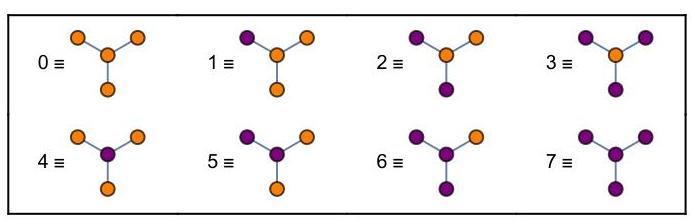
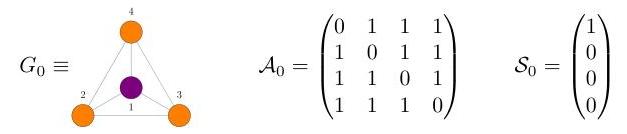Example of evolution starting from a simple initial graph:
Indexing configurations.
The number of possible configurations of node+neighbourhood for their undirected, simple, binary, d-regular graphs is 2(d+1), since each of the d neighbours and the node itself can be either alive or dead.
The following formula gives us indices from [0,2(d+1)), which uniquely identify each configuration:
c(v)=(d+1)⋅s(v)+n∈N(v)∑s(n)
If a node is dead and has k alive neighbours, its configuration index is k
If a node is alive and has k alive neighbours, its configuration index is d+1+k
Note: Order of neighbours does not matter since the graph is undirected.
Rules.
A rule deterministically maps each configuration the next state of the node, and whether to apply a division: Dead vs. alive, and divide vs. not divide.
Thus, for each configuration, there are 4 possible outputs, leading to a total of 42(d+1) possible rules (for d=3, this is 48=65536 possible rules).
The rule function is composed of two functions:
R:{0,…,d}→{0,1}(node state update)R(c(vt))=s(vt+1)R′:{0,…,d}→{0,1}(node division decision)R′(c(vt))={1,if c(vt) leads to a division0 otherwise
Rules are also indexed. The unique rule numbern is computed as:
n=i=0∑2(d+1)−1[2iR(i)+2i+2(d+1)R′(i)]
This allows us to represent each rule as a binary string of length 2⋅2(d+1), similarly to wolfram code.
Each unique bit position i contributes 2i to the total rule number if it’s a 1, and 0 if it’s a 0, just like in standard binary representation. Here, R sets the lower half (LSB) of the bits, and R′ sets the upper half (MSB).
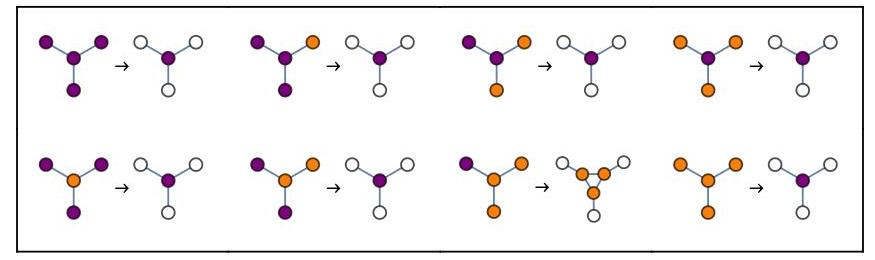
Rule for the example given at the top: n=765=00000010111111012 (for d=3)
Read the figure from left to right top to bottom, with the rules in pairs: 00000010 … there’s only one configuration where division occurs 11111101 … there’s only one configuration where a node dies
A … adjacency matrix of graph G=(V,E) S=[s(v1),s(v2),…s(v∣G∣)]T … state vector A⋅S … sum of neighbour states for each node
The next state vector S′ is computed as:
S′=R(C)
Where R is applied element-wise to the configuration vector C.
Similarily, the division vectorD is computed as:
D=R′(C)
Where R′ is applied element-wise to the configuration vector C.
Divisions.
