Baye’s Theorem: What’s ?
What are the chances of me having cancer? If I don’t know anything else, the chances are the same as anyone else in my demographic → That’s the prior , the best guess without any further info.
If I take a test or have a symptom, I get extra information about and can update that information.
is something we can usually calculate pretty easily as opposed to updating (would need to collect more data, …).
See below as for how to calculate (by considering all the ways can happen, weighted by how likely each way is).
The basic idea of bayesian statistics is sequentially updating your beliefs given new information.
New evidence should not determine beliefs in a vacuum.
Visual explanation
Interactive visualization: https://srulix.com/projects/bayesground?standalone=true
… hypothesis “is a librarian” vs. “is a farmer”
… evidence “is shy”
… how likely is it that somebody is a librarian (prior; If we have no clue, it could be a guess, or uniform distribution 50/50 in this case).
… how likely is it that somebody is a librarian, given that they are shy (posterior we’d like to know).
… how likely is it that a librarian is shy.
… how likely is it that somebody is a farmer.
… how likely is it that somebody is shy (out of all librarians and farmers).
… how likely is it that a farmer is shy.. Questions about the personalities and sterotypes shift around the relevant likelihoods and .
Questions about the context shift around the prior
Among cases where the evidence is true, how often is the hypothesis true?
The probability and the hypothesis being true form an area, see below.

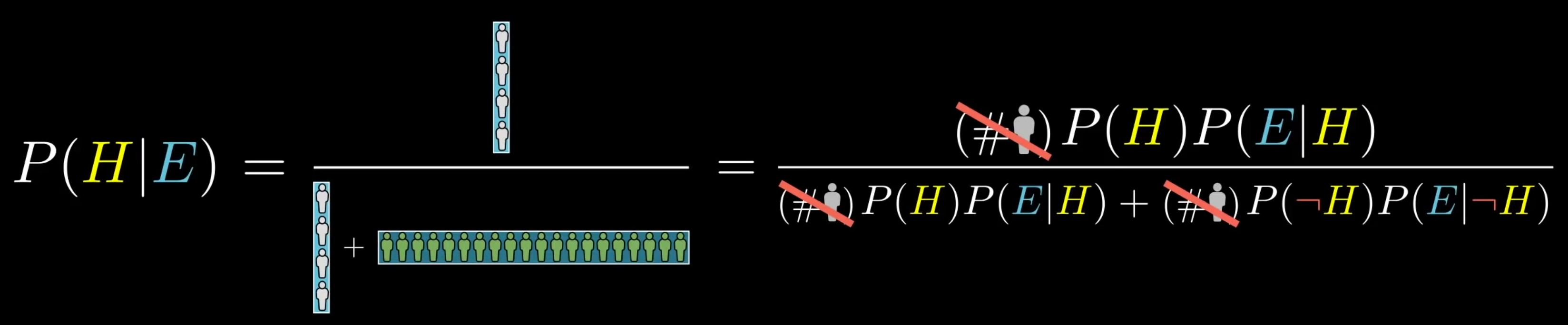
The numerator in Baye’s rule is the probability of both the hypothesis and evidence occuring (chain rule of probability). 1
Spam filter
… how likely is it that an email is spam (prior)
… how likely is it that the word appears in spam emails (likelihood)
… how likely is it that the word appears in any email (evidence, aka marginal likelihood)
… how likely is it that an email is spam, given that it contains the word (posterior)
Sensitivity and specificity
Assume a drug test which has 90% sensitivity (true positive rate or “recall”), i.e. the probability of a positive result given it’s a drug user .
And 80% specificity (true negative rate or “selectivity”), i.e. .This test is quite bad, 20% of non-users get a false positive. Let’s also say 10% of the population use the drug .
The probability of someone being a drug-user after testing positive is:So the probability that you did actually use the drug is only 33%. Even if the sensitivity is 1, we only reach ~35%.
This error gets better for more common events.This is also relevant for machine learning: We can get close to 100% accuracy just by ignoring very rare samples (high sensitivity, low specificity).
If we don’t know , we can express it as conditional probabilities we do know with the help of the law of total probability.
Or generally, for multiple hypotheses that partition the sample space:
So to get , we consider all the ways can happen, weighted by how likely each way is.
If we don’t have “all hypotheses”, we can add an “other” hypothesis with .
Link to originalThe marginal likelihood normalizes the posterior
The marginal likelihood represents the total probability of observing our data, accounting for all possible parameter settings according to our prior beliefs. It serves as the normalizing constant in Bayes Theorem:
Unlike the likelihood, which evaluates parameter settings individually, the marginal likelihood evaluates the model as a whole, integrating over the entire parameter space.
A good understanding of bayes theorem implies that experimentation is essential.
Link to originalBayesian Inference
Treats all parameters 1 as random variables with a prior distribution .
Update via Bayes’ rule:The posterior represents our updated beliefs about parameters after seeing data.
Computing it often requires intractable integrals (for the marginal likelihood ), leading to approximation methods:
- Variational inference - approximate posterior with simpler distribution
- Markov chain Monte Carlo - sample from posterior distribution
- Laplace approximation - Gaussian approximation around posterior mode
Visualization of how different priors and likelihoods affect the posterior.
Todo
Bayes' factor
References
probability
bayesian statistics
Footnotes
-
I find it much easier to reason over the rule / understand the visualization after knowing this identity… why don’t any of the popular explanations mention this? ↩