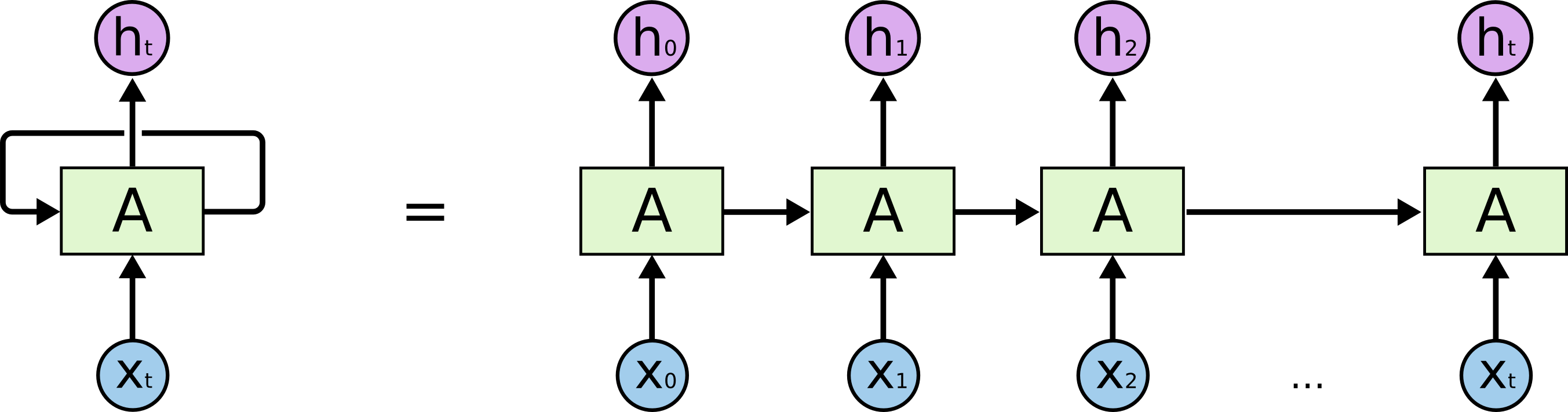
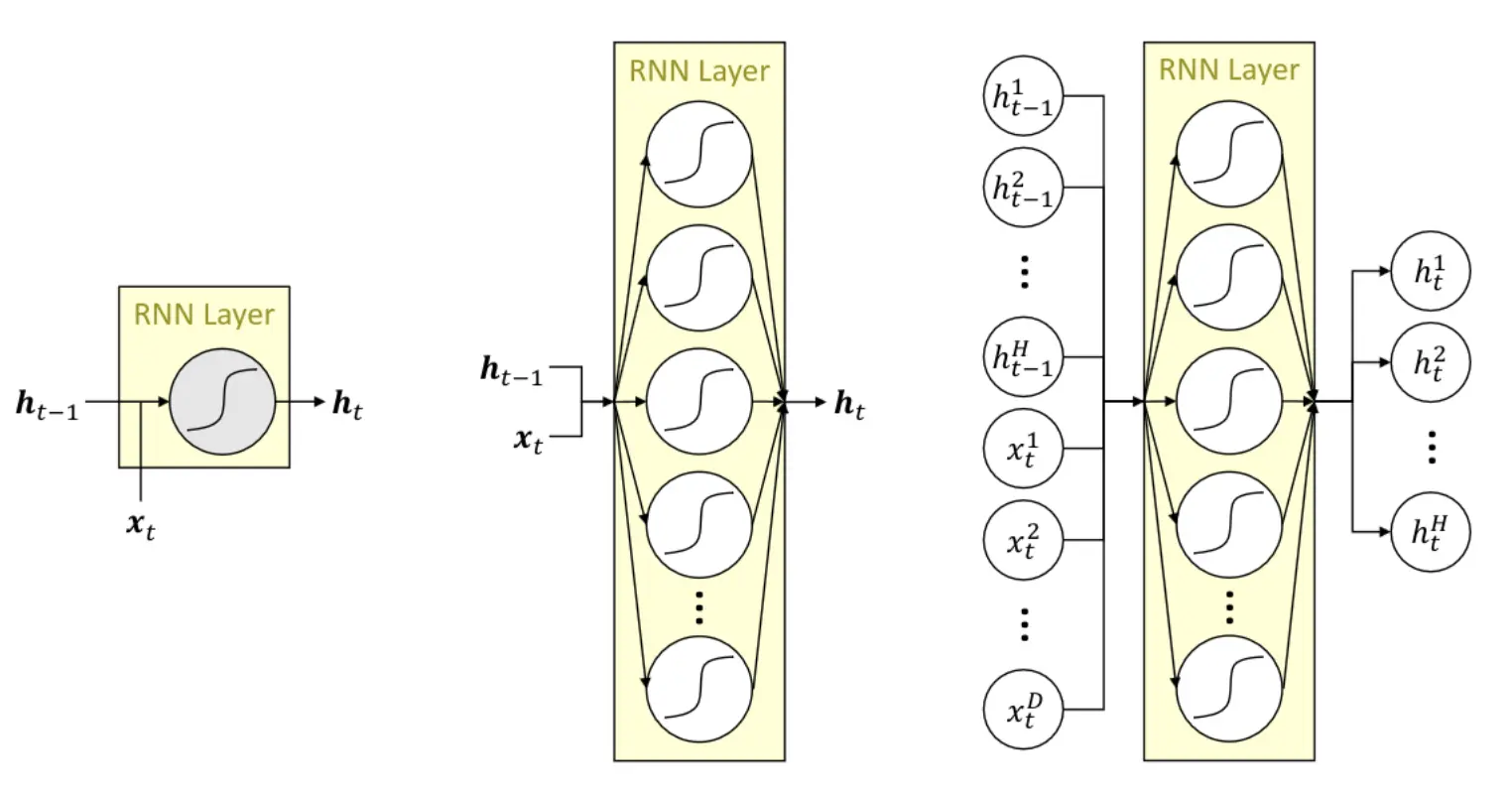
RNNs are feedforward networks with shared weights
RNNs are turing complete / can represent anything theoretically (with sufficient memory)
… the hard problem is finding a good representation
Memory footprint and sequential training nature
RNN have constant memory during inference, since previous hidden states/memories are not needed, so you only need all context tokens once at a time. (memory: ).
However, this means that you cannot explicitly mention any single previous Token out of the memory, which is a major limitation of RNNs compared to transformer. Sometimes you can’t compress all the information into a single hidden state like that. Also, this leads to vanishing gradient (due to Backrop through time). 