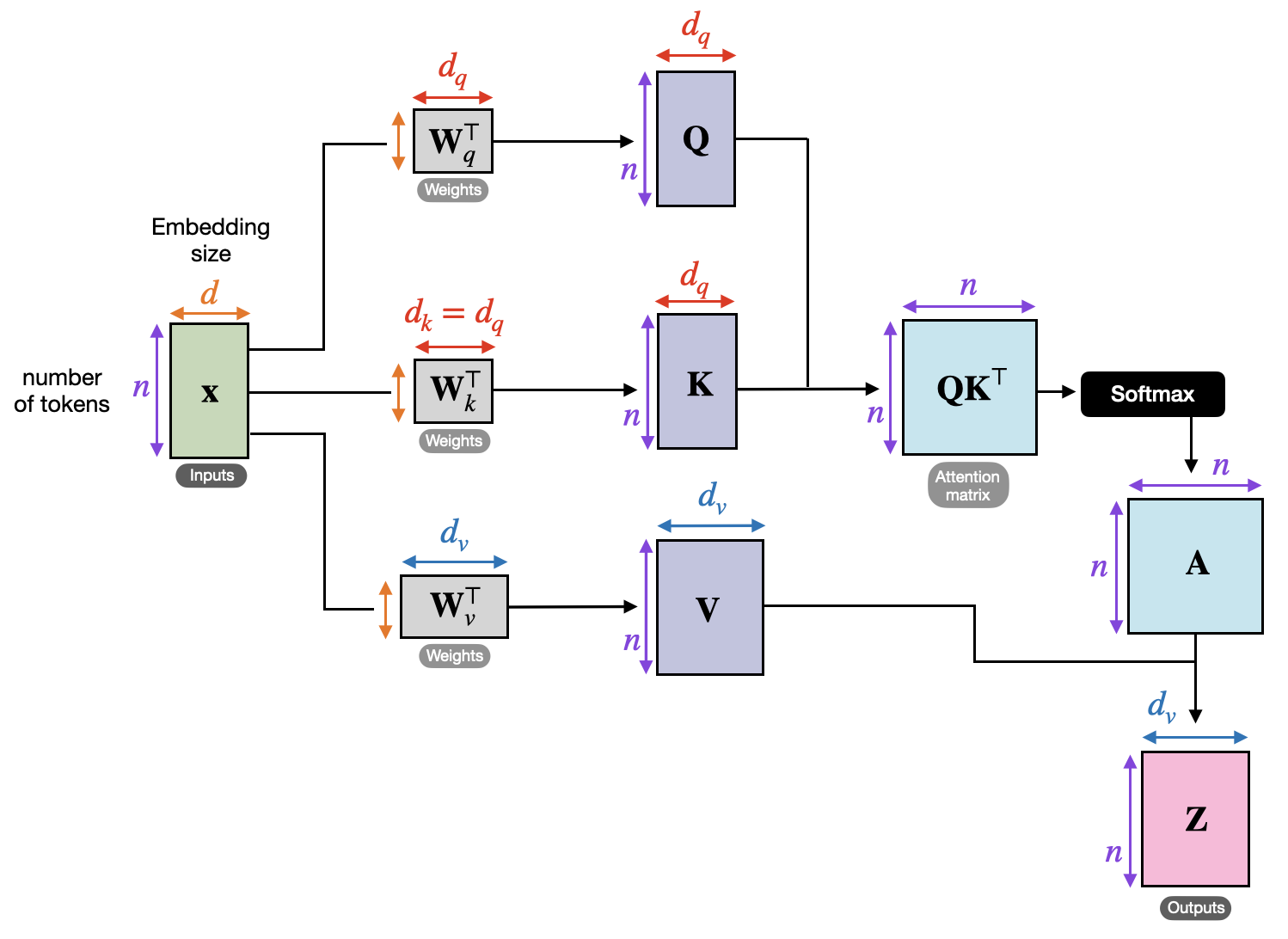
The transformer accepts a set of observations X={x1,x2,…,xT}∈RT×d, (xt could be a word embedding, image patch, …). n is the number of tokens and d is the embedding dimension of each token.
To attend to another, each token xt∈R1×d (a row vector) emits a queryqt=xtWq (qt∈R1×dq,Wq∈Rd×dq) and compares it to the keys of other tokens kτ=xτWk (kτ∈R1×dq,Wk∈Rd×dq), in order to decide what weight to assign to their valuesvτ=xτWv (vτ∈R1×dv,Wv∈Rd×dv):
zt=τ∑Tκ(qt,kτ)vτ
Here, κ(qt,kτ)→R is the similarity measure of qt to kτ.
The resulting output values zt∈R1×dv are a weighted sum of the values that each token encodes. Tokens with large κ(qt,kτ) contribute more to the output zt.
Typically, the similarity measure is the cosine similarity. Combined with a scaling factor and softmax, we get the standard scaled dot product attentiondkqt⋅K∈R1×T.
There are also other variants which remove softmax, e.g. forms of linear attention.
These equations can be succinctly expressed in matrix form, with all elements updated simultaneously:
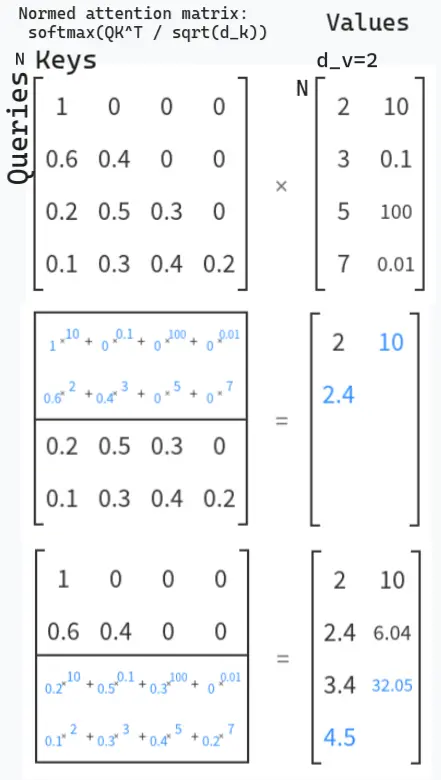
zt=softmax(dkqtKT)V→Z=softmax(dkQKT)V
Here, Q∈RT×dq, K∈RT×dq, and V∈RT×dv are matrices with rows filled by qt, kt, and vt, respectively.
The softmax is taken independently for each row (normalizing over the keys dimension). This creates a probability distribution over which nodes to attend to - ensuring attention weights sum to 1 for each query. Without this normalization, attention weights could explode/vanish and lose their “relative importance” interpretation.
The result of the QKT operation is also called the attention matrix.
QKV?
We project the input nodes to Q,K,V, in order to give the scoring mechanism more expressivity: What you pay attention to and what you extract from it can be different.
In principle we could do without them, see message passing.
Q: Here is what I’m interested in (like text in a search bar).
K: Here is what I have (like titles, description, etc.).
V: Here is what I will communicate to you (actual content, filtered / refined by value head).
For every query, all values are added in a weighted sum, weighted by similarity between that query and the keys.
Attention matrix: queries = rows, keys = columns.
Self-attention?
What makes it Self- attention is, that the K, Q and V are all coming from the same sourcex, the input.
Keys and Values can also come from an entirely seperate source / nodes: cross-attention.
NOTE: Before self-attention became synonymous with “QKV scaled dot-product attention”, it just meant “a set attends to itself” (e.g. GAT, which does not use QKV but still calls it “masked self-attention”)
The qk - and v if it is the same size - dim is sometimes referred to as “head size”, esp. in the context of MHA.
Attention is a communication mechanism / message passing scheme between nodes.
Attention in principle be applied to any arbitrary directed graph.
Attention can be thought of as a message passing scheme.
Every node (token) has some vector of information (R1×d) at each point in time (data-dependent) and it gets to aggregate information via a weighted sum from all the nodes that point to it.
Imagine looping through each node:
The query - representing what this node is looking for - gathers the keys of all edges that are input to this node and then calculates the the unnormalized “interestingness” of information / compatibilities with other nodes by taking the dot-product between the keys and the queries.
We then normalize these scores and multiply them with the value of the input nodes.
This happens in every head in parallel, and every layer in sequence, with different weights (in both cases).
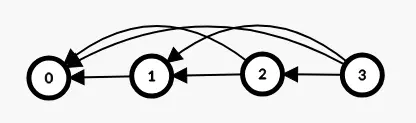
The attention graph of encoder-transformers is fully connected.
The attention graph of the decoder is fully connected to the encoder values, and tokens are fully connected to every token that came before them (triangular attention matrix structure).
Graph of autoregressive attention (self-loops are missing from the illustration):
Attention acts over a set of vectors in a graph: There is no notion of space.
Nodes have no notion of space, e.g. where they are relative to another.
This is why we need to encode them positionally:
The transformer has a very minimal inductive bias.
In the core transformer inductive biases are mostly factored out. Self-attention is a very minimal (and verry useful) inductive bias, with a most general connectivity, where everything attends to everything..
Without positional encodings, there is no notion of space. If you want to have a notion of space, or other constraints, you need to specifically add them. Positional encodings, for example, are a type of inductive bias, same as for example the Swin Transformer, where you limit the attention node-connectivity to local windows, somewhat like the biologically inspired inductive bias of CNNs. Causal attention is another example of an inductive bias, where tokens can only attend to previous tokens in the sequence.
→ If it’s possible for a human domain expert to discover from the data the basis of a useful inductive bias, it should be obvious for your model to learn about it too, so no need for an inductive bias.
→ Instead focus on building biases that improve either scale, learning or search .
→ In the case of sequence models, any bias towards short-term dependency is needless, and may inhibit learning (about long-term dependency).
→ Skip connections are good because they promote learning.
→ MHSA is good because it enables the Transformer to (learn to) perform an online, feed-forward, parallel ‘search’ over possible interpretations of a sequence.
Computing an attention matrix as A=XXT from the raw token features produces a gram matrix. This already captures associations/relational structure between tokens, but since there are no free (learnable) parameters,, it isn’t suitable for tasks beyond simple association.
Learnable Wq,Wk∈Rdemb,dqk matrices are introduced, projecting the raw features into a new space, where A is more meaningful for the task at hand.
These weight matrices can be seen as the small genotype encoding the much larger phenotype attention matrix:
When we scale number of learnable parameters while the input dimension is held constant, the free parameters scale with O(dqk), while A grows with O(n2), and typically, n2≫dqk, where n are the number of input tokens.
In a self-attention head, a query retrieves content by matching against keys and mixing the corresponding values → content-addressable recall aka associative memory in a differentiable key-value memory.
The hamiltonian of the Hopfield Network is identical to the ising model, except that the interaction strength is not constant, and very similar to attention!
For a hopfield network:
H=−i=j∑Wijsisj
W=XiTXj is the weight / interaction matrix, which encodes how patterns are stored, rather than being a simple interaction constant.
In a simplified form, the update rule of the HFN is:
Tokens in self-attention are just like spins in the ising model, but instead of spins, they are vectors in higher dimensional space, with all to all communication, self-organizing to compute the final representation.