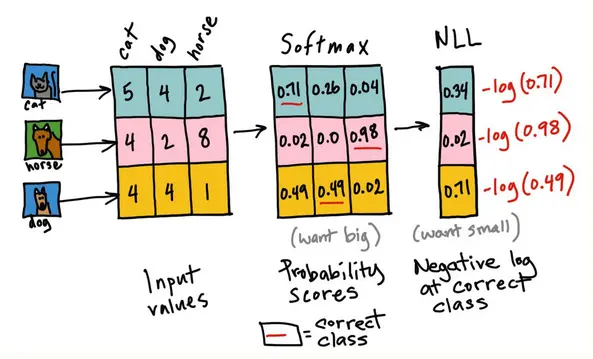
Categorical Cross-Entropy Loss
For one-hot encodings, the cross-entropy loss simplifies to Categorical Cross-Entropy, aka negative log-likelihood loss:
… sample
… index of the correct class
… true label (one-hot, all probability mass is on the true class)
… predicted probability distribution (from softmax, …)
… model parameters
… input features
→
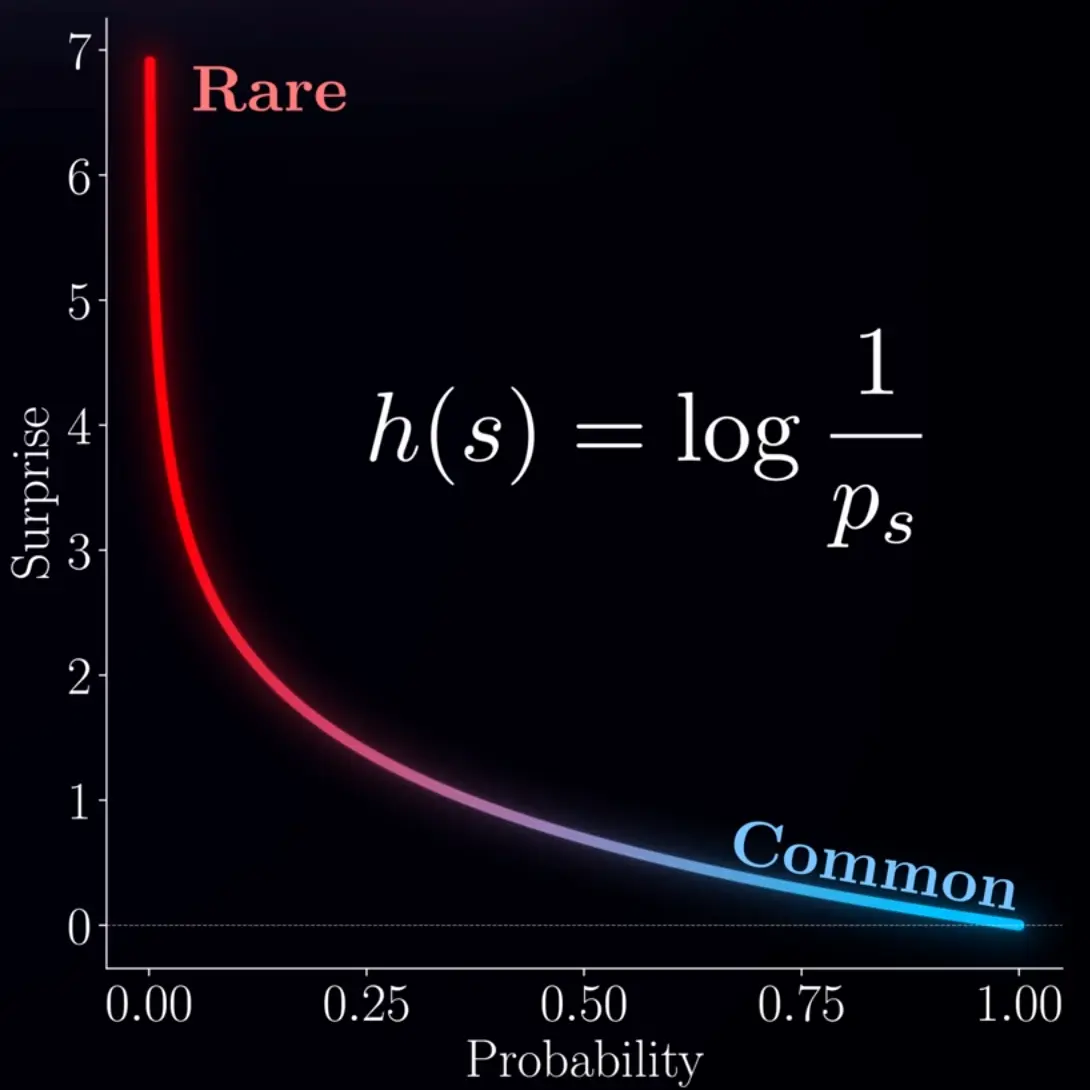
, see surprise: