year: 2022
paper: https://arxiv.org/pdf/2012.14905
website: http://louiskirsch.com/
code: https://github.com/louiskirsch/vsml-neurips2021/tree/main
connections: meta learning, backpropagation, Jürgen Schmidhuber, KAUST, Evolution Strategies as a Scalable Alternative to Reinforcement Learning, parameter-sharing, message passing, self-organization, black-box optimization
This paper is doing message passing with global backpropagation and shared weights.
Transclude of The-Future-of-Artificial-Intelligence-is-Self-Organizing-and-Self-Assembling#^db08ab
The variable ratio problem:
Meta RNNs are simple, but they have much more meta variables than learned variables () leading them to be overparametrized, prone to overfit.
Learned learning rules / Fast Weight Networks have , but introduce a lot of complexity in the meta-learning network etc.
→A variable-sharing and sparsity principle can be used to unify these approaches into a simple framework: VSML.
Meta training vs. Meta testing
During meta testing: Hold fixed.
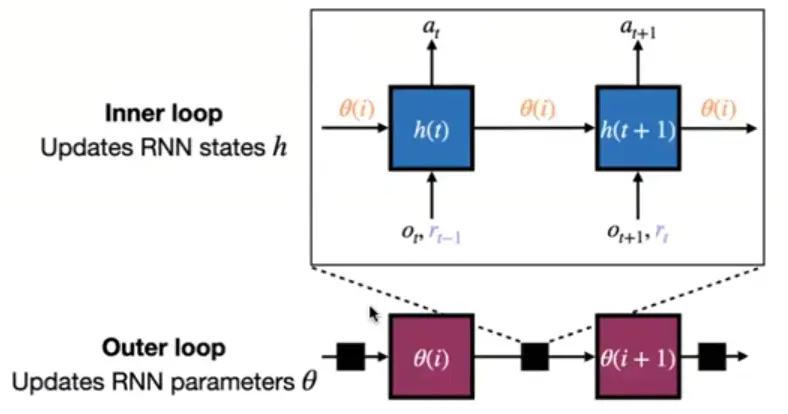
How does the ICL work? How does it go only in forward mode?
→ Errors are also passed in as inputs during meta train and test time! (“backward messages”).
“Everything is a variable: Variables we thought of as activations can be interpreted as weights.”
Multi-agent systems
In the reinforcement learning setting multiple agents can be modeled with shared parameters also in the context of meta learning.
This is related to the variable sharing in VSML depending on how the agent-environment boundary is drawn. Unlike these works, we demonstrate the advantage of variable sharing in meta learning more general-purpose LAs and present a weight update interpretation
Specialization vs generalization through coordinate information
Each sub-RNN can be fed its coordinates (a,b), position in time, or layer position to enable:
Specialization: Different neurons develop different functions (like biological neurons)
Implicit architecture learning: Suppress outputs based on position
However, experiments showed no benefits - the shared parameters without specialization were sufficient.
→ Parameter sharing without positional bias achieves better generalization.
⠀
The computational cost of the current VSML variant is also larger than the one of standard backpropagation. If we run a sub-RNN for each weight in a standard NN with W weights, the cost is in O(W N^2), where N is the state size of a sub-RNN.
If N is small enough, and our experiments suggest small N may be feasible, this may be an acceptable cost.
However, VSML is not bound to the interpretation of a sub-RNN as one weight. Future work may relax this particular choice.Meta optimization is also prone to local minima.
In particular, when the number of ticks between input and feedback increases (e.g. deeper architectures), credit assignment becomes harder.
Early experiments suggest that diverse meta task distributions can help mitigate these issues.Additionally, learning horizons are limited when using backprop-based meta optimization. Using ES allowed for training across longer horizons and more stable optimization. (gradient variance is independent of episode length)
Re credit assignment: Can this be alleviated with dense auxiliary reward of the predicting the local future state of each unit, as like an inner-loop predictive coding loss?
Variable sharing enables distributed memory and self-organization
VSML can be viewed as:
Distributed memory: Memory spread across network instead of external memory banks
Self-organizing system: Many sub-RNNs induce emergence of global learning algorithm
Modular learning: But unlike typical modular systems, no conditional selection - all modules share same to implement the learning algorithm
Recursive weight replacement hierarchy
“For future work”: Meta variables themselves could be replaced by LSTMs, yielding multi-level hierarchies of arbitrary depth. This would create a fractal-like structure where learning algorithms implement learning algorithms.
(old notes)
- Credit assignment issue with increasing number of ticks between inupt and feedback:
- We’ll prlly have a really bad time with soup on simple environments.
- We just need to go for really general stuff (“diverse task distributions”). First thing that comes to my mind is minecraft
- let’s keep in mind: the power of the brain is being overparametrized and extremely general, not excelling at cartpole.
- Simple neurons are most likely possible, and necessary for feasability.