Only the organge parts get (re)computed when is added:
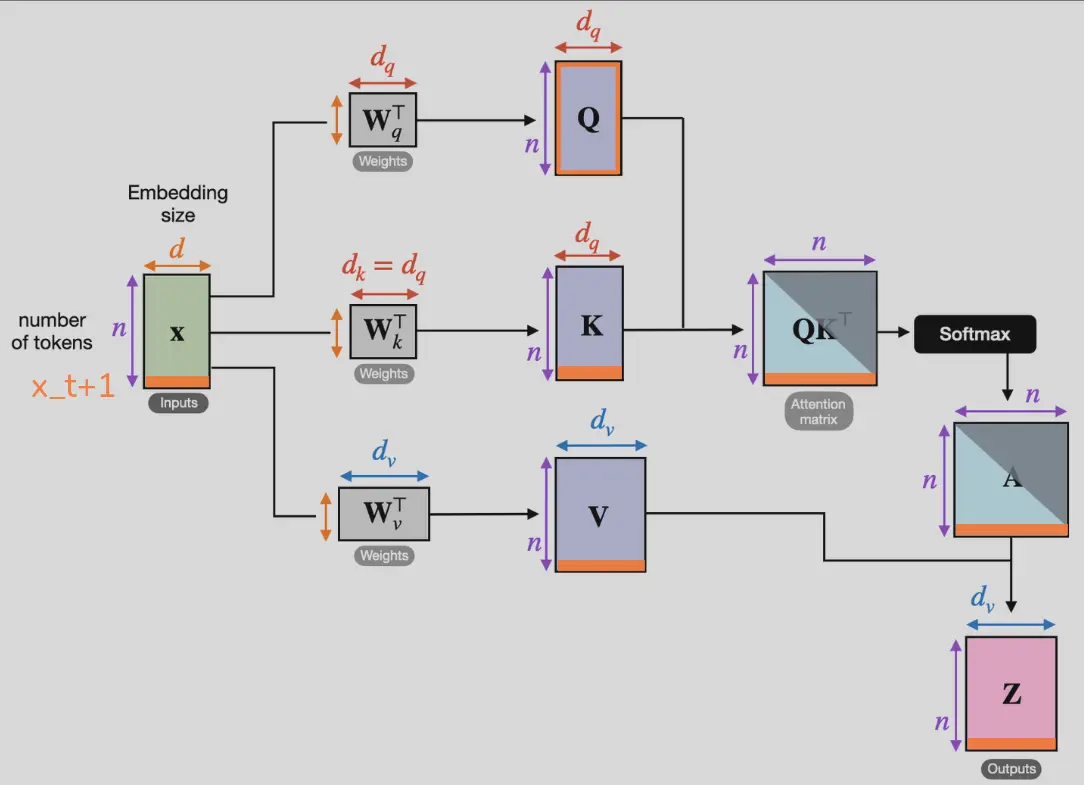
This only works for causal attention, i.e. where each cached pair is invariant to future tokens:
If adding a new token also changes the previous keys and values, then the whole cache needs to be recomputed (as in full-/encoder-self-attention).
Animated: https://huggingface.co/blog/not-lain/kv-caching
Link to originalCausal attention is used for efficiency, as you can use a single training sequence and train it simultaneously, as
len(train_seq)number examples.
However, this restricts the early tokens during inference to also only ever look backwards. So all the computed attention of the previous tokens stays constant!
→ You can cache all of the previously computed values.This breaks down however as soon as you run out of context length, as the past is now different and the cached computations / relations become invalid. So you have to re-compute the entire attention matrix every single new step (like you have to with unmasked attention).
If we were to keep the cache, the 2nd token still sees the first (has some info abt it at least) if we make a step outside the context length, the newest one only sees the 2nd though. This (window) approach does not work in practice without re-computation or attention sinks:
Transclude of Efficient-Streaming-Language-Models-with-Attention-Sinks#^2b5e75