Cumulative Distribution Function (CDF)
The cumulative distribution function (CDF) of a random variable is a function that gives the probability that will take a value less than or equal to . It is defined as:
where is the probability density function (PDF) of .
standard normal distribution CDF ()
For the standard normal distribution (), the CDF is often denoted as .
For the interval , which represents 1 standard deviation from the mean:
This shows that approximately 68% of values drawn from a standard normal distribution lie within one standard deviation of the mean.
The CDF is a non-decreasing function with a range of
For any real-valued random variable, the CDF has the following properties:
- is non-decreasing (i.e., for all )
Relationship between PDF and CDF
The PDF is the derivative of the CDF (when the derivative exists):
Conversely, the CDF is the integral of the PDF:
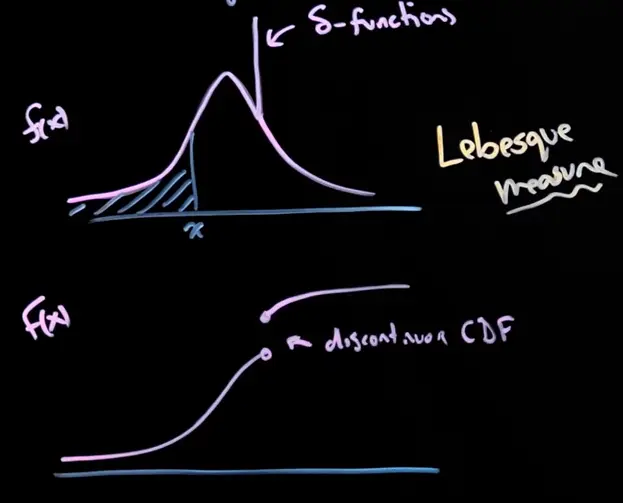
CDFs are often nicer to work with than PDFs for discontinuous distributions
For PDFs, you’d need ugly delta functions to represent jumps, which are nicer to work with if integrated over.
Another approach is lebesgue integration, which is more general than riemann integration and can handle discontinuities better.