In this work, we model ( inattentional blindness) in simulation and restrict our agent’s decision-making controller access only a small faction of its visual input.
We demonstrate that an agent’s inattentive blindness can result in better generalization, simply due to its ability to “not see things” that can confuse it.
As we will show, neuroevolution is an ideal method for training self-attention agents, because not only can we remove unnecessary complexity required for gradient-based methods, resulting in much simpler architectures, we can also incorporate modules that enhance the effectiveness of self-attention that need not be differentiable. We showcase self-attention agents trained with neuroevolution that require 1000x fewer parameters than conventional methods and yet is able to solve challenging vision-based RL tasks.
… our agent learns to attend to only task-critical visual spots and is therefore able to generalize to environments where task irrelevant elements are modified whereas conventional methods fail.
There are four stages of information processing
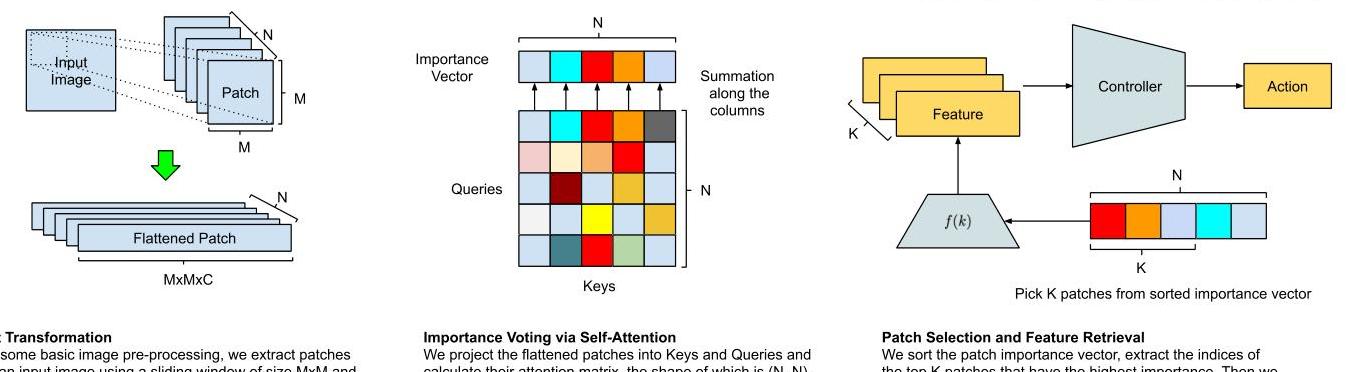
Input Transformation Given an observation, our agent first resizes it into an input image of shape L×L, the agent then segments the image into N patches and regard each patch as a potential region to attend to. Importance Voting via Self-Attention To decide which patches are appropriate, the agent passes the patches to the self-attention module to get a vector representing each patch’s importance, based on which it selects 𝐾K patches of the highest importance. Patch Selection and Feature Retrieval Our agent then uses the index (k) of each of the K patches to fetch relevant features of each patch with a function f(k), which can be either a learned module or a pre-defined function that incorporates domain knowledge. Controller Finally, the agent inputs the features into its controller that outputs the action it will execute in its environment.
There is much discussion in the deep learning community about the generalization properties of large neural networks. While larger neural networks generalize better than smaller networks, the reason is not that they have more weight parameters, but as recent work (e.g. [1, 2, 3]) suggests, it is because larger networks allow the optimization algorithm to find good solutions, or lottery tickets [1], within a small fraction of the allowable solution space. These solutions can then be pruned to form sub-networks with useful inductive biases that have desirable generalization properties.
Recent neuroscience critiques of deep learning (e.g. [4, 5, 6]) point out that animals are born with highly structured brain connectivity that are far too complex to be specified explicitly in the genome and must be compressed through a “genomic bottleneck”—information encoded into the genome that specify a set of rules for wiring up a brain [4]. Innate processes and behaviors are encoded by evolution into the genome, and as such many of the neuronal circuits in animal brains are pre-wired, and ready to operate from birth [6]. These innate abilities make it easier for animals to generalize and quickly adapt to different environments [7].
…
Analogous to the pruning of lottery ticket solutions, indirect encoding methods allow for both the expressiveness of large neural architectures while minimizing the number of free model parameters.
…
By encoding the weights of a large model with a small number of parameters, we can substantially reduce the search space of the solution, at the expense of restricting our solution to a small subspace of all possible solutions offered by direct encoding methods. This constraint naturally incorporates into our agent an inductive bias that determines what it does well at [5, 4, 6], and this inductive bias is dependent on the choice of our indirect encoding method.
Computing an attention matrix as A=XXT from the raw token features produces a gram matrix. This already captures associations/relational structure between tokens, but since there are no free (learnable) parameters,, it isn’t suitable for tasks beyond simple association.
Learnable Wq,Wk∈Rdemb,dqk matrices are introduced, projecting the raw features into a new space, where A is more meaningful for the task at hand.
These weight matrices can be seen as the small genotype encoding the much larger phenotype attention matrix:
When we scale number of learnable parameters while the input dimension is held constant, the free parameters scale with O(dqk), while A grows with O(n2), and typically, n2≫dqk, where n are the number of input tokens.