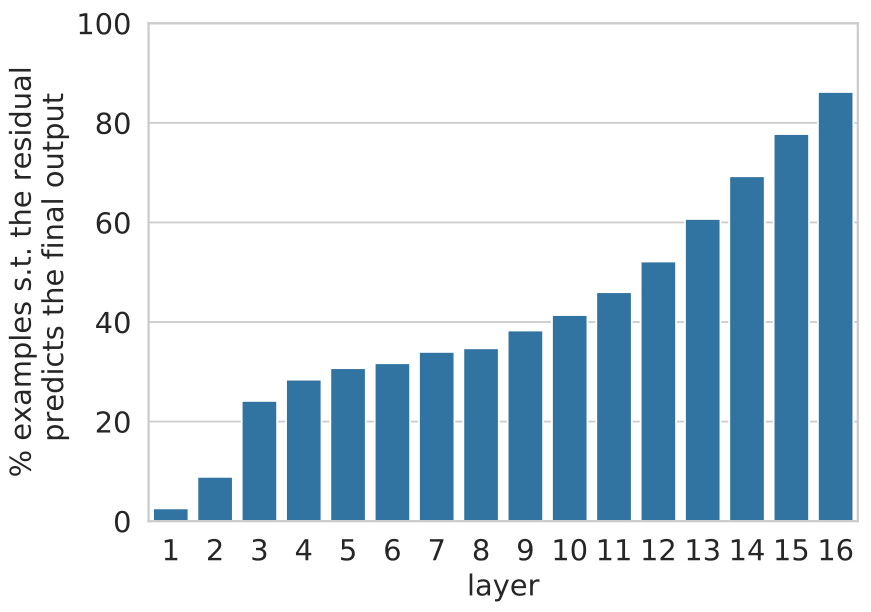
Figure 9 shows that roughly a third of the model’s predictions are determined in the bottom few layers. This number grows rapidly from layer 10 onwards, implying that the majority of “hard” decisions occur before the final layer.
We also measure the probability mass that each layer’s residual vector
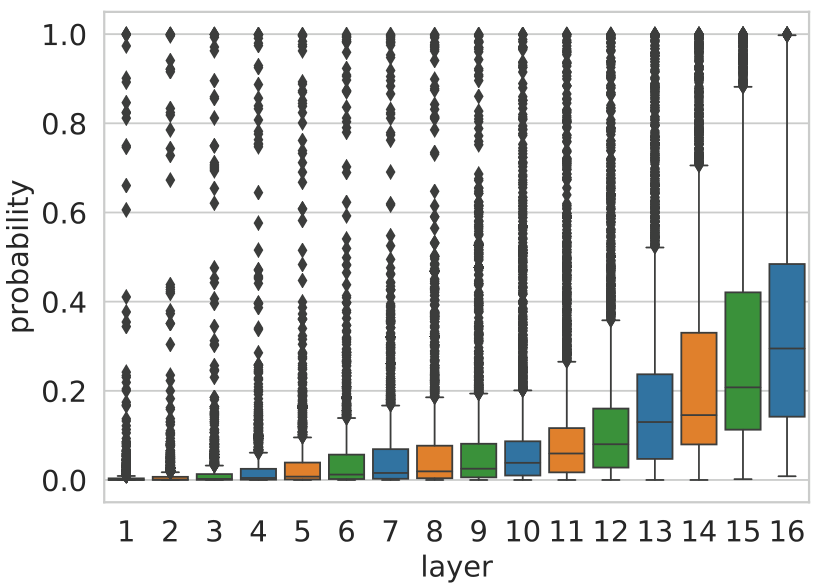
Figure 10 shows a similar trend, but emphasizes that it is not only the top prediction’s identity that is refined as we progress through the layers, it is also the model’s confidence in its decision.
To better understand how the refinement process works at each layer, we measure how often the residual’s top prediction changes following its interaction with the feed-forward layer , and whether this change results from the feed-forward layer overriding the residual or from a true composition .
