KL-Divergence
The KL divergence measures the difference between the probability distribution of a model and the true distribution , i.e. the cross-entropy, disregarding the entropy of the true distribution itself:
It’s extra average surprise, aka information-theoretic regret, when assuming model instead of the true distribution .
In base 2, we get the inefficiency of using to encode in bits
The notation emphasizes that the KL divergence is not symmetric: 1
Link to originaland are not interchangable
E.g.: If you believe a coin is fair (0.5/0.5), but it is rigged (0.99/0.01), then the CE is:
If you believe it is rigged when it is actually fair, then the CE is:
In the second case, the entropy is much larger, as half of the time you are extremely surprsied to see tails, this extreme surprise dominates the average surprise.
KL divergence is not a metric (distance) because it is not symmetric!
→ When using KL divergence as a loss function, the choice of which distribution is the “reference” (P) versus the “approximation” (Q) matters significantly. For example, minimizing tends to produce Q that covers all modes of P (zero-avoiding), while minimizing produces Q that concentrates on high-probability regions of P (zero-forcing).
Here’s a visualization of the difference / KL in general: https://claude.ai/public/artifacts/56ba13ac-42cc-4328-9fa2-32294ebe0345
Link to originalReverse KL
We’re using the reverse , with and swapped, because the forward KL would require us to sample from the posterior which we can’t compute and need variational inference for in the first place.
Note: is always the thing we’re optimizing when using KLBehavioral differences:
(forward KL) is “mass-covering”: weighted by , it tries to cover everything, penalizing for not putting mass where has mass(reverse KL) is “mode-seeking”: weighted by , it focuses on the main modes of , penalizing for putting mass where is low
→ tends to underfit rather than overfit
Why aren’t we using KL-divergence as a loss function, if it seems to have better properties?
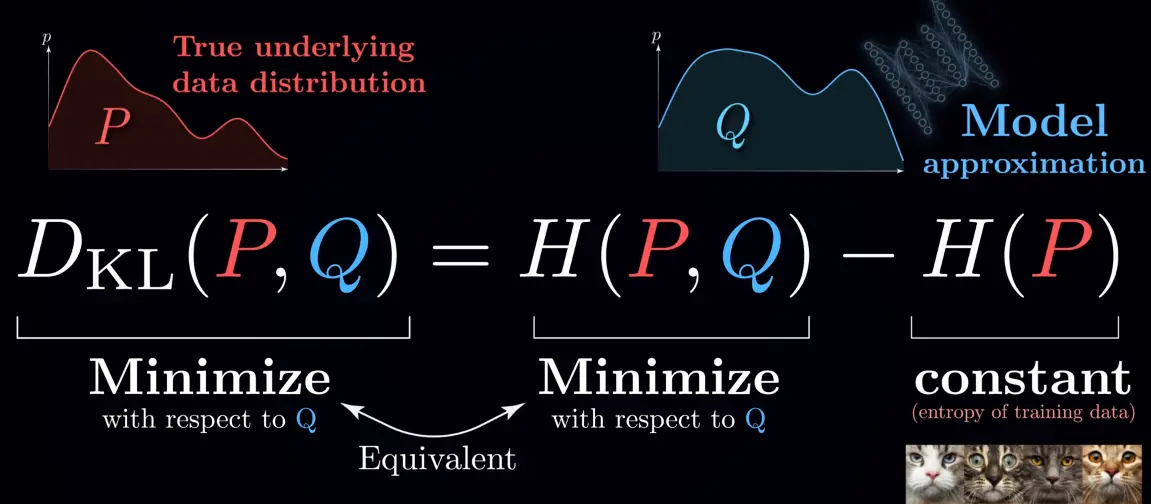
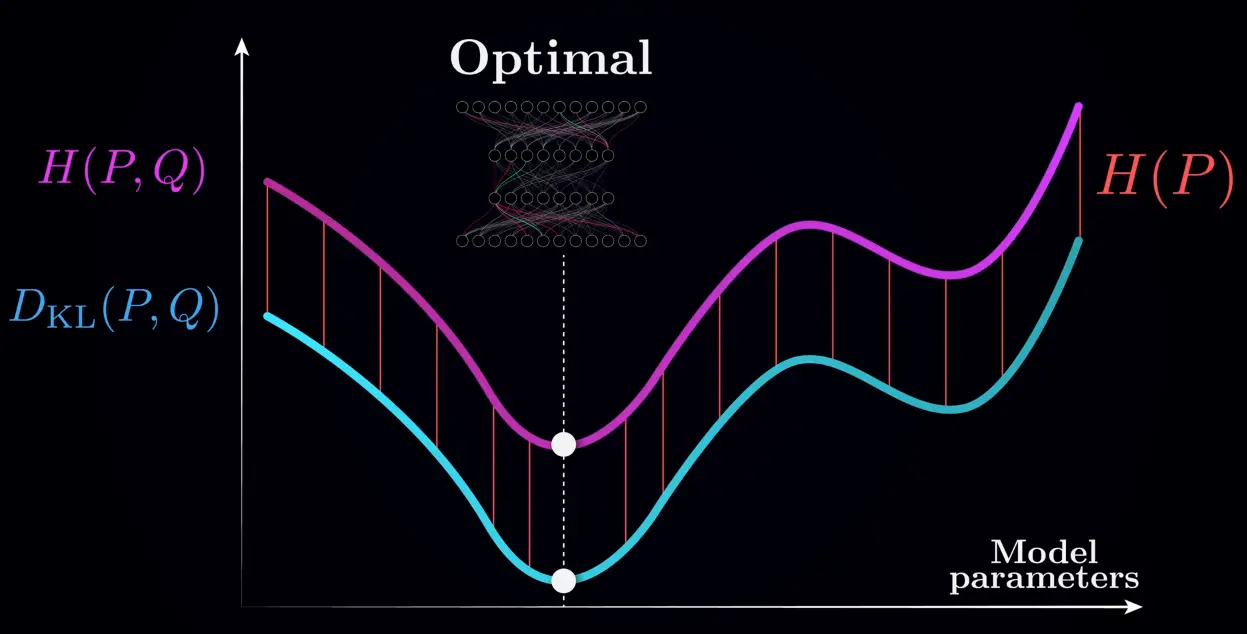
Since we cannot change , we can only minimize w.r.t. , and hence the KL divergence is equivalent to cross-entropy loss:
We don’t care about the exact value, so we don’t bother to estimate the entropy of the training data:
References
The Key Equation Behind Probability
Footnotes
-
Don’t ask me why cross-entropy doesn’t have the same notation. Maybe because it’s because KL-divergence could otherwise be more easily confused with a distance? ↩