1Due to the sequential stepping through time, RNNs can’t be trained in a parallel manner.
In contrast, with a Transformer and its causal attention mask, you can train examples in parallel (which is also different contexts/examples, but in the RNN you always depend on the previous ones).
vanishing gradients
repeated multiplication
gradients of earlier timesteps vanish, doesnt keep it in memory
→ LSTM
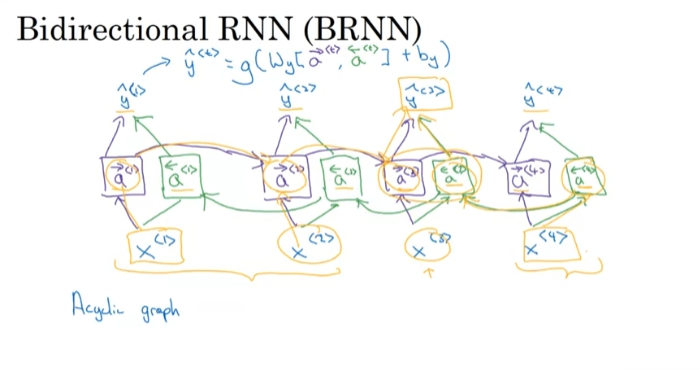
Bi-directional RNN (BRNN) Andrew Ng Lesson
(Allows an RNN to processs an input sequence not only sequentially, but also know stuff about the end of the sequence for calculating the weight for the beginning of the sequence)
References
Footnotes
-
Mentioned in YK RMKV PaperReview ↩