Figure 11 shows the breakdown of different cases per layer. In the vast majority of examples, the residual’s top prediction ends up being the
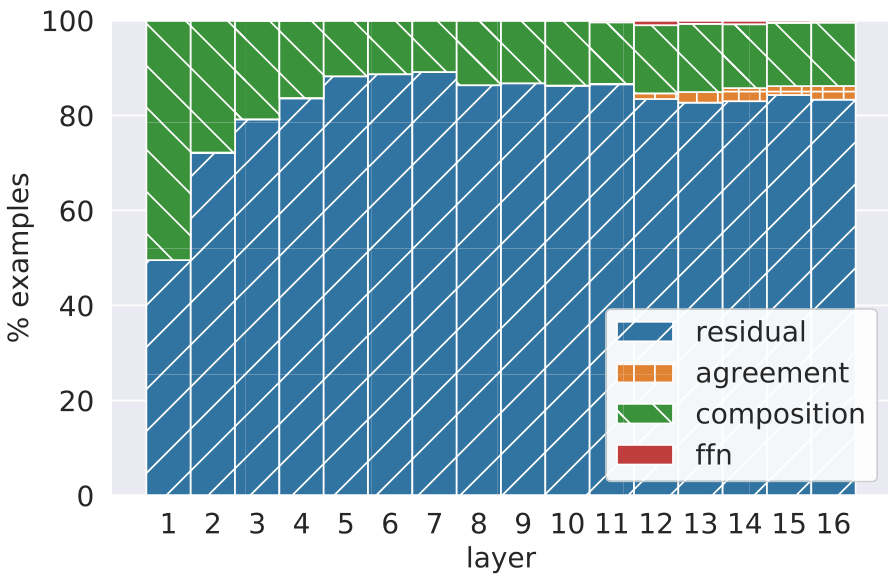
model’s prediction (residual+agreement). In most of these cases, the feed forward layer predicts something different (residual). Perhaps surprisingly, when the residual’s prediction does change (composition+ffn), it rarely changes to the feed-forward layer’s prediction (ffn). Instead, we observe that composing the residual’s distribution with that of the feed-forward layer produces a “compromise” prediction, which is equal to neither (composition). This behavior is similar to the intra-layer composition we observe in Section 5.1. A possible conjecture is that the feed-forward layer acts as an elimination mechanism to “veto” the top prediction in the residual, and thus shifts probability mass towards one of the other candidate predictions in the head of the residual’s distribution.
Finally, we manually analyze 100 random cases of last-layer composition, where the feed-forward layer modifies the residual output in the final layer. We find that in most cases (66 examples), the output changes to a semantically distant word (e.g., “people” “same”) and in the rest of the cases (34 examples), the feed-forward layer’s output shifts the residual prediction to a related word (e.g. “later” “earlier” and “gastric” “stomach”). This suggests that feed-forward layers tune the residual predictions at varying granularity, even in the last layer of the model.
6 Related Work
Considerable attention has been given to demystifying the operation of neural NLP models. An extensive line of work targeted neuron functionality in general, extracting the properties that neurons and subsets of neurons capture
The study of the transformer architecture has focused on the role and function of self-attention layers
Also related are interpretability methods that explain predictions
7 Discussion and Conclusion
Understanding how and why transformers work is crucial to many aspects of modern NLP, including model interpretability, data security, and development of better models. Feed-forward layers account for most of a transformer’s parameters, yet little is known about their function in the network.
In this work, we propose that feed-forward layers emulate key-value memories, and provide a set of experiments showing that: (a) keys are correlated with human-interpretable input patterns; (b) values, mostly in the model’s upper layers, induce distributions over the output vocabulary that correlate with the next-token distribution of patterns in the corresponding key; and (c) the model’s output is formed via an aggregation of these distributions, whereby they are first composed to form individual layer outputs, which are then refined throughout the model’s layers using residual connections.
Our findings open important research directions:
- Layer embedding space. We observe a correlation between value distributions over the output
vocabulary and key patterns, that increases from lower to upper layers
-
Beyond language modeling. Our formulation of feed-forward networks as key-value memories generalizes to any transformer model, e.g. BERT encoders and neural translation models. We thus expect our qualitative empirical observations to hold across diverse settings, and leave verification of this for future work.
-
Practical implications. A better understanding of feed-forward layers has many implications in NLP. For example, future studies may offer interpretability methods by automating the pattern-identification process; memory cells might affect training-data privacy as they could facilitate white-box membership inference
(Nasr et al., 2019) ; and studying cases where a correct pattern is identified but then suppressed during aggregation may guide architectural novelties.
Thus, by illuminating the role of feed-forward layers, we move towards a better understanding of the inner workings of transformers, and open new research threads on modern NLP models.
Acknowledgements
References
Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Proceedings of Neural Information Processing Systems (NeurIPS).
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019. What does BERT look at? An analysis of BERT’s attention. In BlackboxNLP Workshop at ACL.
Fahim Dalvi, Nadir Durrani, Hassan Sajjad, Yonatan Belinkov, Anthony Bau, and James Glass. 2019. What is one grain of sand in the desert? analyzing individual neurons in deep nlp models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6309–6317.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In North American Association for Computational Linguistics (NAACL), pages 4171–4186, Minneapolis, Minnesota.
Nadir Durrani, Hassan Sajjad, Fahim Dalvi, and Yonatan Belinkov. 2020. Analyzing individual neurons in pre-trained language models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).
Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pascal Vincent. 2009. Visualizing higher-layer features of a deep network. University of Montreal, 1341(3):1.
Xiaochuang Han, Byron C. Wallace, and Yulia Tsvetkov. 2020. Explaining black box predictions and unveiling data artifacts through influence functions. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5553–5563, Online. Association for Computational Linguistics.
Alon Jacovi, Oren Sar Shalom, and Yoav Goldberg. 2018. Understanding convolutional neural networks for text classification. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 56–65, Brussels, Belgium. Association for Computational Linguistics.
Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. 2019. What does BERT learn about the structure
Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. 2019. Linguistic knowledge and transferability of contextual representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1073–1094, Minneapolis, Minnesota. Association for Computational Linguistics.
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 2017. Pointer sentinel mixture models. International Conference on Learning Representations (ICLR).
Jesse Mu and Jacob Andreas. 2020. Compositional explanations of neurons. In Proceedings of Neural Information Processing Systems (NeurIPS).
Milad Nasr, Reza Shokri, and Amir Houmansadr. 2019. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In 2019 IEEE Symposium on Security and Privacy (SP), pages 739–753.
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In North American Chapter of the Association for Computational Linguistics (NAACL).
Ofir Press, Noah A. Smith, and Omer Levy. 2020. Improving transformer models by reordering their sublayers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2996–3005, Online. Association for Computational Linguistics.
Bhargav Pulugundla, Yang Gao, Brian King, Gokce Keskin, Harish Mallidi, Minhua Wu, Jasha Droppo, and Roland Maas. 2021. Attention-based neural beamforming layers for multi-channel speech recognition. arXiv preprint arXiv:2105.05920.
Nils Rethmeier, Vageesh Kumar Saxena, and Isabelle Augenstein. 2020. Tx-ray: Quantifying and explaining model-knowledge transfer in (un-) supervised nlp. In Conference on Uncertainty in Artificial Intelligence, pages 440–449. PMLR.
S. Sukhbaatar, J. Weston, and R. Fergus. 2015. End-to-end memory networks. In Advances in Neural Information Processing Systems (NIPS).
Sainbayar Sukhbaatar, Edouard Grave, Guillaume Lample, Herve Jegou, and Armand Joulin. 2019. Augmenting self-attention with persistent memory. arXiv preprint arXiv:1907.01470.
Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. BERT rediscovers the classical NLP pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593–4601, Florence, Italy. Association for Computational Linguistics.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems (NIPS), pages 5998–6008.
Jesse Vig and Yonatan Belinkov. 2019. Analyzing the structure of attention in a transformer language model. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 63–76, Florence, Italy. Association for Computational Linguistics.
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. 2020. Investigating gender bias in language models using causal mediation analysis. Advances in Neural Information Processing Systems, 33.
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.
Sarah Wiegreffe and Yuval Pinter. 2019. Attention is not not explanation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 11–20, Hong Kong, China. Association for Computational Linguistics.
Hongfei Xu, Qiuhui Liu, Deyi Xiong, and Josef van Genabith. 2020. Transformer with depth-wise lstm. arXiv preprint arXiv:2007.06257.
A Pattern Analysis
Table 3 provides a fully-annotated example of 25 prefixes from the memory cell
B Implementation details
In this section, we provide further implementation details for reproducibility of our experiments.
For all our experiments, we used the language model of transformer_lm.wiki103.adaptive trained with the fairseq toolkit6.
WikiText-1037 is a well known language modeling dataset and a collection of over 100M tokens extracted from Wikipedia. We used spaCy8 to split examples into sentences (Section 3).
| 1 | It requires players to press |
|---|---|
| 1 | The video begins at a press |
| 1 | The first player would press |
| 1 | Ivy, disguised as her former self, interrupts a Wayne Enterprises press |
| 1 | The video then cuts back to the press |
| 1 | The player is able to press |
| Leto switched | |
| 1 | In the Nintendo DS version, the player can choose to press |
| 1 | In-house engineer Nick Robbins said Shields made it clear from the outset that he (Robbins) “was just there to press |
| 1 | She decides not to press |
| 1 | she decides not to press |
| 1 | Originally Watson signaled electronically, but show staff requested that it press |
| 1 | At post-game press |
| 1 | In the buildup to the game, the press |
| 2 | Hard to go back to the game after that news |
| 1 | In post-trailer interviews, Bungie staff members told gaming press |
| Space Gun was well received by the video game | |
| 1 | As Bong Load struggled to press |
| At Michigan, Clancy started as a quarterback, switched | |
| 1 | Crush used his size advantage to perform a Gorilla press |
| 1,2 | Groening told the press |
| 1 | Creative director Gregoire <unk> argued that existing dance games were merely instructing players to press |
| 1,2 | Mattingly would be named most outstanding player that year by the press |
| 1 | At the post-match press |
| 1,2 | The company receives bad press |
| ID | Description | shallow / semantic |
|---|---|---|
| 1 | Ends with the word “press” | shallow |
| 2 | Press/news related | semantic |
Table 3: A pattern annotation of trigger examples for the cell memory
Footnotes
-
The code for reproducing our experiments is available at GitHub. ↩ -
We use the terms “memory cells” and “memories” interchangeably. ↩
-
We segment training examples into sentences to simplify the annotation task and later analyses. ↩
-
This is a simplification; in practice, we use the adaptive softmax
(Baevski and Auli, 2019) as described by Baevski and Auli to compute probabilities. ↩ -
The residual propagates information from previous layers, including the transformer’s self-attention layers. ↩