TD learning methods update targets with regard to existing estimates rather than exclusively relying on actual rewards and complete returns as in monte carlo methods, i.e. we update our value estimate towards the TD target , also called one-step return. This approach is known as bootstrapping, and frees us from the need to collect complete episodes to update the value function:
… state-value function at time
… discounted return
… hyperparameter to the extent we want to update the value function based on rewards vs estimates
The last equation here just takes the very next actual reward into account when bootstrapping, but the formula for extending to steps is exactly the same as the second equation above…
Generalized estimate for the -step return :
The question of what we want to pick, i.e. how soon to start relying on predicted rewards, is handled by TD Lambda in a similar way / with a similar intuition as with reward discounting: We take a weighted average of all possible -step TD targets rather than picking a single best , discounting future rewards, as the further in the future we predict, the less confident we are.
The one-step version is equivalent to TD(0).

is called the TD error.
The TD error can be used to update a value estimate as soon as the next state and reward are observed.
Implementation:
def get_td0_returns_and_advantages(
rewards: Float[np.ndarray, "steps ..."],
values: Float[np.ndarray, "step+1 ..."],
dones: Float[np.ndarray, "steps ..."],
gamma: float,
) -> tuple[Float[np.ndarray, "steps ..."], Float[np.ndarray, "steps ..."]]:
"""Compute returns and advantages using TD(0)"""
steps = rewards.shape[0]
advantages = np.zeros_like(rewards)
nonterminal = 1 - dones
for t in range(steps):
# td error: r_t + γV(s_{t+1}) - V(s_t)
advantages[t] = rewards[t] + gamma * values[t + 1] * nonterminal[t] - values[t]
returns = advantages + values[:-1]
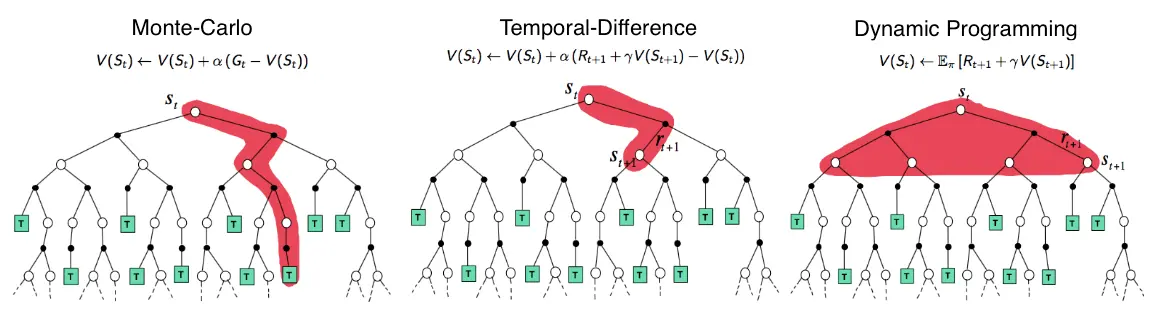
return returns, advantagesLink to originalThe picture shows the value propagation (“backup”) of a single update step with these three methods:
MC methods require complete episodes to learn, using actual returns to update value estimates. They’re unbiased (as long as there is exploration) but have high variance and require complete episodes (and thus more samples to achieve an accurate estimate, so bad for expensive environments), though truncated returns can also work.
TD bootstraps from existing value estimates after single steps, combining actual rewards with predicted future values. This introduces bias but reduces variance and enables online learning.
DP methods use the full model of the environment to consider all possible next states simultaneously, computing expected values directly. This is most sample-efficient (you don’t need to sample in order to approximate values – at the cost of exhaustive search) but requires a complete model of the environment, and are impractical for large state spaces, even with a perfect model (curse of dimensionality).
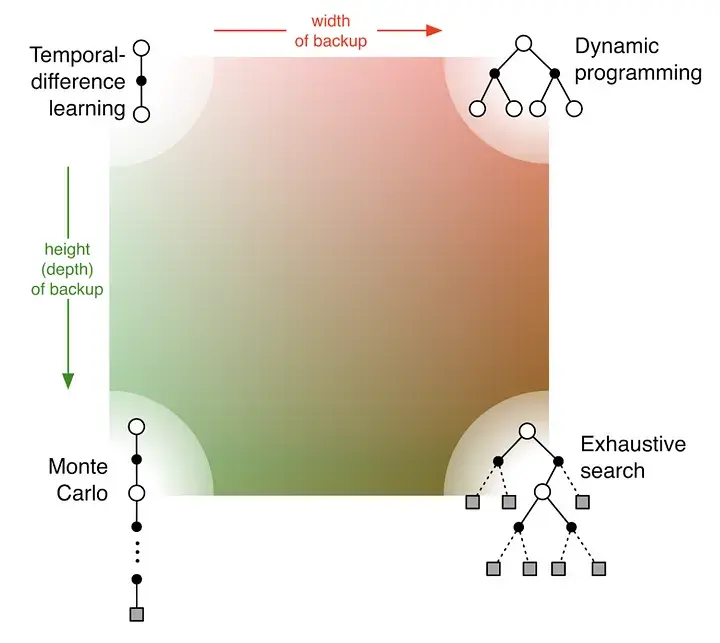
MC (left) vs TD
References
https://lilianweng.github.io/posts/2018-02-19-rl-overview/#temporal-difference-learning