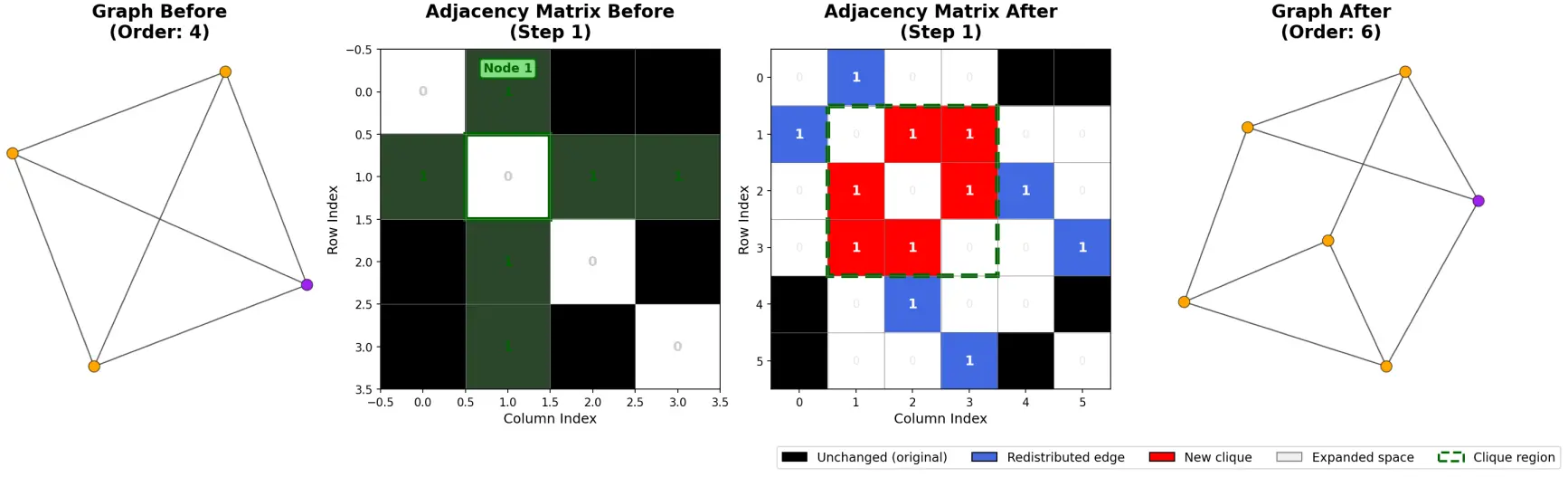
Divisions can now be performed one by one as a combination of simple operations on matrices. The first 1 in D signals the vertex to divide.
For the state vector, suffice to triple the line corresponding to this vertex.
For the adjacency matrix, both the line and the column must be tripled. Ones then have to be spread across these lines and columns and the intersection must be filled with a sub-matrix containing zeros on the diagonal and ones everywhere else.
Finally, the first 1 in the division vector is turned into a 0 and then tripled. This process must be repeated until D is a null vector.
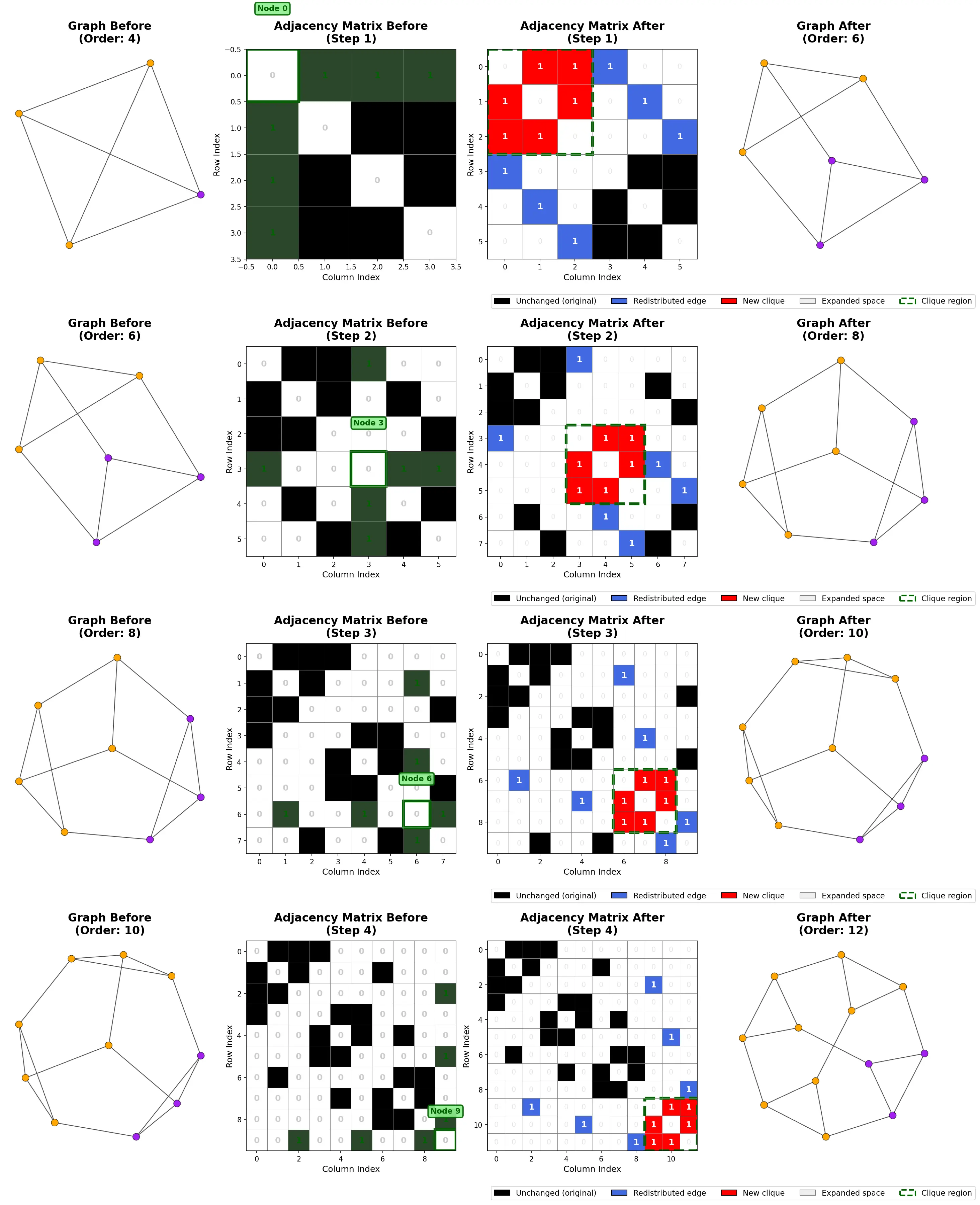
Dividing all nodes of the graph above
You could perform all four steps in parallel/one step (they’re independent and commutative), but it’s not clear to me how
