year: 2025
paper: titans-learning-to-memorize-at-test-time.pdf
website:
code:
connections: memory in transformers, memory token, transformer, in-context learning
Notes from YK paper discussion
Kernelized linear transformers are RNNs.
Linear RNNs use vector-valued memory. Linear transformers use vector-valued memory.
You want a strong memory.
You don’t want to have just a single big memory but different types of memory.
These memory systems need to be interconnected, operate independelty and/or the ability to actively learn (decide deliberately what to store) from data anad memorize the abstraction of past history (do some processing before storing).We argue that in an effective learning paradigm, similar to human brain, there are distinct yet interconnected modules, each of which is responsible for a component crucial to the learning process.
Yh but why not go one step down to not hand-design these modules but have them self-organize.
If you just additively update your memory, every new thing you add will be less effective. If you build in decay, you forget things you shouldn’t.
Make an active choice about what to remember.
Surprising things are worth remembering.
You don’t just remember the very thing that surprised you (momentary surprise), but you generally remember the whole thing/stuff after a thing that surprised you.
They learn in a data-dependent way for how long the surprise should hold on.Yannik says the persistent memory would absolutely simply be absorbable into the rest of the parameters of the model. Hmm. Not buying that, since you have input dependent nonlinear interaction… I probably misunderstood sth
Another analogy is that it’s like prefix tuning.
Random comments from chat:
Lindenstraus-Johnson theorem says you can store more if you accept an error level.
Transclude of vc-dimension#^f52c6a
80/20 notes on the memory mechanisms:
Titans frames memory as a three-component system analogous to human memory:
Short-term memory – standard attention over current context window
Persistent memory – learnable vectors concatenated to input, exactly like memory tokens. They call it “persistent” because these parameters are fixed after training / stateless between forward passes (unlike RMT where memory content changes across segments). Stores task-level knowledge.
Long-term memory – an MLP trained during inference to store key-value associations. Each token writes to memory by gradient-stepping on (i.e., learning to approximate ). History gets compressed into weights rather than stored as explicit KV.
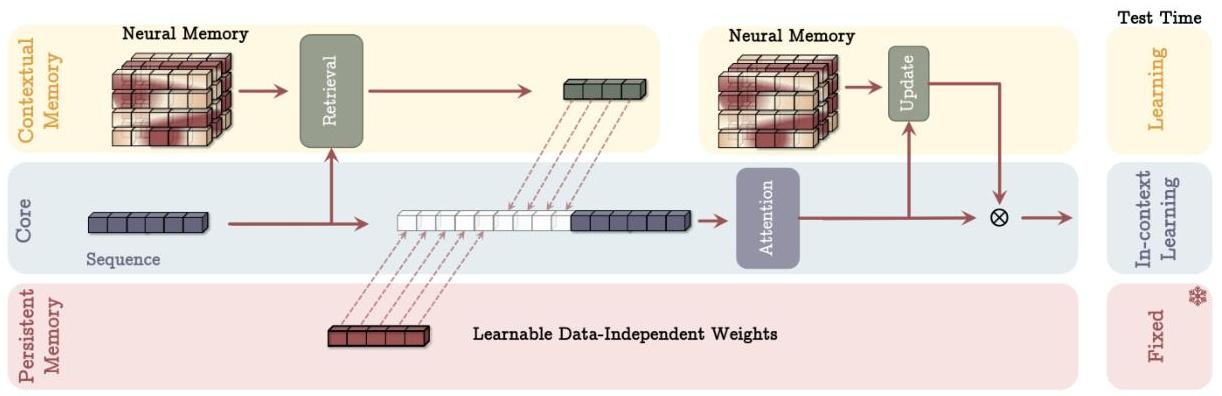
MAC (Memory as Context): Segment sequence → retrieve from memory → concat with current segment + persistent memory tokens → full attention within segment → use output to update memory. Memory and attention interact per-segment.
This architecture includes three branches of (1) core, (2) contextual (long-term) memory, and (3) persistent memory. The core branch concatenates the corresponding long-term and persistent memories with the input sequence. Next, attention performs on the sequence and decides what part of the information should store in the long-term memory. At the test time, parameters corresponds to contextual memory are still learning, parameters corresponds to the core branch are responsible for in-context learning, and parameters of persistent memory are responsible to store the knowledge about tasks and so are fixed.
