SARSA is on-policy TD learning with the Q-function.
Here we are always doing what we think is the best thing, so no epsilon greedy exploration. It’s more conservative “save” due to that (no random actions), and converges slower than Q-learning, but we gain more cumulative reward.
In contrast to Q-learning, we update our Q-values based on the actual actions we take, not the maximum Q-value of the next state:
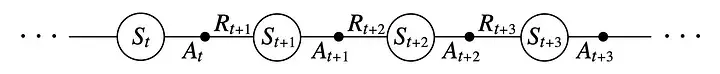

reinforcement learning
on-policy, temporal difference learning
https://lilianweng.github.io/posts/2018-02-19-rl-overview/#sarsa-on-policy-td-control