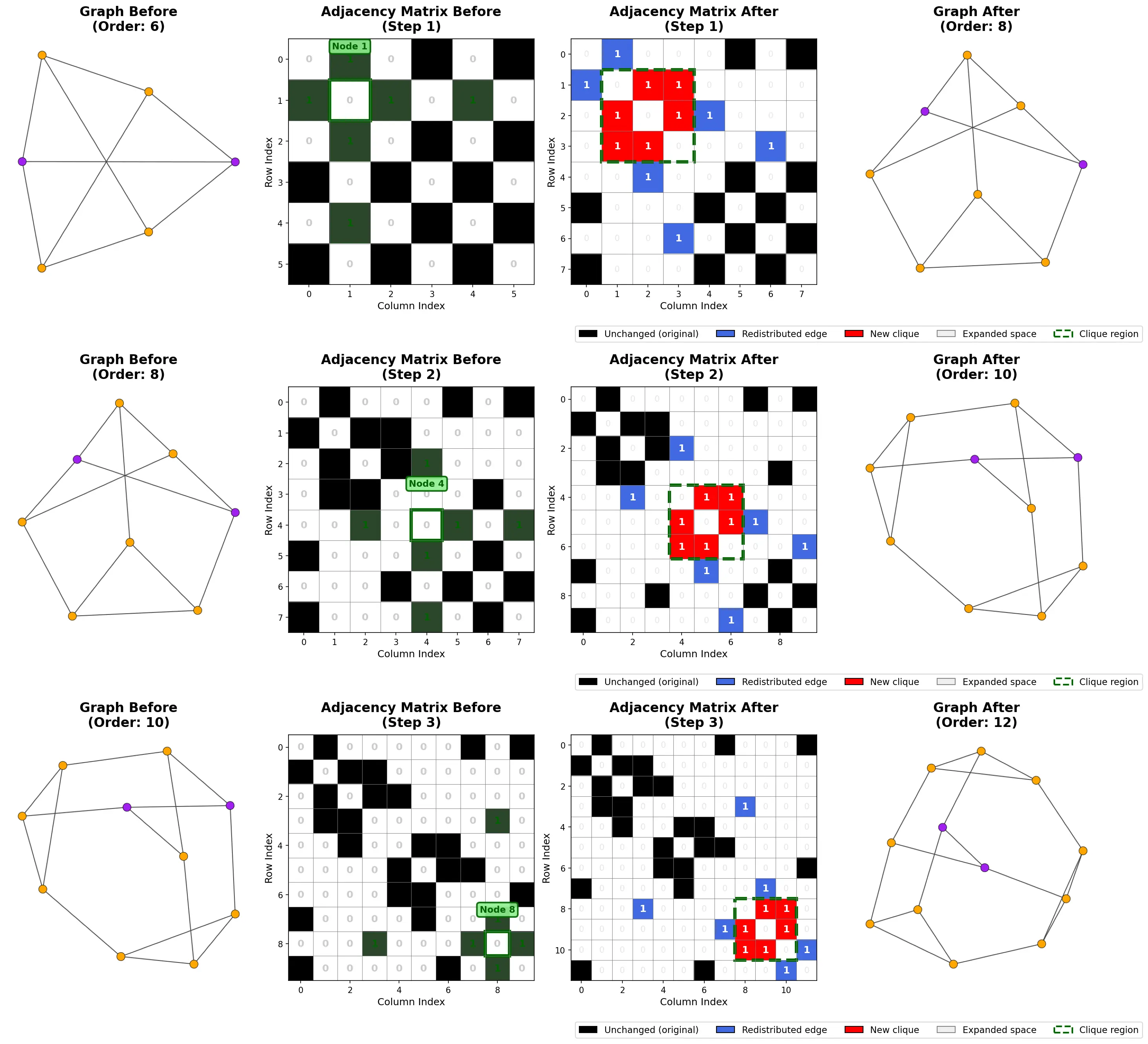
Divisions on a chessboard graph
80-line Jax implementation
It’s 1.6x slower than the original tensorflow implementation, but it works. I’m gonna blame it on Jax’ sparse support, but it’s also my first time using it so ¯\_(ツ)_/¯ (and jit wouldn’t help here because of dynamic shapes in division, which takes up most of the time).
EDIT: Turns out it’s much simpler / more efficient if you use neighbour lists
@dataclass(frozen=True)class Graph: adjacency: sparse.BCOO state: jnp.ndarray @dataclass(frozen=True) class Rule: number: int degree: int = 3 def __post_init__(self) -> None: assert self.degree > 0 assert 0 <= self.number < 4 ** (2 * (self.degree + 1)) @cached_property def binary(self) -> jnp.ndarray: rule = list(map(int, np.binary_repr(self.number))) rule += [0] * (4 * (self.degree + 1) - len(rule)) return