year: 2024/07
paper: https://arxiv.org/pdf/2407.04153
website:
code:
connections: mixture of experts, scaling laws, product keys
Motivation
…increasing the number of experts is an effective way to improve performance without increasing the inference cost. However, their experiments showed that the efficiency gains provided by MoEs plateau after a certain model size is reached.
More recently, Krajewski et al. (2024) discovered that this plateau was caused by using a fixed number of training tokens. When the number of training tokens is compute-optimal, MoEs consistently outperform dense models in terms of FLOP efficiency. Moreover, they introduced granularity (the number of active experts) as a new scaling axis and empirically showed that using higher granularity improves performance. Extrapolating this fine-grained MoE scaling law suggests that continued improvement of model capacity will ultimately lead to a large model with high granularity, corresponding to an architecture of an immense number of tiny experts.Beyond efficient scaling, another reason to have a vast number of experts is lifelong learning, where MoE has emerged as a promising approach. For instance, Chen et al. (2023) showed that, by simply adding new experts and regularizing them properly, MoE models can adapt to continuous data streams. Freezing old experts and updating only new ones prevents catastrophic forgetting and maintains plasticity by design. In lifelong learning settings, the data stream can be indefinitely long or never-ending (Mitchell et al., 2018), necessitating an expanding pool of experts..
Totally not inefficient, lol.
Results
This design is supported by the recent discovery of the fine-grained MoE scaling law. To overcome the computational overhead of routing to a large number of experts, we apply the product keys to efficiently select a small subset of hidden neurons within a wide MLP layer. Empirical analysis using language modeling tasks demonstrate that given the same compute budget, PEER significantly outperforms dense transformers, coarse-grained MoEs and product key memory layers.
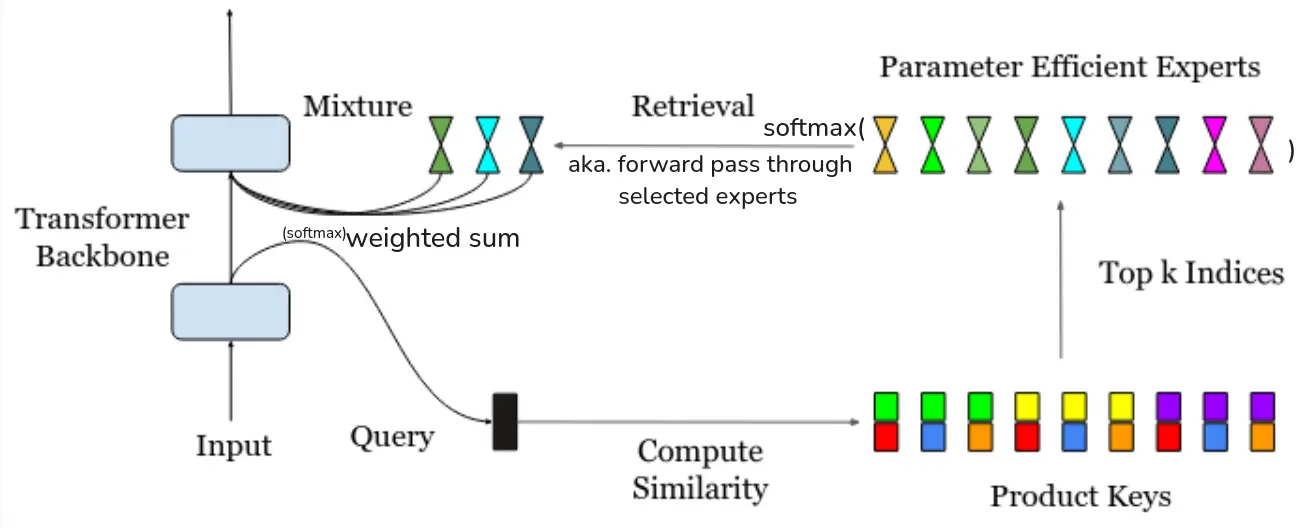
… get the top-K out of experts by taking the dot-product between their product keys with the query vector from the input vector .
… then take the softmax or sigmoid to those similarities, giving us the router scores (ofc we don’t recompute anything).
… expert outputs are then aggregated via a weighted sum.
Problem: Large number of experts, each with a -dim key, computing every product takes , very slow.
