A really fancy visualization: https://poloclub.github.io/transformer-explainer/
TOC:
High level facsts
The transformer is actually a graph neural network processor.
(… pretty much everything is nowadays)
The native representation that the transformer operates on is sets that are connected by edges, in a directed way.
This frees neural net computation form the burden of euclidian space.
Previously you had to conform your compute to a 3D layout, in attention it’s just sets. See also: ^c1f58f.
This message-passing architecture (see ^159181 for an explanation) is general (complete) and powerful (efficient), able to cover many real-world algorithms in a small number of compute steps.
Limitation: Can’t draft / edit.
The autoregressive sampling - sampling a token and then commiting to it - that is used in decoder-only transformers is one of the biggest weaknesses.
Maybe we might find hybrids with diffusion or some other way to incorporate editing into the autoregressive process.
The transformer is super flexibly: Information can easily be plugged in.
Just chop the data into pieces, add it into the mix, self-attend over everything.
Even if it doesn’t make much sense / has zero inductive bias or whatsoever, e.g. with ViT or whisper (any audiotransfomer, e.g. “Conformer”), where you literally just chop up images or audio spectrograms and feed them into the transformer. Or the decision transformer, where you put states, actions, rewards into the transformer, pretend it is language and model the sequence of that.
The transformer is like a computer optimizable by gradient descent.
The shallow architecture of the transformer allows it to run very efficiently on GPUs.
This is in contrast to RNNs, which have a very long, thin compute graph. Apart from paralellization, this also complicates the flow of gradients, where it’s better to have fewer steps.
Link to originalThe transformer has a very minimal inductive bias.
In the core transformer inductive biases are mostly factored out. Self-attention is a very minimal (and verry useful) inductive bias, with a most general connectivity, where everything attends to everything..
Without positional encodings, there is no notion of space.
If you want to have a notion of space, or other constraints, you need to specifically add them.
Positional encodings, for example, are a type of inductive bias, same as for example the Swin Transformer, where you limit the attention node-connectivity to local windows, somewhat like the biologically inspired inductive bias of CNNs.
Causal attention is another example of an inductive bias, where tokens can only attend to previous tokens in the sequence.
Transformer == MPNN
NOTE: the thing in the middle is NOT the “GAT” (but a scaled-dot-product form of graph attention, which GAT doesnt use, and which is actually weaker than GATv2). And the “standard GNN” is a MPNN, specifically.
Point is: Standard transformers/LLMs perform message passing on complete graphs of tokens, with SDP attn as the aggregation.
Source 1 2
Transformers and The Bitter Lesson (from The Bittersweet Lesson)
→ If it’s possible for a human domain expert to discover from the data the basis of a useful inductive bias, it should be obvious for your model to learn about it too, so no need for an inductive bias.
→ Instead focus on building biases that improve either scale, learning or search .
→ In the case of sequence models, any bias towards short-term dependency is needless, and may inhibit learning (about long-term dependency).
→ Skip connections are good because they promote learning.
→ MHSA is good because it enables the Transformer to (learn to) perform an online, feed-forward, parallel ‘search’ over possible interpretations of a sequence.
Inner workings / Components
Task
The transformer accepts a set of observations , ( could be a word embedding, image patch, …), and aims to predict missing elements of that set (usually).
The missing elements could be in the future, i.e (e.g. in autoregressive language modelling), or could be a missing part of a sentence or image, i.e. .
At the core of the transformer is the self-attention mechanism, which often is augmented by using multiple heads: multi-head attention.
Before feeding into self-attention, we often project input to a lower dimension (dimensionality reduction) e.g. using learned word embeddings.
The transformer learns the patterns in this embedding space (where similar are grouped together → similar vectors will be treated similarly).
Padding tokens are added so that the input retains a constant shape of the maximum sequence length.
### finish refactor
Modifications to the original that prevailed
Performance-centered:
- PreNorm
- RMS norm
- ROPE
- cosine learning schedule
- AdamW
- multi-token prediction
Efficiency/Speed centered:
Hyperparameters
### finish refactor
The output from self-attention is then passed through a deep network , typically consisting of residual connections and layer normalization (nowadays PreNorm). This output can then be used for prediction, or
sent through subsequent transformer blocks.
