year: 2023
paper: https://www.nature.com/articles/s42256-023-00748-9
website: https://www.jachterberg.com/seRNN
code: https://github.com/8erberg/spatially-embedded-RNNe
connections: spatial organization, communicability, regularization, strength matrix, sparsity, biologically inspired
Conference Talk (25min + 25min discussion)
quickly look thru recent cites: https://scholar.google.com/scholar?oi=bibs&hl=en&cites=2466081976576789482&as_sdt=5
Regularization method based on spatial graph structure.
Structural prior / nudge towards communication: Prefer to keep those connections around that you use a lot to communicate.
Summary
Spatially-embedded Recurrent Neural Networks (seRNNs) link structural and functional neuroscience by simultaneously optimizing networks for task performance while constraining them to exist in 3D space with “metabolic costs.” This joint optimization causes diverse brain-like features—modularity, small-worldness, functional clustering, mixed selectivity, and energy efficiency —to emerge together in a “sweet spot” of the parameter space.
How seRNNs work
seRNNs add spatial regularization to RNN loss:
- … weight magnitudes (element-wise, like L1 regularization)
- … euclidian distance matrix between units (5×5×4 grid)
- … weighted communicability (LOW for core connections, HIGH for peripheral)
- … regularization strength
Minimizing prunes connections with large values in all three terms. The weighted communicability formulation assigns low values to core connections supporting efficient global paths and high values to redundant peripheral connections. Thus connections survive if they have small weight, short distance, or are part of the efficient communication backbone.
Structural finding: Higher modularity and small-worldness than L1 regularization:
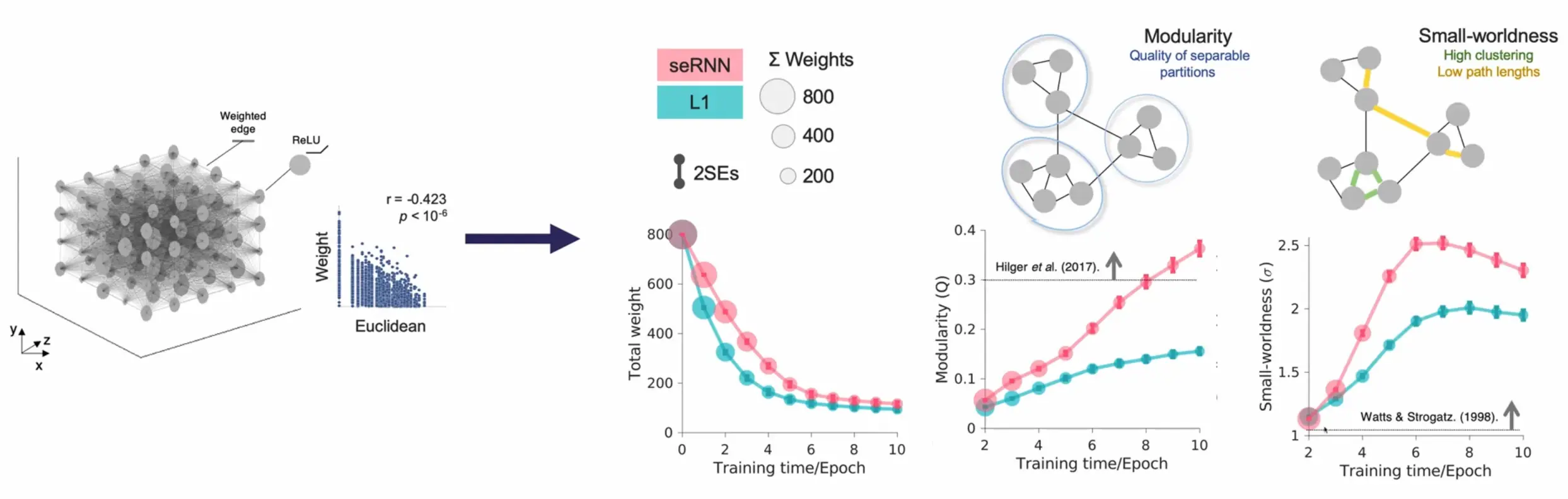
These features all arise in unison:
Brain features emerge from a single optimization process when trained with spatial and communication constraints:
Emergent brain-like properties
Structure:
- Modularity (Q ≈ 0.3-0.7): Dense within-module connections, sparse between-module connections
- Small-worldness: High clustering with short path lengths
- Homophilic wiring: Similar nodes preferentially connect (validated across macro/micro scales)
Function:
- Functional clustering: Persistent info (goals) clusters spatially; transient info (choices) distributes
- Mixed selectivity: Units respond to multiple variables (vs pure selectivity in L1 networks)
- Energy efficiency: Lower neural activity for same performance
These co-emerge from the same optimization pressure—networks can’t achieve modularity without small-worldness.
The spatial organization creates a division of labor in this navigation-like task: a spatially clustered “core” maintains the goal location (which must be remembered throughout the trial), while distributed units process the choice directions (which only appear later and need immediate processing). The network’s physical structure literally determines its computational strategy—persistent information clusters, transient information distributes.
