The generalization error or risk is the exptected loss on future data for a given model with parameters , defined as:
where is the loss function, and is the true (unknown) joint distribution of inputs and outputs .
We estimate the generalization error using the empirical risk (or training error) computed on a finite training dataset :
This works under the assumption that the training data is drawn iid from the same distribution as future data, and by the law of large numbers, the empirical risk converges to the true risk as .
Link to originalThe bias-variance tradeoff in supervised learning
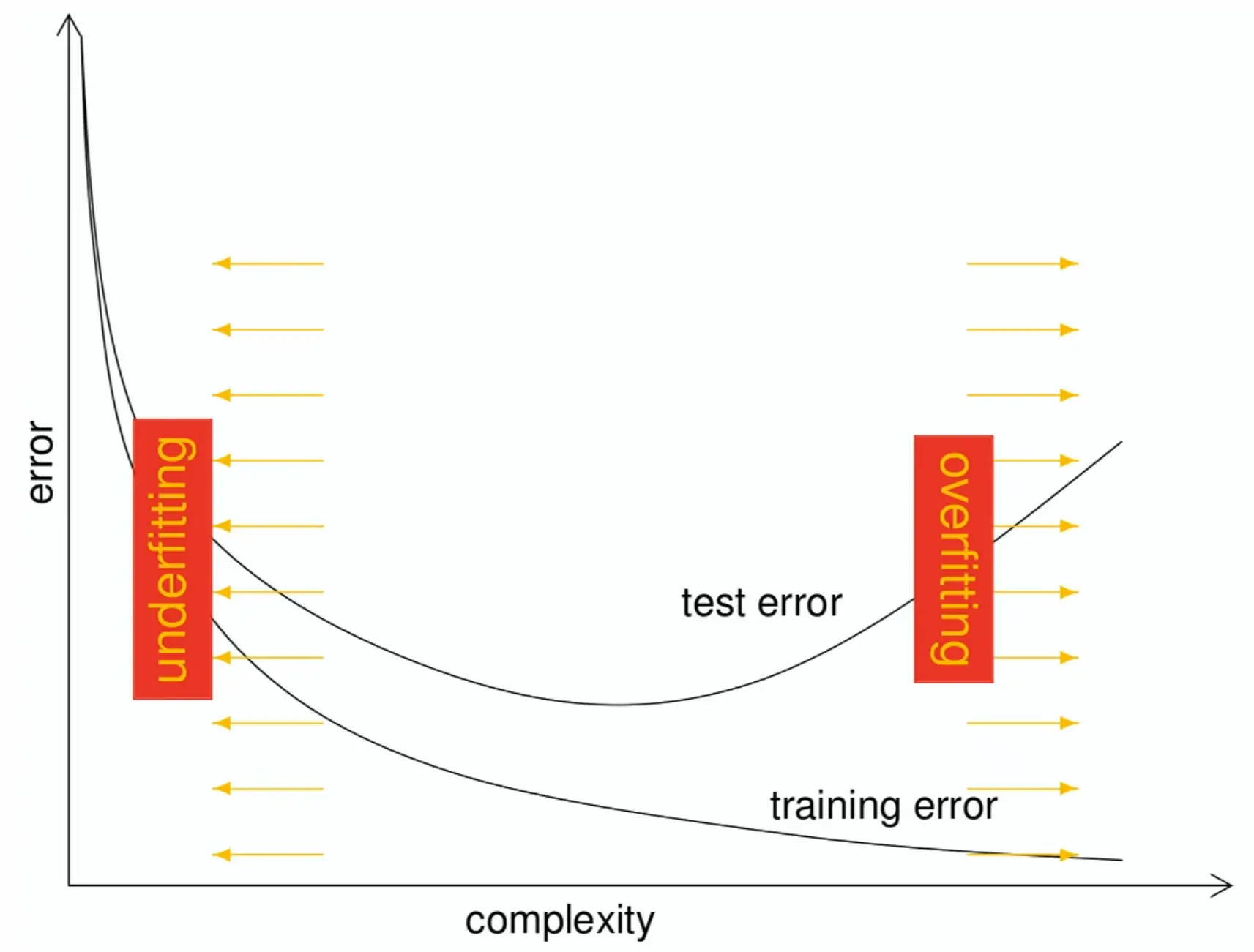
If we train plain empirical risk minimization (ERM), we run the risk of overfitting, where the model fits the training data well (low empirical risk) but performs poorly on unseen data (high generalization error), aka high variance.
→ Assume data samples are iid and partition data into training and validation/test sets to estimate generalization error, e.g. using cross-validation. Validation sets for hyperparameter tuning, to avoid data overlaps/leakage.
→ Use regularization techniques (like L2 regularization, dropout, data augmentation) to reduce overfitting and improve generalization.
The sweetspot is where train and test errors align.