At the end of the transformer blocks in the original paper, they put a “de-embedding” matrix, the same shape as the embedding matrix, but with the number of rows and columns flipped, on which softmax is applied to get probabilities for the next token:
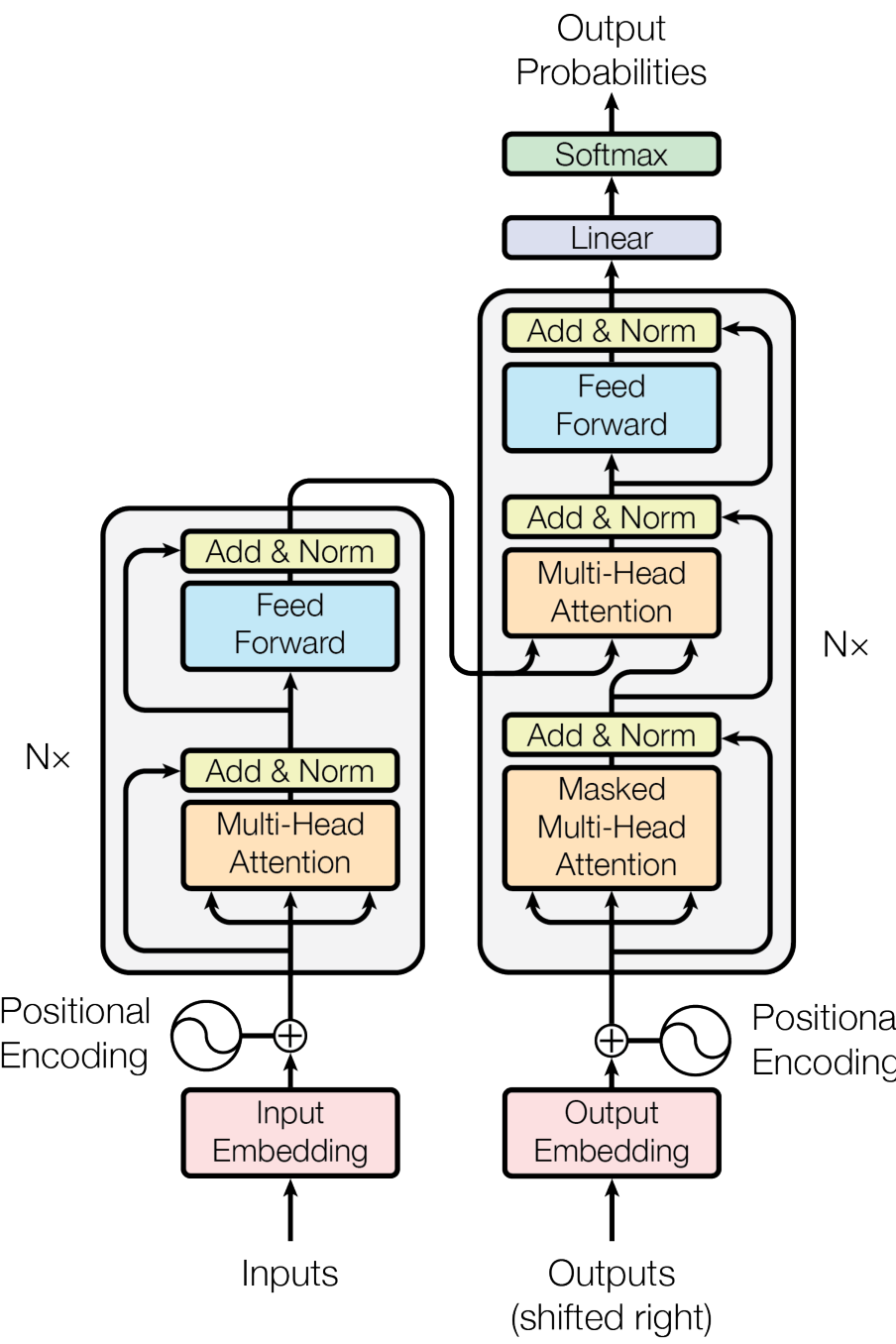
Encoder
![]()
- A stack of identical layers. (in the original paper)
- Each layer has a multi-head attention layer and a simple position-wise fully connected feed-forward network (linear).