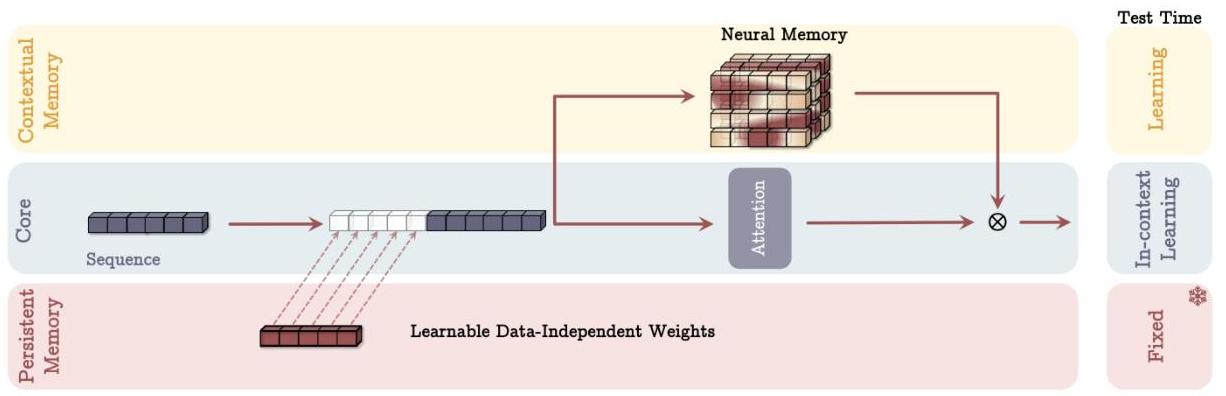
MAG (Memory as Gating): Sliding window attention and memory module run in parallel on the same input, outputs combined via learned gating.
This architecture, similarly, has the three branches of (1) core, (2) contextual memory, and (3) persistent memory. It, however, incorporates only persistent memory into the context and combine memory with the core branch using a gating mechanism. At test time, the behavior is the same as Figure 2.
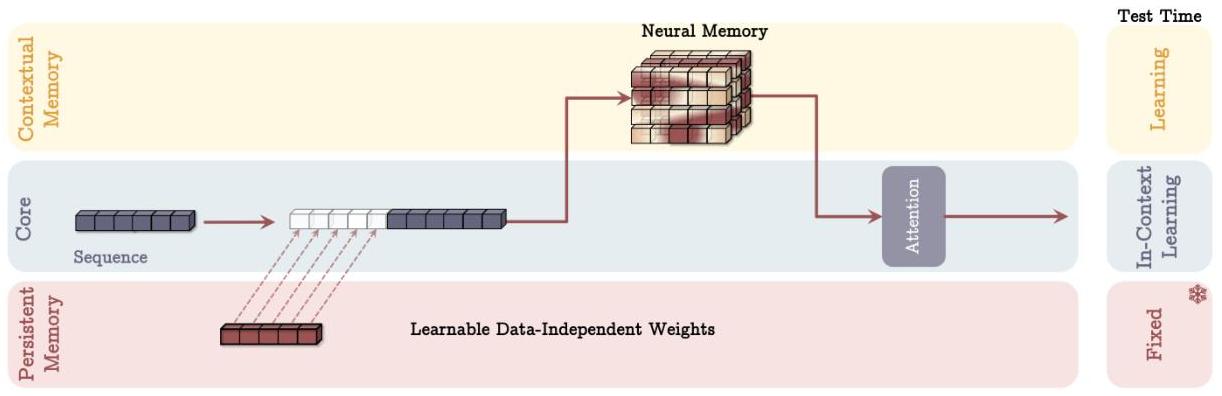
MAL (Memory as Layer): Memory module → sliding window attention. Sequential stacking, same as most hybrid models (Samba, Griffin, etc.).
In this architecture, the memory layer is responsible to compress the past and current context before the attention module.
Key Findings
- Deeper memories () help on longer sequences but slow training linearly
- MAC and MAG beat MAL (i.e., the non-standard ways of combining memory with attention work better than sequential stacking)
- Scales to 2M+ context on BABILong, beating GPT-4 with far fewer parameters
- Each component (momentum, weight decay, depth, convolutions) contributes positively in ablations
“large gradients = larger weight updates.”