Link to originalMany naive things become possible in/with CLIP’s/LLM representation space, such as
- specifying goal states in natural language
- stopping simulation/training once change in latent space plateaus (magnitude of clip vector change)
- (heuristic metrics that fall short in other cases)
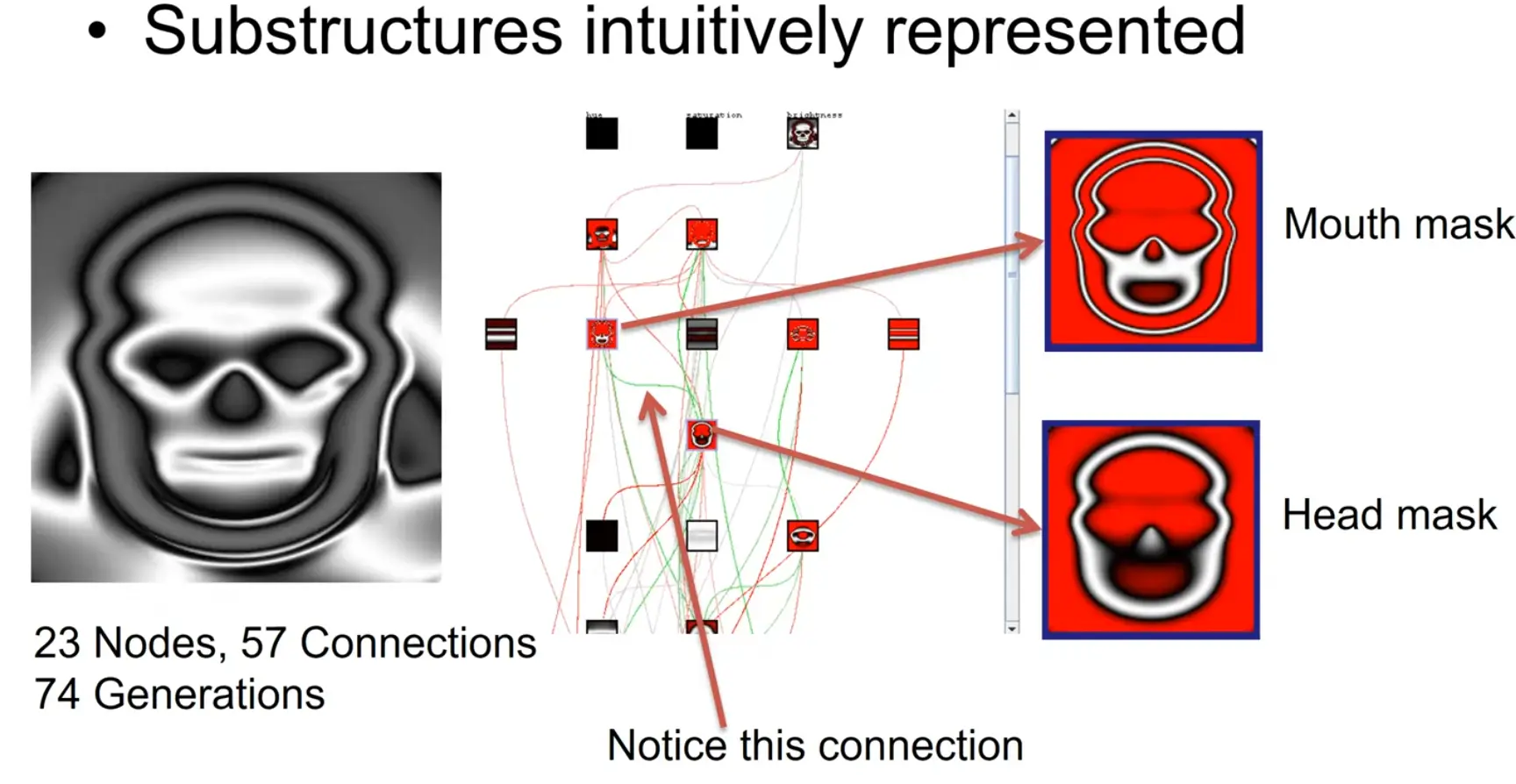
Link to originalOpen ended discovery leads to fundamentally different organization/ representation: Representations are more meaningful / composable / efficient / natural
Explains DNA to some extent: Perturbation is sensible / canalized.
Should representations look like DNA?
