Mini-batch gradient descent
Mini-batch gradient descent strikes a balance between batch gradient descent and SGD by computing gradients on small subsets of the training data:
where is a randomly sampled mini-batch of size (with ), and is the total dataset size.
An epoch is defined as one full pass through the entire dataset, while an iteration is one update step using a mini-batch.
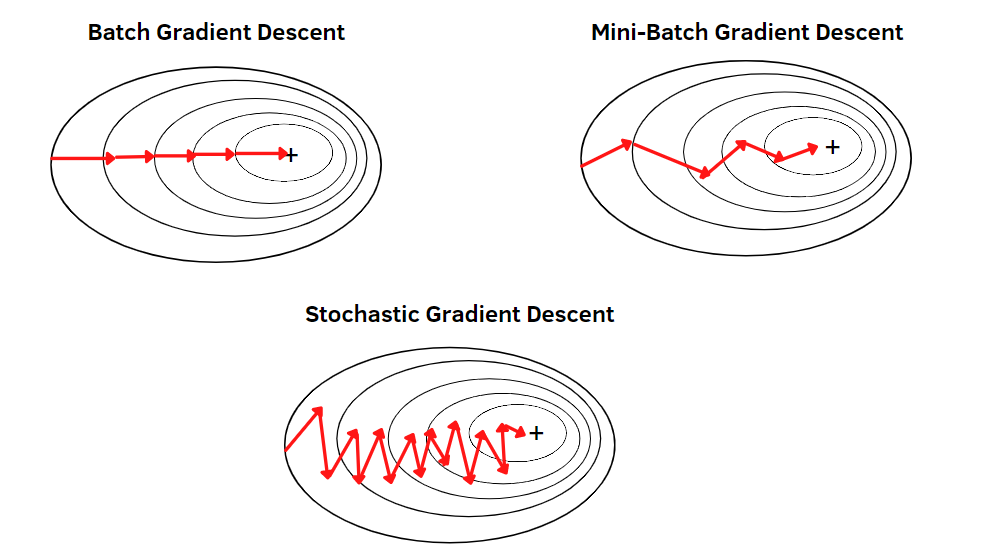
Gradient approximation through mini-batches
The backward step is taken after a mini-batch of samples has gone through the model. Gradients are accumulated across the batch and the optimization step uses their average - producing an approximate gradient of the full dataset.
This approximation introduces noise into the optimization process, which can help escape shallow local minima and acts as implicit regularization.
Why mini-batches work well in practice
GPU parallelism
Variance reduction: Averaging gradients across multiple samples reduces the variance compared to SGD, leading to more stable convergence.
Frequent updates: Unlike batch gradient descent, parameters update multiple times per epoch, allowing faster adaptation to the loss landscape.
Each training sample within a batch remains completely independent from others, preserving the iid assumption (ensures gradient estimates are unbiased and allows for parallel computation without sequential dependencies).
decrease the batch size. Due to the normalization inside batch normalization smaller batch sizes somewhat correspond to stronger regularization. This is because the batch empirical mean/std are more approximate versions of the full mean/std so the scale & offset “wiggles” your batch around more.
Research on large batch sizes
Investigate whether Gradient Accumulation makes sense when sufficient memory exists for reasonable batch sizes (e.g., 32+):
- https://stats.stackexchange.com/questions/276857/too-large-batch-size
- https://arxiv.org/abs/1609.04836 (On Large-Batch Training for Deep Learning)
- https://arxiv.org/abs/1804.07612 (Don’t Decay the Learning Rate, Increase the Batch Size)
- https://forums.fast.ai/t/disadvantages-of-using-very-large-batch-size/29177
- https://datascience.stackexchange.com/questions/16807/why-mini-batch-size-is-better-than-one-single-batch-with-all-training-data