Solution:
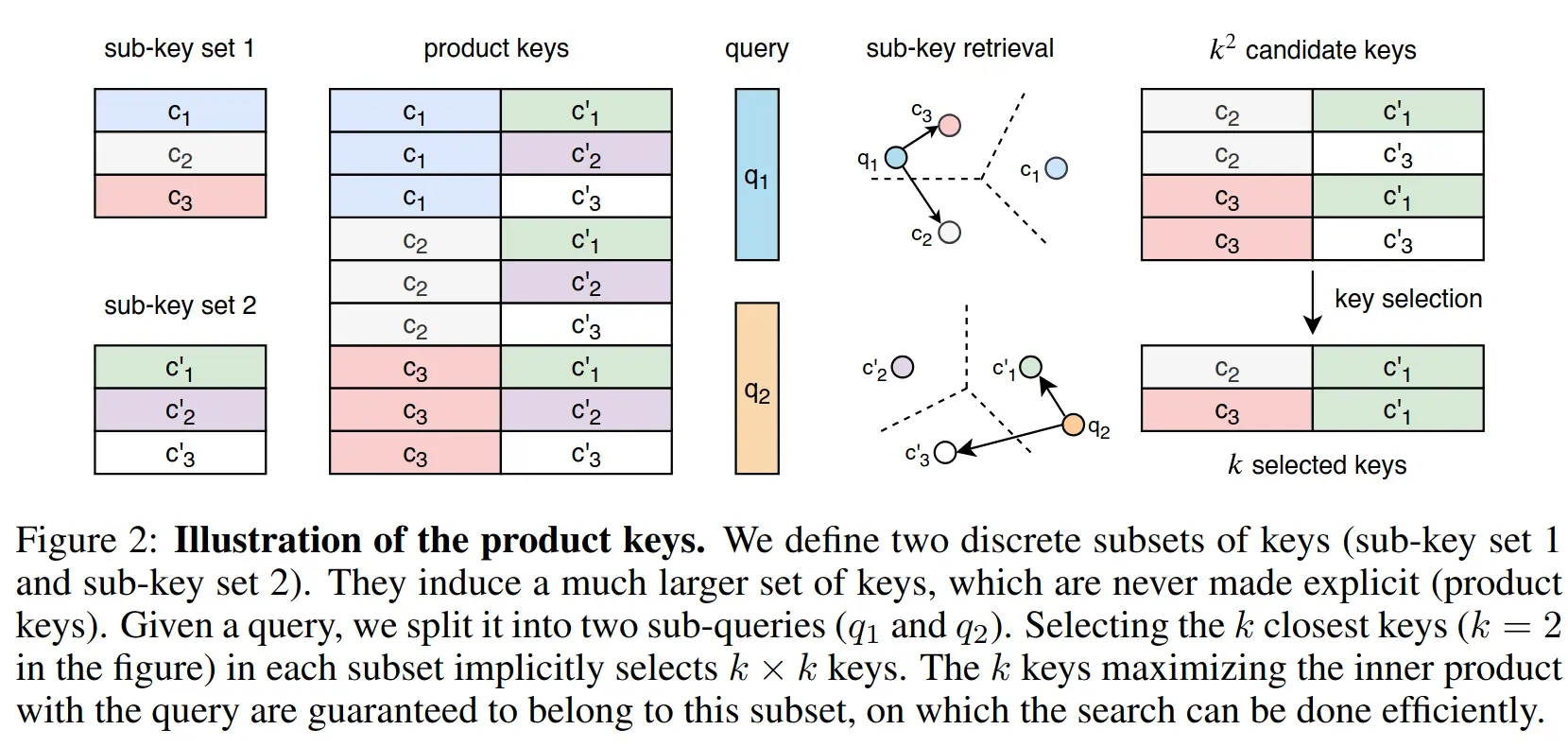
We create two matrices to replace the key matrix , which have a cardinality of and dimensionality .
where are the first and second half of the query vector . So in this equation, we are doing the dot products with halfed dimensionality and only times each.
This creates candidate keys (i.e. containing all the combinations) which contain the most similar keys from to . We can then simply apply the top-k operator again on this set of candidates, leaving us with a runtime complexity of , as opposed to the original , which is much better for large - remember, is just the number of experts we choose, so way less.
The cartesian product of c and c’ is the set of all possible pairs of keys, which is then reduced to the top-k most similar pairs to the query vector q(x).
Link to original
In this paper, “each expert is only a single neuron”:
are vectors with the same dim as , is ReLU / GELU.
???? Single neuron but the are vectors and there are two of them ???
Ig there is a single neuron for each input dimension → scalar activation output → multiplied with second vector to pull up dimensionality again (prlly stores information and is like a gate???)
That’s prlly it - matches this figure. The “singleton” is the squashing of the input to just the scalar activation.

They increase the expressiveness of the network not by adjusting the size of the experts, but adding multiple query heads (similar to MHA / Product Key Memories), by just running them in parallel - the results get summed:
One such “PEER” layer with heads is equivalent to using one expert with hidden neurons:
where .
→ PEER dynamically assembles an MLP with neurons by aggregating singleton MLPs retrieved from a shared repository.
Allows sharing of hidden neurons among experts, enhancing knowledge transfer and parameter efficiency.
 k
k