Eigenvectors are vectors who’s span is unchanged by a linear transformation.
Eigenvectors only get stretched/squished (scaled) or are left unchanged.
The eigenvalue is the value by which the vector is scaled.
You can think of it as the axis of rotation.
For a true rotation however, the eigenvalue needs to be , as rotations don’t scale vectors (we call those transformation matrices unitary)
Applying the transformation matrix to the eigenvector is equivalent to simply scaling it by its eigenvalue :
We want to figure out the eigenvector and the eigenvalue :
For that we make both sides look like matrix-vector multiplication, by multiplying with the identity.
We now want the nonzero solution for :
The product of a nonzero vector with a nonzero matrix can only be zero if the determinant is zero, so we are looking for a that satisfies:
Meaning we tweak lambda in such a way, that the resulting transformation squishes space to a lower dimension:
If , then the transformation changes the space in a way that it collapses to a lower dimension (for the case of it may be a plane, line or point: anything with 0 volume).
Link to original
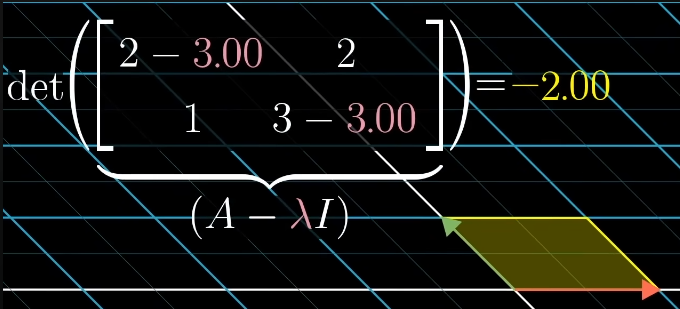
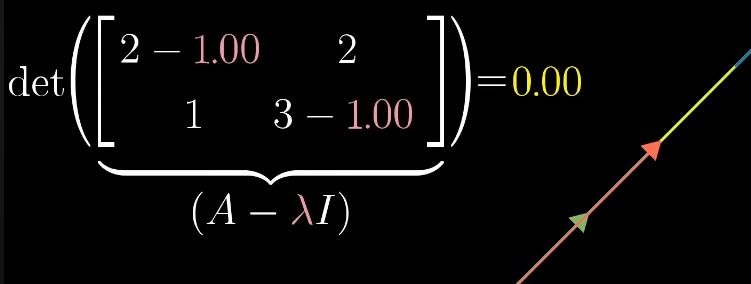
So we need to solve the equation for , then we can find the eigenvector , which stays on its span, scaled by , by solving the equation .
Not every transformation has a real eigenvector.
A rotation e.g.
only has the imaginary eigenvectors and :
The axis of rotation is around the complex plane, at the origin.
So multiplying with usually means some kind of rotation. This is also the case within the complex plane (the angles get added together).
A shear like only has a single eigenvalue.
The eigenspace is 1-dimensional … a single eigenline:
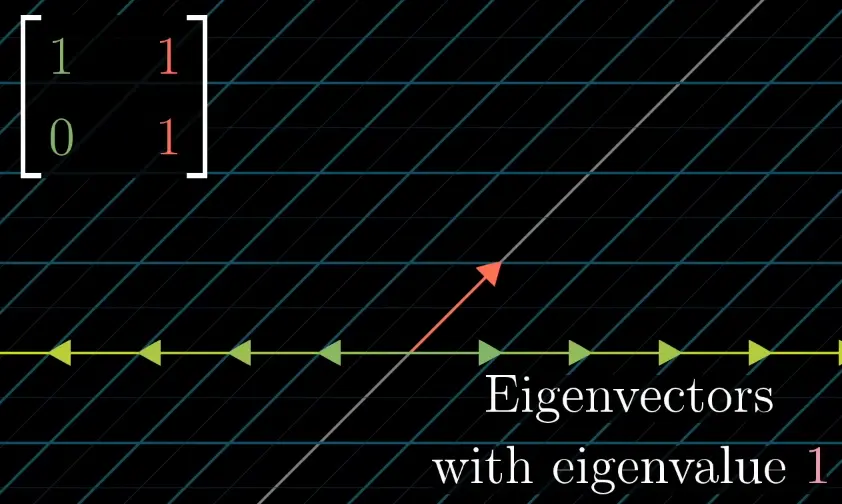
In a diagonal matrix, all vectors are eigenvectors, and the diagonal entries are the eigenvalues.
Diagonal matrices only scale what they are being multiplied with, since the basis vectors are also eigenvectors. For diagonal matrices, every vector is an eigenvector.
The matrix scales every vector by 2. Every vector is an eigenvector with .
Link to originalDiagonal matrices have nice computational properties when taking large powers.
Circular transclusion detected: general/diagonal-matrix
Eigenvector puzzle

3b1b’s solution: Eigenvalue puzzle solution.pdf
Highlights from the solution / my take:
The terms form the fibonacci sequence:
The eigenvalues of were computed by:
… is the golden ratio , and is .
(after calculating the eigenvectors …)
Converting to the eigenbasis:
Now we can compute:
…instead of tedious matrix multiplication.
To translate back into the original cordinate system:
Okay I’m not typing this shit, looks sick tho (look at the solution pdf for the equation).
It’s a really interesting / funny way of computing fibonacci.
(And ig probably the most efficient? As you don’t need any recursion)
References
3b1b: Eigenvectors and eigenvalues | Chapter 14, Essence of linear algebra