The ability to handle situations (or tasks) that differ from from previously encountered situations - On the Measure of Intelligence
Link to originalGrokking is an instance of the minimum description length principle.
If you have a problem, you can just memorize a point-wise input to output mapping.
This has zero generalization.
But from there, you can keep pruning your mapping, making it simpler, a.k.a. more compressed.
The program that generalizes the best (while performing well on a training set), is the shortest. (or is it…? See How to build conscious machines)
→ **Generalization is memorization + regularization ** ←
(this type of generalization is still limited to in distribution, however)
Four levels of generalization
There are roughly four levels of generalization:
0: No generalization (e.g. a database)
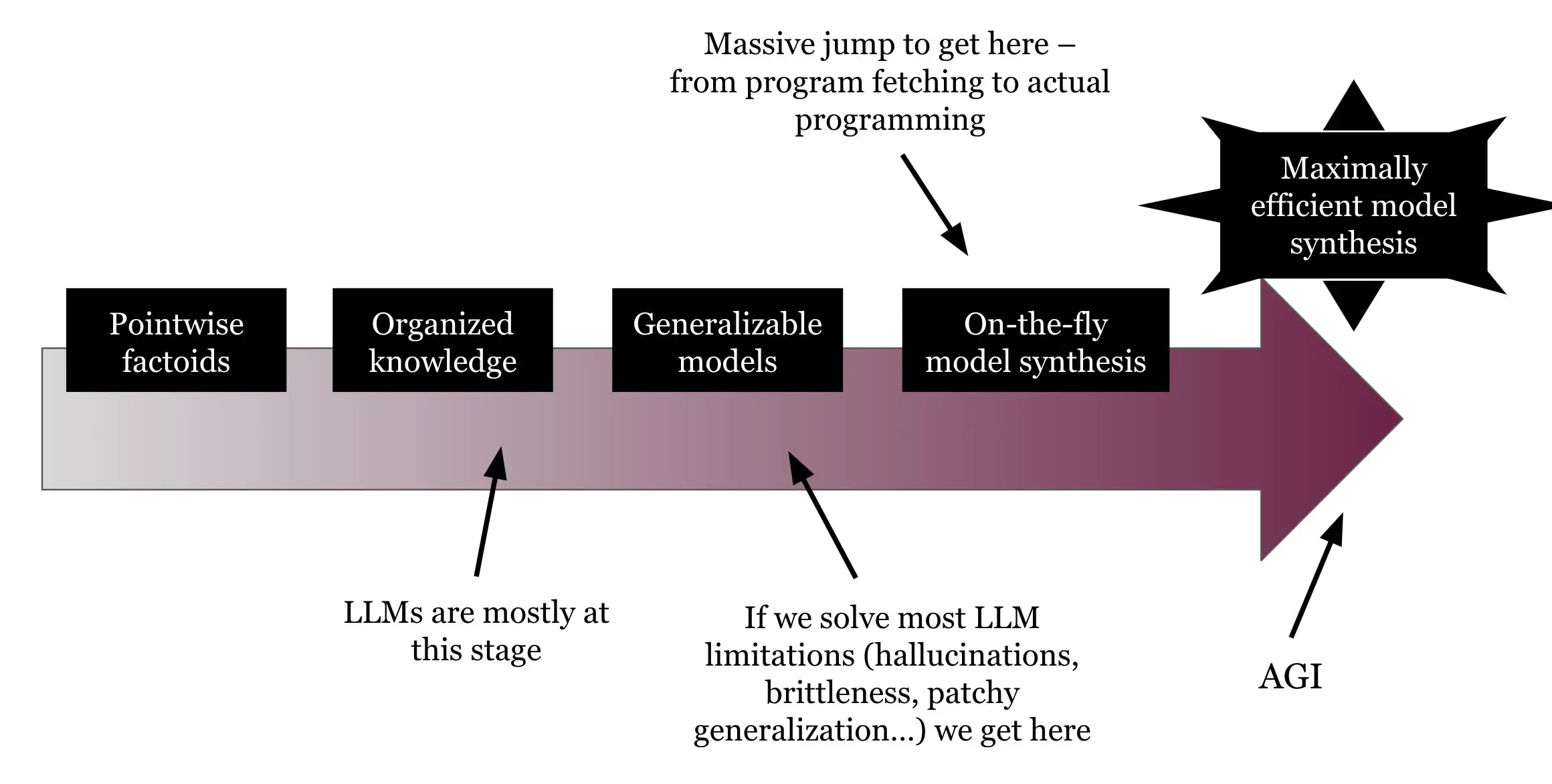
1: Having memorized the answers for a static set of tasks and being able to interpolate between them. Most LLM capabilities are at that level.
