year: 05/2023
paper: https://arxiv.org/pdf/2305.13245.pdf
website: https://paperswithcode.com/method/grouped-query-attention
code: Mistral uses. Code
connections: MQA
Grouped-query attention an interpolation of multi-query and multi-head attention that achieves quality close to multi-head at comparable speed to multi-query attention.
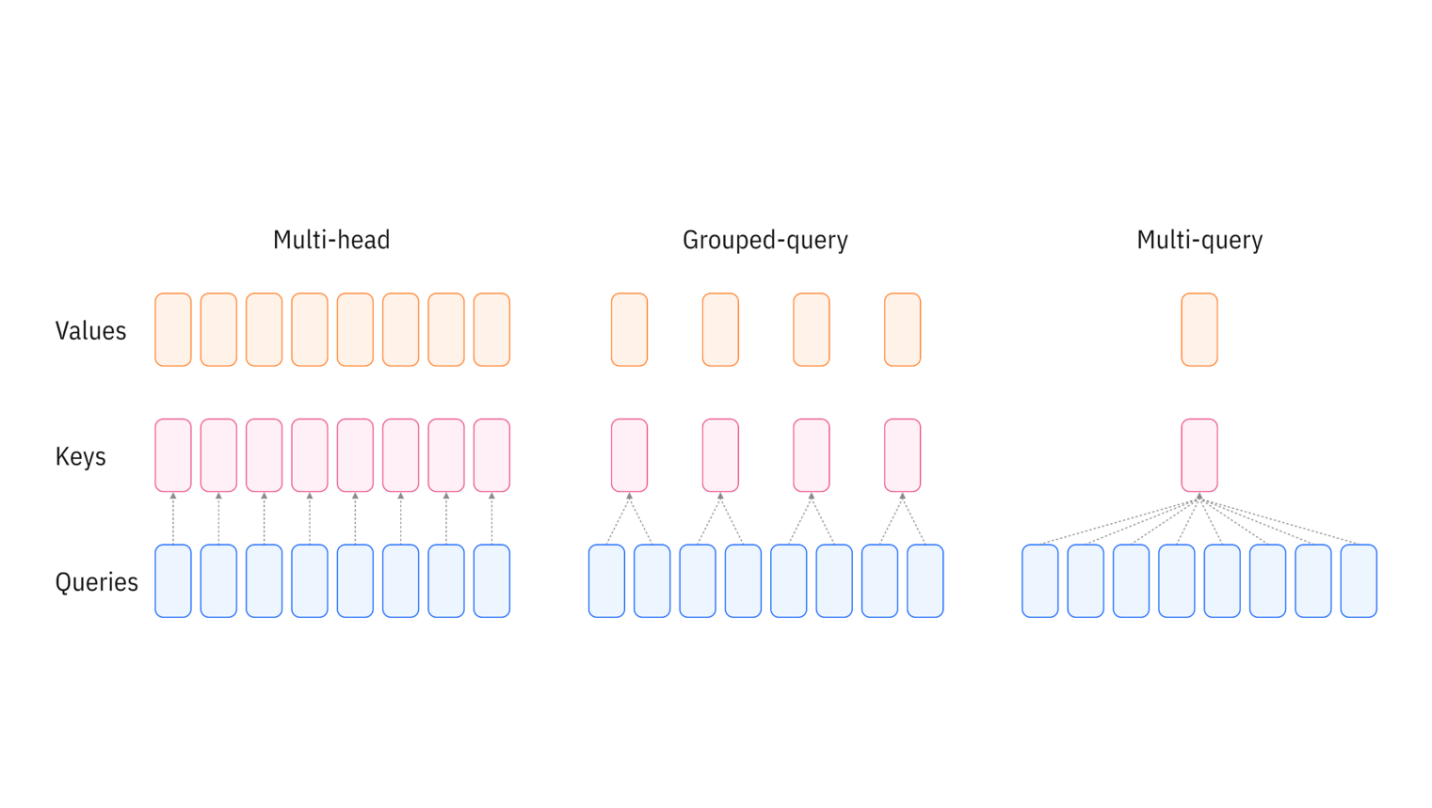
Motivation is to reduce values and keys to save on KV cache size.
The extreme version of just one K and V for each Q doesn’t make that much sense but small group sizes like 2-3 have basically the saame perf while saving lots.