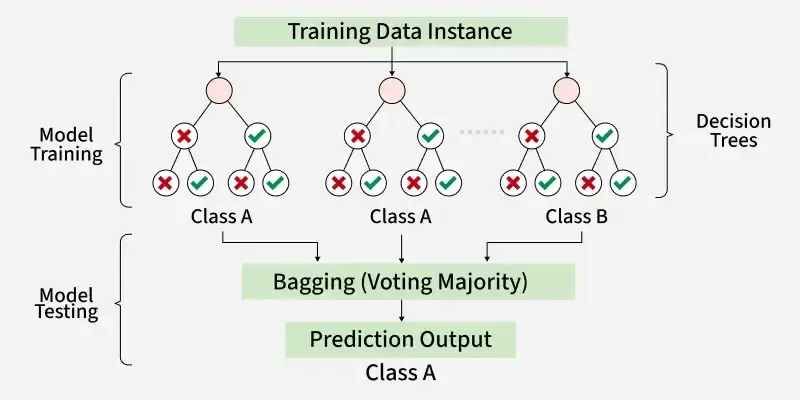
Random Forest
An ensemble of decision trees, each trained on a random subset of data and features.
Predictions are aggregated by majority vote (classification) or averaging (regression).Two sources of randomness decorrelate the trees:
Individual trees are intentionally deep/overfit (high variance, low bias). But because the randomization makes their errors uncorrelated, averaging reduces variance without increasing bias.
Why decorrelation matters
If trees each have variance and pairwise correlation , the ensemble variance is:
The second term vanishes as , but the first doesn’t. Feature subsampling reduces —this is why random forests outperform simple bagging (which only uses bootstrap sampling).
Practical notes
More trees always helps (or plateaus)—unlike many hyperparameters, there’s no overfitting risk from adding trees, just computational cost.
Feature importance: Measure the increase in prediction error when a feature’s values are randomly permuted. Features the forest relies on show large error increases.
Out-of-bag error: Since each tree only sees ~63% of samples (due to bootstrap), the remaining samples provide a free validation set for that tree.
Footnotes
-
BAGGING = Bootstrap AGGregatING but it also results in multisets since samples can be repeated. ↩