This note refers to LLM scaling laws.
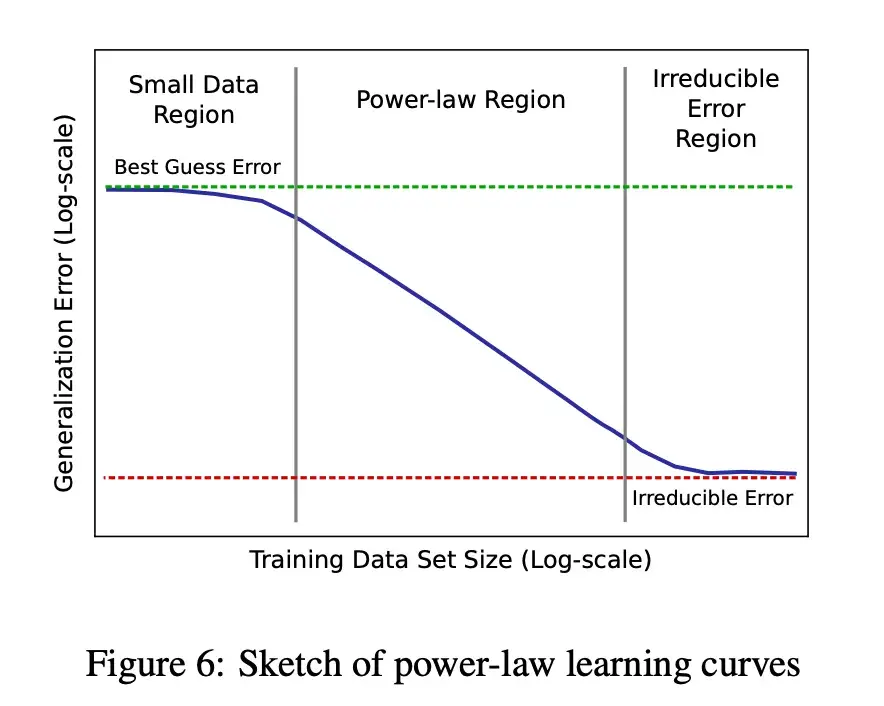
Power law scaling laws prlly come from / long-tailed distribution of correlations lengths in randomly distributed data
→ To beat the “need exponentially mode data for linear increases in performance” regime, you need to actively/intelligently gather new data.
The problem may be more in the teaching than in the learning.
Brains may indeed implement some hyper-efficient neural-learning magic, but it’s increasingly clear that a good deal of the suboptimality in pretraining lies in a foie gras –like approach to training data. We take as much of the Web as we can grab, grind it up into paste, and force it down the neural net’s gullet, in random order, with no regard for curriculum, relevance, redundancy, context, or agency on the part of the model itself. (Apologies if this just put you off dinner.)
Link to original
Circular transclusion detected: library/what-is-intelligence/chapter-09/chapter-09
Circular transclusion detected: library/what-is-intelligence/chapter-09/chapter-09
TLDR of some papers – in a nutshell: Adam and xLSTM improve scaling laws by some constant, but only data (distribution, dataest size) improves the power law exponent, data pruning can even do better than power law scaling: