This work opens a fundamentally new axis of control for training language models. Instead of treating the training distribution as fixed, we can tune the structure of synthetic data to match target domains.
The long-term vision is: foundation models that acquire reasoning from fully synthetic data, then learn semantics from a small, curated corpus of natural language. This would help us build models that reason without inheriting human biases from inception.
Core hypothesis: LLMs learn useful representations from the structure of natural language, not its semantics. If that’s true, richly structured non-linguistic data should also work. They test this with NCA trajectories as a pre-pre-training substrate (train on NCA, then standard language pre-training).
Random NCA transition rules are sampled by randomly initializing a small neural network (3×3 conv → MLP, ~103 params) that governs cell updates on a 12×12 grid with 10-state alphabet. Grids are tokenized as 2×2 patches (vocabulary of 104), flattened left-to-right, top-to-bottom per timestep with <grid>/</grid> delimiters, concatenated into sequences of up to 1024 tokens. Each sequence comes from a unique latent rule the model must infer in context: the model implicitly maintains a posterior over “which rule θ generated this?” and conditions predictions on it (the Bayesian view of ICL).
Since randomly sampling θ yields everything from fixed points to randomness, they filter by gzip compression ratio r=compressed/raw of the serialized trajectory. Low r (highly compressible) means trivially predictable dynamics, high r means near-random chaos. By selecting specific compression bands (e.g. 30-40%, 50%+), they control how much learnable structure the data contains. Default: r>50%. The resulting token distributions follow a Zipfianpower law, similar to natural language, which prior work identifies as a key property for transfer from synthetic data.
Results (1.6B param Llama, 164M NCA tokens)
Up to 6% lower perplexity and 1.6x faster convergence on OpenWebText, OpenWebMath, CodeParrot
Gains transfer to reasoning benchmarks (GSM8K, HumanEval, BigBench-Lite)
160M NCA tokens outperform 1.6B tokens of C4 (cleaned Common Crawl) for pre-pre-training, even when C4 gets 10x more data and compute
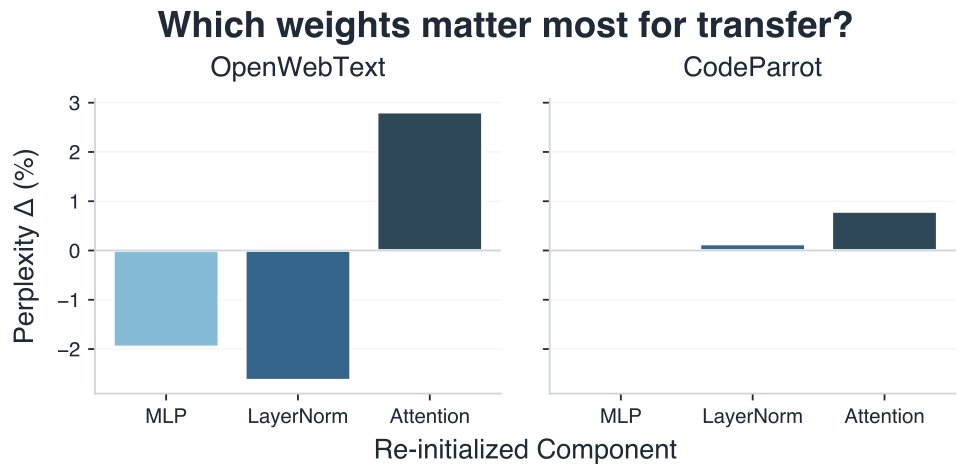
Attention layers learn general-purpose mechanisms for tracking dependencies and inferring latent rules, while MLP layers specialize in storing domain-specific patterns and statistics.
Selectively re-initializing model components after NCA pre-pre-training: losing attention weights hurts most. MLP and LayerNorm transfer is domain-dependent and can even hurt if the source/target domains mismatch.
Proposed mechanism: NCA training may induce earlier, more robust formation of induction heads (circuits that copy prior-token patterns to predict future ones). Since every NCA sequence requires pure in-context rule inference, the training signal for these circuits is undiluted by semantic priors.
