year: 2026
paper: brainca-brain-inspired-neural-cellular-automata-and-applications-to-morphogenesis-and-motor-control
website:
code: https://github.com/LPioL/BraiNCA | https://github.com/MaxWolf-01/brainca
connections: NCA, Benedikt Hartl, levin
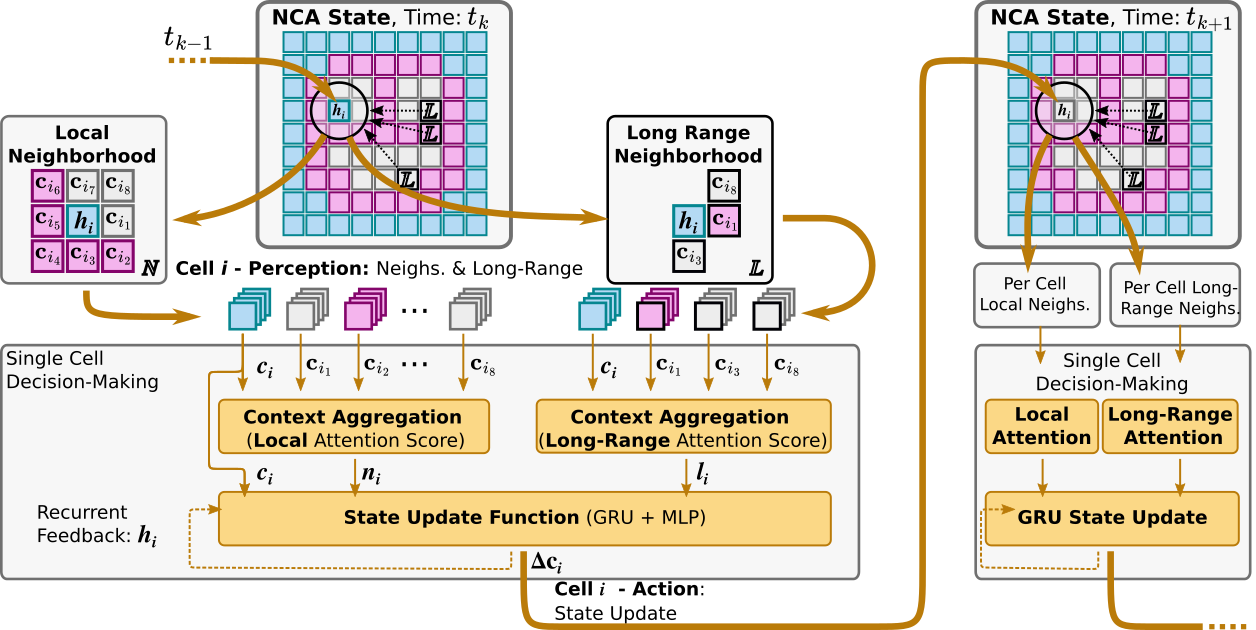
Notation
… cell state of cell at time
… optional conditioning input (positional encoding, prev action, …)
… extended state
… local neighborhood indices
… long-range neighborhood indices
… raw local attention score
… raw long-range attention score
… normalized local attention weight
… normalized long-range attention weight
… local attention MLP,
… long-range attention MLP,
… GRU hidden state (values aggregated by attention); in the code this is the cell state
… aggregated local signal
… aggregated long-range signal
… interaction vector
… composition operator for
… message MLP output, GRU input
… message MLP
… system-level feedback (e.g. one-hot prev action)
… external observation
… GRU cell
… refinement residual
… refinement MLP
… per-cell action logits (lunar lander)
… per-cell fire probability
… cells in action region
… region-level action logit
… action policy
… number of cells
… cell state dim
… extended state dim
… attention score dim
… message dim
… final timestep
Limitations / Ideas / Obvious next steps
- GRU, not QKV-attention-memory
- With graph attn there’s also no any2any between the msgs per node (not sure if it matters - prlly not if u factor efficiency and diffusion over time)
- Hidden state is public / the same as the public message, not compressed / …
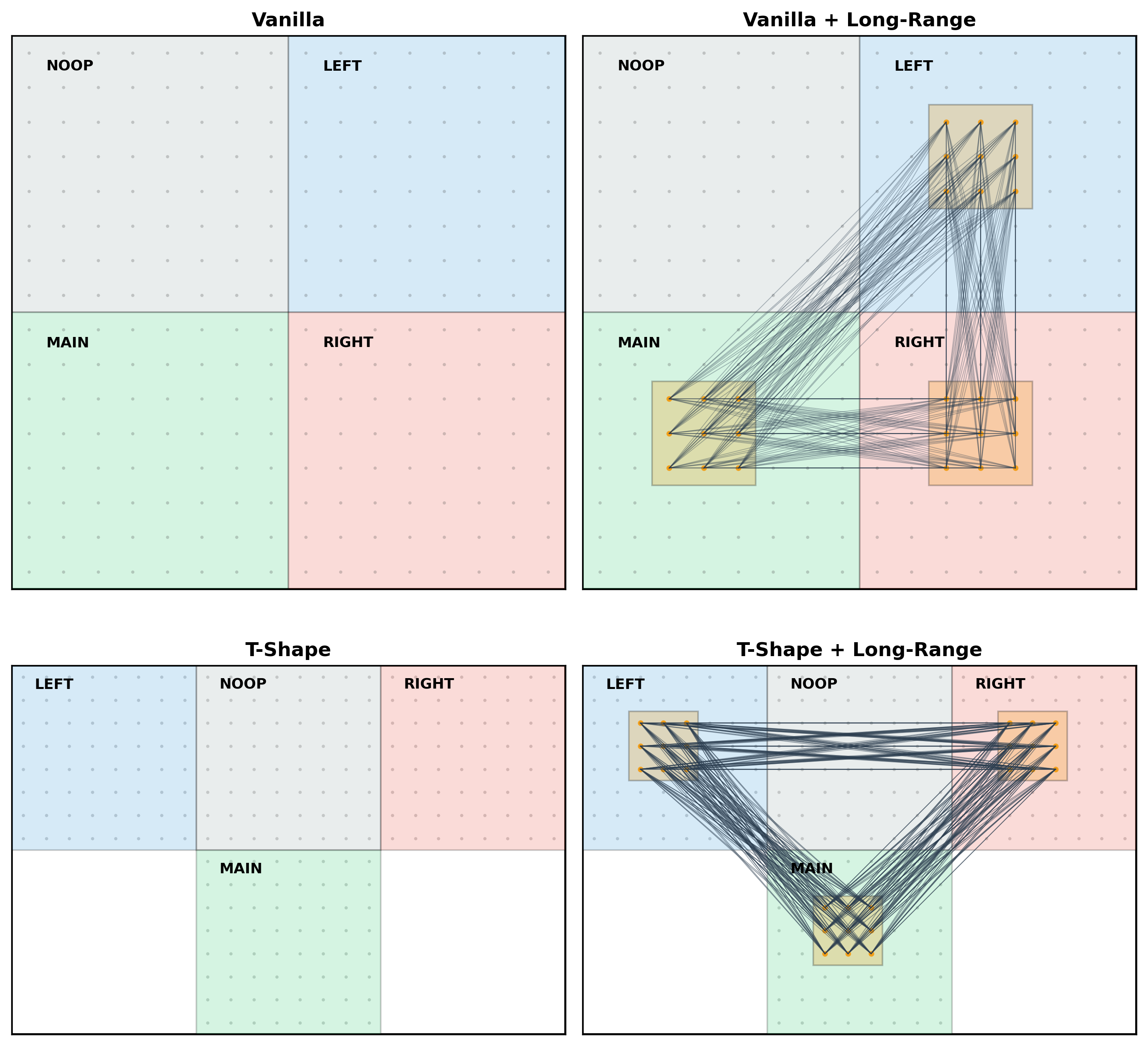
