Batch gradient descent
Batch gradient descent computes the gradient of the loss function using the entire dataset at each iteration before updating the parameters:
where is the total number of training examples, is the learning rate, and is the loss function for individual examples.
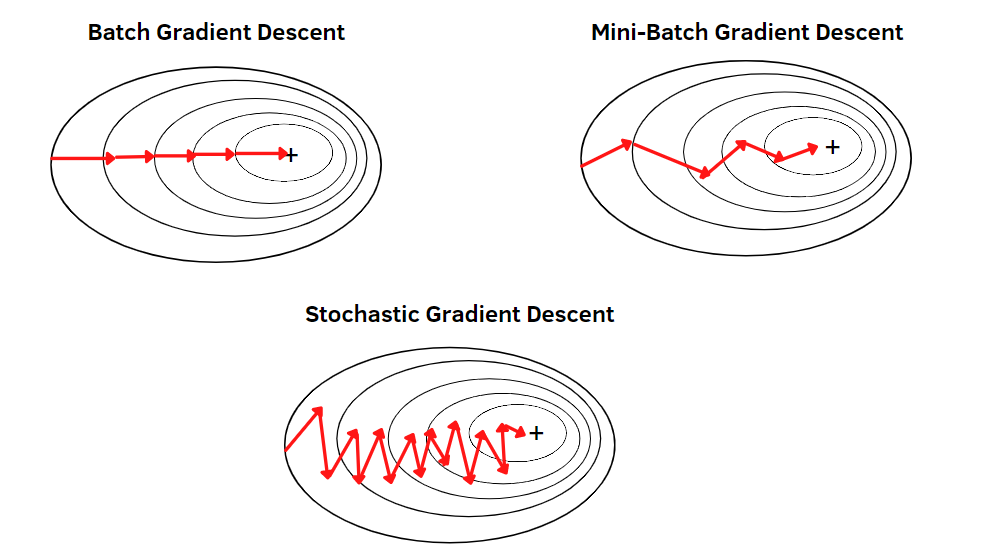
Exact gradient computation
Trade-offs of batch gradient descent
Advantages:
Guaranteed convergence to local minimum (for convex functions) or critical point.
Stable and predictable optimization trajectory.
Can leverage vectorized operations efficiently.Disadvantages:
Computationally expensive for large datasets - requires full dataset pass for single update.
Memory intensive - entire dataset must fit in memory.
No inherent regularization from gradient noise.
Each iteration processes the complete dataset (batch size = ), making it distinct from mini-batch gradient descent (batch size between 1 and ) and SGD (batch size = 1).