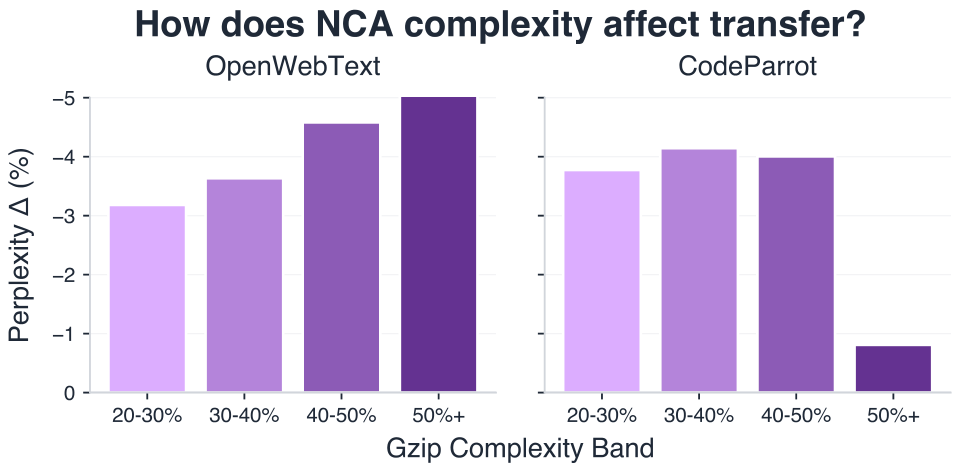
Optimal NCA complexity is domain-dependent
Code benefits from lower-complexity NCA rules (gzip ~30-40%), while math and web text benefit from higher complexity (50%+). This correlates with the intrinsic compressibility of the target corpora themselves (CodeParrot ~32% gzip, OpenWebText/Math ~60-70%).
So the type of structure that is pre-pretrained matters.
But why don't they mix complexity bands so a broad spectrum is learned?
The paper focuses on crafting domain-specific distributions “Beyond one-size-fits-all” but would’ve been interesting to see how well mixed performs…
if researchers can craft distributions that embody the primitives a domain requires (e.g., rigid state-tracking for code, richer long-range dependencies for genomic sequences), they can instill these capabilities directly
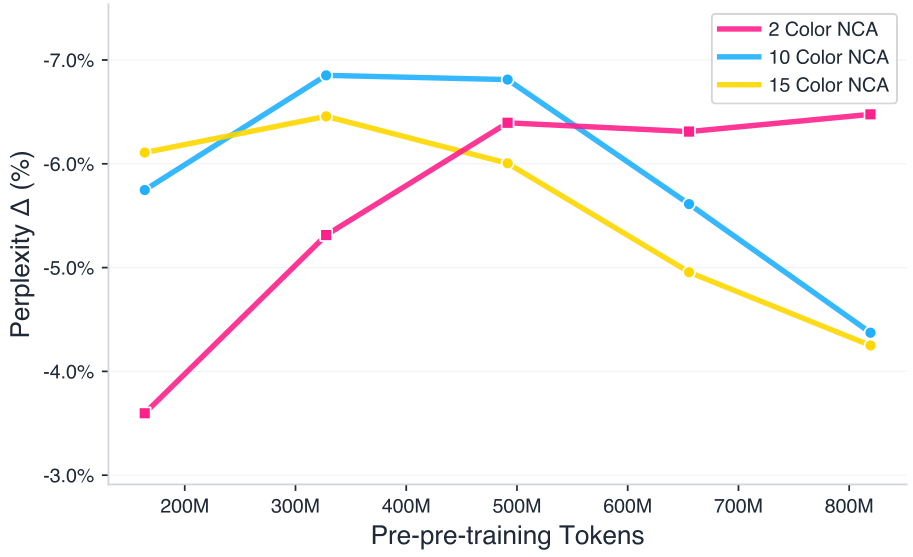
A second complexity axis: NCA state alphabet size
n∈{2,10,15}. Larger n produces more complex dynamics, but n=2 actually scales best with more tokens, while n=10,15 plateau past ~400M tokens. Smaller state spaces seem to concentrate samples on dynamics with more consistently transferable structure.
Why does non-linguistic synthetic data transfer better than language itself (at matched budget)?
At only 1.6B tokens, C4 pre-pre-training is in an early training regime where the model primarily acquires shallow syntactic patterns. NCA sequences provide a purer signal for in-context rule inference: no semantic shortcuts, every token forces latent rule identification.
Each NCA sequence is also structurally unique (unique random network weights), while natural language corpora contain substantial redundancy in linguistic patterns.
Deterministic NCA rules can produce emergent structures (gliders, collisions) that a finite-capacity model cannot brute-force simulate.
The model must learn higher-level abstractions to predict efficiently, and these abstractions transfer.