If you “think open-endedly” (not optimizing for one specific (end-)goal), do you obtain representations that are different than those who don’t? (broader / more organized / easier creative thinking)
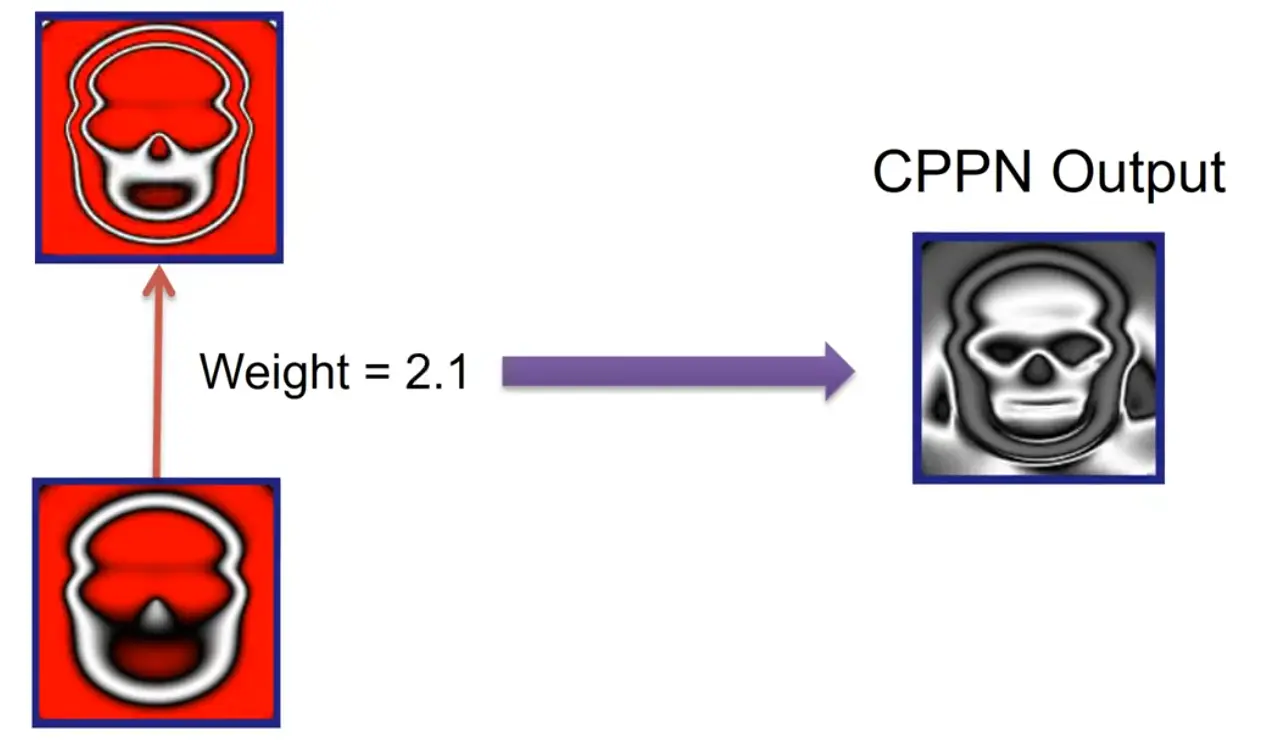
A single weight controls the mouth aperture:
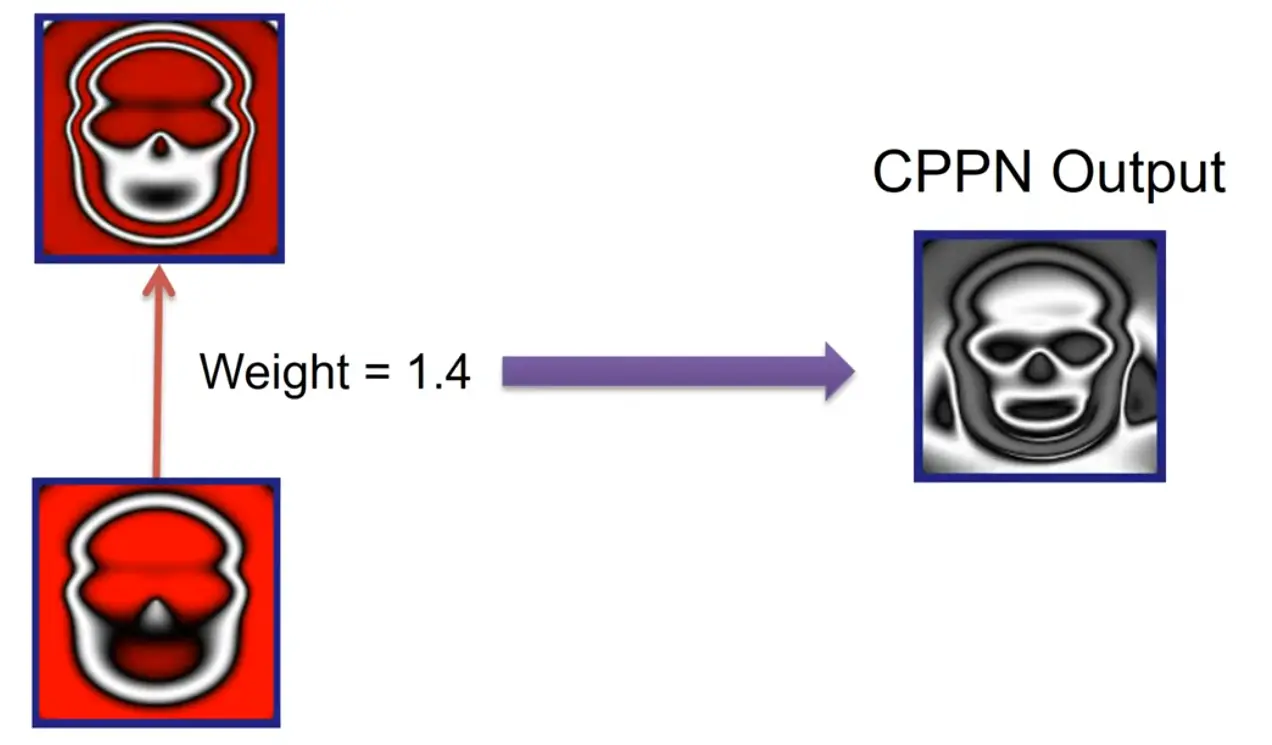
(other example: single weight controls the swing of the stem of an apple)

Link to originalHow do we measure the extent of open-ended learning?
Even with the above problems addressed, there are no commonly accepted measures for tracking the degree of open-ended learning achieved—that is, some measure of increasing capability. Previously proposed measures of open-endedness cannot be adapted for this purpose, as they focus on measuring novelty, rather than model capability. In general, such novelty and model capability are unrelated. For example, a process that evolves an agent across an endless range of mazes, while progressively growing the size of the agent’s memory buffer, may score highly in novelty, but remains limited in capability.
LLM, while not posessing the capabilities itself could be used to judge capabilities / achievements of other models?
→As the learning potential and diversity terms in the open-ended exploration criterion in equation (4.2) are dependent on the current model, they present challenging non-stationary search objectives for active collection. Efficient search may require a compact latent representation of the data space, as well as the use of surrogate models to cheaply approximate the value of a datapoint under the search criterion. This latent space might correspond to the input context to a Transformer-based generative model of the data space or of data-generating programs.
… we lack principled ways to predict the relative efficacy of training on data actively collected manually, online or offline. Lastly, it is unclear how the relative weighing between the terms in equation (4.2) should evolve over time.Ok great, so does it boil down to: The objective sounds good and all in theory but we need proxies to actually optimize?
So the big question is how much can we offload to LLMs here?
Alpha Evolve suggests: Plenty.
Good representations are fundamental for (efficiently) finding solutions
Is it possible to fill this mutilated chessboard with dominoes?
With raw search, it's difficult to find a solution, but taking a more abstract representation helps a lot: Each domino takes up a black and a white square, but we removed two black squares, so we'd need a "diagonal domino", else there'll always be two white squares left over.
Is it possible to place 8 non-attacking queens on a chessboard? (
math.log(math.prod([64-i for i in range(8)]), 10)) possible placements to check. But if you realize that each row and column must contain exactly one queen, you can shrink the search space to placements. If you also check for diagonal constraints, that leaves us with 92 valid solutions (12 if you consider rotations and reflections as the same solution).Naively, you have
Another way of solving it is by placing 8 queens right away, and moving them using the heuristic of minimizing the number of attacking pairs of queens, until there are none left / every possible move worsens the objective (hill-climbing search / aka greedy local search).