This note is a reference for different kinds of attention.
Attention? Attention! (Blogpost) [Deep intro to attention]
See also:
self-attention (attention mostly refers to this nowadays)
scaled dot product attention
cross-attention
Link to originalAttention is a communication mechanism / message passing scheme between nodes.
Attention in principle be applied to any arbitrary directed graph.
Attention can be thought of as a message passing scheme.
Every node (token) has some vector of information () at each point in time (data-dependent) and it gets to aggregate information via a weighted sum from all the nodes that point to it.
Imagine looping through each node:
- The query - representing what this node is looking for - gathers the keys of all edges that are input to this node and then calculates the the unnormalized “interestingness” of information / compatibilities with other nodes by taking the dot-product between the keys and the queries.
- We then normalize these scores and multiply them with the value of the input nodes.
- This happens in every head in parallel, and every layer in sequence, with different weights (in both cases).
The attention graph of encoder-transformers is fully connected.
The attention graph of the decoder is fully connected to the encoder values, and tokens are fully connected to every token that came before them (triangular attention matrix structure).
Graph of autoregressive attention (self-loops are missing from the illustration):
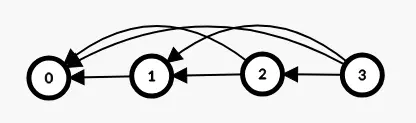

Circular transclusion detected: general/self-attention
Link to originalThe hamiltonian of the Hopfield Network is identical to the ising model, except that the interaction strength is not constant, and very similar to attention!
For a hopfield network:
is the weight / interaction matrix, which encodes how patterns are stored, rather than being a simple interaction constant.
In a simplified form, the update rule of the HFN is:And for attention:
Tokens in self-attention are just like spins in the ising model, but instead of spins, they are vectors in higher dimensional space, with all to all communication, self-organizing to compute the final representation.
See also: associative memory.
Circular transclusion detected: general/self-attention
Causal, non-causal attention and cache: See causal attention.
Soft vs Hard Attention
Soft Attention:
- The alignment weights are learned and placed “softly” over all patches in the source image; essentially the same type of attention as in Bahdanau et al., 2015.
- Pro: the model is smooth and differentiable.
- Con: expensive when the source input is large.
Hard Attention (Not acutally used):
- only selects one patch of the image to attend to at a time.
- Pro: less calculation at the inference time.
- Con: the model is non-differentiable and requires more complicated techniques such as variance reduction or reinforcement learning to train. (Luong, et al., 2015)