2: Having encoded generalizable programs to robustly solve tasks within a static set of tasks. LLMs can do some of that, but as displayed below, they suck at it, and fitting programs via gradient descent is ridiculously data-inefficient.
3: Being able to synthesize new programs on the fly to solve never-seen-before tasks. This is general intelligence.
Breadth of training predicts breadth of transfer. That is, the more contexts in which something is learned, the more the learner creates abstract models, and the less they rely on any particular example. Learners become better at applying their knowledge to a situation they’ve never seen before, which is the essence of creativity. - David Epstein, Range: Why Generalists Triumph in a Specialized World.
Link to originalBeyond the facts, I looked for laws. Naturally, this lead me - more than once - to hasty and incorrect generalizations. Especially in my younger years, when my knowledge - book aquired - and my experience in life were still inadequate. But in every sphere, barring none, I felt that I could only move and act when I held in my hand the thread of the general. - Trotzki
- Beware of hasty generalization → “from the particular to the general”
- Theory is necessary for practice → “from the general to the particular”
Link to originalIntelligence is skill-acquisition efficiency.
The size of the skill-space you can navigate within a given time / budget is the generality of the intelligence.
Joscha Bach calls this the ability to make models, which is the same thing. Being good at a single task is a skill. Having a model that allows you to pick up different skills is intelligence.
Link to originalgeneral intelligence is not a task specific skill, but the ability to quickly and sample-efficiently pick up any new task.
It is relatively easy to write an algorithm or train a model to solve a specifc task, even ARC, better than every human, especially if we just throw so much compute at it in order to model the entire distribution, i.e. brute-force it the deep-learning way, or spend a lot of compute doing discrete program search to solve it.
Link to originalThe ability for generalization in LLMs is intrinsically limited: A fundamental limitation of gradient descent.
To compress, LLMs try to represent new information in the compressed vector programs they’ve already learnt.
But this generalization capability is intrinsically limited, because the substrate of the model is a big parametric curve. Your are restricted to local generalization on that curve.
This is a fundamental limitation of gradient descent: While it gives you a strong signal about where the solution is, it is very data inefficient, because it requires a dense sampling of the data distribution and you are then limited to only generalizing within that data distribution, because your model is just interpolating between the data points it has seen during training.
LLM progress in a nutshell:
Link to originalAbstract vs general vs category hierarchy vs abstraction layer
Concrete → Abstract: Which? → What kind?
Specific → General: Narrow kind→ Broad kindSpecific → General operates within the space of categories.
Intension … defining properties of a category (what it is)
Extension … the set of things that fall under that category
Shrinking the intension → expanding the extension (and vice versa)
Specific General Abstract Int Num Concrete 42 :: Int a ⇒ a 42 :: Num a ⇒ a Category hierarchy: A is-a B is-a C … requires only shared properties (e.g.: tabby cat mammal)
Abstraction layer: hides a mechanism, exposes an interface … requires near-decomposability (e.g.: the structure of reality)
References
On the Measure of Intelligence
https://x.com/_saurabh/status/1763626711407816930?s=20
https://x.com/fchollet/status/1763692655408779455?s=20
https://arxiv.org/abs/1911.01547
https://arxiv.org/abs/2402.19450