GRU
The Gated Recurrent Unit is an RNN that combines forget and input gates of the LSTM into a single update gate, and merges cell state and hidden state.
… input vector at time (t)
… previous and current hidden states
… update and reset gates (values between 0 and 1)
… sigmoid, tanh
… elementwise multiplication
… input weight matrices
… hidden state weight (update) matrices
… bias vectors
The notation here summarizes and into a single weight matrix each, and concatenates the input and hidden state vectors. Biases are like so often omitted for simplicity.
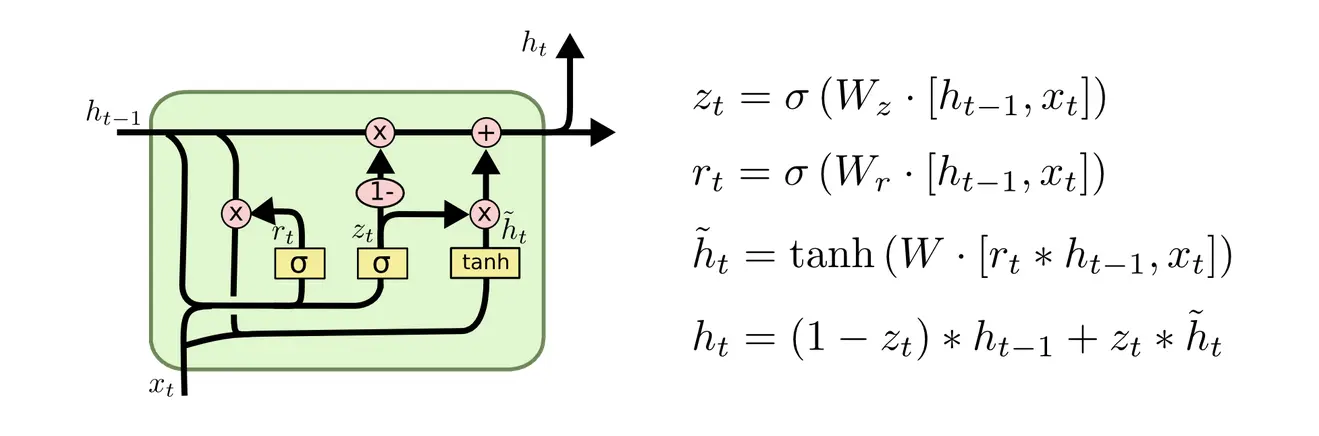

This matches how it’s actually implemented, doing 2 instead of 6 matmuls:
class GRUCellDiagram(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.gates = nn.Linear(input_size + hidden_size, 2 * hidden_size) # W_z and W_r
self.cand = nn.Linear(input_size + hidden_size, hidden_size) # W
def forward(self, x_t, h_prev): # (batch, input_size), (batch, hidden_size)
hx = torch.cat([h_prev, x_t], dim=-1)
r_t, z_t = self.gates(hx).chunk(2, dim=-1)
r_t = torch.sigmoid(r_t)
z_t = torch.sigmoid(z_t)
rhx = torch.cat([r_t * h_prev, x_t], dim=-1)
h_hat = torch.tanh(self.cand(rhx))
h_t = (1.0 - z_t) * h_prev + z_t * h_hat
return h_t