year: 2018
paper: https://arxiv.org/abs/1806.07366
website: Steve Brunton🐐 Yannik Paper Explained
code: https://github.com/llSourcell/Neural_Differential_Equations/blob/master/Neural_Ordinary_Differential_Equations.ipynb nice example code!
connections: optimization, lagrange multiplier
overview and intuition
A ResNet can be thought of as a discrete-time analogs to an ODE:
You update the representation in discrete steps layer by layer. Neural ODE views this as an infinite process with continous time.
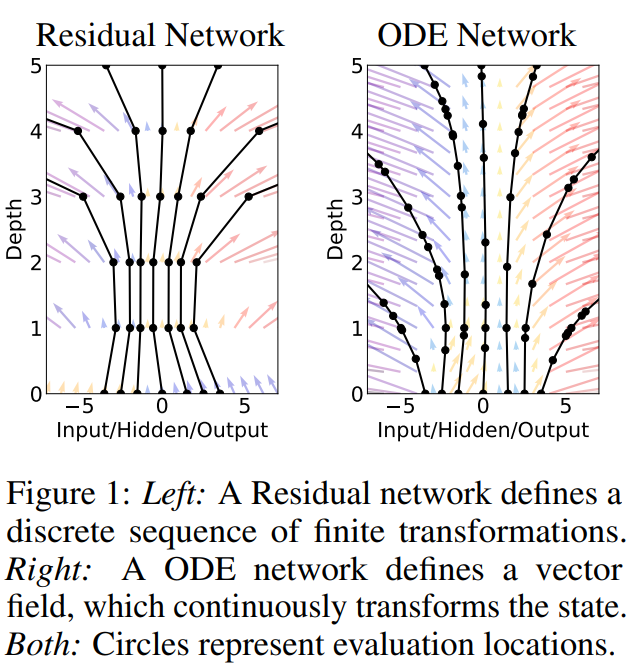
The regular NN has a discrete gradient field, whereas the gradient field of the ODE Network is continous. The black dots are data points.
Again, with resnet you only model the distance (residual) of
… this is a textbook euler numerical integrator (However euler integration, esp. with large time steps is a bad numerical integration method). So the resnet is doing euler integration over a vector field , so what the neural network is learning, , can also be thought of as a vector field, a differential equation
With NODE, we model the differential equation itself, instead of just a one-timestep-update or flow-map of the differential equation.
So it is a generalization of resnets to continuous time, where you also use a fancier integrator and smallar or arbitrary time-steps to model the vector field very accurately.
The mathematician’s solution to this would be:
That’s hard to compute, hence we approximate it (and you can use any integrator for that).
Classic dynamical system:
With NODE, is parametrized by a neural network
Free parameters:
network parameters
initial condition
timestep
Hidden state:
… data is samples at discrete points in time (doesn’t need to be uniformly in time), so between any two data / measurement points, there is a continous state and the flow map integrates along that hidden state from to .
And we want information about this hidden state, which is not in the training data!
TODO
steve skips over the details here “lagrange multiplier, adjoint equation”, “we been knowing how to do this the past 20 years”, … TODO steve’s optimization bootcamp)
tldr: we can keep track of the variable which keeps track of with AD, in the paper called reverse-mode differentiation
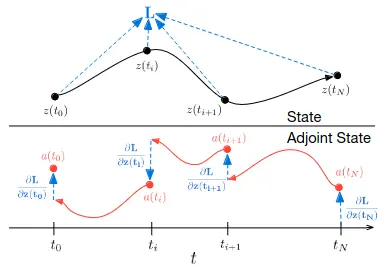
algorithm details
You solve a differential equation, that has the starting state of e.g. an image, and the end state - the function value at some point in time - is your classification. And at each point in time, the ODE solver queries the function for the gradient and solves it (???: minimizes it along some direction?)
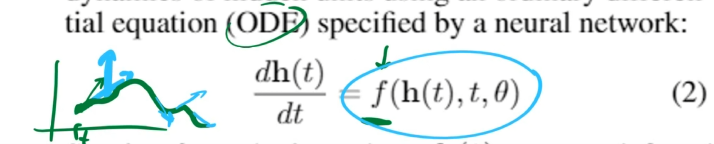
is an equation defined by a neural network (green) and the (blue) arrows are the gradients at specific points in time.
But instead of going from input to output, this network parametrizes (learns) how you go from each step in time to the next (the gradient at each infinitesimally small timestep).
We start from the input layer and we define the output layer to be the solution to the ODE with initial value at some time . An ODE solver calculates the necessary steps wherever necessary i.e. with arbitrary accuracy / time steps to achieve the desired accuracy (e.g. look at the ODE gradient field in the first figure: The black dots / points where the gradient was calculated are at arbitrary time intervals in contrast to the ResNet “which requires discretizing observation and emission intervals”).
The loss of the end state is equal to the loss of the start state plus the integral over time of the ODE given by and ODE solver:
The network doesn’t represent the continuous function, but is a discrete approximation to the linear update equation of ODEs (?)