jnp.array(rule[::-1], dtype=jnp.int32) @cached_property def binary_lsb(self) -> jnp.ndarray: return self.binary[::-1] def __repr__(self) -> str: return f"Rule(degree={self.degree}, number={self.number}, binary={''.join(map(str, self.binary.tolist()))})" def __call__(self, g: Graph) -> Graph: new_state, division_vector = apply_rule_without_division(self, g.adjacency, g.state, self.binary_lsb) C = (rule.degree + 1) * g.state + g.adjacency @ g.state new_state = self.binary_lsb[C] division_vector = self.binary_lsb[C + 2 * (rule.degree + 1)] div_indicies = jnp.where(division_vector != 0)[0] current_adjacency, current_states = g.adjacency, new_state for i, idx in enumerate(div_indicies): idx += i * (self.degree - 1) # net addition of two nodes current_adjacency, current_states = divide(current_adjacency, current_states, idx, self.degree) return Graph(current_adjacency, current_states, d=self.degree) def divide(adjacency: sparse.BCOO, states: jnp.ndarray, div_idx, degree: int): n = adjacency.shape[0] new_size = n + degree - 1 # replace state of div_idx with degree copies of itself new_states = jnp.concatenate([states[:div_idx], jnp.full((degree, 1), states[div_idx]), states[div_idx + 1 :]]) (rows, cols), data = adjacency.indices.T, adjacency.data neighbours = rows[cols == div_idx] neighbours = jnp.sort(neighbours) # consistent ordering # remove edges connected to div_idx mask = (rows != div_idx) & (cols != div_idx) rows, cols, data = rows[mask], cols[mask], data[mask] # shift indices greater than div_idx by degree - 1 to account for new nodes rows = jnp.where(rows > div_idx, rows + degree - 1, rows) cols = jnp.where(cols > div_idx, cols + degree - 1, cols) neighbours = jnp.where(neighbours > div_idx, neighbours + degree - 1, neighbours) # add clique of new nodes clique_rows = jnp.repeat(jnp.arange(div_idx, div_idx + degree), degree) clique_cols = jnp.tile(jnp.arange(div_idx, div_idx + degree), degree) clique_mask = clique_rows != clique_cols clique_rows, clique_cols = clique_rows[clique_mask], clique_cols[clique_mask] clique_data = jnp.ones_like(clique_rows, dtype=jnp.int32) # redistribute neighbours sequentially, connecting each of the original neighbours to one of the new nodes connect_rows = neighbours connect_cols = div_idx + jnp.arange(degree) connect_data = jnp.ones_like(connect_rows, dtype=jnp.int32) # combine all # symmetric adjacency all_rows = jnp.concatenate([rows, clique_rows, connect_rows, connect_cols]) all_cols = jnp.concatenate([cols, clique_cols, connect_cols, connect_rows]) all_data = jnp.concatenate([data, clique_data, connect_data, connect_data]) new_adjacency = sparse.BCOO((all_data, jnp.stack([all_rows, all_cols], axis=1)), shape=(new_size, new_size)) return new_adjacency, new_states ```
Results / Exploration.
Search Space.
They exhaustively explore the set of rules with one division.
This set is color symmetric, i.e. swapping alive/dead states gives an equivalent rule with inverted colors.
Hence it’s sufficient to explore half the rules only.
So there are 4 division rules: c0 divides (dead, 0 alive neighbours), … c3 divides (dead, 3 alive neighbours)).
And there are 28=256 possible survival rules (8 configurations, each can lead to alive or dead).
Hence,
n∈{i+2j∣i∈{0,…255},j∈{8,…,1}}
They use an initial graph G0 which contains all configurations, to ensure G1=G0, i.e. each rule gets a chance.