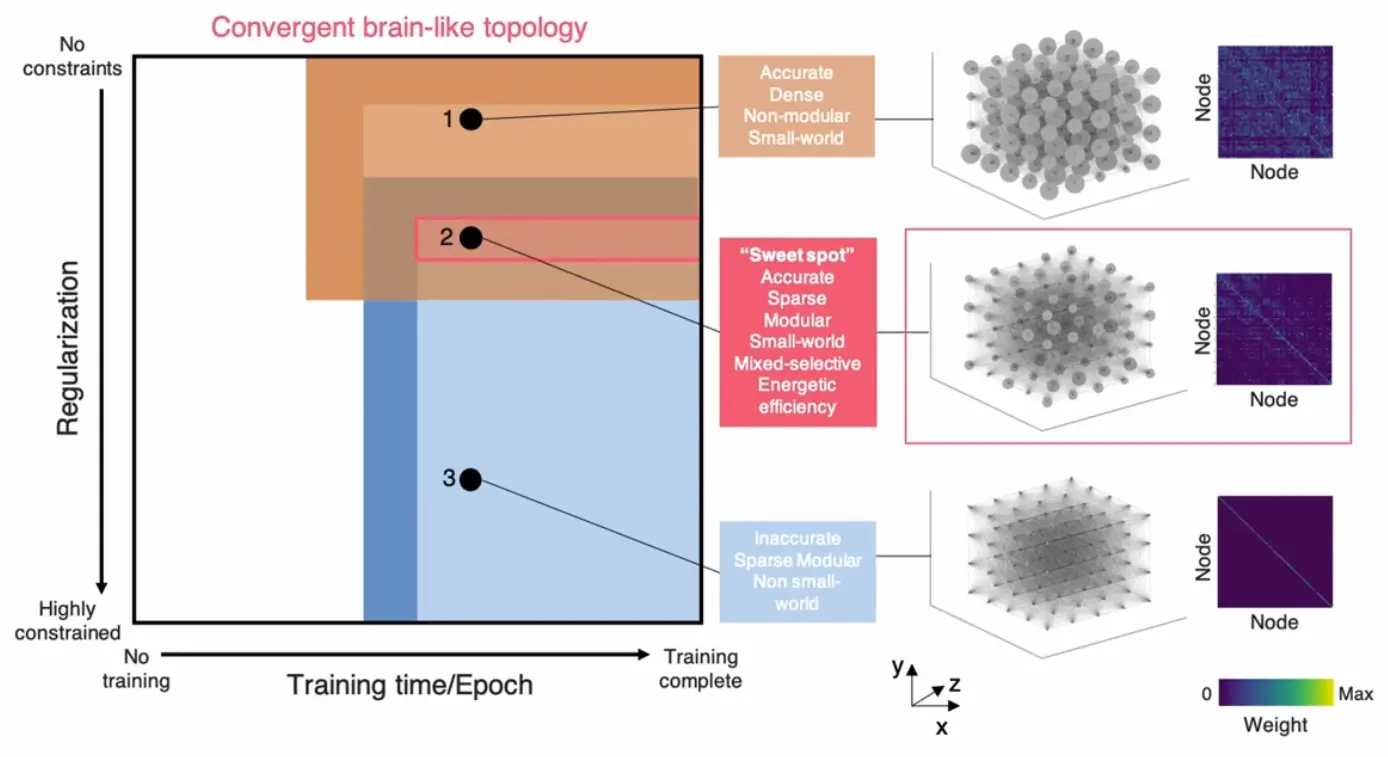
The "sweet spot" phenomenon
Brain-like features only coexist within a critical parameter window (). Networks are simultaneously:
- Task-accurate
- Sparse but connected
- Modular and small-world
- Mixed-selective
- Energy-efficient
Outside this range: too sparse → task failure; too dense → no modularity. Physical constraints dictate this unique viable solution.
Note
Dense networks (weak regularization) preferentially maintain goal information.
Sparse networks (strong regularization) focus on current choice inputs.
Experimental Details
The study compared 1000 seRNNs against 1000 standard L1-regularized RNNs, all with 100 hidden units. Networks were trained on a simple but cognitively demanding task:
Goal presentation (20 steps): Show a location on a 2×2 grid
Delay period (10 steps): No input, must maintain goal in memory
Choice presentation (20 steps): Show two directional options (e.g., “left” and “right” arrows) simultaneously. The network processes these inputs over 20 time steps, integrating them with the remembered goal location
Decision: After step 50, read out which direction the network chooses. Correct choice moves toward the remembered goal
This task requires two fundamental cognitive abilities: working memory (maintaining the goal) and integration (combining remembered information with new sensory input). Despite its simplicity, it captures the essence of many real-world cognitive tasks.
Networks started fully connected and learned through weight pruning. The key innovation was comparing networks matched for overall sparsity but differing in how they achieved it—seRNNs through spatial/communication constraints versus L1 through simple weight minimization.
Weighted communicability
quantifies information flow through all paths (exponentially weighted by length). Degree normalization prevents hub dominance. Implements small-world prior by favoring short communication paths.
Modularity measure
The modularity compares actual connections to what you’d expect by chance:
- = actual connection between nodes i and j
- = expected connection probability if wiring was random (where is node i’s degree, is total connections)
- = 1 if nodes are in same module, 0 otherwise
Q > 0 means more within-module connections than random. Q ≈ 0.3-0.7 is typical for real brain networks.
Modules are discovered algorithmically by finding node groupings that maximize Q.