- Long-range connectivity is task-specific/engineered and fixed (Zipf’s law… tho it’s more complicated than that and different per task and… you get the point, it could be much simpler, bitter lesson pilled)
- All cells get (the same) observations…
- All cells are active every step
- Arrangement affects performance and learning speed - let the cells arrange themselves
- No growth and death; weights are the genome, evolved slowly over many generations of growth, growth happening during rollouts (i.e. genome only meta learns). This prlly (definitely) needs some pre-training to have any chance of working. Perhaps… pre-pre-training the NCA on CAs…
Unclarities
- Why does the morpho experiment use additive fusion for the interaction vector while lunar lander concatenates ? Not motivated in the paper.
- why dont they do all to all comms in the attn agg? efficiency? unnecessary? (same info is spread out through timesteps) - maybe full attn only worth it for internal states
- Lunar lander readout: paper prose says ” output is split into two heads” but the equations write both heads as reading from directly. : , but , suggests the prose is right and the equations are wrong. And it also makes more sense that way…
BraiNCA
Init:
(morpho) or (lunar)
Obs and optional system-feedback broadcast to all cells (last action taken by lander, one-hot; empty in morpho).
Connections
Repeat for steps (morpho: total; lunar: per env step), cells ():
Lunar lander
- cells are placed in regions, quadrants or somatotopic (T-shaped, like the body of a lander, left right thrusts up top, main thruster down bottom, noop action regions bottom left and right). The noop region is excluded from LR connections, which is not motivated.
