Momentum
Momentum is a popular heuristic used along with SGD in place of full second order optimization: It updates weights based on an exponentially weighted moving average of the past gradients.
This helps to smooth out the updates/approximate curvature to find a better path towards the minimum. Essentially: If past updates all point in the same direction, we’re more confident of taking large steps in that direction.
The update rule for gradient dececnt with momentum is:
TODO
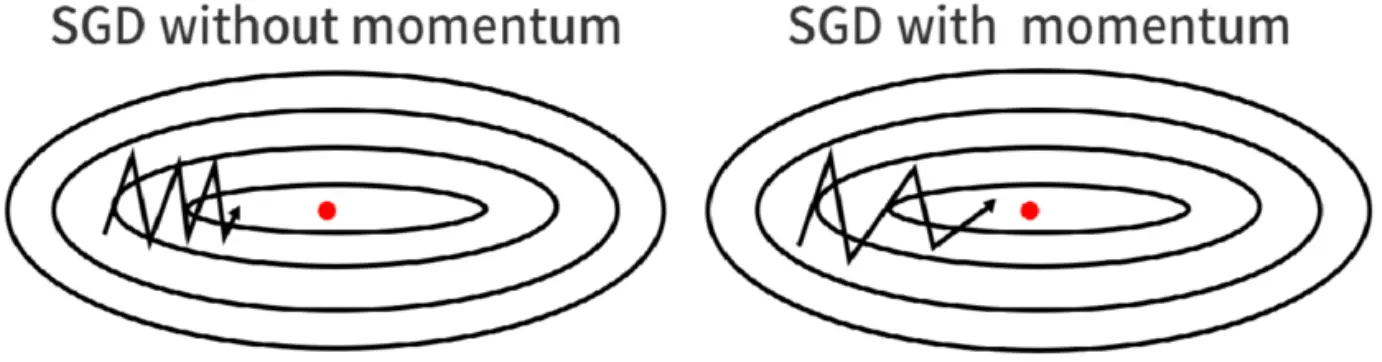
(reminiscent of the effect of mini-batch gradient descent)
redo the equations after reading the nesterov paper… NOTE: likely stands for velocity!
got confused with (https://pytorch.org/docs/stable/generated/torch.optim.SGD.html) which imlpements differently (see note)