read DeepSeek-V2
stores a low-rank projection of the attention block input and compute the KV from it (reduces KV size)
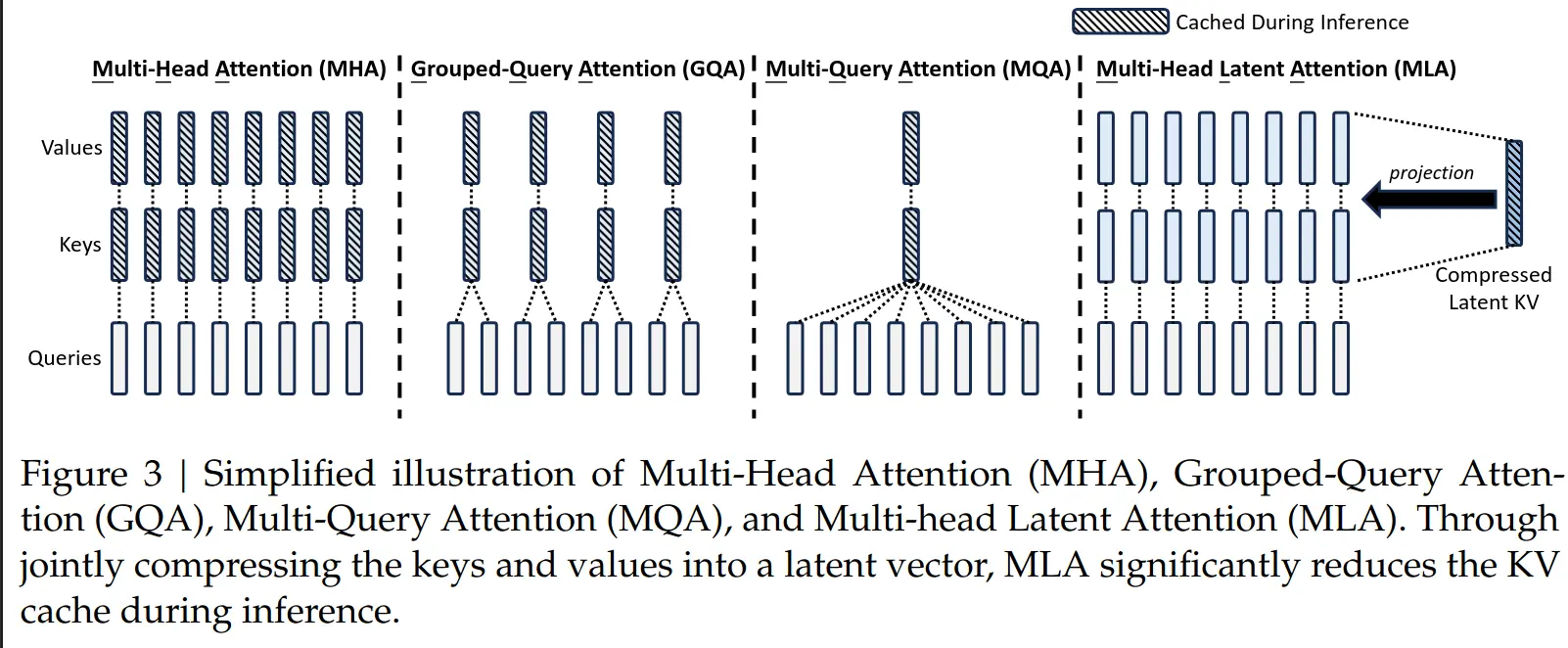
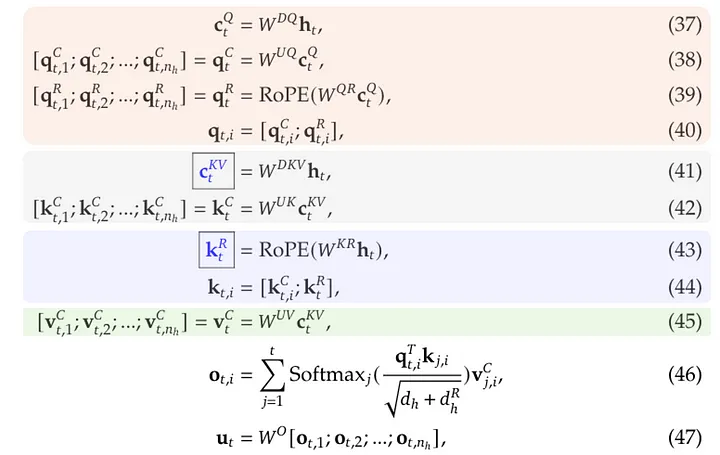
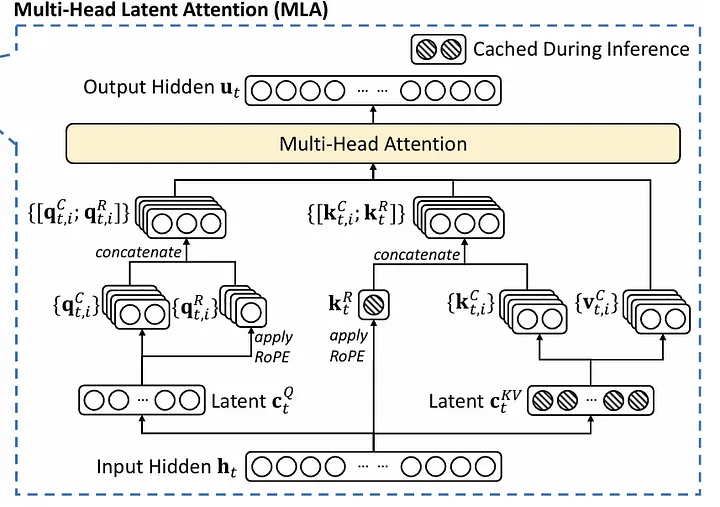
(actually improves on perf)
read DeepSeek-V2
stores a low-rank projection of the attention block input and compute the KV from it (reduces KV size)
(actually improves on perf)