Shannon information / Self-information / Surprise
The base of the logarithm sets the units. With , we measure in bits.
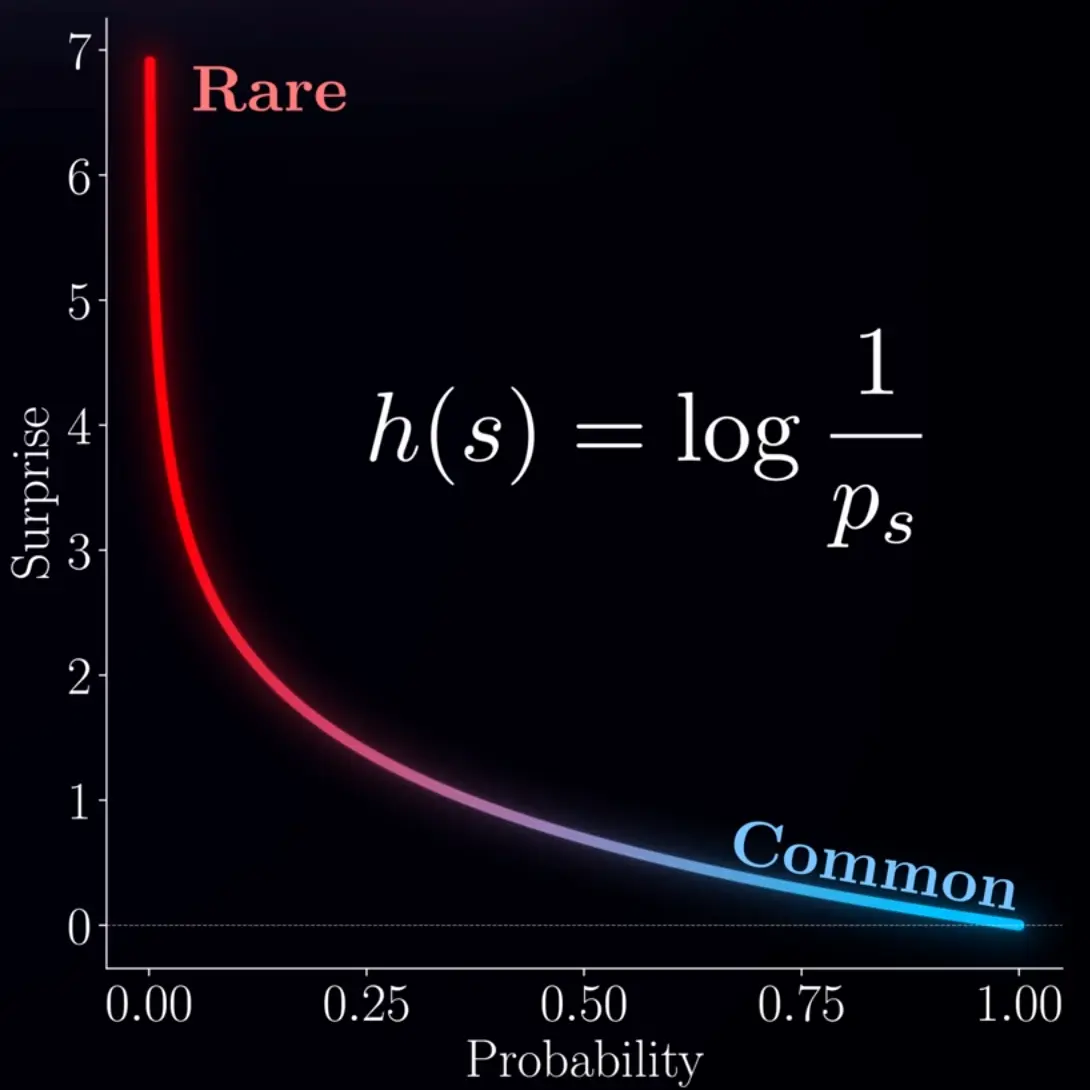
(s is the state in the above image, h is the surprise function)
Extreme cases:
p(x) = 1 → 0 surprise
p(x) = 0 → surprise
Information content with bits:
p(x) = 1/2 → 1 bit
p(x) = 1/4 → 2 bits
p(x) = 1/8 → 3 bits
p(x) = 1/10 → ~3.32 bits
p(x) = 1/100 → ~6.64 bits
The expected value of surprise is entropy:
Link to originalEntropy (Information Theory)
Entropy is the expected value of surprise/self-information of a discrete random variable :
Note: The continuous form “differential entropy” is not analogous and not a good measure for uncertainty or information, as it can be negative (even infinite), and is not invariant under continuous coordinate transformations. See wikipedia.
Additivity of information
Two independent probabilities multiply, the information of two independent events should add, intuitively.
The logarithmturns multiplication into addition:
Link to originaland are not interchangable
E.g.: If you believe a coin is fair (0.5/0.5), but it is rigged (0.99/0.01), then the CE is:
If you believe it is rigged when it is actually fair, then the CE is:
In the second case, the entropy is much larger, as half of the time you are extremely surprsied to see tails, this extreme surprise dominates the average surprise.
More surprising things are harder to compress.
In machine learning, for example if we predict how likely a football team is to win, we want to achieve a very low suprise (loss), so we can estimate confidently:
In machine learning, we want the next target to have a very high probability, i.e. low surprise → negative log-likelihood loss
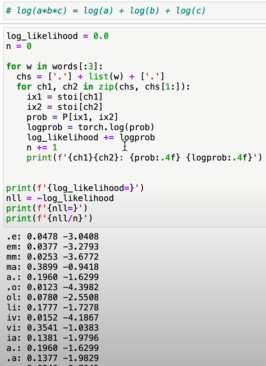
Don’t get confused
Quantity Formula Depends on Surprise / self-information Per-example NLL (log-likelihood) cross-entropy ,