They classify by growth type using “several methods, mainly the least squares method”:
For halted (cyclic) patterns, they examine the periods:
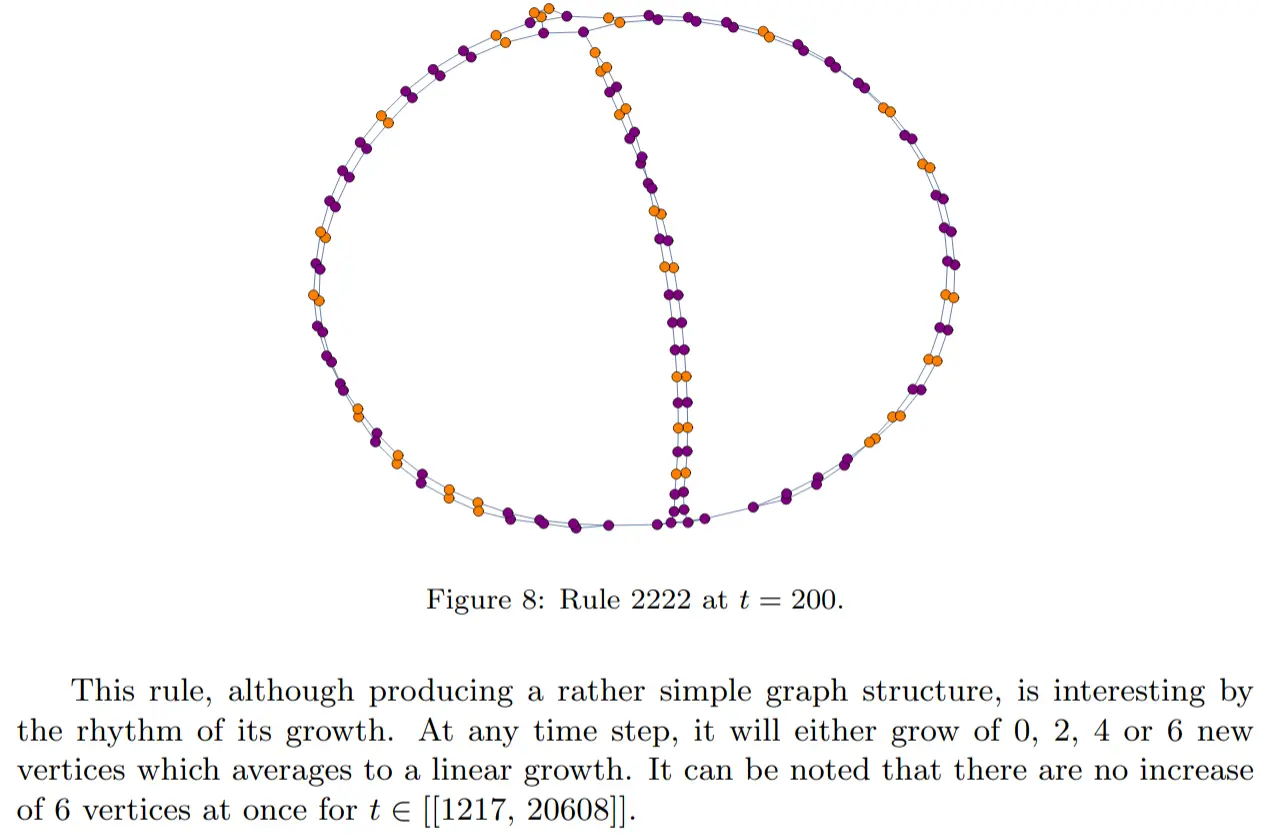
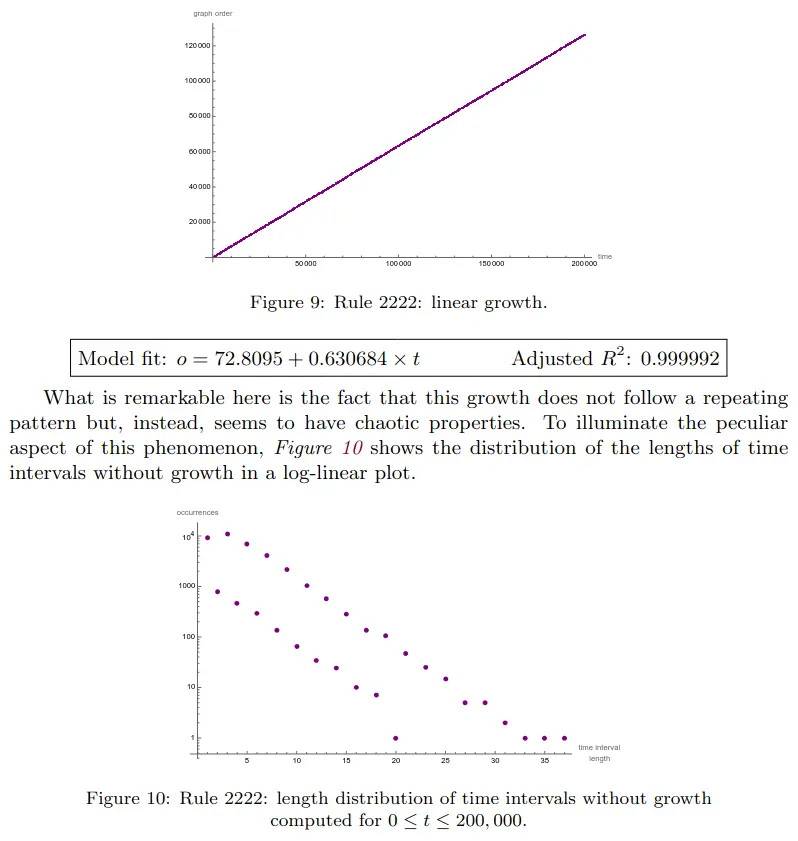
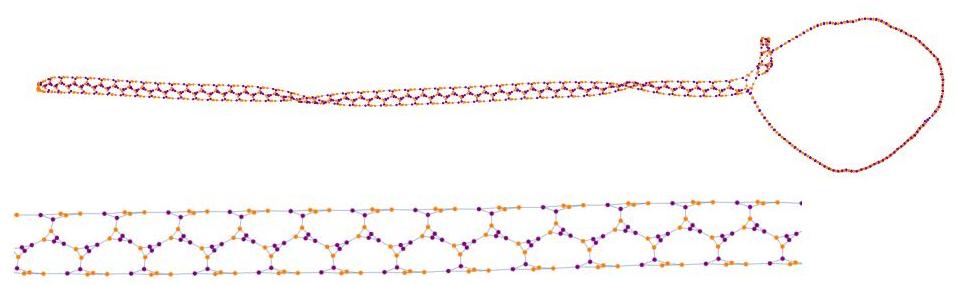
Rule 2222 – Chaotic linear growth
Linear growth
Rule 2183
(Quasi-)Quadratic growth ( 2.01874)
Exponential growth
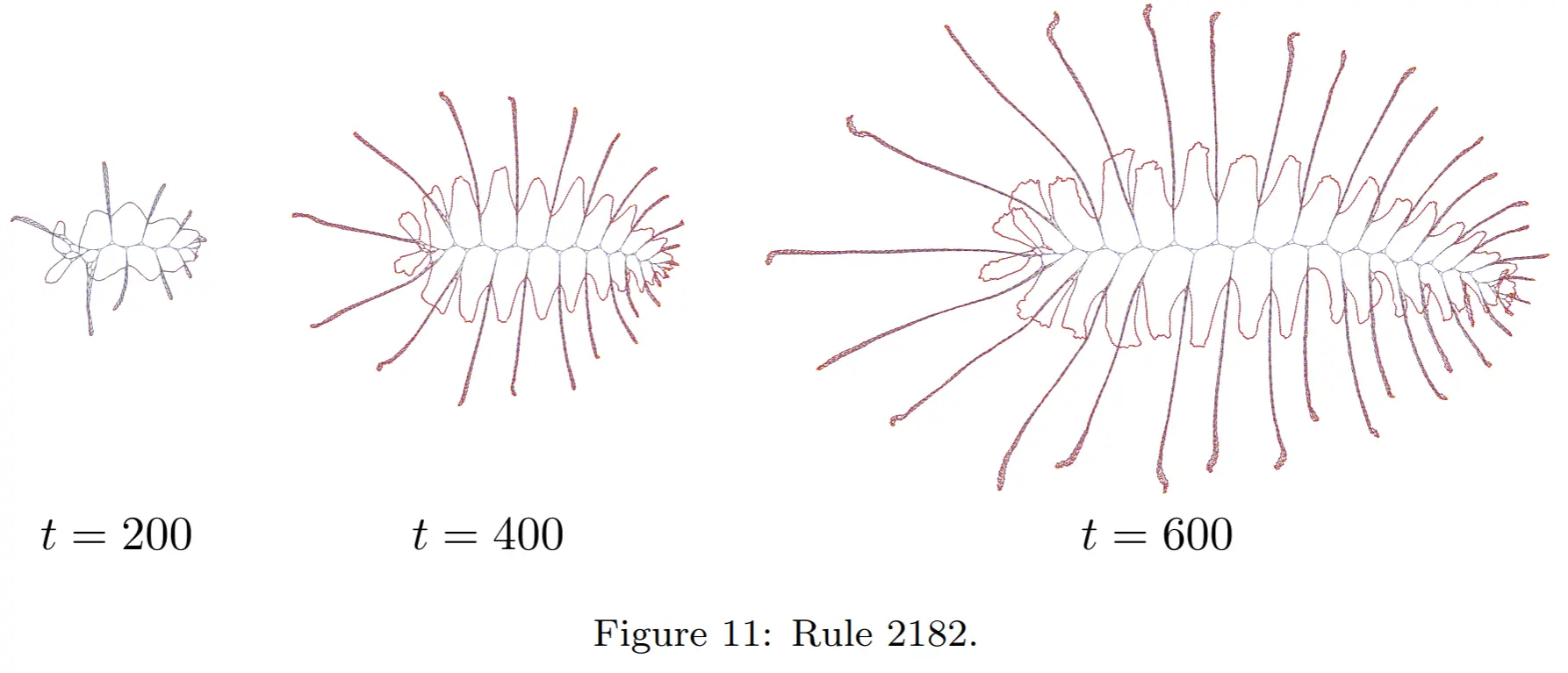
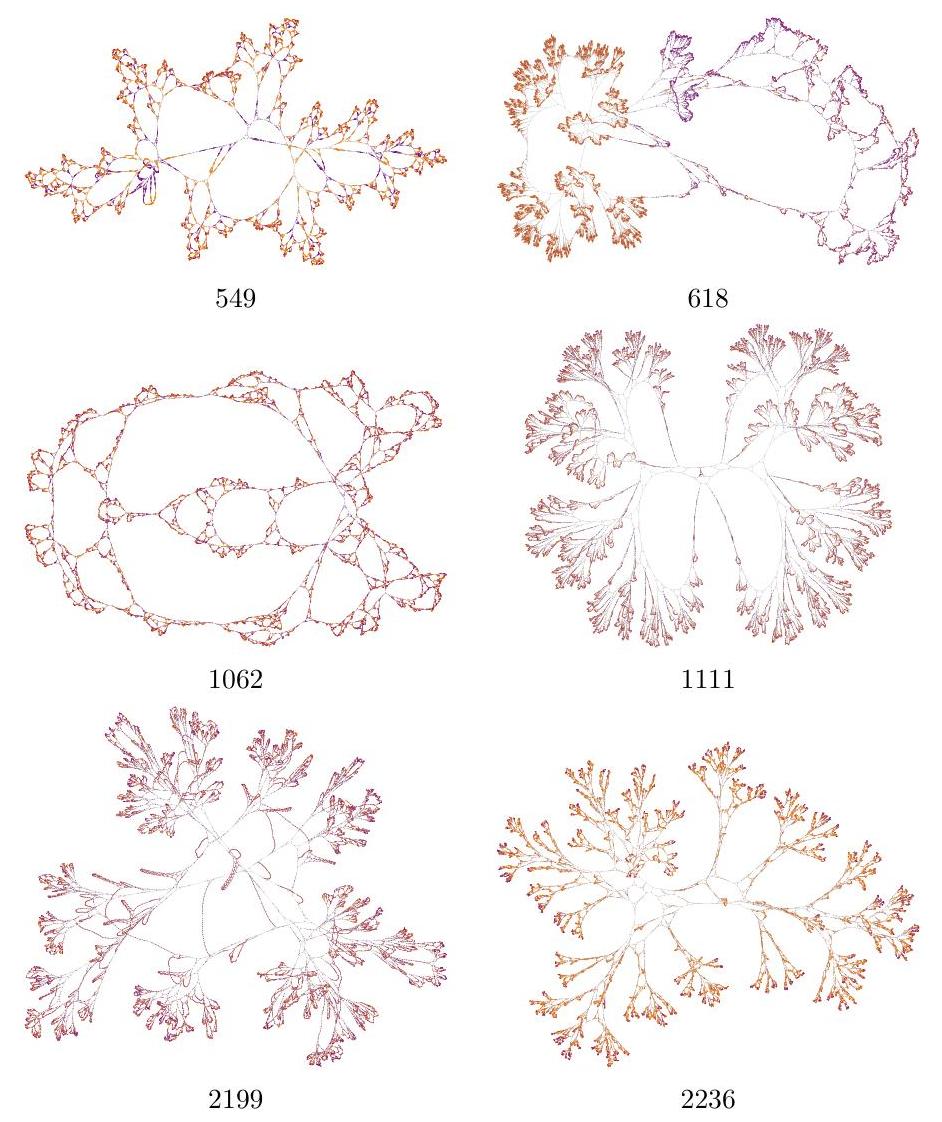
Unclassified; Selection of organic looking ones
Future work.
using continuous valued or non-binary discrete states (I suppose via function approximation)
working with d−regular (instead of just 3-regular) graphs
working with non-regular graphs (→ scale-free, small-world, etc.)
reaching an extended neighborhood with powers of A
working with directed graphs using AS and ATS
other topology altering operations (pruning, rewiring, …)