stands for the expectation, which is a mathematical operator that calculates the average value of a random variable over many possible outcomes.
In short, it’s the mean/“center of mass” of a probability distribution
random variable (distribution), can be discrete or continuous
possible outcomes of the random variable
The expected value of a random variable is like saying you go through all of the possible outcomes and multiply the probability of that outcome times the value of that variable (weighted average).
For continous random variables (described by PDFs), the expected value is:
The integral exetends over all possible values of .
In a more general notation:
where is the probability density function and is the expectation function of the random variable and is shorthand for integrating over all possible values of .
Expectations can be approximated by with a sample mean:
If we draw from a particular distribution , we write it like this
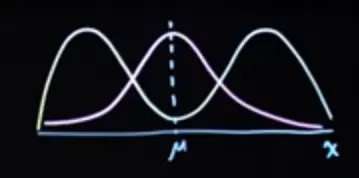
For oddly shaped distributions, the expected value might not actually correspond ot a common value in the distribution
The gaussian and bimodal distributions below have the same , but the bimodal distribution almost never takes on that value:
Properties
The expected value is linear
The expected value is a constant and constants stay constants
If the distribution is uniform, the expected value simplifies to the arithmetic mean of the values.
Only if are independent, then …
Derivation
\begin{align*}
\mathbb{E}(XY) &= \sum_{x} \sum_{y} xy , \underbrace{ P(X=x, Y=y) }{ \text{if independent} } \
&= \sum{x} \sum_{y} xy , P(X=x) P(Y=y) \
&= \left(\sum_{x} x , P(X=x)\right) \left(\sum_{y} y , P(Y=y)\right) \
&= \mathbb{E}[X] \cdot \mathbb{E}[Y]
\end{align*}Where/Why it doesn’t hold because the joint distribution . The difference is captured by the covariance:
For dependent variables,
Parent-child height = parent height, = child height Parents: 160, 180 → Children: 155, 175 →
Joint pairs: (160,155), (180,175) The positive correlation () makes talltall and shortshort pairs more likely, increasing above the independent case.Let
Law of the Unconscious Statistician (LOTUS)
For , you can compute directly using ‘s distribution:
\begin{align*} E[g(X)] = \cases{ \sum_{x} g(x) P(x) & \text{discrete} \cr \int_{-\infty}^{\infty} g(x) f(x) \, dx & \text{continuous} } \end{align*}Important: in general (only equal for linear functions)
with , , but
Let
Common notations for expectations
— after declaring . (Very common in stats/prob.)
or — variable-centric.
— measure/distribution-centric. (Favored in info theory; clean when doesn’t name .)
— explicit sampling form. (Very common in ML.)
or — when referring to a density .
, , — measure/integral form. (Probability/info theory texts.)
— physics/stat-mech style; you’ll sometimes see it in evolutionary/EC papers.
Parametric models: or , sometimes .
Machine learning (incl. VI/RL): , ; Monte Carlo .
Converting Celsius to Fahrenheit &
I measure in , and want the expected value and variance in , .
→ Since is a linear function of , we can directly transform the expectation.
→ Variance changes with change of units / scale, but is not affected by shifts.
Link to originalTail Sum Formula
For a non-negative random variable , the expected value can be computed using the tail sum formula:
Note that , where is the cumulative distribution function of .
References
https://chat.openai.com/c/92cd3571-92b1-4c8f-8345-b62a753888e3