- softmax over logits → fire probability
- majority vote, confidence weighted
- Within each region, compute a weighted average of fire logits , weighted by the fire probability/confidence :
- softmax over to get action dist to sample from
Detailed
Extended state bundles all non-cell-state inputs. What it contains is task-dependent: Morphogenesis: nothing , … 3 visible channels (cell type logits) + 6 hidden channels. (Code uses : 3 visible + 13 hidden.) Lunar lander: where is the previous fire/noop decision, and is normalized grid position 1 (static). … extended state. . The 1 is the previous fire/noop decision, the 2 is the positional encoding. … latent dim (no "visible" channels, the readout is via a separate action head).
Neighbor scoring ( graph attention) : Linear(, 64) → GELU → Linear(64, ), applied to the concatenated pair , with (a scalar score per neighbour). Each cell scores each of its neighbours independently, and local and long-range use separate . In the official implementation, the local scorer uses GELU but the long-range one uses ReLU, even though the paper says GELU for both.
\begin{align*}
a_{ij}^t &= f_{\text{attn}}^{(\mathcal{N})}([\mathbf{s}i^t;\mathbf{s}j^t]), \quad \alpha{ij}^t = \text{softmax}j(a{ij}^t), \quad \mathbf{n}i^t = \sum{k\in\mathcal{N}i}\alpha{ik}^t,\mathbf{h}k^t \
b{ij}^t &= f{\text{attn}}^{(\mathcal{L})}([\mathbf{s}i^t;\mathbf{s}j^t]), \quad \beta{ij}^t = \text{softmax}j(b{ij}^t), \quad \mathbf{l}i^t = \sum{k’\in\mathcal{L}i}\beta{ik’}^t,\mathbf{h}{k’}^t
\end{align*}Scoring uses the extended states $\mathbf{s}$; the aggregated values are the hiddens $\mathbf{h}_k$, i.e. the cell states $\mathbf{c}_k$ (see GRU note). Grid edges: the original impl. zero-pads, so a boundary cell's missing neighbours enter the softmax as zero vectors instead of being dropped. That gives every cell a distance-from-edge signal, which for morphogenesis is its only positional information (besides the init … which is supposed to be random… according to the paper, contrary to the code, but non-random would be a silly memorization task so all my final experiments use random inits). I first tried masking the edges instead but morphogenesis convergence was much more fragile (lunar has positional encodings)."Interaction vector" (cell input)
\mathbf{z}{i}^{t}=f{Z}(\mathbf{s}{i}^{t},\mathbf{n}{i}^{t},\mathbf{l}_{i}^{t})
Morphogenesis vanilla:
Morphogenesis long-range:
Lunar lander long-range:"Message MLP"
In morphogenesis, and are empty so it’s just . The code makes it a stack of 1×1 convs, , so comes out -dim and the GRU input matches its hidden width. The paper never states these dims.
In lunar lander, they’re simply concatted to , all cells receive the same obs.GRU update + readout as its recurrent input, so it reads like is a second state that persists on its own, next to . The code keeps no separate : it feeds in as the hidden; wherever the paper writes the implementation uses . That includes the that attention aggregates, which are just the neighbours' cell states .
The paper’s GRU takes
\begin{align*}
\mathbf{h}{i}^{t} &= f{\textnormal{GRU}}(\mathbf{m}{i}^{t},;\mathbf{c}{i}^{t}) \
\tilde{\mathbf{h}}_i^t &= \mathbf{h}i^t + f{\textnormal{refine}}(\mathbf{h}_i^t)
\end{align*}No $\mathbf{c}_t$ skip connection is needed because the gate already holds the old state. $\mathbf{h} = (1-\mathbf{z})\tilde{\mathbf{h}} + \mathbf{z}\,\mathbf{c}_t$ is an interpolation, so it's bounded, and $\mathbf{c}_{t+1} = \mathbf{h} + f_\text{refine}(\mathbf{h})$ doesn't blow up. If you take the paper literally instead (a separate $\mathbf{h}$) and add a $\mathbf{c}_t$ skip connection on top, which is what our first reimpl did, you get $\mathbf{c}_{t+1} = \mathbf{c}_t$ plus an $O(1)$ term that never goes to zero, and it blows up. $f_\text{refine}$: the "refinement MLP" (two dense layers, $C$ units, GELU), a [[ResNet|resblock]] on the GRU output. Morphogenesis: $\mathbf{c}_i^{t+1} = \tilde{\mathbf{h}}_i^t$ Lunar lander: $\mathbf{c}_i^{t+1} = W_C \, \tilde{\mathbf{h}}_i^t$ (state projection) and $\boldsymbol{\ell}_i^t = f_\text{act}(\tilde{\mathbf{h}}_i^t)$ (action logits). $f_\text{act}$: two-layer MLP (GELU), outputs 2D (noop, fire).