- Each head 64 dimensional (as standard)
- The MLP adds extra complexity / ability for post-process new information and prepare for next block.
- usually inner dimensionality of MLP is 2-8 x larger than (dimensionality of original input ), 4x in paper.
- wider layer → faster, parallelizable execution.
- After* both, layer normalization is applied. (Faster training, small regularization, features of simmilar magnitude among elements in a sequence)
- No BatchNorm, esp. because small batches in Transformers (require lot of GPU RAM)
- BatchNorm performs particularly bad in language: Many very rare words which are important for a good distribution estimate → high variance
-
- Applied after MHA and FFN in original paper, but directly on the inputs before going into them is more common now, see summary below (src: Karpathy explains).
- Lastly, both adopt a residual connection
- Crucial for smooth gradient flow through the model (some models contain more than 24 stacked blocks)
- Without it, positinal information would be lost (MHA ignores position).
All the sub-layers () output data of the same dimension.
Overall it calculates (original paper):
newer version:
cross-attention - Encoder Decoder Intuition
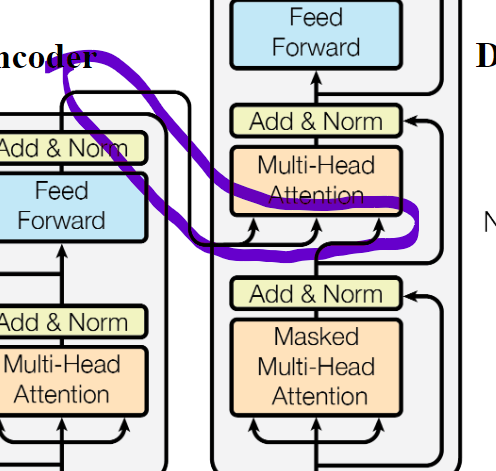
In the original task of the paper, translation, the encoder gets shown the e.g. french sentence.
It is not masked so all tokens (words) can talk to eachother as much as they want (to “get the meaning of the sentence”).
The keys and values of the encoder are input to the second MHA of the decoder (all blocks), so essentially, the decoder has the information of the past english tokens and the information of the fully encoded french sentence.
Decoder TODO
positional encodings
Fixed values added to input in order to keep positional information. (Residual connections needed aswell)
Essentially like adding binary counting vectors to the input, but with continous values.
Properties / Limitations
Shape size intuition (TODO … refactor this)
voc … vocabulary size | multiple (tens) of thousands
seqL … sequence length | 2048 in GPT3
d_model … number of hidden dimensions in embedding space throughout model | 512 in Vaswani
(voc x d_model) ← word embedding; positional embedding
Time and space complexity
Memory requirement for transformersscales quadratically with evry Token added, since every Token attends to every other Token, like in a fully meshed topology:
( … Tokens form connections with every other except itself, division removes duplicates)
| Time | Space | |
|---|---|---|
| Transformer | ||
| RWKV | ||
| … embedding dimension (constant) | ||
| (RWKV - Reinventing RNNs for the Transformer Era) |
Variations and Sucessors
Improvements
The only fundamental change to the architecture throughout the years has been swapping the order of the layernorm:
Transclude of PreNorm#^ref
Variations
ViT
Transformer with memory (lucidrains)
GPT
Music Transformer: Generating Music with Long-Term Structure Paper
{kind=link}
Code
References
Best one:
→ Stanford CS25: V2 I Introduction to Transformers w/ Andrej Karpathy ←
Super good first intuition (and walkthrough all components) Assembly AI Transformers for beginners
In-depth tensorflow article / colab
Goated Karpathy GPT walkthrough .
Illustrated Transformer
CodeEmporium entire encoder ; Self-Attention with nice experimenting code; … | Video: Tutorial(uses einops)
Annotated Transformer (With Attention visualization, full code)
Youtube: Sentence Tokenization in Transformer Code from scratch - Code Emporium
Theory from scratch (e2eml) (a bit dry and long and not practical)
Relating transformers to models and neural representations of the hippocampal formation