year: 2025/03
paper: https://arxiv.org/pdf/2503.12406v1
website:
code:
connections: Meta-Learning through Hebbian Plasticity in Random Networks, Sebastian Risi, robotic control, synaptic plasticity, adaptation, generalization
The approach of evolving synaptic plasticity for sim-to-real adaptation and robust policies proposed here is conceptually simple and does not require a randomization1 of terrain, mass distribution, joint properties, contact friction, or morphological damage to extend the training data for sim-to-real locomotion adaptation.
The training methodology, motivations, conclusions, properties etc. is the same as in the precursos paper Meta-Learning through Hebbian Plasticity in Random Networks, but proven to work irl.
There’s some interesting properties like the robot only walking if it’s in contact with the ground.
And the 3D PCA shows a nice low-dim structure, and one principal component showing larger standard deviation on unseen uneven terrain “suggests that the network leverages Hebbian plasticity to explore a broader range of online weight adaptation, enhancing its ability to adapt efficiently to unpredictable environments”
They use an LSTM baseline and count its hidden + cell state as plastic parameters and allude to the variable ratio problem as a reason for its worse performance (1 OOM less plastic params than the plastic NN).
Weight normalization is crucial to improve the network stability by preventing the weights from becoming excessively large (i.e., preventing divergence) as the Hebbian updates are continually added to them.
Why wasn't this an issue in the previous work?
Risi @ ALIFE 2025 - Neuroevolution Tutorial:
→ This wasn’t an issue in the simulated version (where they didn’t even clip the weights), but crucial for the real version.
→ If you want incremental / continual adaptation, you might need some mechanism for enabling/disabling plasticity.
→ Interesting exploration also is energy-regularization / mass preservation of weight magnitudes “firing frequencies”.
They find that layerwise max normalization works better than layerwise standardization:
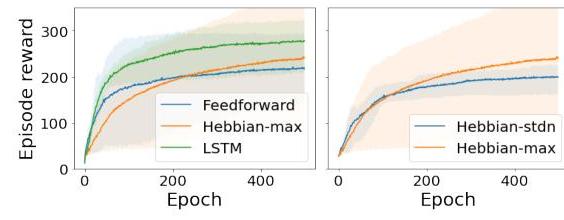
Max norm:
Stdn norm:
Footnotes
-
A recent work that does take the approach of domain randomization (+ICL): LocoFormer ↩