year: 2025/01
paper: https://papers-pdfs.assets.alphaxiv.org/2505.12082v3.pdf
website: bycloud youtube video
code:
connections: model merging, ML-Performance Tricks, SPARTA, distributed training, DiLoCo, bytedance
PMA (Pre-trained Model Averaging) lets you skip annealing during pre-training while achieving similar performance. Instead of gradually decaying the learning rate at the end of training, you just average checkpoints saved during the constant learning rate phase.
The PMA process
Save checkpoints at fixed token intervals during constant LR training.
Average all these snapshots with Simple Moving Average (SMA) to get a final model.
This merged model achieves performance equivalent to full annealing - but saves ~15% compute and 3-6 days of training.The technique is shown to work on models from 411M to 70B parameters and MoE architectures up to 200B total parameters.
Tested three averaging methods: SMA (equal weights), EMA (exponential decay), WMA (linear decay).
SMA wins because late checkpoints converge closer together with less variance - EMA/WMA would overweight these low-information checkpoints.Is this related to continual learning / exploration? Or just the high-pass filter / averaging out the noise effect?
![[Model Merging in Pre-training of Large Language Models-1753039449797.webp]]
![[Model Merging in Pre-training of Large Language Models-1753039491111.webp]]Why model merging predicts annealing
During constant LR training, weights oscillate around the optimal point like a noisy signal. annea dampens these oscillations iteratively - acting as a low-pass filter.
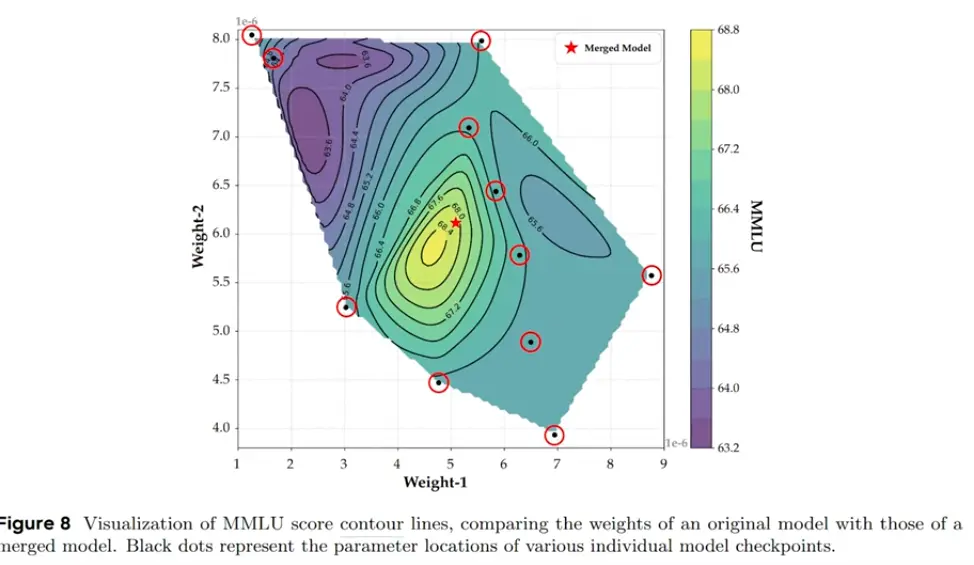
SMA achieves the same effect in one shot. It cancels out positive/negative deviations across the checkpoint window, extracting the smooth low-frequency component without changing the learning rate. On 2D weight contour plots, individual checkpoints scatter in a ring around the basin while the merged point sits at the peak:
Mathematical analysis shows merging works when deviation vectors have negative correlation in the Hessian sense: . This “complementarity” means checkpoints explore different directions in parameter space.
Model merging during pre-training provides
- Early performance estimates without waiting for full training
- 3-7% accuracy gains essentially for free
- Resilience to training instabilities and loss spikes
- Crash recovery by merging last stable checkpoints
Connection to SPARTA
Both PMA and SPARTA leverage weight averaging instead of gradient synchronization. While PMA averages complete checkpoints at intervals, SPARTA continuously averages sparse subsets (0.05-0.5%) of parameters. This shared principle - that weight space moves slowly enough for asynchronous averaging - enables both methods to reduce communication overhead in distributed training.
Optimal interval scales with model size:
0.7B / 8B tokens → every 4B tokens
1.3B / 13B tokens → every 8B tokens
10B / 100B tokens → every 80B tokens